А вы знали что метрики покрытия вашего кода врут?
В 2003 году Дерик Ретанс (Derick Rethans) выпустил Xdebug 1.2. Впервые в экосистеме PHP появилась возможность собирать данные о покрытии кода. В 2004 году Себастьян Бергманн выпустил PHPUnit 2, где впервые это использовал. У разработчиков появилась возможность оценивать эффективность своих наборов тестов, используя отчеты о покрытии.
С тех пор функциональность перенесли в универсальный независимый компонент php-code-coverage. В качестве альтернативных драйверов появились PHPDBG и PCOV. Но фундаментально основной процесс для разработчиков за последние 16 лет не поменялся.
В августе 2020 года с релизом php-code-coverage 9.0 и связанных с ним релизов PHPUnit 9.3 и behat-code-coverage 5.0 стал доступен новый способ оценивать покрытие.
Большинство PHP-разработчиков знакомы с идеей автоматизированного тестирования кода. Идея покрытия кода тесно связана с автоматизированным тестированием и заключается в измерении процента кода, который был выполнен или, как говорят, «покрыт» тестами. Например, если есть следующий код:
То мы можем написать тест на PHPUnit как показано ниже:
После выполнения теста PHPUnit подтверждает, что в этом тривиальном примере мы достигли 100% покрытия:

В примере выше, однако, была небольшая потенциальная ошибка. Если $denominator равен 0, то мы получим ошибку деления на ноль. Исправим это и посмотрим, что произойдет:
Несмотря на то, что в строке 12 теперь используется тернарный оператор if/else (и мы даже не написали тест для проверки правильности нашей обработки нуля), отчёт сообщает нам, что у нас всё еще 100% покрытие кода.
Если часть строки покрыта тестом, то вся строка помечается как покрытая. Это может ввести в заблуждение!
При простом подсчете, выполнена строка или нет, в других конструкциях кода часто могут возникать те же проблемы, например:
Начиная с версии 2.3 Xdebug мог собирать не только знакомые построчные метрики, но и альтернативные метрики покрытия веток и путей. Пост в блоге Дерика, рассказывающий об этой функции, закончился печально известным заявлением:
После 5 лет ожидания этого таинственного «кого-то еще», я решил попробовать реализовать всё это сам. Большое спасибо Себастиану Бергману за то, что принял мои pull request.
Во всяком коде, кроме самого простейшего, есть места, где путь выполнения может расходиться на два или более пути. Это происходит в каждой точке принятия решения, например, при каждом if/else или while. Каждая «сторона» этих точек расхождения — это отдельная ветка. Если точки принятия решения нет, поток выполнения содержит только одну ветку.
Обратите внимание, что несмотря на использование метафоры дерева, ветка в этом контексте — это не то же самое, что ветка в системе контроля версий, не путайте их!
Когда включено покрытие веток и путей, HTML-отчет, сгенерированный с помощью php-code-coverage, в дополнение к обычному отчету о покрытии строк, включает дополнения для отображения покрытия веток и путей. Вот как выглядит покрытие ветки с использованием того же примера кода, что и ранее:

Как вы можете видеть, сводное поле в верхней части страницы сразу указывает на то, что, хотя у нас полное построчное покрытие, к покрытию веток и путей это не относится (пути подробно разбираются в следующем разделе).
Кроме того, строка 12 выделяется желтым цветом, чтобы указать, что покрытие для неё является неполным (строка с покрытием 0% будет отображаться, как обычно, красным).
Наконец, более внимательные могут заметить, что, в отличие от построчного покрытия, цветом выделено больше строк. Это связано с тем, что ветки вычисляются на основе потока выполнения внутри интерпретатора PHP. Первая ветка каждой функции начинается при входе в эту функцию. В этом и есть отличие от покрытия на основе строк, где только тело функции считается содержащим исполняемые строки, а само объявление функции считается неисполняемым.
Такие различия между тем, что интерпретатор PHP считает логически отдельной веткой кода, и ментальной моделью разработчика могут затруднить понимание метрик. Например, если бы вы спросили меня, сколько веток в calculatePercent(), я бы ответил что 2 (частный случай для 0 и общий случай). Однако, глядя на отчет php-code-coverage выше, эта однострочная функция на самом деле содержит… 4 ветки?!
Чтобы понять, что интерпретатор PHP имеет в виду, под основной веткой есть дополнительный отчет о покрытии. Он показывает расширенную версию отображения каждой ветки, что помогает эффективней определить скрытое в исходном коде. Выглядит это так:
Всё это пока не вполне очевидно, но уже можно понять, какие ветки есть в calculatePercent() на самом деле:
Мысленное сопоставление веток с отдельными частями исходного кода — это новый навык, требующий немного практики. Но делать это с легко читаемым и понимаемым кодом определенно легче. Если ваш код полон «умных» однострочников, в которых несколько частей логики сочетаются как в нашем примере, то стоит ожидать большей сложности по сравнению с кодом, где всё структурировано и записано в несколько строк, полностью соответствующие веткам. Та же логика, написанная в этом стиле, будет выглядеть так:
Если вы экспортируете отчёт о покрытии php-code-coverage в формате Clover для передачи его в другую систему, то при включенном покрытии на основе веток, данные будут записаны в ключи conditionals и coveredconditionals. Ранее (или если покрытие на основе веток не включено) экспортируемые значения всегда были равны нулю.
Пути — это возможные комбинации веток. В примере calculatePercent() есть два возможных пути, как было показано выше:

Однако часто количество путей больше, чем количество веток, например, в коде, который содержит много условных выражений и циклов. В следующем примере, взятом из php-code-coverage, 23 ветки, но на самом деле существует 65 различных вариантов путей выполнения функции:
Да, это означает что для 100% покрытия необходимо 65 тестов.
HTML-отчёт php-code-coverage, как и для веток, включает дополнительное представление для каждого пути. Оно показывает, какие из них покрыты тестом, а какие нет.
Включение покрытия путей дополнительно влияет на отображаемые метрики, а именно на оценку CRAP. В определении, опубликованном на crap4j.org, в качестве входных данных для расчета используется исторически недоступная в PHP метрика покрытия пути в процентах. Тогда как в PHP всегда использовался процент построчного покрытия. Для небольших функций с хорошим покрытием оценка CRAP, вероятно, останется прежней или даже уменьшится. А вот для функций с множеством путей выполнения и плохим покрытием значение значительно увеличится.
Покрытие веток и путей включается или отключается вместе, так как и те, и другие являются просто разными представлениями одних и тех же базовых данных о выполнении кода.
Для PHPUnit 9.3+ дополнительные метрики отключены по умолчанию и могут быть включены либо через командную строку, либо через файл конфигурации phpunit.xml, но только при работе под Xdebug. Попытка включить эту функцию при использовании PCOV или PHPDBG приведет к предупреждению о несовместимости конфигурации, и покрытие не будет собрано.
Для behat-code-cover 5.0+ настройка выполняется в behat.yml, атрибут называется branchAndPathCoverage. Если вы попытаетесь включить его при использовании драйвера, отличного от Xdebug, будет выдано предупреждение, но покрытие всё равно будет сгенерировано. Это сделано, чтобы упростить использование одного и того же файла конфигурации в разных средах. Если явной настройки нет, новое покрытие будет включено по умолчанию при работе под Xdebug.
Лично я (Doug Wright) буду использовать новые метрики всегда, когда это возможно. Я протестировал их на различном коде, чтобы понять, что является «нормой». На своих проектах, скорее всего, я буду использовать гибридный подход, который покажу далее. Для коммерческих проектов решение по переходу на новые метрики, очевидно, должно приниматься всей командой, и я с интересом жду шанса сравнить их выводы со своими.
100% покрытие на основе путей исполнения, несомненно, является святым Граалем, и там, где это разумно применять — это хорошая метрика, к которой нужно стремиться, даже если вы не достигните её. Если вы пишете тесты, вам всё равно следует думать о таких вещах, как граничные случаи. Покрытие на основе путей исполнения помогает удостовериться, что с этим всё хорошо.
Однако, если метод содержит десятки, сотни или даже тысячи путей (что на самом деле не редкость для достаточно сложных штук), я бы не стал тратить время на написание сотен тестов. Разумно остановиться на десятке. Тестирование — это не самоцель, а инструмент снижения рисков и инвестиция в будущее. Тесты должны окупаться, а время, потраченное на такое количество тестов вряд ли окупится. В таких ситуациях лучше стремиться к хорошему покрытию веток, поскольку это хотя бы гарантирует, что вы подумали о том, что происходит в каждой точке принятия решения.
В случаях большого количества путей (они с честным CRAP теперь отлично определяются), я оцениваю, не делает ли рассматриваемый код слишком много, и существует ли разумный способ разбить его на более мелкие функции (которые уже можно разобрать более детально)? Иногда нет, и это нормально — нам не нужно устранять абсолютно все риски проекта. Даже знать о них уже замечательно. Также важно помнить, что границы функций и их изолированное модульное тестирование — это искусственное разделение логики, а не истинная сложность вашего ПО в общем. Поэтому я бы рекомендовал не разбивать большие функции только из-за пугающего количества путей выполнения. Делайте это только там, где разделение снижает когнитивную нагрузку и помогает восприятию кода.
Да, производительность. Не секрет, что код под Xdebug работает невероятно медленно по сравнению с обычной производительностью PHP. А если включить покрытие веток и путей, то всё усугубляется из-за прибавки накладных расходов на все дополнительные данные по выполнению, которые ему теперь необходимо отслеживать.
Хорошая новость в том, что необходимость бороться с этими проблемами вдохновила разработчика на общие улучшения производительности внутри php-code-coverage, что принесет пользу всем, кто использует Xdebug. Производительность наборов тестов сильно различается, поэтому трудно судить, как это повлияет на каждый набор, но сбор покрытия на основе строк будет быстрее в любом случае.
Создание покрытия на основе веток и путей по-прежнему проходит примерно в 3-5 раз медленнее. Это нужно учитывать. Рассмотрите возможность выборочного включения для отдельных тестовых файлов, а не всего набора тестов, или ночной сборки с «улучшенным покрытием» вместо запуска каждый раз по push.
Xdebug 3 будет значительно быстрее, чем текущие версии, из-за работы, проделанной над модуляризацией и производительностью, поэтому эти предостережения следует рассматривать как относящиеся только к Xdebug 2. С версией 3, даже учитывая накладные расходы из-за сбора дополнительных данных, можно сгенерировать покрытие на основе веток и путей за меньшее время, чем требуется сегодня, чтобы получить построчное покрытие!

Пожалуйста, протестируйте новые возможности и напишите нам. Полезны ли они? Особенно интересны идеи по альтернативной визуализации (возможно, из других языков).
Ну и мне всегда интересно ваше мнение о том, что является нормальным уровнем покрытия кода.

В 2003 году Дерик Ретанс (Derick Rethans) выпустил Xdebug 1.2. Впервые в экосистеме PHP появилась возможность собирать данные о покрытии кода. В 2004 году Себастьян Бергманн выпустил PHPUnit 2, где впервые это использовал. У разработчиков появилась возможность оценивать эффективность своих наборов тестов, используя отчеты о покрытии.
С тех пор функциональность перенесли в универсальный независимый компонент php-code-coverage. В качестве альтернативных драйверов появились PHPDBG и PCOV. Но фундаментально основной процесс для разработчиков за последние 16 лет не поменялся.
В августе 2020 года с релизом php-code-coverage 9.0 и связанных с ним релизов PHPUnit 9.3 и behat-code-coverage 5.0 стал доступен новый способ оценивать покрытие.
Сегодня мы рассмотрим
- Краткий обзор основ
- Ограничения
- Альтернативные метрики
- Покрытие веток
- Покрытие путей
- Включаем новые метрики
- Какую метрику использовать?
- Есть ли причины не включать новые метрики?
- Итоги
Краткий обзор основ
Большинство PHP-разработчиков знакомы с идеей автоматизированного тестирования кода. Идея покрытия кода тесно связана с автоматизированным тестированием и заключается в измерении процента кода, который был выполнен или, как говорят, «покрыт» тестами. Например, если есть следующий код:
<?php
class PercentCalculator
{
public function __construct(int $numerator, int $denominator)
{
$this->numerator = $numerator;
$this->denominator = $denominator;
}
public function calculatePercent(): float
{
return round($this->numerator / $this->denominator * 100, 1);
}
}То мы можем написать тест на PHPUnit как показано ниже:
<?php
class PercentCalculatorTest extends PHPUnit\Framework\TestCase
{
public function testTwentyIntoForty(): void
{
$calculator = new PercentCalculator(20, 40);
self::assertEquals(50.0, $calculator->calculatePercent());
}
}После выполнения теста PHPUnit подтверждает, что в этом тривиальном примере мы достигли 100% покрытия:
Ограничения
В примере выше, однако, была небольшая потенциальная ошибка. Если $denominator равен 0, то мы получим ошибку деления на ноль. Исправим это и посмотрим, что произойдет:
<?php
class PercentCalculator
{
public function __construct(int $numerator, int $denominator)
{
$this->numerator = $numerator;
$this->denominator = $denominator;
}
public function calculatePercent(): float
{
// Можно было добавить валидацию значения,
// но именно такое исправление важно
// для последующего объяснения
return $this->denominator ? round($this->numerator / $this->denominator * 100, 1) : 0.0;
}
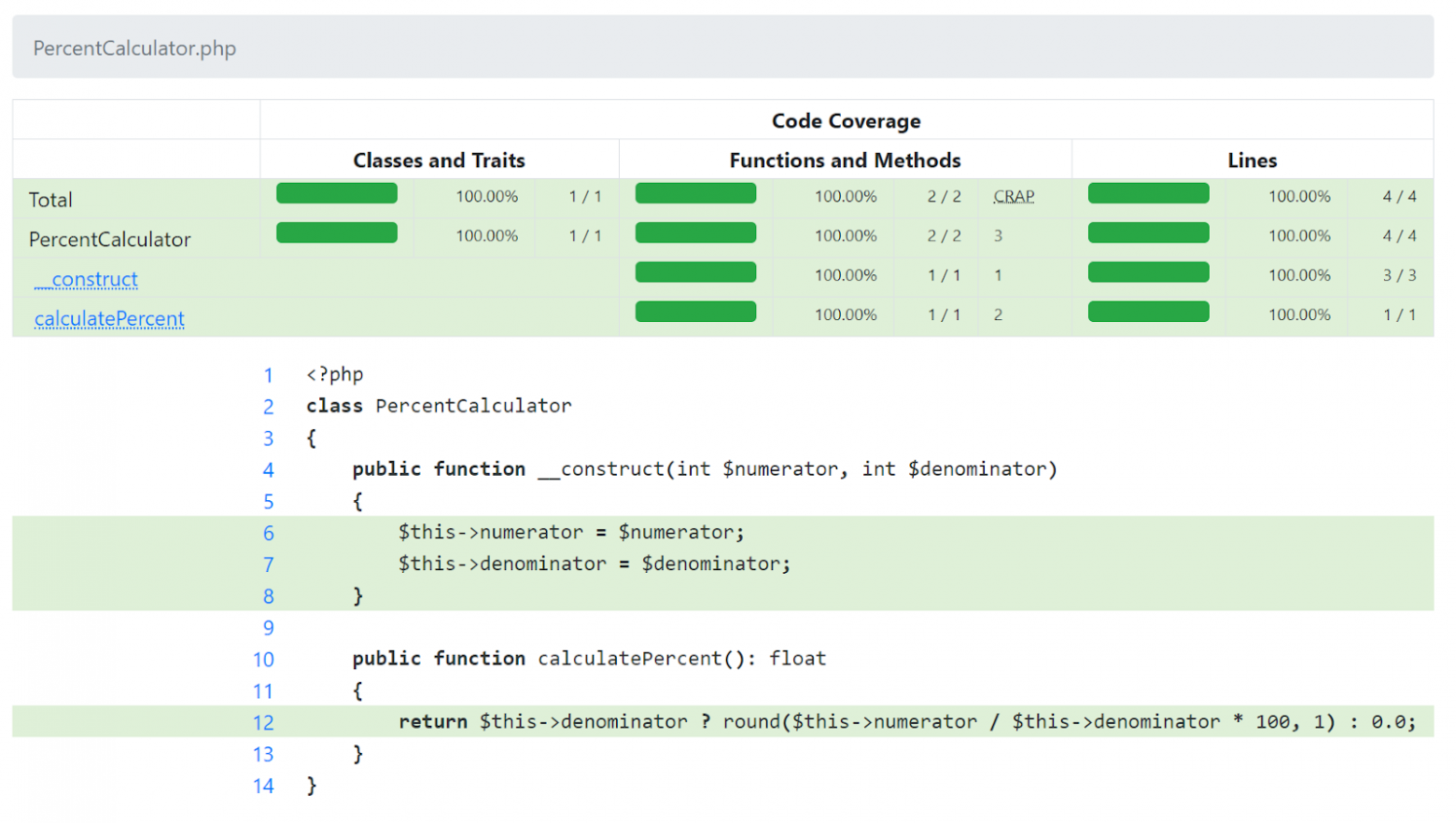
}Несмотря на то, что в строке 12 теперь используется тернарный оператор if/else (и мы даже не написали тест для проверки правильности нашей обработки нуля), отчёт сообщает нам, что у нас всё еще 100% покрытие кода.
Если часть строки покрыта тестом, то вся строка помечается как покрытая. Это может ввести в заблуждение!
При простом подсчете, выполнена строка или нет, в других конструкциях кода часто могут возникать те же проблемы, например:
if ($a || $b || $c) { // проверяем *одно* условие
doSomething(); // возможность выполнения будет считаться 100% покрытием
}
public function pluralise(string $thing, int $count): string
{
$string = $count . ' ' . $thing;
if ($count > 1) { // если проверяете только с $count >= 2, покрытие всё-равно 100%
$string .= 's'; // так как отдельного кода для $count === 1,
} // который можно пометить как не покрытый, нет
return $string;
}Альтернативные метрики
Начиная с версии 2.3 Xdebug мог собирать не только знакомые построчные метрики, но и альтернативные метрики покрытия веток и путей. Пост в блоге Дерика, рассказывающий об этой функции, закончился печально известным заявлением:
«Осталось подождать пока у Себастиана (или кого-то еще) появится время обновить PHP_CodeCoverage, чтобы тот показывал покрытие ветки и пути. Happy hacking!
Дерик Ретанс, январь 2015 г.»
После 5 лет ожидания этого таинственного «кого-то еще», я решил попробовать реализовать всё это сам. Большое спасибо Себастиану Бергману за то, что принял мои pull request.
Покрытие веток
Во всяком коде, кроме самого простейшего, есть места, где путь выполнения может расходиться на два или более пути. Это происходит в каждой точке принятия решения, например, при каждом if/else или while. Каждая «сторона» этих точек расхождения — это отдельная ветка. Если точки принятия решения нет, поток выполнения содержит только одну ветку.
Обратите внимание, что несмотря на использование метафоры дерева, ветка в этом контексте — это не то же самое, что ветка в системе контроля версий, не путайте их!
Когда включено покрытие веток и путей, HTML-отчет, сгенерированный с помощью php-code-coverage, в дополнение к обычному отчету о покрытии строк, включает дополнения для отображения покрытия веток и путей. Вот как выглядит покрытие ветки с использованием того же примера кода, что и ранее:
Как вы можете видеть, сводное поле в верхней части страницы сразу указывает на то, что, хотя у нас полное построчное покрытие, к покрытию веток и путей это не относится (пути подробно разбираются в следующем разделе).
Кроме того, строка 12 выделяется желтым цветом, чтобы указать, что покрытие для неё является неполным (строка с покрытием 0% будет отображаться, как обычно, красным).
Наконец, более внимательные могут заметить, что, в отличие от построчного покрытия, цветом выделено больше строк. Это связано с тем, что ветки вычисляются на основе потока выполнения внутри интерпретатора PHP. Первая ветка каждой функции начинается при входе в эту функцию. В этом и есть отличие от покрытия на основе строк, где только тело функции считается содержащим исполняемые строки, а само объявление функции считается неисполняемым.
Поиск веток
Такие различия между тем, что интерпретатор PHP считает логически отдельной веткой кода, и ментальной моделью разработчика могут затруднить понимание метрик. Например, если бы вы спросили меня, сколько веток в calculatePercent(), я бы ответил что 2 (частный случай для 0 и общий случай). Однако, глядя на отчет php-code-coverage выше, эта однострочная функция на самом деле содержит… 4 ветки?!
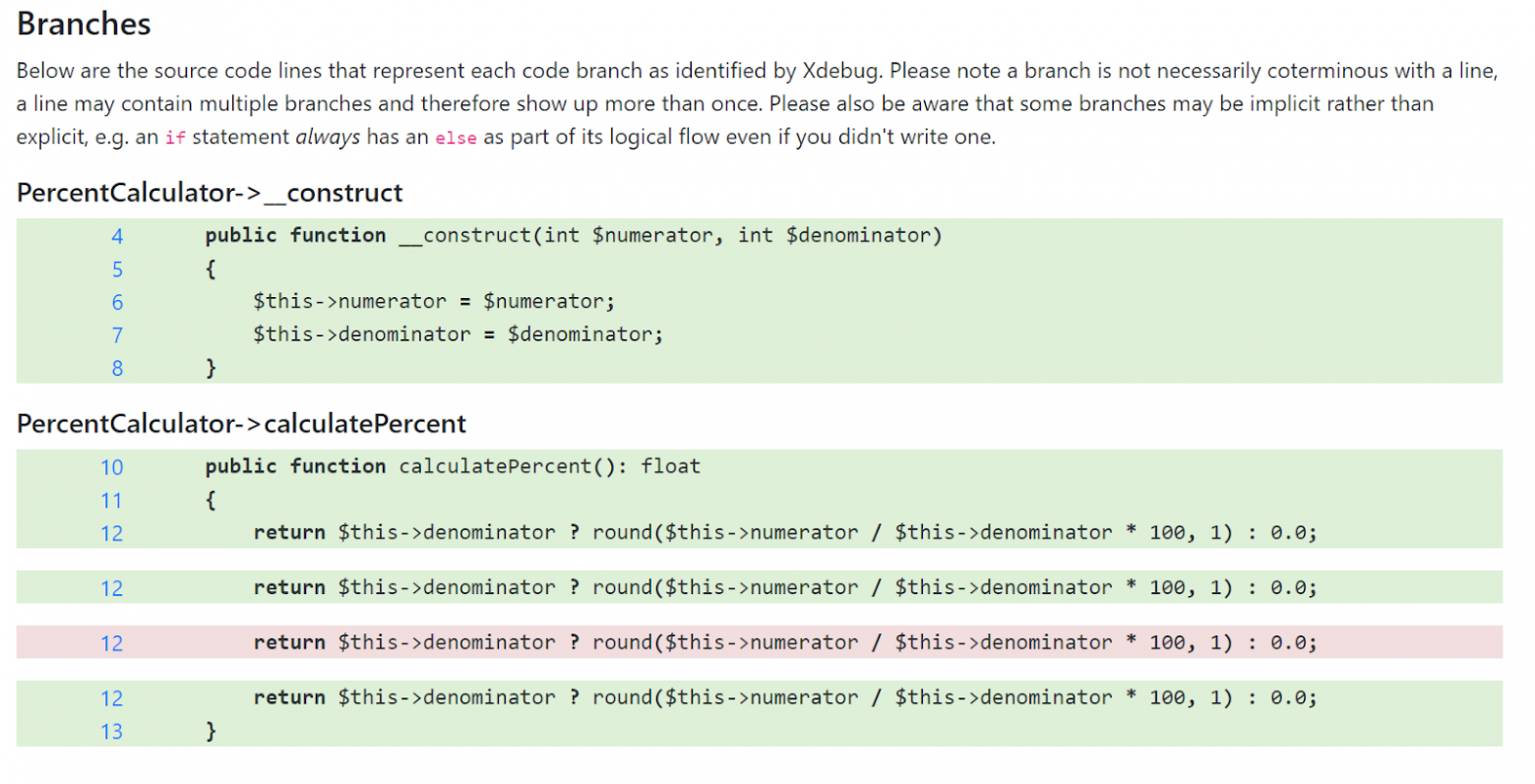
Чтобы понять, что интерпретатор PHP имеет в виду, под основной веткой есть дополнительный отчет о покрытии. Он показывает расширенную версию отображения каждой ветки, что помогает эффективней определить скрытое в исходном коде. Выглядит это так:
Подпись в шапке гласит: «Ниже приведены строки исходного кода, которые представляют каждую ветвь кода, найденную Xdebug. Обратите внимание, что ветвь не обязательно совпадает со строкой: строка может содержать несколько ветвей и, следовательно, отображаться более одного раза. Также имейте в виду, что некоторые ветки могут быть неявными, например, у оператора if всегда есть else в логическом потоке, даже если вы его не писали».
Всё это пока не вполне очевидно, но уже можно понять, какие ветки есть в calculatePercent() на самом деле:
- Ветка 1 начинается при входе в функцию и включает проверку $this->denominator;
- Затем выполнение разделяется на ветви 2 и 3 в зависимости от того, обрабатывается особый случай или нет;
- Ветка 4 — это место слияния веток 2 и 3. Она состоит из return и выхода из функции.
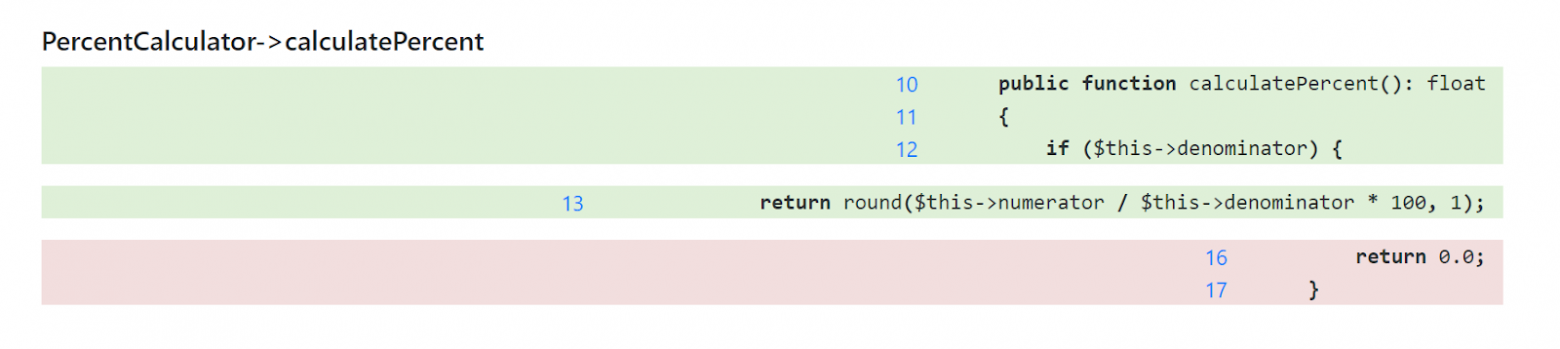
Мысленное сопоставление веток с отдельными частями исходного кода — это новый навык, требующий немного практики. Но делать это с легко читаемым и понимаемым кодом определенно легче. Если ваш код полон «умных» однострочников, в которых несколько частей логики сочетаются как в нашем примере, то стоит ожидать большей сложности по сравнению с кодом, где всё структурировано и записано в несколько строк, полностью соответствующие веткам. Та же логика, написанная в этом стиле, будет выглядеть так:
Clover
Если вы экспортируете отчёт о покрытии php-code-coverage в формате Clover для передачи его в другую систему, то при включенном покрытии на основе веток, данные будут записаны в ключи conditionals и coveredconditionals. Ранее (или если покрытие на основе веток не включено) экспортируемые значения всегда были равны нулю.
Покрытие путей
Пути — это возможные комбинации веток. В примере calculatePercent() есть два возможных пути, как было показано выше:
- Ветвь 1, затем ветвь 2, а затем ветвь 4;
- Ветвь 1, затем ветвь 3, а затем ветвь 4.
Однако часто количество путей больше, чем количество веток, например, в коде, который содержит много условных выражений и циклов. В следующем примере, взятом из php-code-coverage, 23 ветки, но на самом деле существует 65 различных вариантов путей выполнения функции:
final class File extends AbstractNode
{
public function numberOfTestedMethods(): int
{
if ($this->numTestedMethods === null) {
$this->numTestedMethods = 0;
foreach ($this->classes as $class) {
foreach ($class['methods'] as $method) {
if ($method['executableLines'] > 0 &&
$method['coverage'] === 100) {
$this->numTestedMethods++;
}
}
}
foreach ($this->traits as $trait) {
foreach ($trait['methods'] as $method) {
if ($method['executableLines'] > 0 &&
$method['coverage'] === 100) {
$this->numTestedMethods++;
}
}
}
}
return $this->numTestedMethods;
}
}Если не получается найти все 23 ветки, вспомните что foreach может принимать пустой итератор, а также в if всегда есть невидимый else.
Да, это означает что для 100% покрытия необходимо 65 тестов.
HTML-отчёт php-code-coverage, как и для веток, включает дополнительное представление для каждого пути. Оно показывает, какие из них покрыты тестом, а какие нет.
CRAP
Включение покрытия путей дополнительно влияет на отображаемые метрики, а именно на оценку CRAP. В определении, опубликованном на crap4j.org, в качестве входных данных для расчета используется исторически недоступная в PHP метрика покрытия пути в процентах. Тогда как в PHP всегда использовался процент построчного покрытия. Для небольших функций с хорошим покрытием оценка CRAP, вероятно, останется прежней или даже уменьшится. А вот для функций с множеством путей выполнения и плохим покрытием значение значительно увеличится.
Включаем новые метрики
Покрытие веток и путей включается или отключается вместе, так как и те, и другие являются просто разными представлениями одних и тех же базовых данных о выполнении кода.
PHPUnit
Для PHPUnit 9.3+ дополнительные метрики отключены по умолчанию и могут быть включены либо через командную строку, либо через файл конфигурации phpunit.xml, но только при работе под Xdebug. Попытка включить эту функцию при использовании PCOV или PHPDBG приведет к предупреждению о несовместимости конфигурации, и покрытие не будет собрано.
- В консоли используйте опцию --path-coverage: vendor/bin/phpunit — path-coverage.
- В phpunit.xml установите в элементе coverage атрибут pathCoverage в true.
<?xml version="1.0" encoding="UTF-8"?>
<phpunit xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="https://schema.phpunit.de/9.3/phpunit.xsd">
<testsuites>
<testsuite name="default">
<directory>tests</directory>
</testsuite>
</testsuites>
<coverage pathCoverage="true" processUncoveredFiles="true" cacheDirectory="build/phpunit/cache">
<include>
<directory suffix=".php">src</directory>
</include>
<report>
<text outputFile="php://stdout"/>
<html outputDirectory="build/coverage"/>
</report>
</coverage>
</phpunit>В PHPUnit 9.3 был серьёзно изменён формат файла конфигурации, так что структура выше, вероятно, выглядит иначе, чем вы привыкли.
behat-code-coverage
Для behat-code-cover 5.0+ настройка выполняется в behat.yml, атрибут называется branchAndPathCoverage. Если вы попытаетесь включить его при использовании драйвера, отличного от Xdebug, будет выдано предупреждение, но покрытие всё равно будет сгенерировано. Это сделано, чтобы упростить использование одного и того же файла конфигурации в разных средах. Если явной настройки нет, новое покрытие будет включено по умолчанию при работе под Xdebug.
Какую метрику использовать?
Лично я (Doug Wright) буду использовать новые метрики всегда, когда это возможно. Я протестировал их на различном коде, чтобы понять, что является «нормой». На своих проектах, скорее всего, я буду использовать гибридный подход, который покажу далее. Для коммерческих проектов решение по переходу на новые метрики, очевидно, должно приниматься всей командой, и я с интересом жду шанса сравнить их выводы со своими.
Моё мнение
100% покрытие на основе путей исполнения, несомненно, является святым Граалем, и там, где это разумно применять — это хорошая метрика, к которой нужно стремиться, даже если вы не достигните её. Если вы пишете тесты, вам всё равно следует думать о таких вещах, как граничные случаи. Покрытие на основе путей исполнения помогает удостовериться, что с этим всё хорошо.
Однако, если метод содержит десятки, сотни или даже тысячи путей (что на самом деле не редкость для достаточно сложных штук), я бы не стал тратить время на написание сотен тестов. Разумно остановиться на десятке. Тестирование — это не самоцель, а инструмент снижения рисков и инвестиция в будущее. Тесты должны окупаться, а время, потраченное на такое количество тестов вряд ли окупится. В таких ситуациях лучше стремиться к хорошему покрытию веток, поскольку это хотя бы гарантирует, что вы подумали о том, что происходит в каждой точке принятия решения.
В случаях большого количества путей (они с честным CRAP теперь отлично определяются), я оцениваю, не делает ли рассматриваемый код слишком много, и существует ли разумный способ разбить его на более мелкие функции (которые уже можно разобрать более детально)? Иногда нет, и это нормально — нам не нужно устранять абсолютно все риски проекта. Даже знать о них уже замечательно. Также важно помнить, что границы функций и их изолированное модульное тестирование — это искусственное разделение логики, а не истинная сложность вашего ПО в общем. Поэтому я бы рекомендовал не разбивать большие функции только из-за пугающего количества путей выполнения. Делайте это только там, где разделение снижает когнитивную нагрузку и помогает восприятию кода.
Есть ли причины не включать новые метрики?
Да, производительность. Не секрет, что код под Xdebug работает невероятно медленно по сравнению с обычной производительностью PHP. А если включить покрытие веток и путей, то всё усугубляется из-за прибавки накладных расходов на все дополнительные данные по выполнению, которые ему теперь необходимо отслеживать.
Хорошая новость в том, что необходимость бороться с этими проблемами вдохновила разработчика на общие улучшения производительности внутри php-code-coverage, что принесет пользу всем, кто использует Xdebug. Производительность наборов тестов сильно различается, поэтому трудно судить, как это повлияет на каждый набор, но сбор покрытия на основе строк будет быстрее в любом случае.
Создание покрытия на основе веток и путей по-прежнему проходит примерно в 3-5 раз медленнее. Это нужно учитывать. Рассмотрите возможность выборочного включения для отдельных тестовых файлов, а не всего набора тестов, или ночной сборки с «улучшенным покрытием» вместо запуска каждый раз по push.
Xdebug 3 будет значительно быстрее, чем текущие версии, из-за работы, проделанной над модуляризацией и производительностью, поэтому эти предостережения следует рассматривать как относящиеся только к Xdebug 2. С версией 3, даже учитывая накладные расходы из-за сбора дополнительных данных, можно сгенерировать покрытие на основе веток и путей за меньшее время, чем требуется сегодня, чтобы получить построчное покрытие!
Тесты провёл Sebastian Bergmann, график построил Derick Rethans
Итоги
Пожалуйста, протестируйте новые возможности и напишите нам. Полезны ли они? Особенно интересны идеи по альтернативной визуализации (возможно, из других языков).
Ну и мне всегда интересно ваше мнение о том, что является нормальным уровнем покрытия кода.
На PHP Russia 29 ноября мы обсудим все самые важные вопросы по PHP-разработке, о том, чего нет в документации, но что даст новый уровень вашему коду.
Присоединяйтесь к нам на конференции: не только послушать доклады и задать вопросы лучшим спикерам PHP-вселенной, но и для профессионального общения (наконец в оффлайне!) в теплой атмосфере. Наши сообщества: Telegram, Facebook, VKontakte, YouTube.

