
В Сбере есть несколько практик Oracle, которые могут оказаться вам полезны. Думаю, часть вам знакома, но мы используем для загрузки не только ETL-средства, но и хранимые процедуры Oracle. На Oracle PL/SQL реализованы наиболее сложные алгоритмы загрузки данных в хранилища, где требуется «прочувствовать каждый байт».
На некоторых базах данных Oracle в Сбере стоит триггер на компиляцию, который запоминает, кто, когда и что менял в коде серверных объектов. Тем самым из таблицы журнала компиляций можно установить автора изменений. Также автоматически реализуется система контроля версий. Во всяком случае, если программист забыл сдать изменения в Git, то этот механизм его подстрахует. Опишем пример реализации такой системы автоматического журналирования компиляций. Один из упрощённых вариантов триггера на компиляцию, пишущего в журнал в виде таблицы ddl_changes_log, выглядит так:
В этом триггере получают название и новое содержимое компилируемого объекта, дополняют его предыдущим содержимым из словаря данных и записывают в лог изменений.
Такое желание может часто посещать разработчика на Oracle. Почему можно сделать процедуру или функцию с параметрами, но не бывает вьюшек с входными параметрами, которые можно использовать при вычислениях? В Oracle есть чем заменить это недостающее, на наш взгляд, понятие.
Рассмотрим пример. Пусть есть таблица с продажами по подразделениям за каждый день.
Такой запрос сравнивает продажи по подразделениям за два дня. В данном случае, 30.04.2020 и 11.09.2020.
Вот вьюшка, которую хочется написать для обобщения такого запроса. Хочется передавать даты в качестве параметров. Однако синтаксис не позволяет такое сделать.
Предлагается такое обходное решение. Создадим тип под строку из этой вьюшки.
И создадим тип под таблицу из таких строк.
Вместо вьюшки напишем pipelined функцию с входными параметрами-датами.
Обращаться к ней можно так:
Этот запрос и выдаст нам такой же результат, как запрос в начале этой заметки с явным образом подставленными датами.
Pipelined функции могут быть также полезны, если нужно передать параметр внутрь сложного запроса.
Например, рассмотрим с��ожную вьюшку, в которой поле field1, по которому хочется отфильтровать данные, запрятано где-то глубоко во вьюшке.
И запрос из вьюшки с фиксированным значением field1 может иметь плохой план выполнения.
Т.е. вместо того, чтобы сначала отфильтровать deep_table по условию field1 = 'myvalue', запрос может сначала соединить все таблицы, обработав излишне большой объём данных, а потом уже фильтровать результат по условию field1 = 'myvalue'. Такой сложности можно избежать, если сделать вместо вьюшки pipelined функцию с параметром, значение которого присваивается полю field1.
Бывает, что один и тот же запрос в БД Oracle обрабатывает всякий раз различный объём данных в использующихся в нём таблицах и подзапросах. Как заставить оптимизатор всякий раз понимать, какой из способов соединения таблиц на этот раз лучше и какие индексы использовать? Рассмотрим, например, запрос, который соединяет порцию изменившихся с последней загрузки остатков по счетам со справочником счетов. Порция изменившихся остатков по счетам сильно меняется от загрузки к загрузке, составляя то сотни строк, то миллионы строк. В зависимости от размера этой порции требуется соединять изменившиеся остатки со счетами то способом /*+ use_nl*/, то способом /*+ use_hash*/. Всякий раз повторно собирать статистику неудобно, особенно, если от загрузки к загрузке изменяется количество строк не в соединяемой таблице, а в соединяемом подзапросе. На помощь тут может прийти хинт /*+ dynamic_sampling()*/. Покажем, как он влияет, на примере запроса. Пусть таблица change_balances содержит изменения остатков, а accounts – справочник счетов. Соединяем эти таблицы по полям account_id, имеющимся в каждой из таблиц. В начале эксперимента запишем в эти таблицы побольше строк и не будем менять их содержимое.
Сначала возьмём 10% изменений остатков в таблице change_balances и посмотрим, какой план будет с использованием dynamic_sampling:
Итак, видим, что предлагается пройти таблицы change_balances и accounts с помощью full scan и соединить их посредством hash join.
Теперь резко уменьшим выборку из change_balances. Возьмём 0.1% изменений остатков и посмотрим, какой план будет с использованием dynamic_sampling:
На этот раз к таблице change_balances таблица accounts присоединяется посредством nested loops и используется индекс для чтения строк из accounts.
Если же хинт dynamic_sampling убрать, то во втором случае план останется такой же, как в первом случае, и это не оптимально.
Подробности о хинте dynamic_sampling и возможных значениях его числового аргумента можно найти в документации.
Решаем такую задачу. На сервере-источнике данных имеются таблицы, которые нужно соединить и загрузить в хранилище данных. Допустим, на сервере-источнике написана вьюшка, которая содержит в себе всю нужную ETL-логику преобразований. Вьюшка написана оптимально, в ней указаны хинты оптимизатору, подсказывающие, как соединять таблицы и какие индексы использовать. На стороне сервера хранилища данных нужно сделать несложную вещь – вставить данные из вьюшки в целевую таблицу. И тут могут возникнуть сложности. Если вставку в целевую таблицу осуществить командой вида
, то вся логика плана запроса, содержащаяся во вьюшке, из которой читаем данные по database link, может быть проигнорирована. Все хинты, зашитые в этой вьюшке могут быть не учтены.
Чтобы сохранить план запроса во вьюшке, можно воспользоваться вставкой данных в целевую таблицу из курсора:
Запрос из курсора
в отличие от вставки
сохранит план запроса, заложенный во вьюшку на сервере-источнике.
Часто стоит задача запустить из некоторой родительской процедуры несколько параллельных расчётов и, дождавшись завершения каждого из них, продолжить выполнение родительской процедуры. Это может быть полезно при параллельных вычислениях, если ресурсы сервера позволяют это. Есть много способов сделать это.
Опишем очень простой вариант реализации такого механизма. Параллельные процедуры будем выполнять в параллельных “одноразовых” джобах, родительская же процедура в цикле будет ожидать завершения всех этих джобов.
Создадим таблицы с метаданными для этого механизма. Для начала сделаем таблицу с группами параллельно запускаемых процедур:
Далее создадим таблицу со скриптами, которые будут параллельно выполняться в группах. Наполнение этой таблицы может быть как статическим, так и создаваться динамически:
И сделаем таблицу журнала, где будем собирать лог того, какая процедура когда в каком джобе запускалась:
Теперь приведём код процедуры по запуску параллельных потоков:
Проверим, как работает процедура run_in_parallel. Создадим тестовую процедуру, которую будем вызывать в параллельных сессиях.
Заполним название группы и таблицу со cкриптами, которые будут выполняться параллельно.
Запустим группу параллельных процедур.
По завершении посмотрим лог.
Видим, что время выполнения экземпляров тестовой процедуры соответствует ожиданиям.
Опишем вариант решения достаточно типовой банковской задачи по “протягиванию остатков”. Допустим, имеется таблица фактов изменения остатков по счетам. Требуется на каждый день календаря указать актуальный остаток по счёту (последний за день). Такая информация часто бывает нужна в хранилищах данных. Если в какой-то день не было движений по счёту, то нужно повторить последний известный остаток. Если объёмы данных и вычислительные мощности сервера позволяют, то можно решить такую задачу с помощью SQL-запроса, даже не прибегая к PL/SQL. Поможет нам в этом функция last_value(* ignore nulls) over(partition by * order by *), которая протянет последний известный остаток на последующие даты, в которых не было изменений.
Создадим таблицу и заполним её тестовыми данными.
Нижеприведённый запрос решает нашу задачу. Подзапрос ‘cld’ содержит календарь дат, в подзапросе ‘ab’ группируем остатки за каждый день, в подзапросе ‘a’ запоминаем перечень всех счетов и дату начала истории по каждому счёту, в подзапросе ‘pre’ для каждого счёта составляем календарь дней с начала его истории. Финальный запрос присоединяет к календарю дней активности каждого счёта последние остатки на каждый день и протягивает их на дни, в которых не было изменений.
Результат запроса соответствует ожиданиям.
При загрузке данных в хранилища часто решается задача, когда нужно выстроить единую историю по сущности, имея отдельные истории атрибутов этой сущности, пришедшие из различных источников. Допустим, имеется некоторая сущность с первичным ключом primary_key_id, о которой известна история (start_dt — end_dt) трёх её различных атрибутов, расположенная в трёх различных таблицах.
Целью является загрузка единой истории изменения трёх атрибутов в одну таблицу.
Ниже приведён запрос, решающий такую задачу. В нём сначала формируется диагональная таблица q1 с данными из разных источников по разным атрибутам (отсутствующие в источнике атрибуты заполняются null-ами). Затем с помощью функции last_value(* ignore nulls) диагональная таблица схлопывается в единую историю, а последние известные значения атрибутов протягиваются вперёд на те даты, в которые изменений по ним не было:
Результат получается такой:
Иногда встаёт задача о нормализации данных, пришедших в формате поля с разделителями. Например, в виде такой таблицы:
Такой запрос нормализует данные, расклеив соединённые запятой поля в виде нескольких строк:
Результат получается такой:
Часто возникает желание как-то визуализировать числовые показатели, хранящиеся в базе данных. Например, построить графики, гистограммы, диаграммы. В этом могут помочь специализированные средства, например, Oracle BI. Но лицензии на эти средства могут стоить денег, а настройка их может занять больше времени, чем написание “на коленке” SQL-запроса к Oracle, который выдаст готовую картинку. Продемонстрируем на примере, как с помощью запроса быстро нарисовать такую картинку в формате SVG.
Предположим, у нас есть таблица с данными
dt – это дата актуальности,
val – это числовой показатель, динамику которого по времени мы визуализируем,
radius – это ещё один числовой показатель, который будем рисовать в виде кружка с таким радиусом.
Скажем пару слов о формате SVG. Это формат векторной графики, который можно смотреть в современных браузерах и конвертировать в другие графические форматы. В нём, среди прочего, можно рисовать линии, кружки и писать текст:
Ниже SQL-запрос к Oracle, который строит график из данных в этой таблице. Здесь подзапрос const содержит различные константные настройки – размеры картинки, количество меток на осях графика, цвета линий и кружочков, размеры шрифта и т.д. В подзапросе gd1 мы приводим данные из таблицы graph_data к координатам x и y на рисунке. Подзапрос gd2 запоминает предыдущие по времени точки, из которых нужно вести линии к новым точкам. Блок ‘header’ – это заголовок картинки с белым фоном. Блок ‘vertical lines’ рисует вертикальные линии. Блок ‘dates under vertical lines’ подписывает даты на оси x. Блок ‘horizontal lines’ рисует горизонтальные линии. Блок ‘values near horizontal lines’ подписывает значения на оси y. Блок ‘circles’ рисует кружочки указанного в таблице graph_data радиуса. Блок ‘graph data’ строит из линий график динамики показателя val из таблицы graph_data. Блок ‘footer’ добавляет замыкающий тэг.
Результат запроса можно сохранить в файл с расширением *.svg и посмотреть в браузере. При желании можно с помощью какой-либо из утилит конвертировать его в другие графические форматы, размещать на веб-страницах своего приложения и т.д.
Получилась такая картинка:
Представьте себе, что стоит задача найти что-либо в исходном коде на Oracle, поискав информацию сразу на нескольких серверах. Речь идёт о поиске по объектам словаря данных Oracle. Рабочим местом для поиска является веб-интерфейс, куда пользователь-программист вводит искомую строку и выбирает галочками, на каких серверах Oracle осуществить этот поиск.
Веб-поисковик умеет искать строку по серверным объектам Oracle одновременно в нескольких различных базах данных банка. Например, можно поискать:
По результатам поиска пользователю выдаётся информация, на каком сервере в коде каких функций, процедур, пакетов, триггеров, вьюшек и т.п. найдены требуемые результаты.
Опишем, как реализован такой поисковик.
Клиентская часть не сложная. Веб-интерфейс получает введённую пользователем поисковую строку, список серверов для поиска и логин пользователя. Веб-страница передаёт их в хранимую процедуру Oracle на сервере-обработчике. История обращений к поисковику, т.е. кто какой запрос выполнял, на всякий случай журналируется.
Получив поисковый запрос, серверная часть на поисковом сервере Oracle запускает в параллельных джобах несколько процедур, которые по database links на выбранных серверах Oracle сканируют следующие представления словаря данных в поисках искомой строки: dba_col_comments, dba_jobs, dba_mviews, dba_objects, dba_scheduler_jobs, dba_source, dba_tab_cols, dba_tab_comments, dba_views. Каждая из процедур, если что-то обнаружила, записывает найденное в таблицу результатов поиска (с соответствующим ID поискового запроса).
Когда все поисковые процедуры завершили работу, клиентская часть выдаёт пользователю всё, что записалось в таблицу результатов поиска с соответствующим ID поискового запроса.
Но это ещё не всё. Помимо поиска по словарю данных Oracle в описанный механизм прикрутили ещё и поиск по репозиторию Informatica PowerCenter. Informatica PowerCenter является популярным ETL-средством, использующимся в Сбербанке при загрузке различной информации в хранилища данных. Informatica PowerCenter имеет открытую хорошо задокументированную структуру репозитория. По этому репозиторию есть возможность искать информацию так же, как и по словарю данных Oracle. Какие таблицы и поля используются в коде загрузок, разработанном на Informatica PowerCenter? Что можно найти в трансформациях портов и явных SQL-запросах? Вся эта информация имеется в структурах репозитория и может быть найдена. Для знатоков PowerCenter напишу, что наш поисковик сканирует следующие места репозитория в поисках маппингов, сессий или воркфловов, содержащих в себе где-то искомую строку: sql override, mapplet attributes, ports, source definitions in mappings, source definitions, target definitions in mappings, target_definitions, mappings, mapplets, workflows, worklets, sessions, commands, expression ports, session instances, source definition fields, target definition fields, email tasks.
- Автоматическое журналирование компиляций
- Как быть, если хочется сделать вьюшку с параметрами
- Использование динамической статистики в запросах
- Как сохранить план запроса при вставке данных через database link
- Запуск процедур в параллельных сессиях
- Протягивание остатков
- Объединение нескольких историй в одну
- Нормалайзер
- Визуализация в формате SVG
- Приложение поиска по метаданным Oracle
Автоматическое журналирование компиляций
На некоторых базах данных Oracle в Сбере стоит триггер на компиляцию, который запоминает, кто, когда и что менял в коде серверных объектов. Тем самым из таблицы журнала компиляций можно установить автора изменений. Также автоматически реализуется система контроля версий. Во всяком случае, если программист забыл сдать изменения в Git, то этот механизм его подстрахует. Опишем пример реализации такой системы автоматического журналирования компиляций. Один из упрощённых вариантов триггера на компиляцию, пишущего в журнал в виде таблицы ddl_changes_log, выглядит так:
create table DDL_CHANGES_LOG
(
id INTEGER,
change_date DATE,
sid VARCHAR2(100),
schemaname VARCHAR2(30),
machine VARCHAR2(100),
program VARCHAR2(100),
osuser VARCHAR2(100),
obj_owner VARCHAR2(30),
obj_type VARCHAR2(30),
obj_name VARCHAR2(30),
previous_version CLOB,
changes_script CLOB
);
create or replace trigger trig_audit_ddl_trg
before ddl on database
declare
v_sysdate date;
v_valid number;
v_previous_obj_owner varchar2(30) := '';
v_previous_obj_type varchar2(30) := '';
v_previous_obj_name varchar2(30) := '';
v_previous_change_date date;
v_lob_loc_old clob := '';
v_lob_loc_new clob := '';
v_n number;
v_sql_text ora_name_list_t;
v_sid varchar2(100) := '';
v_schemaname varchar2(30) := '';
v_machine varchar2(100) := '';
v_program varchar2(100) := '';
v_osuser varchar2(100) := '';
begin
v_sysdate := sysdate;
-- find whether compiled object already presents and is valid
select count(*)
into v_valid
from sys.dba_objects
where owner = ora_dict_obj_owner
and object_type = ora_dict_obj_type
and object_name = ora_dict_obj_name
and status = 'VALID'
and owner not in ('SYS', 'SPOT', 'WMSYS', 'XDB', 'SYSTEM')
and object_type in ('TRIGGER', 'PROCEDURE', 'FUNCTION', 'PACKAGE', 'PACKAGE BODY', 'VIEW');
-- find information about previous compiled object
select max(obj_owner) keep(dense_rank last order by id),
max(obj_type) keep(dense_rank last order by id),
max(obj_name) keep(dense_rank last order by id),
max(change_date) keep(dense_rank last order by id)
into v_previous_obj_owner, v_previous_obj_type, v_previous_obj_name, v_previous_change_date
from ddl_changes_log;
-- if compile valid object or compile invalid package body broken by previous compilation of package then log it
if (v_valid = 1 or v_previous_obj_owner = ora_dict_obj_owner and
(v_previous_obj_type = 'PACKAGE' and ora_dict_obj_type = 'PACKAGE BODY' or
v_previous_obj_type = 'PACKAGE BODY' and ora_dict_obj_type = 'PACKAGE') and
v_previous_obj_name = ora_dict_obj_name and
v_sysdate - v_previous_change_date <= 1 / 24 / 60 / 2) and
ora_sysevent in ('CREATE', 'ALTER') then
-- store previous version of object (before compilation) from dba_source or dba_views in v_lob_loc_old
if ora_dict_obj_type <> 'VIEW' then
for z in (select substr(text, 1, length(text) - 1) || chr(13) || chr(10) as text
from sys.dba_source
where owner = ora_dict_obj_owner
and type = ora_dict_obj_type
and name = ora_dict_obj_name
order by line) loop
v_lob_loc_old := v_lob_loc_old || z.text;
end loop;
else
select sys.dbms_metadata_util.long2clob(v.textlength, 'SYS.VIEW$', 'TEXT', v.rowid) into v_lob_loc_old
from sys."_CURRENT_EDITION_OBJ" o, sys.view$ v, sys.user$ u
where o.obj# = v.obj#
and o.owner# = u.user#
and u.name = ora_dict_obj_owner
and o.name = ora_dict_obj_name;
end if;
-- store new version of object (after compilation) from v_sql_text in v_lob_loc_new
v_n := ora_sql_txt(v_sql_text);
for i in 1 .. v_n loop
v_lob_loc_new := v_lob_loc_new || replace(v_sql_text(i), chr(10), chr(13) || chr(10));
end loop;
-- find information about session that changed this object
select max(to_char(sid)), max(schemaname), max(machine), max(program), max(osuser)
into v_sid, v_schemaname, v_machine, v_program, v_osuser
from v$session
where audsid = userenv('sessionid');
-- store changes in ddl_changes_log
insert into ddl_changes_log
(id, change_date, sid, schemaname, machine, program, osuser,
obj_owner, obj_type, obj_name, previous_version, changes_script)
values
(seq_ddl_changes_log.nextval, v_sysdate, v_sid, v_schemaname, v_machine, v_program, v_osuser,
ora_dict_obj_owner, ora_dict_obj_type, ora_dict_obj_name, v_lob_loc_old, v_lob_loc_new);
end if;
exception
when others then
null;
end;В этом триггере получают название и новое содержимое компилируемого объекта, дополняют его предыдущим содержимым из словаря данных и записывают в лог изменений.
Как быть, если хочется сделать вьюшку с параметрами
Такое желание может часто посещать разработчика на Oracle. Почему можно сделать процедуру или функцию с параметрами, но не бывает вьюшек с входными параметрами, которые можно использовать при вычислениях? В Oracle есть чем заменить это недостающее, на наш взгляд, понятие.
Рассмотрим пример. Пусть есть таблица с продажами по подразделениям за каждый день.
create table DIVISION_SALES
(
division_id INTEGER,
dt DATE,
sales_amt NUMBER
);Такой запрос сравнивает продажи по подразделениям за два дня. В данном случае, 30.04.2020 и 11.09.2020.
select t1.division_id,
t1.dt dt1,
t2.dt dt2,
t1.sales_amt sales_amt1,
t2.sales_amt sales_amt2
from (select dt, division_id, sales_amt
from division_sales
where dt = to_date('30.04.2020', 'dd.mm.yyyy')) t1,
(select dt, division_id, sales_amt
from division_sales
where dt = to_date('11.09.2020', 'dd.mm.yyyy')) t2
where t1.division_id = t2.division_id;Вот вьюшка, которую хочется написать для обобщения такого запроса. Хочется передавать даты в качестве параметров. Однако синтаксис не позволяет такое сделать.
create or replace view vw_division_sales_report(in_dt1 date, in_dt2 date) as
select t1.division_id,
t1.dt dt1,
t2.dt dt2,
t1.sales_amt sales_amt1,
t2.sales_amt sales_amt2
from (select dt, division_id, sales_amt
from division_sales
where dt = in_dt1) t1,
(select dt, division_id, sales_amt
from division_sales
where dt = in_dt2) t2
where t1.division_id = t2.division_id;Предлагается такое обходное решение. Создадим тип под строку из этой вьюшки.
create type t_division_sales_report as object
(
division_id INTEGER,
dt1 DATE,
dt2 DATE,
sales_amt1 NUMBER,
sales_amt2 NUMBER
);И создадим тип под таблицу из таких строк.
create type t_division_sales_report_table as table of t_division_sales_report;Вместо вьюшки напишем pipelined функцию с входными параметрами-датами.
create or replace function func_division_sales(in_dt1 date, in_dt2 date)
return t_division_sales_report_table
pipelined as
begin
for z in (select t1.division_id,
t1.dt dt1,
t2.dt dt2,
t1.sales_amt sales_amt1,
t2.sales_amt sales_amt2
from (select dt, division_id, sales_amt
from division_sales
where dt = in_dt1) t1,
(select dt, division_id, sales_amt
from division_sales
where dt = in_dt2) t2
where t1.division_id = t2.division_id) loop
pipe row(t_division_sales_report(z.division_id,
z.dt1,
z.dt2,
z.sales_amt1,
z.sales_amt2));
end loop;
end;Обращаться к ней можно так:
select *
from table(func_division_sales(to_date('30.04.2020', 'dd.mm.yyyy'),
to_date('11.09.2020', 'dd.mm.yyyy')));Этот запрос и выдаст нам такой же результат, как запрос в начале этой заметки с явным образом подставленными датами.
Pipelined функции могут быть также полезны, если нужно передать параметр внутрь сложного запроса.
Например, рассмотрим с��ожную вьюшку, в которой поле field1, по которому хочется отфильтровать данные, запрятано где-то глубоко во вьюшке.
create or replace view complex_view as
select field1, ...
from (select field1, ...
from (select field1, ... from deep_table), table1
where ...),
table2
where ...;И запрос из вьюшки с фиксированным значением field1 может иметь плохой план выполнения.
select field1, ... from complex_view
where field1 = 'myvalue';Т.е. вместо того, чтобы сначала отфильтровать deep_table по условию field1 = 'myvalue', запрос может сначала соединить все таблицы, обработав излишне большой объём данных, а потом уже фильтровать результат по условию field1 = 'myvalue'. Такой сложности можно избежать, если сделать вместо вьюшки pipelined функцию с параметром, значение которого присваивается полю field1.
Использование динамической статистики в запросах
Бывает, что один и тот же запрос в БД Oracle обрабатывает всякий раз различный объём данных в использующихся в нём таблицах и подзапросах. Как заставить оптимизатор всякий раз понимать, какой из способов соединения таблиц на этот раз лучше и какие индексы использовать? Рассмотрим, например, запрос, который соединяет порцию изменившихся с последней загрузки остатков по счетам со справочником счетов. Порция изменившихся остатков по счетам сильно меняется от загрузки к загрузке, составляя то сотни строк, то миллионы строк. В зависимости от размера этой порции требуется соединять изменившиеся остатки со счетами то способом /*+ use_nl*/, то способом /*+ use_hash*/. Всякий раз повторно собирать статистику неудобно, особенно, если от загрузки к загрузке изменяется количество строк не в соединяемой таблице, а в соединяемом подзапросе. На помощь тут может прийти хинт /*+ dynamic_sampling()*/. Покажем, как он влияет, на примере запроса. Пусть таблица change_balances содержит изменения остатков, а accounts – справочник счетов. Соединяем эти таблицы по полям account_id, имеющимся в каждой из таблиц. В начале эксперимента запишем в эти таблицы побольше строк и не будем менять их содержимое.
Сначала возьмём 10% изменений остатков в таблице change_balances и посмотрим, какой план будет с использованием dynamic_sampling:
SQL> EXPLAIN PLAN
2 SET statement_id = 'test1'
3 INTO plan_table
4 FOR with c as
5 (select /*+ dynamic_sampling(change_balances 2)*/
6 account_id, balance_amount
7 from change_balances
8 where mod(account_id, 10) = 0)
9 select a.account_id, a.account_number, c.balance_amount
10 from c, accounts a
11 where c.account_id = a.account_id;
Explained.
SQL>
SQL> SELECT * FROM table (DBMS_XPLAN.DISPLAY);
Plan hash value: 874320301
----------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time |
----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 9951K| 493M| | 140K (1)| 00:28:10 |
|* 1 | HASH JOIN | | 9951K| 493M| 3240K| 140K (1)| 00:28:10 |
|* 2 | TABLE ACCESS FULL| CHANGE_BALANCES | 100K| 2057K| | 7172 (1)| 00:01:27 |
| 3 | TABLE ACCESS FULL| ACCOUNTS | 10M| 295M| | 113K (1)| 00:22:37 |
----------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("ACCOUNT_ID"="A"."ACCOUNT_ID")
2 - filter(MOD("ACCOUNT_ID",10)=0)
Note
-----
- dynamic sampling used for this statement (level=2)
20 rows selected.Итак, видим, что предлагается пройти таблицы change_balances и accounts с помощью full scan и соединить их посредством hash join.
Теперь резко уменьшим выборку из change_balances. Возьмём 0.1% изменений остатков и посмотрим, какой план будет с использованием dynamic_sampling:
SQL> EXPLAIN PLAN
2 SET statement_id = 'test2'
3 INTO plan_table
4 FOR with c as
5 (select /*+ dynamic_sampling(change_balances 2)*/
6 account_id, balance_amount
7 from change_balances
8 where mod(account_id, 1000) = 0)
9 select a.account_id, a.account_number, c.balance_amount
10 from c, accounts a
11 where c.account_id = a.account_id;
Explained.
SQL>
SQL> SELECT * FROM table (DBMS_XPLAN.DISPLAY);
Plan hash value: 2360715730
-------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 73714 | 3743K| 16452 (1)| 00:03:18 |
| 1 | NESTED LOOPS | | | | | |
| 2 | NESTED LOOPS | | 73714 | 3743K| 16452 (1)| 00:03:18 |
|* 3 | TABLE ACCESS FULL | CHANGE_BALANCES | 743 | 15603 | 7172 (1)| 00:01:27 |
|* 4 | INDEX RANGE SCAN | IX_ACCOUNTS_ACCOUNT_ID | 104 | | 2 (0)| 00:00:01 |
| 5 | TABLE ACCESS BY INDEX ROWID| ACCOUNTS | 99 | 3069 | 106 (0)| 00:00:02 |
-------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - filter(MOD("ACCOUNT_ID",1000)=0)
4 - access("ACCOUNT_ID"="A"."ACCOUNT_ID")
Note
-----
- dynamic sampling used for this statement (level=2)
22 rows selected.На этот раз к таблице change_balances таблица accounts присоединяется посредством nested loops и используется индекс для чтения строк из accounts.
Если же хинт dynamic_sampling убрать, то во втором случае план останется такой же, как в первом случае, и это не оптимально.
Подробности о хинте dynamic_sampling и возможных значениях его числового аргумента можно найти в документации.
Как сохранить план запроса при вставке данных через database link
Решаем такую задачу. На сервере-источнике данных имеются таблицы, которые нужно соединить и загрузить в хранилище данных. Допустим, на сервере-источнике написана вьюшка, которая содержит в себе всю нужную ETL-логику преобразований. Вьюшка написана оптимально, в ней указаны хинты оптимизатору, подсказывающие, как соединять таблицы и какие индексы использовать. На стороне сервера хранилища данных нужно сделать несложную вещь – вставить данные из вьюшки в целевую таблицу. И тут могут возникнуть сложности. Если вставку в целевую таблицу осуществить командой вида
insert into dwh_table
(field1, field2)
select field1, field2 from vw_for_dwh_table@xe_link;, то вся логика плана запроса, содержащаяся во вьюшке, из которой читаем данные по database link, может быть проигнорирована. Все хинты, зашитые в этой вьюшке могут быть не учтены.
SQL> EXPLAIN PLAN
2 SET statement_id = 'test'
3 INTO plan_table
4 FOR insert into dwh_table
5 (field1, field2)
6 select field1, field2 from vw_for_dwh_table@xe_link;
Explained.
SQL>
SQL> SELECT * FROM table (DBMS_XPLAN.DISPLAY);
Plan hash value: 1788691278
-------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Inst |IN-OUT|
-------------------------------------------------------------------------------------------------------------
| 0 | INSERT STATEMENT | | 1 | 2015 | 2 (0)| 00:00:01 | | |
| 1 | LOAD TABLE CONVENTIONAL | DWH_TABLE | | | | | | |
| 2 | REMOTE | VW_FOR_DWH_TABLE | 1 | 2015 | 2 (0)| 00:00:01 | XE_LI~ | R->S |
-------------------------------------------------------------------------------------------------------------
Remote SQL Information (identified by operation id):
----------------------------------------------------
2 - SELECT /*+ OPAQUE_TRANSFORM */ "FIELD1","FIELD2" FROM "VW_FOR_DWH_TABLE" "VW_FOR_DWH_TABLE"
(accessing 'XE_LINK' )
16 rows selected.Чтобы сохранить план запроса во вьюшке, можно воспользоваться вставкой данных в целевую таблицу из курсора:
declare
cursor cr is
select field1, field2 from vw_for_dwh_table@xe_link;
cr_row cr%rowtype;
begin
open cr;
loop
fetch cr
into cr_row;
insert into dwh_table
(field1, field2)
values
(cr_row.field1, cr_row.field2);
exit when cr%notfound;
end loop;
close cr;
end;Запрос из курсора
select field1, field2 from vw_for_dwh_table@xe_link;в отличие от вставки
insert into dwh_table
(field1, field2)
select field1, field2 from vw_for_dwh_table@xe_link;сохранит план запроса, заложенный во вьюшку на сервере-источнике.
Запуск процедур в параллельных сессиях
Часто стоит задача запустить из некоторой родительской процедуры несколько параллельных расчётов и, дождавшись завершения каждого из них, продолжить выполнение родительской процедуры. Это может быть полезно при параллельных вычислениях, если ресурсы сервера позволяют это. Есть много способов сделать это.
Опишем очень простой вариант реализации такого механизма. Параллельные процедуры будем выполнять в параллельных “одноразовых” джобах, родительская же процедура в цикле будет ожидать завершения всех этих джобов.
Создадим таблицы с метаданными для этого механизма. Для начала сделаем таблицу с группами параллельно запускаемых процедур:
create table PARALLEL_PROC_GROUP_LIST
(
group_id INTEGER,
group_name VARCHAR2(4000)
);
comment on column PARALLEL_PROC_GROUP_LIST.group_id
is 'Номер группы параллельно запускаемых процедур';
comment on column PARALLEL_PROC_GROUP_LIST.group_name
is 'Название группы параллельно запускаемых процедур';Далее создадим таблицу со скриптами, которые будут параллельно выполняться в группах. Наполнение этой таблицы может быть как статическим, так и создаваться динамически:
create table PARALLEL_PROC_LIST
(
group_id INTEGER,
proc_script VARCHAR2(4000),
is_active CHAR(1) default 'Y'
);
comment on column PARALLEL_PROC_LIST.group_id
is 'Номер группы параллельно запускаемых процедур';
comment on column PARALLEL_PROC_LIST.proc_script
is 'Pl/sql блок с кодом процедуры';
comment on column PARALLEL_PROC_LIST.is_active
is 'Y - active, N - inactive. С помощью этого поля можно временно отключать процедуру из группы';И сделаем таблицу журнала, где будем собирать лог того, какая процедура когда в каком джобе запускалась:
create table PARALLEL_PROC_LOG
(
run_id INTEGER,
group_id INTEGER,
proc_script VARCHAR2(4000),
job_id INTEGER,
start_time DATE,
end_time DATE
);
comment on column PARALLEL_PROC_LOG.run_id
is 'Номер запуска процедуры run_in_parallel';
comment on column PARALLEL_PROC_LOG.group_id
is 'Номер группы параллельно запускаемых процедур';
comment on column PARALLEL_PROC_LOG.proc_script
is 'Pl/sql блок с кодом процедуры';
comment on column PARALLEL_PROC_LOG.job_id
is 'Job_id джоба, в котором была запущена эта процедура';
comment on column PARALLEL_PROC_LOG.start_time
is 'Время начала работы';
comment on column PARALLEL_PROC_LOG.end_time
is 'Время окончания работы';
create sequence Seq_Parallel_Proc_Log;Теперь приведём код процедуры по запуску параллельных потоков:
create or replace procedure run_in_parallel(in_group_id integer) as
-- Процедура по параллельному запуску процедур из таблицы parallel_proc_list.
-- Параметр - номер группы из parallel_proc_list
v_run_id integer;
v_job_id integer;
v_job_id_list varchar2(32767);
v_job_id_list_ext varchar2(32767);
v_running_jobs_count integer;
begin
select seq_parallel_proc_log.nextval into v_run_id from dual;
-- submit jobs with the same parallel_proc_list.in_group_id
-- store seperated with ',' JOB_IDs in v_job_id_list
v_job_id_list := null;
v_job_id_list_ext := null;
for z in (select pt.proc_script
from parallel_proc_list pt
where pt.group_id = in_group_id
and pt.is_active = 'Y') loop
dbms_job.submit(v_job_id, z.proc_script);
insert into parallel_proc_log
(run_id, group_id, proc_script, job_id, start_time, end_time)
values
(v_run_id, in_group_id, z.proc_script, v_job_id, sysdate, null);
v_job_id_list := v_job_id_list || ',' || to_char(v_job_id);
v_job_id_list_ext := v_job_id_list_ext || ' union all select ' ||
to_char(v_job_id) || ' job_id from dual';
end loop;
commit;
v_job_id_list := substr(v_job_id_list, 2);
v_job_id_list_ext := substr(v_job_id_list_ext, 12);
-- loop while not all jobs finished
loop
-- set parallel_proc_log.end_time for finished jobs
execute immediate 'update parallel_proc_log set end_time = sysdate where job_id in (' ||
v_job_id_list_ext ||
' minus select job from user_jobs where job in (' ||
v_job_id_list ||
') minus select job_id from parallel_proc_log where job_id in (' ||
v_job_id_list || ') and end_time is not null)';
commit;
-- check whether all jobs finished
execute immediate 'select count(1) from user_jobs where job in (' ||
v_job_id_list || ')'
into v_running_jobs_count;
-- if all jobs finished then exit
exit when v_running_jobs_count = 0;
-- sleep a little
sys.dbms_lock.sleep(0.1);
end loop;
end;Проверим, как работает процедура run_in_parallel. Создадим тестовую процедуру, которую будем вызывать в параллельных сессиях.
create or replace procedure sleep(in_seconds integer) as
begin
sys.Dbms_Lock.Sleep(in_seconds);
end;Заполним название группы и таблицу со cкриптами, которые будут выполняться параллельно.
insert into PARALLEL_PROC_GROUP_LIST(group_id, group_name) values(1, 'Тестовая группа');
insert into PARALLEL_PROC_LIST(group_id, proc_script, is_active) values(1, 'begin sleep(5); end;', 'Y');
insert into PARALLEL_PROC_LIST(group_id, proc_script, is_active) values(1, 'begin sleep(10); end;', 'Y');Запустим группу параллельных процедур.
begin
run_in_parallel(1);
end;По завершении посмотрим лог.
select * from PARALLEL_PROC_LOG;| RUN_ID | GROUP_ID | PROC_SCRIPT | JOB_ID | START_TIME | END_TIME |
| 1 | 1 | begin sleep(5); end; | 1 | 11.09.2020 15:00:51 | 11.09.2020 15:00:56 |
| 1 | 1 | begin sleep(10); end; | 2 | 11.09.2020 15:00:51 | 11.09.2020 15:01:01 |
Видим, что время выполнения экземпляров тестовой процедуры соответствует ожиданиям.
Протягивание остатков
Опишем вариант решения достаточно типовой банковской задачи по “протягиванию остатков”. Допустим, имеется таблица фактов изменения остатков по счетам. Требуется на каждый день календаря указать актуальный остаток по счёту (последний за день). Такая информация часто бывает нужна в хранилищах данных. Если в какой-то день не было движений по счёту, то нужно повторить последний известный остаток. Если объёмы данных и вычислительные мощности сервера позволяют, то можно решить такую задачу с помощью SQL-запроса, даже не прибегая к PL/SQL. Поможет нам в этом функция last_value(* ignore nulls) over(partition by * order by *), которая протянет последний известный остаток на последующие даты, в которых не было изменений.
Создадим таблицу и заполним её тестовыми данными.
create table ACCOUNT_BALANCE
(
dt DATE,
account_id INTEGER,
balance_amt NUMBER,
turnover_amt NUMBER
);
comment on column ACCOUNT_BALANCE.dt
is 'Дата и время остатка по счёту';
comment on column ACCOUNT_BALANCE.account_id
is 'Номер счёта';
comment on column ACCOUNT_BALANCE.balance_amt
is 'Остаток по счёту';
comment on column ACCOUNT_BALANCE.turnover_amt
is 'Оборот по счёту';
insert into account_balance(dt, account_id, balance_amt, turnover_amt) values(to_date('01.01.2020 00:00:00','dd.mm.yyyy hh24.mi.ss'), 1, 23, 23);
insert into account_balance(dt, account_id, balance_amt, turnover_amt) values(to_date('05.01.2020 01:00:00','dd.mm.yyyy hh24.mi.ss'), 1, 45, 22);
insert into account_balance(dt, account_id, balance_amt, turnover_amt) values(to_date('05.01.2020 20:00:00','dd.mm.yyyy hh24.mi.ss'), 1, 44, -1);
insert into account_balance(dt, account_id, balance_amt, turnover_amt) values(to_date('05.01.2020 00:00:00','dd.mm.yyyy hh24.mi.ss'), 2, 67, 67);
insert into account_balance(dt, account_id, balance_amt, turnover_amt) values(to_date('05.01.2020 20:00:00','dd.mm.yyyy hh24.mi.ss'), 2, 77, 10);
insert into account_balance(dt, account_id, balance_amt, turnover_amt) values(to_date('07.01.2020 00:00:00','dd.mm.yyyy hh24.mi.ss'), 2, 72, -5);
Нижеприведённый запрос решает нашу задачу. Подзапрос ‘cld’ содержит календарь дат, в подзапросе ‘ab’ группируем остатки за каждый день, в подзапросе ‘a’ запоминаем перечень всех счетов и дату начала истории по каждому счёту, в подзапросе ‘pre’ для каждого счёта составляем календарь дней с начала его истории. Финальный запрос присоединяет к календарю дней активности каждого счёта последние остатки на каждый день и протягивает их на дни, в которых не было изменений.
with cld as
(select /*+ materialize*/
to_date('01.01.2020', 'dd.mm.yyyy') + level - 1 dt
from dual
connect by level <= 10),
ab as
(select trunc(dt) dt,
account_id,
max(balance_amt) keep(dense_rank last order by dt) balance_amt,
sum(turnover_amt) turnover_amt
from account_balance
group by trunc(dt), account_id),
a as
(select min(dt) min_dt, account_id from ab group by account_id),
pre as
(select cld.dt, a.account_id from cld left join a on cld.dt >= a.min_dt)
select pre.dt,
pre.account_id,
last_value(ab.balance_amt ignore nulls) over(partition by pre.account_id order by pre.dt) balance_amt,
nvl(ab.turnover_amt, 0) turnover_amt
from pre
left join ab
on pre.dt = ab.dt
and pre.account_id = ab.account_id
order by 2, 1;
Результат запроса соответствует ожиданиям.
| DT | ACCOUNT_ID | BALANCE_AMT | TURNOVER_AMT |
| 01.01.2020 | 1 | 23 | 23 |
| 02.01.2020 | 1 | 23 | 0 |
| 03.01.2020 | 1 | 23 | 0 |
| 04.01.2020 | 1 | 23 | 0 |
| 05.01.2020 | 1 | 44 | 21 |
| 06.01.2020 | 1 | 44 | 0 |
| 07.01.2020 | 1 | 44 | 0 |
| 08.01.2020 | 1 | 44 | 0 |
| 09.01.2020 | 1 | 44 | 0 |
| 10.01.2020 | 1 | 44 | 0 |
| 05.01.2020 | 2 | 77 | 77 |
| 06.01.2020 | 2 | 77 | 0 |
| 07.01.2020 | 2 | 72 | -5 |
| 08.01.2020 | 2 | 72 | 0 |
| 09.01.2020 | 2 | 72 | 0 |
| 10.01.2020 | 2 | 72 | 0 |
Объединение нескольких историй в одну
При загрузке данных в хранилища часто решается задача, когда нужно выстроить единую историю по сущности, имея отдельные истории атрибутов этой сущности, пришедшие из различных источников. Допустим, имеется некоторая сущность с первичным ключом primary_key_id, о которой известна история (start_dt — end_dt) трёх её различных атрибутов, расположенная в трёх различных таблицах.
create table HIST1
(
primary_key_id INTEGER,
start_dt DATE,
attribute1 NUMBER
);
insert into HIST1(primary_key_id, start_dt, attribute1) values(1, to_date('2014-01-01','yyyy-mm-dd'), 7);
insert into HIST1(primary_key_id, start_dt, attribute1) values(1, to_date('2015-01-01','yyyy-mm-dd'), 8);
insert into HIST1(primary_key_id, start_dt, attribute1) values(1, to_date('2016-01-01','yyyy-mm-dd'), 9);
insert into HIST1(primary_key_id, start_dt, attribute1) values(2, to_date('2014-01-01','yyyy-mm-dd'), 17);
insert into HIST1(primary_key_id, start_dt, attribute1) values(2, to_date('2015-01-01','yyyy-mm-dd'), 18);
insert into HIST1(primary_key_id, start_dt, attribute1) values(2, to_date('2016-01-01','yyyy-mm-dd'), 19);
create table HIST2
(
primary_key_id INTEGER,
start_dt DATE,
attribute2 NUMBER
);
insert into HIST2(primary_key_id, start_dt, attribute2) values(1, to_date('2015-01-01','yyyy-mm-dd'), 4);
insert into HIST2(primary_key_id, start_dt, attribute2) values(1, to_date('2016-01-01','yyyy-mm-dd'), 5);
insert into HIST2(primary_key_id, start_dt, attribute2) values(1, to_date('2017-01-01','yyyy-mm-dd'), 6);
insert into HIST2(primary_key_id, start_dt, attribute2) values(2, to_date('2015-01-01','yyyy-mm-dd'), 14);
insert into HIST2(primary_key_id, start_dt, attribute2) values(2, to_date('2016-01-01','yyyy-mm-dd'), 15);
insert into HIST2(primary_key_id, start_dt, attribute2) values(2, to_date('2017-01-01','yyyy-mm-dd'), 16);
create table HIST3
(
primary_key_id INTEGER,
start_dt DATE,
attribute3 NUMBER
);
insert into HIST3(primary_key_id, start_dt, attribute3) values(1, to_date('2016-01-01','yyyy-mm-dd'), 10);
insert into HIST3(primary_key_id, start_dt, attribute3) values(1, to_date('2017-01-01','yyyy-mm-dd'), 20);
insert into HIST3(primary_key_id, start_dt, attribute3) values(1, to_date('2018-01-01','yyyy-mm-dd'), 30);
insert into HIST3(primary_key_id, start_dt, attribute3) values(2, to_date('2016-01-01','yyyy-mm-dd'), 110);
insert into HIST3(primary_key_id, start_dt, attribute3) values(2, to_date('2017-01-01','yyyy-mm-dd'), 120);
insert into HIST3(primary_key_id, start_dt, attribute3) values(2, to_date('2018-01-01','yyyy-mm-dd'), 130);Целью является загрузка единой истории изменения трёх атрибутов в одну таблицу.
Ниже приведён запрос, решающий такую задачу. В нём сначала формируется диагональная таблица q1 с данными из разных источников по разным атрибутам (отсутствующие в источнике атрибуты заполняются null-ами). Затем с помощью функции last_value(* ignore nulls) диагональная таблица схлопывается в единую историю, а последние известные значения атрибутов протягиваются вперёд на те даты, в которые изменений по ним не было:
select primary_key_id,
start_dt,
nvl(lead(start_dt - 1)
over(partition by primary_key_id order by start_dt),
to_date('9999-12-31', 'yyyy-mm-dd')) as end_dt,
last_value(attribute1 ignore nulls) over(partition by primary_key_id order by start_dt) as attribute1,
last_value(attribute2 ignore nulls) over(partition by primary_key_id order by start_dt) as attribute2,
last_value(attribute3 ignore nulls) over(partition by primary_key_id order by start_dt) as attribute3
from (select primary_key_id,
start_dt,
max(attribute1) as attribute1,
max(attribute2) as attribute2,
max(attribute3) as attribute3
from (select primary_key_id,
start_dt,
attribute1,
cast(null as number) attribute2,
cast(null as number) attribute3
from hist1
union all
select primary_key_id,
start_dt,
cast(null as number) attribute1,
attribute2,
cast(null as number) attribute3
from hist2
union all
select primary_key_id,
start_dt,
cast(null as number) attribute1,
cast(null as number) attribute2,
attribute3
from hist3) q1
group by primary_key_id, start_dt) q2
order by primary_key_id, start_dt;Результат получается такой:
| PRIMARY_KEY_ID | START_DT | END_DT | ATTRIBUTE1 | ATTRIBUTE2 | ATTRIBUTE3 |
| 1 | 01.01.2014 | 31.12.2014 | 7 | NULL | NULL |
| 1 | 01.01.2015 | 31.12.2015 | 8 | 4 | NULL |
| 1 | 01.01.2016 | 31.12.2016 | 9 | 5 | 10 |
| 1 | 01.01.2017 | 31.12.2017 | 9 | 6 | 20 |
| 1 | 01.01.2018 | 31.12.9999 | 9 | 6 | 30 |
| 2 | 01.01.2014 | 31.12.2014 | 17 | NULL | NULL |
| 2 | 01.01.2015 | 31.12.2015 | 18 | 14 | NULL |
| 2 | 01.01.2016 | 31.12.2016 | 19 | 15 | 110 |
| 2 | 01.01.2017 | 31.12.2017 | 19 | 16 | 120 |
| 2 | 01.01.2018 | 31.12.9999 | 19 | 16 | 130 |
Нормалайзер
Иногда встаёт задача о нормализации данных, пришедших в формате поля с разделителями. Например, в виде такой таблицы:
create table DENORMALIZED_TABLE
(
id INTEGER,
val VARCHAR2(4000)
);
insert into DENORMALIZED_TABLE(id, val) values(1, 'aaa,cccc,bb');
insert into DENORMALIZED_TABLE(id, val) values(2, 'ddd');
insert into DENORMALIZED_TABLE(id, val) values(3, 'fffff,e');Такой запрос нормализует данные, расклеив соединённые запятой поля в виде нескольких строк:
select id, regexp_substr(val, '[^,]+', 1, column_value) val, column_value
from denormalized_table,
table(cast(multiset
(select level
from dual
connect by regexp_instr(val, '[^,]+', 1, level) > 0) as
sys.odcinumberlist))
order by id, column_value;Результат получается такой:
| ID | VAL | COLUMN_VALUE |
| 1 | aaa | 1 |
| 1 | cccc | 2 |
| 1 | bb | 3 |
| 2 | ddd | 1 |
| 3 | fffff | 1 |
| 3 | e | 2 |
Визуализация в формате SVG
Часто возникает желание как-то визуализировать числовые показатели, хранящиеся в базе данных. Например, построить графики, гистограммы, диаграммы. В этом могут помочь специализированные средства, например, Oracle BI. Но лицензии на эти средства могут стоить денег, а настройка их может занять больше времени, чем написание “на коленке” SQL-запроса к Oracle, который выдаст готовую картинку. Продемонстрируем на примере, как с помощью запроса быстро нарисовать такую картинку в формате SVG.
Предположим, у нас есть таблица с данными
create table graph_data(dt date, val number, radius number);
insert into graph_data(dt, val, radius) values (to_date('01.01.2020','dd.mm.yyyy'), 12, 3);
insert into graph_data(dt, val, radius) values (to_date('02.01.2020','dd.mm.yyyy'), 15, 4);
insert into graph_data(dt, val, radius) values (to_date('05.01.2020','dd.mm.yyyy'), 17, 5);
insert into graph_data(dt, val, radius) values (to_date('06.01.2020','dd.mm.yyyy'), 13, 6);
insert into graph_data(dt, val, radius) values (to_date('08.01.2020','dd.mm.yyyy'), 3, 7);
insert into graph_data(dt, val, radius) values (to_date('10.01.2020','dd.mm.yyyy'), 20, 8);
insert into graph_data(dt, val, radius) values (to_date('11.01.2020','dd.mm.yyyy'), 18, 9);dt – это дата актуальности,
val – это числовой показатель, динамику которого по времени мы визуализируем,
radius – это ещё один числовой показатель, который будем рисовать в виде кружка с таким радиусом.
Скажем пару слов о формате SVG. Это формат векторной графики, который можно смотреть в современных браузерах и конвертировать в другие графические форматы. В нём, среди прочего, можно рисовать линии, кружки и писать текст:
<line x1="94" x2="94" y1="15" y2="675" style="stroke:rgb(150,255,255); stroke-width:1px"/>
<circle cx="30" cy="279" r="3" style="fill:rgb(255,0,0)"/>
<text x="7" y="688" font-size="10" fill="rgb(0,150,255)">2020-01-01</text>Ниже SQL-запрос к Oracle, который строит график из данных в этой таблице. Здесь подзапрос const содержит различные константные настройки – размеры картинки, количество меток на осях графика, цвета линий и кружочков, размеры шрифта и т.д. В подзапросе gd1 мы приводим данные из таблицы graph_data к координатам x и y на рисунке. Подзапрос gd2 запоминает предыдущие по времени точки, из которых нужно вести линии к новым точкам. Блок ‘header’ – это заголовок картинки с белым фоном. Блок ‘vertical lines’ рисует вертикальные линии. Блок ‘dates under vertical lines’ подписывает даты на оси x. Блок ‘horizontal lines’ рисует горизонтальные линии. Блок ‘values near horizontal lines’ подписывает значения на оси y. Блок ‘circles’ рисует кружочки указанного в таблице graph_data радиуса. Блок ‘graph data’ строит из линий график динамики показателя val из таблицы graph_data. Блок ‘footer’ добавляет замыкающий тэг.
with const as
(select 700 viewbox_width,
700 viewbox_height,
30 left_margin,
30 right_margin,
15 top_margin,
25 bottom_margin,
max(dt) - min(dt) + 1 num_vertical_lines,
11 num_horizontal_lines,
'rgb(150,255,255)' stroke_vertical_lines,
'1px' stroke_width_vertical_lines,
10 font_size_dates,
'rgb(0,150,255)' fill_dates,
23 x_dates_pad,
13 y_dates_pad,
'rgb(150,255,255)' stroke_horizontal_lines,
'1px' stroke_width_horizontal_lines,
10 font_size_values,
'rgb(0,150,255)' fill_values,
4 x_values_pad,
2 y_values_pad,
'rgb(255,0,0)' fill_circles,
'rgb(51,102,0)' stroke_graph,
'1px' stroke_width_graph,
min(dt) min_dt,
max(dt) max_dt,
max(val) max_val
from graph_data),
gd1 as
(select graph_data.dt,
const.left_margin +
(const.viewbox_width - const.left_margin - const.right_margin) *
(graph_data.dt - const.min_dt) / (const.max_dt - const.min_dt) x,
const.viewbox_height - const.bottom_margin -
(const.viewbox_height - const.top_margin - const.bottom_margin) *
graph_data.val / const.max_val y,
graph_data.radius
from graph_data, const),
gd2 as
(select dt,
round(nvl(lag(x) over(order by dt), x)) prev_x,
round(x) x,
round(nvl(lag(y) over(order by dt), y)) prev_y,
round(y) y,
radius
from gd1)
/* header */
select '<?xml version="1.0" encoding="UTF-8" standalone="no"?>' txt
from dual
union all
select '<svg version="1.1" width="' || viewbox_width || '" height="' ||
viewbox_height || '" viewBox="0 0 ' || viewbox_width || ' ' ||
viewbox_height ||
'" style="background:yellow" baseProfile="full" xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" xmlns:ev="http://www.w3.org/2001/xml-events">'
from const
union all
select '<title>Test graph</title>'
from dual
union all
select '<desc>Test graph</desc>'
from dual
union all
select '<rect width="' || viewbox_width || '" height="' || viewbox_height ||
'" style="fill:white" />'
from const
union all
/* vertical lines */
select '<line x1="' ||
to_char(round(left_margin +
(viewbox_width - left_margin - right_margin) *
(level - 1) / (num_vertical_lines - 1))) || '" x2="' ||
to_char(round(left_margin +
(viewbox_width - left_margin - right_margin) *
(level - 1) / (num_vertical_lines - 1))) || '" y1="' ||
to_char(round(top_margin)) || '" y2="' ||
to_char(round(viewbox_height - bottom_margin)) || '" style="stroke:' ||
const.stroke_vertical_lines || '; stroke-width:' ||
const.stroke_width_vertical_lines || '"/>'
from const
connect by level <= num_vertical_lines
union all
/* dates under vertical lines */
select '<text x="' ||
to_char(round(left_margin +
(viewbox_width - left_margin - right_margin) *
(level - 1) / (num_vertical_lines - 1) - x_dates_pad)) ||
'" y="' ||
to_char(round(viewbox_height - bottom_margin + y_dates_pad)) ||
'" font-size="' || font_size_dates || '" fill="' || fill_dates || '">' ||
to_char(min_dt + level - 1, 'yyyy-mm-dd') || '</text>'
from const
connect by level <= num_vertical_lines
union all
/* horizontal lines */
select '<line x1="' || to_char(round(left_margin)) || '" x2="' ||
to_char(round(viewbox_width - right_margin)) || '" y1="' ||
to_char(round(top_margin +
(viewbox_height - top_margin - bottom_margin) *
(level - 1) / (num_horizontal_lines - 1))) || '" y2="' ||
to_char(round(top_margin +
(viewbox_height - top_margin - bottom_margin) *
(level - 1) / (num_horizontal_lines - 1))) ||
'" style="stroke:' || const.stroke_horizontal_lines ||
'; stroke-width:' || const.stroke_width_horizontal_lines || '"/>'
from const
connect by level <= num_horizontal_lines
union all
/* values near horizontal lines */
select '<text text-anchor="end" x="' ||
to_char(round(left_margin - x_values_pad)) || '" y="' ||
to_char(round(viewbox_height - bottom_margin -
(viewbox_height - top_margin - bottom_margin) *
(level - 1) / (num_horizontal_lines - 1) +
y_values_pad)) || '" font-size="' || font_size_values ||
'" fill="' || fill_values || '">' ||
to_char(round(max_val / (num_horizontal_lines - 1) * (level - 1), 2)) ||
'</text>'
from const
connect by level <= num_horizontal_lines
union all
/* circles */
select '<circle cx="' || to_char(gd2.x) || '" cy="' || to_char(gd2.y) ||
'" r="' || gd2.radius || '" style="fill:' || const.fill_circles ||
'"/>'
from gd2, const
union all
/* graph data */
select '<line x1="' || to_char(gd2.prev_x) || '" x2="' || to_char(gd2.x) ||
'" y1="' || to_char(gd2.prev_y) || '" y2="' || to_char(gd2.y) ||
'" style="stroke:' || const.stroke_graph || '; stroke-width:' ||
const.stroke_width_graph || '"/>'
from gd2, const
union all
/* footer */
select '</svg>' from dual;Результат запроса можно сохранить в файл с расширением *.svg и посмотреть в браузере. При желании можно с помощью какой-либо из утилит конвертировать его в другие графические форматы, размещать на веб-страницах своего приложения и т.д.
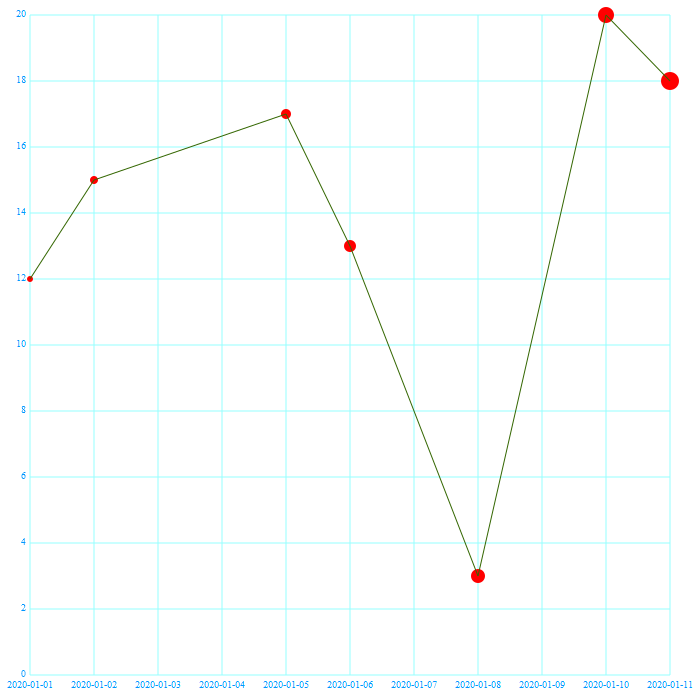
Получилась такая картинка:
Приложение поиска по метаданным Oracle
Представьте себе, что стоит задача найти что-либо в исходном коде на Oracle, поискав информацию сразу на нескольких серверах. Речь идёт о поиске по объектам словаря данных Oracle. Рабочим местом для поиска является веб-интерфейс, куда пользователь-программист вводит искомую строку и выбирает галочками, на каких серверах Oracle осуществить этот поиск.
Веб-поисковик умеет искать строку по серверным объектам Oracle одновременно в нескольких различных базах данных банка. Например, можно поискать:
- Где в коде Oracle зашита константа 61209, представляющая собой номер счёта второго порядка?
- Где в коде и на каких серверах используется таблица accounts (в т.ч. через database link)?
- С какого сервера из какой хранимой процедуры или триггера приходит сгенерированная программистом ошибка, например, ORA-20001 “Курс валюты не найден”?
- Прописан ли планируемый к удалению индекс IX_CLIENTID где-либо явным образом в хинтах оптимизатора в SQL-запросах?
- Используются ли где-либо (в т.ч. через database link) планируемые к удалению таблица, поле, процедура, функция и т.д.?
- Где в коде явно зашит чей-то е-мэйл или номер телефона? Такие вещи лучше выносить из серверных объектов в настроечные таблицы.
- Где в коде на серверах используется зависящий от версии Oracle функционал? Например, функция wm_concat выдаёт различный тип данных на выходе в зависимости от версии Oracle. Это может быть критично и требует внимания при миграции на более новую версию.
- Где в коде используется какой-либо редкий приём, на который программисту хочется посмотреть, как на образец? Например, поискать в коде Oracle примеры использования функций sys_connect_by_path, regexp_instr или хинта push_subq.
По результатам поиска пользователю выдаётся информация, на каком сервере в коде каких функций, процедур, пакетов, триггеров, вьюшек и т.п. найдены требуемые результаты.
Опишем, как реализован такой поисковик.
Клиентская часть не сложная. Веб-интерфейс получает введённую пользователем поисковую строку, список серверов для поиска и логин пользователя. Веб-страница передаёт их в хранимую процедуру Oracle на сервере-обработчике. История обращений к поисковику, т.е. кто какой запрос выполнял, на всякий случай журналируется.
Получив поисковый запрос, серверная часть на поисковом сервере Oracle запускает в параллельных джобах несколько процедур, которые по database links на выбранных серверах Oracle сканируют следующие представления словаря данных в поисках искомой строки: dba_col_comments, dba_jobs, dba_mviews, dba_objects, dba_scheduler_jobs, dba_source, dba_tab_cols, dba_tab_comments, dba_views. Каждая из процедур, если что-то обнаружила, записывает найденное в таблицу результатов поиска (с соответствующим ID поискового запроса).
Когда все поисковые процедуры завершили работу, клиентская часть выдаёт пользователю всё, что записалось в таблицу результатов поиска с соответствующим ID поискового запроса.
Но это ещё не всё. Помимо поиска по словарю данных Oracle в описанный механизм прикрутили ещё и поиск по репозиторию Informatica PowerCenter. Informatica PowerCenter является популярным ETL-средством, использующимся в Сбербанке при загрузке различной информации в хранилища данных. Informatica PowerCenter имеет открытую хорошо задокументированную структуру репозитория. По этому репозиторию есть возможность искать информацию так же, как и по словарю данных Oracle. Какие таблицы и поля используются в коде загрузок, разработанном на Informatica PowerCenter? Что можно найти в трансформациях портов и явных SQL-запросах? Вся эта информация имеется в структурах репозитория и может быть найдена. Для знатоков PowerCenter напишу, что наш поисковик сканирует следующие места репозитория в поисках маппингов, сессий или воркфловов, содержащих в себе где-то искомую строку: sql override, mapplet attributes, ports, source definitions in mappings, source definitions, target definitions in mappings, target_definitions, mappings, mapplets, workflows, worklets, sessions, commands, expression ports, session instances, source definition fields, target definition fields, email tasks.
Автор: Михаил Гричик, эксперт профессионального сообщества Сбербанка SberProfi DWH/BigData.
Профессиональное сообщество SberProfi DWH/BigData отвечает за развитие компетенций в таких направлениях, как экосистема Hadoop, Teradata, Oracle DB, GreenPlum, а также BI инструментах Qlik, SAP BO, Tableau и др.
