Привет,
Я создатель Dependency Injector. Это dependency injection фреймворк для Python.
Это завершающее руководство по построению приложений с помощью Dependency Injector. Прошлые руководства рассказывают как построить веб-приложение на Flask, REST API на Aiohttp и мониторинг демона на Asyncio применяя принцип dependency injection.
Сегодня хочу показать как можно построить консольное (CLI) приложение.
Дополнительно я подготовил ответы на часто задаваемые вопросы и опубликую их постскриптум.
Руководство состоит из таких частей:
Завершенный проект можно найти на Github.
Для старта необходимо иметь:
И желательно иметь общее представление о принципе dependency injection.
Мы будем строить CLI (консольное) приложение, которое ищет фильмы. Назовем его Movie Lister.
Как работает Movie Lister?
Movie Lister это приложение-пример, которое используется в статье Мартина Фаулера о dependency injection и inversion of control.
Вот как выглядит диаграмма классов приложения Movie Lister:

Обязанности между классами распределены так:
Начнём с подготовки окружения.
В первую очередь нам нужно создать папку проекта и virtual environment:
Теперь давайте активируем virtual environment:
Окружение готово. Теперь займемся структурой проекта.
В этом разделе организуем структуру проекта.
Создадим в текущей папке следующую структуру. Все файлы пока оставляем пустыми.
Начальная структура:
Пришло время установить зависимости. Мы будем использовать такие пакеты:
Добавим следующие строки в файл
И выполним в терминале:
Установка зависимостей завершена. Переходим к фикстурам.
В это разделе мы добавим фикстуры. Фикстурами называют тестовые данные.
Мы создадим скрипт, который создаст тестовые базы данных.
Добавляем директорию
Далее редактируем
Теперь выполним в терминале:
Скрипт должен вывести
Проверим, что файлы
Фикстуры созданы. Продолжаем.
В этом разделе мы добавим основную часть нашего приложения — контейнер.
Контейнер позволяет описать структуру приложения в декларативном стиле. Он будет содержать все компоненты приложения их зависимости. Все зависимости будут указаны явно. Для добавления компонентов приложения в контейнер используются провайдеры. Провайдеры управляют временем жизни компонентов. При создании провайдера не происходит создание компонента. Мы указываем провайдеру как создавать объект, и он создаст его как только в этом будет необходимость. Если зависимостью одного провайдера является другой провайдер, то он будет вызван и так далее по цепочке зависимостей.
Отредактируем
Контейнер пока пуст. Мы добавим провайдеры в следующих секциях.
Давайте еще добавим функцию
Отредактируем
Теперь добавим все что нужно для работы с csv файлами.
Нам понадобится:
После добавления каждого компонента будем добавлять его в контейнер.
Создаем файл
и добавляем внутрь следующие строки:
Теперь нам нужно добавить фабрику
Отредактируем
Переходим к созданию
Создаем файл
и добавляем внутрь следующие строки:
Теперь добавим
Отредактируем
У
У
Теперь давайте добавим значения конфигурации.
Отредактируем
Значения установлены в конфигурационный файл. Обновим функцию
Отредактируем
Переходим к
Создаем файл
и добавляем внутрь следующие строки:
Обновляем
Все компоненты созданы и добавлены в контейнер.
В завершение обновляем функцию
Отредактируем
Все готово. Теперь запустим приложение.
Выполним в терминале:
Вы увидите:
Наше приложение работает с базой данных фильмов в формате
В это разделе мы добавим другой тип
Отредактируем
Добавляем провайдер
Отредактируем
У провайдера
Отредактируем
Готово. Давайте проверим.
Выполняем в терминале:
Вы увидите:
Наше приложение поддерживает оба формата базы данных:
В этом разделе мы сделаем наше приложение более гибким.
Больше не нужно будет делать изменения в коде для переключения между
В этом нам поможет провайдер
Отредактрируем
Мы создали провайдер
Переключателем является опция конфигурации
Теперь нам нужно считать значение
Отредактируем
Готово.
Выполним в терминале следующие команды:
Вывод при выполнении каждой команды будет выглядеть так:
В этом разделе познакомились с провайдером
В следующем разделе добавим несколько тестов.
В завершение добавим несколько тестов.
Создаём файл
и добавляем в него следующие строки:
Теперь запустим тестирование и проверим покрытие:
Вы увидите:
Работа закончена. Теперь давайте подведем итоги.
Мы построили консольное (CLI) приложение применяя принцип dependency injection. Мы использовали Dependency Injector в качестве dependency injection фреймворка.
Преимущество, которое вы получаете с Dependency Injector — это контейнер.
Контейнер начинает окупаться, когда вам нужно понять или изменить структуру приложения. С контейнером это легко, потому что все компоненты приложения и их зависимости определены явно и в одном месте:
Контейнер как карта вашего приложения. Вы всегда знайте что от чего зависит.
В комментариях к прошлому руководству были заданы классные вопросы: «зачем это нужно?», «зачем нужен фреймворк?», «чем фреймворк помогает в реализации?».
Я подготовил ответы:
Что такое dependency injection?
Зачем мне применять dependency injection?
Как мне начать применять dependency injection?
Зачем мне для этого фреймворк?
Какаю цену я плачу?
В дополнение опишу концепцию Dependency Injector как фреймворка.
Dependency Injector основан на двух принципах:
Чем Dependency Injector отличается от другим фреймворков?
Dependency Injector предлагает простой контракт:
Сила Dependency Injector в его простоте и прямолинейности. Это простой инструмент для реализации мощного принципа.
Если вы заинтересовались, но сомневайтесь, моя рекомендация такая:
Попробуйте применить этот подход на протяжении 2-х месяцев. Он неинтуитивный. Нужно время чтобы привыкнуть и прочувствовать. Польза стает ощутимой, когда проект вырастает до 30+ компонентов в контейнере. Если не понравится — много не потеряйте. Если понравится — получите существенное преимущество.
Буду рад фидбеку и отвечу на вопросы в комментариях.
Я создатель Dependency Injector. Это dependency injection фреймворк для Python.
Это завершающее руководство по построению приложений с помощью Dependency Injector. Прошлые руководства рассказывают как построить веб-приложение на Flask, REST API на Aiohttp и мониторинг демона на Asyncio применяя принцип dependency injection.
Сегодня хочу показать как можно построить консольное (CLI) приложение.
Дополнительно я подготовил ответы на часто задаваемые вопросы и опубликую их постскриптум.
Руководство состоит из таких частей:
- Что мы будем строить?
- Подготовка окружения
- Структура проекта
- Установка зависимостей
- Фикстуры
- Контейнер
- Работа с csv
- Работа с sqlite
- Провайдер Selector
- Тесты
- Заключение
- PS: вопросы и ответы
Завершенный проект можно найти на Github.
Вышла новая мажорная версия Dependency Injector 4.0.
Основная фича этой версии — связывание (wiring). Узнать больше о новой фиче можно в этом посте.
Для старта необходимо иметь:
- Python 3.5+
- Virtual environment
И желательно иметь общее представление о принципе dependency injection.
Что мы будем строить?
Мы будем строить CLI (консольное) приложение, которое ищет фильмы. Назовем его Movie Lister.
Как работает Movie Lister?
- У нас есть база данных фильмов
- О каждом фильме известна такая информация:
- Название
- Год выпуска
- Имя режиссёра
- База данных распространяется в двух форматах:
- Csv файл
- Sqlite база данных
- Приложение выполняет поиск по базе данных по таким критериям:
- Имя режиссёра
- Год выпуска
- Другие форматы баз данных могут быть добавлены в будущем
Movie Lister это приложение-пример, которое используется в статье Мартина Фаулера о dependency injection и inversion of control.
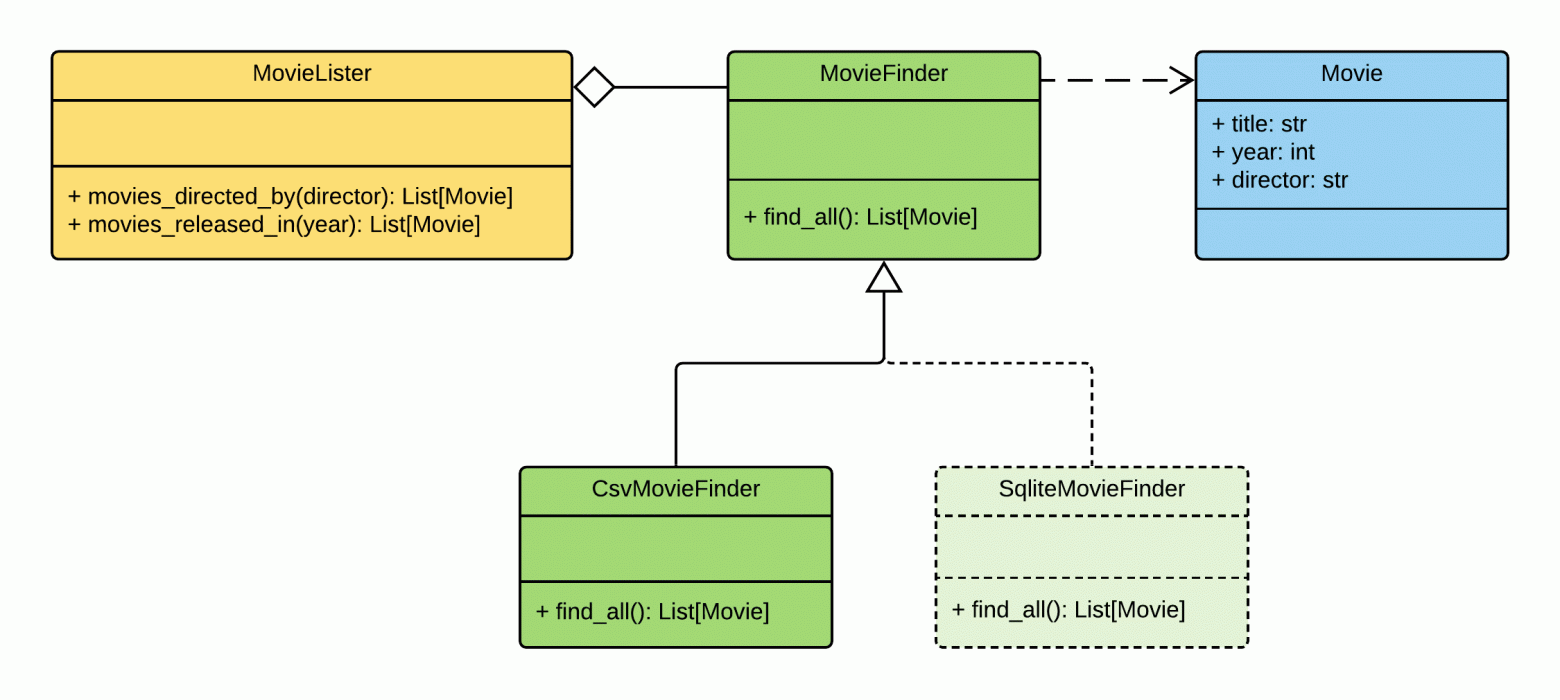
Вот как выглядит диаграмма классов приложения Movie Lister:
Обязанности между классами распределены так:
MovieLister— отвечает за поискMovieFinder— отвечает за извлечение данных из базыMovie— класс сущности «фильм»
Подготовка окружения
Начнём с подготовки окружения.
В первую очередь нам нужно создать папку проекта и virtual environment:
mkdir movie-lister-tutorial cd movie-lister-tutorial python3 -m venv venv
Теперь давайте активируем virtual environment:
. venv/bin/activate
Окружение готово. Теперь займемся структурой проекта.
Структура проекта
В этом разделе организуем структуру проекта.
Создадим в текущей папке следующую структуру. Все файлы пока оставляем пустыми.
Начальная структура:
./ ├── movies/ │ ├── __init__.py │ ├── __main__.py │ └── containers.py ├── venv/ ├── config.yml └── requirements.txt
Установка зависимостей
Пришло время установить зависимости. Мы будем использовать такие пакеты:
dependency-injector— dependency injection фреймворкpyyaml— библиотека для парсинга YAML файлов, используется для чтения конфигаpytest— фреймворк для тестированияpytest-cov— библиотека-помогатор для измерения покрытия кода тестами
Добавим следующие строки в файл
requirements.txt:dependency-injector pyyaml pytest pytest-cov
И выполним в терминале:
pip install -r requirements.txt
Установка зависимостей завершена. Переходим к фикстурам.
Фикстуры
В это разделе мы добавим фикстуры. Фикстурами называют тестовые данные.
Мы создадим скрипт, который создаст тестовые базы данных.
Добавляем директорию
data/ в корень проекта и внутрь добавляем файл fixtures.py:./ ├── data/ │ └── fixtures.py ├── movies/ │ ├── __init__.py │ ├── __main__.py │ └── containers.py ├── venv/ ├── config.yml └── requirements.txt
Далее редактируем
fixtures.py:"""Fixtures module.""" import csv import sqlite3 import pathlib SAMPLE_DATA = [ ('The Hunger Games: Mockingjay - Part 2', 2015, 'Francis Lawrence'), ('Rogue One: A Star Wars Story', 2016, 'Gareth Edwards'), ('The Jungle Book', 2016, 'Jon Favreau'), ] FILE = pathlib.Path(__file__) DIR = FILE.parent CSV_FILE = DIR / 'movies.csv' SQLITE_FILE = DIR / 'movies.db' def create_csv(movies_data, path): with open(path, 'w') as opened_file: writer = csv.writer(opened_file) for row in movies_data: writer.writerow(row) def create_sqlite(movies_data, path): with sqlite3.connect(path) as db: db.execute( 'CREATE TABLE IF NOT EXISTS movies ' '(title text, year int, director text)' ) db.execute('DELETE FROM movies') db.executemany('INSERT INTO movies VALUES (?,?,?)', movies_data) def main(): create_csv(SAMPLE_DATA, CSV_FILE) create_sqlite(SAMPLE_DATA, SQLITE_FILE) print('OK') if __name__ == '__main__': main()
Теперь выполним в терминале:
python data/fixtures.py
Скрипт должен вывести
OK при успешном завершении.Проверим, что файлы
movies.csv и movies.db появились в директории data/:./ ├── data/ │ ├── fixtures.py │ ├── movies.csv │ └── movies.db ├── movies/ │ ├── __init__.py │ ├── __main__.py │ └── containers.py ├── venv/ ├── config.yml └── requirements.txt
Фикстуры созданы. Продолжаем.
Контейнер
В этом разделе мы добавим основную часть нашего приложения — контейнер.
Контейнер позволяет описать структуру приложения в декларативном стиле. Он будет содержать все компоненты приложения их зависимости. Все зависимости будут указаны явно. Для добавления компонентов приложения в контейнер используются провайдеры. Провайдеры управляют временем жизни компонентов. При создании провайдера не происходит создание компонента. Мы указываем провайдеру как создавать объект, и он создаст его как только в этом будет необходимость. Если зависимостью одного провайдера является другой провайдер, то он будет вызван и так далее по цепочке зависимостей.
Отредактируем
containers.py:"""Containers module.""" from dependency_injector import containers class ApplicationContainer(containers.DeclarativeContainer): ...
Контейнер пока пуст. Мы добавим провайдеры в следующих секциях.
Давайте еще добавим функцию
main(). Её обязанность — запускать приложение. Пока она будет только создавать контейнер.Отредактируем
__main__.py:"""Main module.""" from .containers import ApplicationContainer def main(): container = ApplicationContainer() if __name__ == '__main__': main()
Контейнер — первый объект в приложении. Он используется для получения всех остальных объектов.
Работа с csv
Теперь добавим все что нужно для работы с csv файлами.
Нам понадобится:
- Сущность
Movie - Базовый класс
MovieFinder - Его реализация
CsvMovieFinder - Класс
MovieLister
После добавления каждого компонента будем добавлять его в контейнер.
Создаем файл
entities.py в пакете movies:./ ├── data/ │ ├── fixtures.py │ ├── movies.csv │ └── movies.db ├── movies/ │ ├── __init__.py │ ├── __main__.py │ ├── containers.py │ └── entities.py ├── venv/ ├── config.yml └── requirements.txt
и добавляем внутрь следующие строки:
"""Movie entities module.""" class Movie: def __init__(self, title: str, year: int, director: str): self.title = str(title) self.year = int(year) self.director = str(director) def __repr__(self): return '{0}(title={1}, year={2}, director={3})'.format( self.__class__.__name__, repr(self.title), repr(self.year), repr(self.director), )
Теперь нам нужно добавить фабрику
Movie в контейнер. Для этого нам понадобиться модуль providers из dependency_injector.Отредактируем
containers.py:"""Containers module.""" from dependency_injector import containers, providers from . import entities class ApplicationContainer(containers.DeclarativeContainer): movie = providers.Factory(entities.Movie)
Не забудьте убрать эллипсис (...). В контейнере уже есть провайдеры и он больше не нужен.Переходим к созданию
finders.Создаем файл
finders.py в пакете movies:./ ├── data/ │ ├── fixtures.py │ ├── movies.csv │ └── movies.db ├── movies/ │ ├── __init__.py │ ├── __main__.py │ ├── containers.py │ ├── entities.py │ └── finders.py ├── venv/ ├── config.yml └── requirements.txt
и добавляем внутрь следующие строки:
"""Movie finders module.""" import csv from typing import Callable, List from .entities import Movie class MovieFinder: def __init__(self, movie_factory: Callable[..., Movie]) -> None: self._movie_factory = movie_factory def find_all(self) -> List[Movie]: raise NotImplementedError() class CsvMovieFinder(MovieFinder): def __init__( self, movie_factory: Callable[..., Movie], path: str, delimiter: str, ) -> None: self._csv_file_path = path self._delimiter = delimiter super().__init__(movie_factory) def find_all(self) -> List[Movie]: with open(self._csv_file_path) as csv_file: csv_reader = csv.reader(csv_file, delimiter=self._delimiter) return [self._movie_factory(*row) for row in csv_reader]
Теперь добавим
CsvMovieFinder в контейнер.Отредактируем
containers.py:"""Containers module.""" from dependency_injector import containers, providers from . import finders, entities class ApplicationContainer(containers.DeclarativeContainer): config = providers.Configuration() movie = providers.Factory(entities.Movie) csv_finder = providers.Singleton( finders.CsvMovieFinder, movie_factory=movie.provider, path=config.finder.csv.path, delimiter=config.finder.csv.delimiter, )
У
CsvMovieFinder есть зависимость от фабрики Movie. CsvMovieFinder нуждается в фабрике так как будет создавать объекты Movie по мере того как будет читать данные из файла. Для того чтобы передать фабрику мы используем атрибут .provider. Это называется делегирование провайдеров. Если мы укажем фабрику movie как зависимость, она будет вызвана когда csv_finder будет создавать CsvMovieFinder и в качестве инъекции будет передан объект Movie. Используя атрибут .provider в качестве инъекции будет передам сам провайдер.У
csv_finder еще есть зависимость от нескольких опций конфигурации. Мы добавили провайдер Сonfiguration чтобы передать эти зависимости.Мы использовали параметры конфигурации перед тем как задали их значения. Это принцип, по которому работает провайдерConfiguration.
Сначала используем, потом задаем значения.
Теперь давайте добавим значения конфигурации.
Отредактируем
config.yml:finder: csv: path: "data/movies.csv" delimiter: ","
Значения установлены в конфигурационный файл. Обновим функцию
main() чтобы указать его расположение.Отредактируем
__main__.py:"""Main module.""" from .containers import ApplicationContainer def main(): container = ApplicationContainer() container.config.from_yaml('config.yml') if __name__ == '__main__': main()
Переходим к
listers.Создаем файл
listers.py в пакете movies:./ ├── data/ │ ├── fixtures.py │ ├── movies.csv │ └── movies.db ├── movies/ │ ├── __init__.py │ ├── __main__.py │ ├── containers.py │ ├── entities.py │ ├── finders.py │ └── listers.py ├── venv/ ├── config.yml └── requirements.txt
и добавляем внутрь следующие строки:
"""Movie listers module.""" from .finders import MovieFinder class MovieLister: def __init__(self, movie_finder: MovieFinder): self._movie_finder = movie_finder def movies_directed_by(self, director): return [ movie for movie in self._movie_finder.find_all() if movie.director == director ] def movies_released_in(self, year): return [ movie for movie in self._movie_finder.find_all() if movie.year == year ]
Обновляем
containers.py:"""Containers module.""" from dependency_injector import containers, providers from . import finders, listers, entities class ApplicationContainer(containers.DeclarativeContainer): config = providers.Configuration() movie = providers.Factory(entities.Movie) csv_finder = providers.Singleton( finders.CsvMovieFinder, movie_factory=movie.provider, path=config.finder.csv.path, delimiter=config.finder.csv.delimiter, ) lister = providers.Factory( listers.MovieLister, movie_finder=csv_finder, )
Все компоненты созданы и добавлены в контейнер.
В завершение обновляем функцию
main().Отредактируем
__main__.py:"""Main module.""" from .containers import ApplicationContainer def main(): container = ApplicationContainer() container.config.from_yaml('config.yml') lister = container.lister() print( 'Francis Lawrence movies:', lister.movies_directed_by('Francis Lawrence'), ) print( '2016 movies:', lister.movies_released_in(2016), ) if __name__ == '__main__': main()
Все готово. Теперь запустим приложение.
Выполним в терминале:
python -m movies
Вы увидите:
Francis Lawrence movies: [Movie(title='The Hunger Games: Mockingjay - Part 2', year=2015, director='Francis Lawrence')] 2016 movies: [Movie(title='Rogue One: A Star Wars Story', year=2016, director='Gareth Edwards'), Movie(title='The Jungle Book', year=2016, director='Jon Favreau')]
Наше приложение работает с базой данных фильмов в формате
csv. Нам нужно еще добавить поддержку формата sqlite. Разберемся с этим в следующем разделе.Работа с sqlite
В это разделе мы добавим другой тип
MovieFinder — SqliteMovieFinder.Отредактируем
finders.py:"""Movie finders module.""" import csv import sqlite3 from typing import Callable, List from .entities import Movie class MovieFinder: def __init__(self, movie_factory: Callable[..., Movie]) -> None: self._movie_factory = movie_factory def find_all(self) -> List[Movie]: raise NotImplementedError() class CsvMovieFinder(MovieFinder): def __init__( self, movie_factory: Callable[..., Movie], path: str, delimiter: str, ) -> None: self._csv_file_path = path self._delimiter = delimiter super().__init__(movie_factory) def find_all(self) -> List[Movie]: with open(self._csv_file_path) as csv_file: csv_reader = csv.reader(csv_file, delimiter=self._delimiter) return [self._movie_factory(*row) for row in csv_reader] class SqliteMovieFinder(MovieFinder): def __init__( self, movie_factory: Callable[..., Movie], path: str, ) -> None: self._database = sqlite3.connect(path) super().__init__(movie_factory) def find_all(self) -> List[Movie]: with self._database as db: rows = db.execute('SELECT title, year, director FROM movies') return [self._movie_factory(*row) for row in rows]
Добавляем провайдер
sqlite_finder в контейнер и указываем его в качестве зависимости для провайдера lister.Отредактируем
containers.py:"""Containers module.""" from dependency_injector import containers, providers from . import finders, listers, entities class ApplicationContainer(containers.DeclarativeContainer): config = providers.Configuration() movie = providers.Factory(entities.Movie) csv_finder = providers.Singleton( finders.CsvMovieFinder, movie_factory=movie.provider, path=config.finder.csv.path, delimiter=config.finder.csv.delimiter, ) sqlite_finder = providers.Singleton( finders.SqliteMovieFinder, movie_factory=movie.provider, path=config.finder.sqlite.path, ) lister = providers.Factory( listers.MovieLister, movie_finder=sqlite_finder, )
У провайдера
sqlite_finder есть зависимость от опций конфигурации, которые мы еще не определили. Обновим файл конфигурации:Отредактируем
config.yml:finder: csv: path: "data/movies.csv" delimiter: "," sqlite: path: "data/movies.db"
Готово. Давайте проверим.
Выполняем в терминале:
python -m movies
Вы увидите:
Francis Lawrence movies: [Movie(title='The Hunger Games: Mockingjay - Part 2', year=2015, director='Francis Lawrence')] 2016 movies: [Movie(title='Rogue One: A Star Wars Story', year=2016, director='Gareth Edwards'), Movie(title='The Jungle Book', year=2016, director='Jon Favreau')]
Наше приложение поддерживает оба формата базы данных:
csv и sqlite. Каждый раз когда нам нужно изменить формат нам приходится менять код в контейнере. Мы улучшим это в следующем разделе.Провайдер Selector
В этом разделе мы сделаем наше приложение более гибким.
Больше не нужно будет делать изменения в коде для переключения между
csv и sqlite форматами. Мы реализуем переключатель на базе переменной окружения MOVIE_FINDER_TYPE:- Когда
MOVIE_FINDER_TYPE=csvприложения использует форматcsv. - Когда
MOVIE_FINDER_TYPE=sqliteприложения использует форматsqlite.
В этом нам поможет провайдер
Selector. Он выбирает провайдер на основе опции конфигурации (документация).Отредактрируем
containers.py:"""Containers module.""" from dependency_injector import containers, providers from . import finders, listers, entities class ApplicationContainer(containers.DeclarativeContainer): config = providers.Configuration() movie = providers.Factory(entities.Movie) csv_finder = providers.Singleton( finders.CsvMovieFinder, movie_factory=movie.provider, path=config.finder.csv.path, delimiter=config.finder.csv.delimiter, ) sqlite_finder = providers.Singleton( finders.SqliteMovieFinder, movie_factory=movie.provider, path=config.finder.sqlite.path, ) finder = providers.Selector( config.finder.type, csv=csv_finder, sqlite=sqlite_finder, ) lister = providers.Factory( listers.MovieLister, movie_finder=finder, )
Мы создали провайдер
finder и указали его в качестве зависимости для провайдера lister. Провайдер finder выбирает между провайдерами csv_finder и sqlite_finder во время выполнения. Выбор зависит от значения переключателя.Переключателем является опция конфигурации
config.finder.type. Когда ее значение csv используется провайдер из ключа csv. Аналогично для sqlite.Теперь нам нужно считать значение
config.finder.type из переменной окружения MOVIE_FINDER_TYPE.Отредактируем
__main__.py:"""Main module.""" from .containers import ApplicationContainer def main(): container = ApplicationContainer() container.config.from_yaml('config.yml') container.config.finder.type.from_env('MOVIE_FINDER_TYPE') lister = container.lister() print( 'Francis Lawrence movies:', lister.movies_directed_by('Francis Lawrence'), ) print( '2016 movies:', lister.movies_released_in(2016), ) if __name__ == '__main__': main()
Готово.
Выполним в терминале следующие команды:
MOVIE_FINDER_TYPE=csv python -m movies MOVIE_FINDER_TYPE=sqlite python -m movies
Вывод при выполнении каждой команды будет выглядеть так:
Francis Lawrence movies: [Movie(title='The Hunger Games: Mockingjay - Part 2', year=2015, director='Francis Lawrence')] 2016 movies: [Movie(title='Rogue One: A Star Wars Story', year=2016, director='Gareth Edwards'), Movie(title='The Jungle Book', year=2016, director='Jon Favreau')]
В этом разделе познакомились с провайдером
Selector. C помощью этого провайдера можно делать приложение более гибким. Значение переключателя может быть задано из любого источника: конфигурационного файла, словаря, другого провайдера.Подсказка:
Переопределение значения конфигурации из другого провайдера позволяет реализовать перегрузку конфигурации в приложении без перезапуска, «на горячую».
Для этого нужно использовать делегирование провайдеров и метод.override().
В следующем разделе добавим несколько тестов.
Тесты
В завершение добавим несколько тестов.
Создаём файл
tests.py в пакете movies:./ ├── data/ │ ├── fixtures.py │ ├── movies.csv │ └── movies.db ├── movies/ │ ├── __init__.py │ ├── __main__.py │ ├── containers.py │ ├── entities.py │ ├── finders.py │ ├── listers.py │ └── tests.py ├── venv/ ├── config.yml └── requirements.txt
и добавляем в него следующие строки:
"""Tests module.""" from unittest import mock import pytest from .containers import ApplicationContainer @pytest.fixture def container(): container = ApplicationContainer() container.config.from_dict({ 'finder': { 'type': 'csv', 'csv': { 'path': '/fake-movies.csv', 'delimiter': ',', }, 'sqlite': { 'path': '/fake-movies.db', }, }, }) return container def test_movies_directed_by(container): finder_mock = mock.Mock() finder_mock.find_all.return_value = [ container.movie('The 33', 2015, 'Patricia Riggen'), container.movie('The Jungle Book', 2016, 'Jon Favreau'), ] with container.finder.override(finder_mock): lister = container.lister() movies = lister.movies_directed_by('Jon Favreau') assert len(movies) == 1 assert movies[0].title == 'The Jungle Book' def test_movies_released_in(container): finder_mock = mock.Mock() finder_mock.find_all.return_value = [ container.movie('The 33', 2015, 'Patricia Riggen'), container.movie('The Jungle Book', 2016, 'Jon Favreau'), ] with container.finder.override(finder_mock): lister = container.lister() movies = lister.movies_released_in(2015) assert len(movies) == 1 assert movies[0].title == 'The 33'
Теперь запустим тестирование и проверим покрытие:
pytest movies/tests.py --cov=movies
Вы увидите:
platform darwin -- Python 3.8.3, pytest-5.4.3, py-1.9.0, pluggy-0.13.1 plugins: cov-2.10.0 collected 2 items movies/tests.py .. [100%] ---------- coverage: platform darwin, python 3.8.3-final-0 ----------- Name Stmts Miss Cover ------------------------------------------ movies/__init__.py 0 0 100% movies/__main__.py 10 10 0% movies/containers.py 9 0 100% movies/entities.py 7 1 86% movies/finders.py 26 13 50% movies/listers.py 8 0 100% movies/tests.py 24 0 100% ------------------------------------------ TOTAL 84 24 71%
Мы использовали метод.override()провайдераfinder. Провайдер переопределяется моком. При обращении к провайдеруfinderтеперь будет возвращен переопределяющий мок.
Работа закончена. Теперь давайте подведем итоги.
Заключение
Мы построили консольное (CLI) приложение применяя принцип dependency injection. Мы использовали Dependency Injector в качестве dependency injection фреймворка.
Преимущество, которое вы получаете с Dependency Injector — это контейнер.
Контейнер начинает окупаться, когда вам нужно понять или изменить структуру приложения. С контейнером это легко, потому что все компоненты приложения и их зависимости определены явно и в одном месте:
"""Containers module.""" from dependency_injector import containers, providers from . import finders, listers, entities class ApplicationContainer(containers.DeclarativeContainer): config = providers.Configuration() movie = providers.Factory(entities.Movie) csv_finder = providers.Singleton( finders.CsvMovieFinder, movie_factory=movie.provider, path=config.finder.csv.path, delimiter=config.finder.csv.delimiter, ) sqlite_finder = providers.Singleton( finders.SqliteMovieFinder, movie_factory=movie.provider, path=config.finder.sqlite.path, ) finder = providers.Selector( config.finder.type, csv=csv_finder, sqlite=sqlite_finder, ) lister = providers.Factory( listers.MovieLister, movie_finder=finder, )
Контейнер как карта вашего приложения. Вы всегда знайте что от чего зависит.
PS: вопросы и ответы
В комментариях к прошлому руководству были заданы классные вопросы: «зачем это нужно?», «зачем нужен фреймворк?», «чем фреймворк помогает в реализации?».
Я подготовил ответы:
Что такое dependency injection?
- это принцип который уменьшает связывание (coupling) и увеличивает сцепление (cohesion)
Зачем мне применять dependency injection?
- твой код становится более гибким, понятным и лучше поддается тестированию
- у тебя меньше проблем когда тебе нужно понять как он работает или изменить его
Как мне начать применять dependency injection?
- ты начинаешь писать код следуя принципу dependency injection
- ты регистрируешь все компоненты и их зависимости в контейнере
- когда тебе нужен компонент, ты получаешь его из контейнера
Зачем мне для этого фреймворк?
- тебе нужен фреймворк для того чтобы не создавать свой. Код создания объектов будет дублироваться и его тяжело будет менять. Для того чтобы этого не было тебе нужен контейнер.
- фреймворк дает тебе контейнер и провайдеры
- провайдеры управляют временем жизни объектов. Тебе понадобятся фабрики, синглтоны и объекты конфигурации
- контейнер служит коллекцией провайдеров
Какаю цену я плачу?
- тебе нужно явно указывать зависимости в контейнере
- это дополнительная работа
- это начнет приносить дивиденды когда проект начнет расти
- или через 2 недели после его завершения (когда ты забудешь какие решения принимал и какова структура проекта)
Концепция Dependency Injector
В дополнение опишу концепцию Dependency Injector как фреймворка.
Dependency Injector основан на двух принципах:
- Явное лучше неявного (PEP20).
- Не делать никакой магии с вашим кодом.
Чем Dependency Injector отличается от другим фреймворков?
- Нет автоматического связывания. Фреймворк не делает автоматического связывания зависимостей. Не используется интроспекция, связывание по именам аргументов и / или типам. Потому что «явное лучше неявного (PEP20)».
- Не загрязняет код вашего приложения. Ваше приложение не знает о наличии Dependency Injector и не зависит от него. Никаких
@injectдекораторов, аннотаций, патчинга или других волшебных трюков.
Dependency Injector предлагает простой контракт:
- Вы показываете фреймворку как собирать объекты
- Фреймворк их собирает
Сила Dependency Injector в его простоте и прямолинейности. Это простой инструмент для реализации мощного принципа.
Что дальше?
Если вы заинтересовались, но сомневайтесь, моя рекомендация такая:
Попробуйте применить этот подход на протяжении 2-х месяцев. Он неинтуитивный. Нужно время чтобы привыкнуть и прочувствовать. Польза стает ощутимой, когда проект вырастает до 30+ компонентов в контейнере. Если не понравится — много не потеряйте. Если понравится — получите существенное преимущество.
- Узнайте больше о Dependency Injector на GitHub
- Ознакомтесь с документацией на Read the Docs
Буду рад фидбеку и отвечу на вопросы в комментариях.

