Перевод статьи подготовлен в преддверии старта курса «DevOps практики и инструменты».

Метод RED (Rate, Errors, Duration) является одним из популярных подходов к мониторингу производительности. Он часто применяется для мониторинга микросервисов, хотя ничего не мешает использовать его для баз данных, таких как MySQL.
В Percona Monitoring and Management (PMM) v2 вся необходимая информация собирается в базу данных ClickHouse, и дальше уже дело техники с помощью встроенного источника данных ClickHouse создать дашборд для визуализации метрик.
При создании дашборда помимо панелей для RED были добавлены несколько дополнительных панелей, чтобы показать некоторые интересные вещи, которые можно сделать с Grafana + ClickHouse в качестве источника данных и информацией, которую мы храним о производительности запросов MySQL.
Давайте посмотрим на дашборд внимательнее.

Мы видим классические панели RED-метода, показывающие Query Rate (количество запросов в секунду), Error Rate (количество ошибок), а также среднее значение и 99ый процентиль Query Latency (время выполнения запросов) для всех узлов системы. На панелях ниже отображается информация по конкретным узлам, что очень полезно для сравнения их производительности. Если один из узлов начнет работать не так, как остальные аналогичные узлы, то это повод для расследования.
С помощью фильтров (“Filters” в верхней части дашборда) вы можете просматривать только нужные вам данные. Например, можно выбрать только запросы схемы “sbtest” для хостов, расположенных в регионе “datacenter4”:
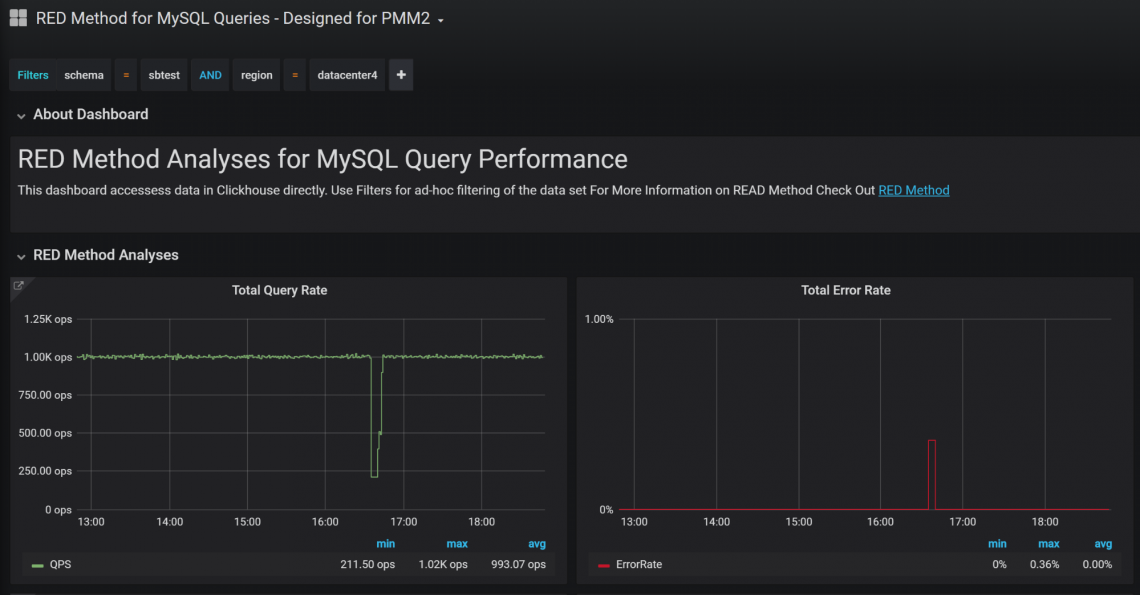
Такая ad-hoc фильтрация очень удобна. Вы можете использовать в фильтрах регулярные выражения, искать по конкретному QueryID, анализировать запросы от конкретных клиентских хостов и т. д. Описание колонок, доступных в ClickHouse, есть в посте Advanced Query Analysis in Percona Monitoring and Management with Direct ClickHouse Access.
Из большинства панелей вы можете быстро перейти в Query Analytics (анализ запросов) для просмотра подробной информации о производительности запросов, или, если вы заметили у одного из хостов что-то необычное, то через “Data Links” можете посмотреть запросы этого хоста — нажмите на график и перейдите по выделенной ссылке:
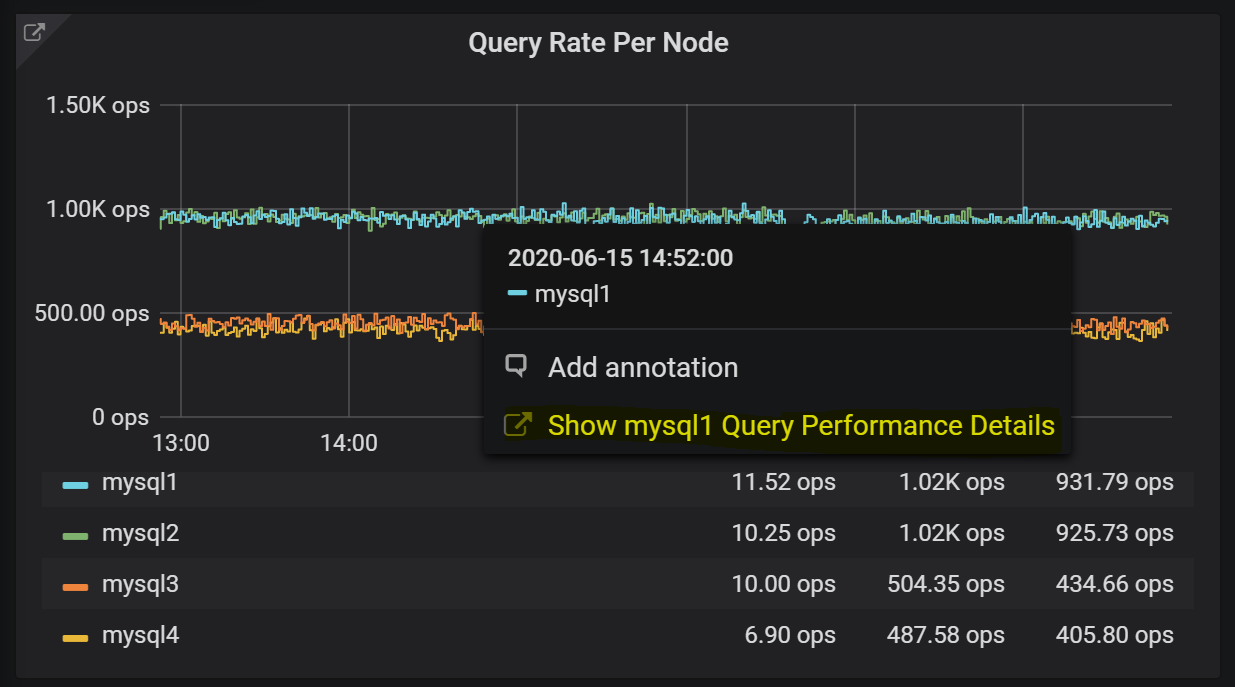
Для каждой из систем в отдельности вы можете смотреть те же RED-метрики, что и для всей системы в целом. По умолчанию я бы оставлял эти панели свернутыми, особенно если вы мониторите много хостов.
Мы познакомились с панелями RED-метода. Теперь давайте посмотрим на дополнительные панели (Additional Dashboards) в этом дашборде.
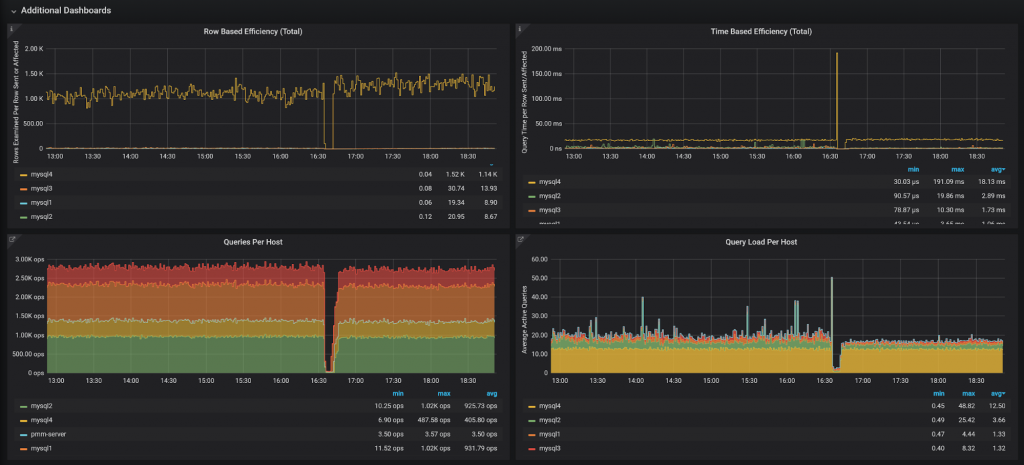
Row Based Efficiency (эффективность на основе строк) показывает, сколько строк было проанализировано на каждую возвращенную или измененную строку. Как правило, значения больше 100 указывают на плохие индексы или на очень сложные запросы, которые считывают много данных, а возвращают только несколько строк. Оба этих случая требуют анализа.
Time-Based Efficiency (эффективность на основе времени) основана на той же математике, но смотрит на время выполнения запроса, а не на количество сканированных строк. Это позволяет выявлять проблемы, связанные с медленным диском или конфликтующими запросами. Как правило, от высокопроизводительной системы следует ожидать доли миллисекунды на отправку строки клиенту или на ее изменение. Запросы, которые возвращают или изменяют много строк, будут иметь более низкое значение.
Queries Per Host (количество запросов по хостам) говорит само за себя и рядом с ним очень полезно видеть Query Load Per Host (нагрузку по хостам), которая показывает количество одновременных активных запросов. Здесь мы можем видеть, что несмотря на то, что у mysql4 не самое большое количество запросов (query rate), но у него самая большая нагрузка и наибольшее среднее количество активных запросов.
Размышляя о том, какие еще метрики могут быть полезны, я добавил следующие дополнительные панели:
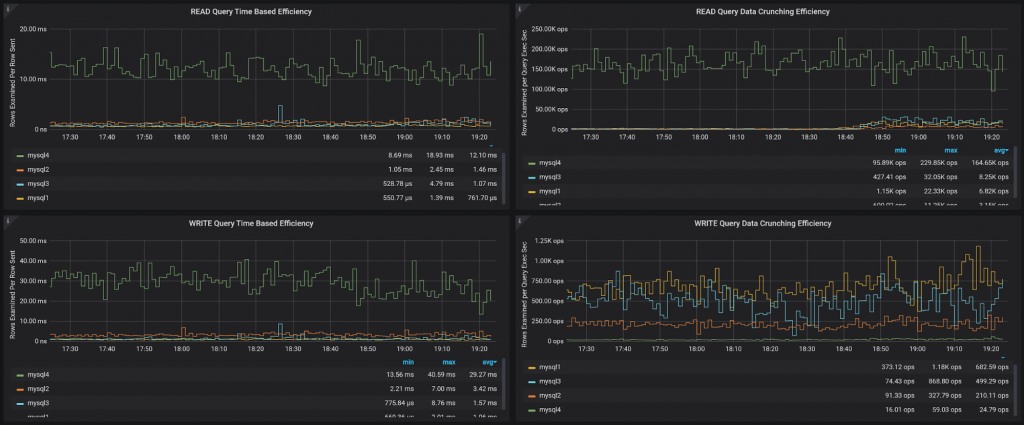
Эти панели разделяют Query Processing Efficiency на READ-запросы (которые возвращают строки) и WRITE-запросы (у которых есть row_affected).
QueryTime Based Efficiency — это то же самое, что описано выше, только с акцентом на определенные виды запросов.
Data Crunching Efficiency (эффективность обработки данных) — это несколько другой взгляд на те же данные. Здесь показано сколько строк анализируется (examined) запросом в сравнении с временем выполнения запроса. Это, с одной стороны, показывает вычислительную мощность системы. Система с большим количеством ядер, имеющая все данные в памяти, может обрабатывать миллионы строк в секунду и выполнять много работы. Но это не говорит об эффективности запросов. На самом деле, системы, которые быстро обрабатывают много данных, часто выполняют много операций полного сканирования таблиц.
Наконец, есть несколько списков с запросами.

Частые запросы, самые медленные запросы (по среднему времени выполнения), запросы, вызывающие наибольшую нагрузку, и запросы, которые завершились с ошибкой или предупреждением. Вы также можете увидеть эти запросы и в Query Analytics, но я хотел показать их здесь для примера.
Заинтересовались? Вы можете установить дашборд в Percona Monitoring and Management (PMM) v2 с Grafana.com.
От кода до kubernetes
Метод RED (Rate, Errors, Duration) является одним из популярных подходов к мониторингу производительности. Он часто применяется для мониторинга микросервисов, хотя ничего не мешает использовать его для баз данных, таких как MySQL.
В Percona Monitoring and Management (PMM) v2 вся необходимая информация собирается в базу данных ClickHouse, и дальше уже дело техники с помощью встроенного источника данных ClickHouse создать дашборд для визуализации метрик.
При создании дашборда помимо панелей для RED были добавлены несколько дополнительных панелей, чтобы показать некоторые интересные вещи, которые можно сделать с Grafana + ClickHouse в качестве источника данных и информацией, которую мы храним о производительности запросов MySQL.
Давайте посмотрим на дашборд внимательнее.
Мы видим классические панели RED-метода, показывающие Query Rate (количество запросов в секунду), Error Rate (количество ошибок), а также среднее значение и 99ый процентиль Query Latency (время выполнения запросов) для всех узлов системы. На панелях ниже отображается информация по конкретным узлам, что очень полезно для сравнения их производительности. Если один из узлов начнет работать не так, как остальные аналогичные узлы, то это повод для расследования.
С помощью фильтров (“Filters” в верхней части дашборда) вы можете просматривать только нужные вам данные. Например, можно выбрать только запросы схемы “sbtest” для хостов, расположенных в регионе “datacenter4”:
Такая ad-hoc фильтрация очень удобна. Вы можете использовать в фильтрах регулярные выражения, искать по конкретному QueryID, анализировать запросы от конкретных клиентских хостов и т. д. Описание колонок, доступных в ClickHouse, есть в посте Advanced Query Analysis in Percona Monitoring and Management with Direct ClickHouse Access.
Из большинства панелей вы можете быстро перейти в Query Analytics (анализ запросов) для просмотра подробной информации о производительности запросов, или, если вы заметили у одного из хостов что-то необычное, то через “Data Links” можете посмотреть запросы этого хоста — нажмите на график и перейдите по выделенной ссылке:
Для каждой из систем в отдельности вы можете смотреть те же RED-метрики, что и для всей системы в целом. По умолчанию я бы оставлял эти панели свернутыми, особенно если вы мониторите много хостов.
Мы познакомились с панелями RED-метода. Теперь давайте посмотрим на дополнительные панели (Additional Dashboards) в этом дашборде.
Row Based Efficiency (эффективность на основе строк) показывает, сколько строк было проанализировано на каждую возвращенную или измененную строку. Как правило, значения больше 100 указывают на плохие индексы или на очень сложные запросы, которые считывают много данных, а возвращают только несколько строк. Оба этих случая требуют анализа.
Time-Based Efficiency (эффективность на основе времени) основана на той же математике, но смотрит на время выполнения запроса, а не на количество сканированных строк. Это позволяет выявлять проблемы, связанные с медленным диском или конфликтующими запросами. Как правило, от высокопроизводительной системы следует ожидать доли миллисекунды на отправку строки клиенту или на ее изменение. Запросы, которые возвращают или изменяют много строк, будут иметь более низкое значение.
Queries Per Host (количество запросов по хостам) говорит само за себя и рядом с ним очень полезно видеть Query Load Per Host (нагрузку по хостам), которая показывает количество одновременных активных запросов. Здесь мы можем видеть, что несмотря на то, что у mysql4 не самое большое количество запросов (query rate), но у него самая большая нагрузка и наибольшее среднее количество активных запросов.
Размышляя о том, какие еще метрики могут быть полезны, я добавил следующие дополнительные панели:
Эти панели разделяют Query Processing Efficiency на READ-запросы (которые возвращают строки) и WRITE-запросы (у которых есть row_affected).
QueryTime Based Efficiency — это то же самое, что описано выше, только с акцентом на определенные виды запросов.
Data Crunching Efficiency (эффективность обработки данных) — это несколько другой взгляд на те же данные. Здесь показано сколько строк анализируется (examined) запросом в сравнении с временем выполнения запроса. Это, с одной стороны, показывает вычислительную мощность системы. Система с большим количеством ядер, имеющая все данные в памяти, может обрабатывать миллионы строк в секунду и выполнять много работы. Но это не говорит об эффективности запросов. На самом деле, системы, которые быстро обрабатывают много данных, часто выполняют много операций полного сканирования таблиц.
Наконец, есть несколько списков с запросами.
Частые запросы, самые медленные запросы (по среднему времени выполнения), запросы, вызывающие наибольшую нагрузку, и запросы, которые завершились с ошибкой или предупреждением. Вы также можете увидеть эти запросы и в Query Analytics, но я хотел показать их здесь для примера.
Заинтересовались? Вы можете установить дашборд в Percona Monitoring and Management (PMM) v2 с Grafana.com.
От кода до kubernetes

