DataHub с открытым исходным кодом: платформа поиска и обнаружения метаданных от LinkedIn
Быстрый поиск нужных данных необходим для любой компании, которая полагается на большое количество данных для принятия решений на основе этих данных. Это не только влияет на продуктивность пользователей данных (включая аналитиков, разработчиков машинного обучения, специалистов по обработке данных и инженеров данных), но также оказывает прямое влияние на конечные продукты, которые зависят от качественного конвейера машинного обучения (ML). Кроме того, тенденция к внедрению или созданию платформ машинного обучения естественным образом вызывает вопрос: каков ваш метод внутреннего обнаружения функций, моделей, показателей, наборов данных и т. Д.
В этой статье мы расскажем о том, как опубликовали под открытой лицензией источник данных DataHub в нашей платформе поиска и обнаружения метаданных, начиная с первых дней проекта WhereHows. LinkedIn поддерживает собственную версию DataHub отдельно от версии с открытым исходным кодом. Мы начнем с объяснения того, почему нам нужны две отдельные среды разработки, после чего обсудим первые подходы к использованию WhereHows с открытым исходным кодом и проведем сравнение нашей внутренней (производственной) версии DataHub с версией на GitHub. Мы также поделимся подробностями о нашем новом автоматизированном решении для отправки и получения обновлений с открытым исходным кодом, чтобы синхронизировать оба репозитория. Наконец, мы дадим инструкции о том, как начать использовать DataHub с открытым исходным кодом, и кратко обсудим его архитектуру.

WhereHows это теперь DataHub!
Команда метаданных LinkedIn ранее представила DataHub (преемник WhereHows), платформу поиска и обнаружения метаданных LinkedIn, и поделилась планами по ее открытию. Вскоре после этого объявления мы выпустили альфа-версию DataHub и поделились ею с сообществом. С тех пор мы постоянно вносили свой вклад в репозиторий и работали с заинтересованными пользователями, чтобы добавить наиболее востребованные функции и решить проблемы. Теперь мы рады объявить об официальном выпуске DataHub на GitHub.
Подходы с открытым исходным кодом
WhereHows, оригинальный портал LinkedIn для поиска данных и их происхождения, открывался как внутренний проект; команда метаданных открыла его исходный код в 2016 году. С тех пор команда всегда поддерживала две разные кодовые базы — одну для открытого исходного кода, а другую для внутреннего использования LinkedIn, поскольку не все функции продукта, разработанные для вариантов использования LinkedIn, в целом были применимы для более широкой аудитории. Кроме того, WhereHows имеет некоторые внутренние зависимости (инфраструктура, библиотеки и т. д.), исходный код которых не открыт. В последующие годы WhereHows прошел через множество итераций и циклов разработки, что сделало синхронизацию двух кодовых баз большой проблемой. Команда метаданных на протяжении многих лет пыталась использовать разные подходы, чтобы попытаться синхронизировать внутреннюю разработку и разработку с открытым исходным кодом.
Первая попытка: «Сначала открытый код»
Первоначально мы следовали модели разработки «сначала открытый исходный код», где основная разработка происходит в репозитории с открытым исходным кодом, а изменения вносятся для внутреннего развертывания. Проблема с этим подходом заключается в том, что код всегда сначала отправляется на GitHub, прежде чем он будет полностью проверен внутри. Пока не будут внесены изменения из репозитория с открытым исходным кодом и не будет выполнено новое внутреннее развертывание, мы не обнаружим никаких производственных проблем. В случае плохого развертывания также было очень сложно определить виновника, потому что изменения вносились партиями.
Кроме того, эта модель снизила продуктивность команды при разработке новых функций, которые требовали быстрых итераций, поскольку она заставляла все изменения сначала помещать в репозиторий с открытым исходным кодом, а затем переносить во внутренний репозиторий. Чтобы сократить время обработки, необходимое исправление или изменение можно было сделать сначала во внутреннем репозитории, но это стало огромной проблемой, когда дело дошло до объединения этих изменений обратно в репозиторий с открытым исходным кодом, потому что два репозитория вышли из синхронизации.
Эту модель гораздо проще реализовать для общих платформ, библиотек или инфраструктурных проектов, чем для полнофункциональных пользовательских веб-приложений. Кроме того, эта модель идеально подходит для проектов, которые начинаются с открытого исходного кода с первого дня, но WhereHows создавалось как полностью внутреннее веб-приложение. Было действительно сложно полностью абстрагироваться от всех внутренних зависимостей, поэтому нам нужно было сохранить внутреннюю вилку, но сохранение внутренней вилки и разработка в основном с открытым исходным кодом не совсем сработали.
Вторая попытка: «Сначала внутренний»
** В качестве второй попытки мы перешли на модель разработки «сначала внутренний», в которой основная разработка происходит внутри компании, а изменения вносятся в открытый исходный код на регулярной основе. Хотя эта модель лучше всего подходит для нашего случая использования, ей присущи проблемы. Прямая отправка всех различий в репозиторий с открытым исходным кодом, а затем попытка разрешить конфликты слияния позже — вариант, но это отнимает много времени. Разработчики в большинстве случаев стараются не делать этого при каждой проверке кода. В результате это будет выполняться гораздо реже, партиями, и, таким образом, затрудняет последующее разрешение конфликтов слияния.
В третий раз все получилось!
Две упомянутые выше неудачные попытки привели к тому, что репозиторий WhereHows GitHub оставался устаревшим долгое время. Команда продолжала совершенствовать функции и архитектуру продукта, поэтому внутренняя версия WhereHows для LinkedIn становилась все более совершенной, чем версия с открытым исходным кодом. У него даже было новое название — DataHub. На основе предыдущих неудачных попыток команда решила разработать масштабируемое долгосрочное решение.
Для любого нового проекта с открытым исходным кодом команда разработчиков открытого исходного кода LinkedIn консультирует и поддерживает модель разработки, в которой модули проекта полностью разрабатываются с открытым исходным кодом. Артефакты с поддержкой версий развертываются в общедоступном репозитории, а затем возвращаются во внутренний артефакт LinkedIn с помощью запроса внешней библиотеки (ELR). Следование этой модели разработки не только хорошо для тех, кто использует открытый исходный код, но также приводит к созданию более модульной, расширяемой и подключаемой архитектуры.
Однако для достижения этого состояния для зрелого внутреннего приложения, такого как DataHub, потребуется значительное количество времени. Это также исключает возможность открытого исходного кода полностью работающей реализации до того, как все внутренние зависимости будут полностью абстрагированы. Поэтому мы разработали инструменты, которые помогают нам вносить вклады с открытым исходным кодом быстрее и гораздо менее болезненно. Это решение выгодно как команде метаданных (разработчик DataHub), так и сообществу открытого исходного кода. В следующих разделах будет обсуждаться этот новый подход.
Автоматизация публикации с открытым исходным кодом
Последний подход группы метаданных к DataHub с открытым исходным кодом заключается в разработке инструмента, который автоматически синхронизирует внутреннюю кодовую базу и репозиторий с открытым исходным кодом. Функции высокого уровня этого инструментария включают:
- Синхронизация кода LinkedIn с / из открытого исходного кода, аналогично rsync.
- Генерация заголовка лицензии, аналогичная Apache Rat.
- Автоматическое создание логов коммитов с открытым исходным кодом из внутренних логов коммитов.
- Предотвращение внутренних изменений, нарушающих сборку с открытым исходным кодом, путем тестирования зависимостей.
В следующих подразделах будут подробно рассмотрены вышеупомянутые функции, имеющие интересные проблемы.
Синхронизация исходного кода
В отличие от версии DataHub с открытым исходным кодом, которая представляет собой единый репозиторий GitHub, версия DataHub для LinkedIn представляет собой комбинацию нескольких репозиториев (внутри компании называемых multiproducts). Интерфейс DataHub, библиотека моделей метаданных, серверная служба хранилища метаданных и потоковые задания находятся в разных репозиториях в LinkedIn. Однако для облегчения работы пользователей с открытым исходным кодом у нас есть единый репозиторий для версии DataHub с открытым исходным кодом.
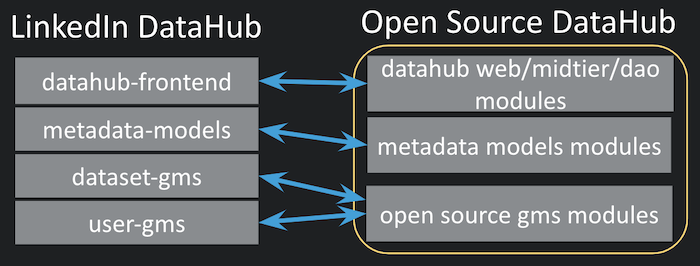
Рисунок 1: Синхронизация между репозиториями LinkedIn DataHub и единым репозиторием DataHub с открытым исходным кодом
Для поддержки автоматических рабочих процессов сборки, отправки и извлечения наш новый инструмент автоматически создает сопоставление на уровне файла, соответствующее каждому исходному файлу. Однако для инструментария требуется первоначальная конфигурация, и пользователи должны предоставить высокоуровневое отображение модулей, как показано ниже.
{ "datahub-dao": [ "${datahub-frontend}/datahub-dao" ], "gms/impl": [ "${dataset-gms}/impl", "${user-gms}/impl" ], "metadata-dao": [ "${metadata-models}/metadata-dao" ], "metadata-builders": [ "${metadata-models}/metadata-builders" ] }
Сопоставление на уровне модуля — это простой JSON, ключи которого являются целевыми модулями в репозитории с открытым исходным кодом, а значения — списком исходных модулей в репозиториях LinkedIn. Любой целевой модуль в репозитории с открытым исходным кодом может питаться любым количеством исходных модулей. Для обозначения внутренних имен репозиториев в исходных модулях используется строковая интерполяция в стиле Bash. Используя файл сопоставления на уровне модуля, инструментальные средства создают файл сопоставления на уровне файлов, сканируя все файлы в связанных каталогах.
{ "${metadata-models}/metadata-builders/src/main/java/com/linkedin/Foo.java": "metadata-builders/src/main/java/com/linkedin/Foo.java", "${metadata-models}/metadata-builders/src/main/java/com/linkedin/Bar.java": "metadata-builders/src/main/java/com/linkedin/Bar.java", "${metadata-models}/metadata-builders/build.gradle": null, }
Сопоставление файлового уровня автоматически создается инструментами; однако он также может быть обновлен пользователем вручную. Это сопоставление 1: 1 исходного файла LinkedIn с файлом в репозитории с открытым исходным кодом. Есть несколько правил, связанных с этим автоматическим созданием сопоставления файлов:
- В случае нескольких исходных модулей для целевого модуля в открытом исходном коде могут возникнуть конфликты, например, один и тот же FQCN, существующий более чем в одном исходном модуле. В качестве стратегии разрешения конфликтов наши инструменты по умолчанию используют опцию «последний выигрывает».
- «null» означает, что исходный файл не является частью репозитория с открытым исходным кодом.
- После каждой отправки в открытый исходный код или извлечения из него это сопоставление автоматически обновляется и создается моментальный снимок. Это необходимо для определения добавлений и удалений исходного кода после последнего действия.
Создание логов коммитов
Логи коммитов для коммитов с открытым исходным кодом также автоматически создаются путем объединения логов коммитов внутренних репозиториев. Ниже приведен образец лога коммита, чтобы показать структуру лога коммита, созданного нашим инструментом. Коммит четко указывает, какие версии исходных репозиториев упакованы в этот коммит, и предоставляет сводную информацию лога коммита. Проверьте этот коммит на реальном примере лога коммита, созданного нашим инструментарием.
metadata-models 29.0.0 -> 30.0.0 Added aspect model foo Fixed issue bar dataset-gms 2.3.0 -> 2.3.4 Added rest.li API to serve foo aspect MP_VERSION=dataset-gms:2.3.4 MP_VERSION=metadata-models:30.0.0
Тестирование зависимости
LinkedIn имеет инфраструктуру тестирования зависимостей, которая помогает гарантировать, что изменения внутреннего мультипродукта не нарушат сборку зависимых мультипродуктов. Репозиторий DataHub с открытым исходным кодом не является многопродуктовым, и он не может быть прямой зависимостью от какого-либо многопродукта, но с помощью многопродуктовой оболочки, которая извлекает исходный код DataHub с открытым исходным кодом, мы все еще можем использовать эту систему тестирования зависимостей.. Таким образом, любое изменение (которое, возможно, позже будет открыто) в любом из мультипродуктов, которые питают репозиторий DataHub с открытым исходным кодом, запускает событие сборки в мультипродукте оболочки. Следовательно, любое изменение, которое не позволяет построить многопродукт-оболочку, не проходит тесты перед коммитом исходного многопродукта и возвращается.
Это полезный механизм, который помогает предотвратить любой внутренний коммит, которая нарушает сборку с открытым исходным кодом, и обнаруживает ее во время создания коммита. Без этого было бы довольно сложно определить, какой внутренний коммит привел к сбою сборки репозитория с открытым исходным кодом, потому что мы помещаем пакетные внутренние изменения в репозиторий DataHub с открытым исходным кодом.
Различия между DataHub с открытым исходным кодом и нашей производственной версией
До этого момента мы обсуждали наше решение для синхронизации двух версий репозиториев DataHub, но до сих пор не обозначили причины, по которым нам вообще нужны два разных потока разработки. В этом разделе мы перечислим различия между общедоступной версией DataHub и производственной версией на серверах LinkedIn, а также объясним причины этих различий.
Один из источников расхождений проистекает из того факта, что наша производственная версия имеет зависимости от кода с еще не открытым исходным кодом, такого как LinkedIn's Offspring (внутренняя структура внедрения зависимостей LinkedIn). Offspring широко используется во внутренней кодовой базе, потому что это предпочтительный метод управления динамической конфигурацией. Но это не с открытым исходным кодом; поэтому нам нужно было найти альтернативы с открытым исходным кодом для DataHub с открытым исходным кодом.
Есть и другие причины. По мере того как мы создаем расширения модели метаданных для нужд LinkedIn, эти расширения обычно очень специфичны для LinkedIn и могут не применяться напрямую к другим средам. Например, у нас есть очень специфические метки для идентификаторов участников и других типов метаданных соответствия. Итак, в настоящее время мы исключили эти расширения из модели метаданных DataHub с открытым исходным кодом. По мере того, как мы взаимодействуем с сообществом и понимаем их потребности, мы будем работать над общими версиями этих расширений с открытым исходным кодом, где это необходимо.
Простота использования и более легкая адаптация для сообщества открытого исходного кода также вдохновили некоторые различия между двумя версиями DataHub. Различия в инфраструктуре потоковой обработки — хороший тому пример. Хотя наша внутренняя версия использует инфраструктуру управляемой потоковой обработки, мы решили использовать встроенную (автономную) потоковую обработку для версии с открытым исходным кодом, поскольку она позволяет избежать создания еще одной зависимости инфраструктуры.
Другой пример различия — наличие одного GMS (Обобщенное хранилище метаданных) в реализации с открытым исходным кодом, а не нескольких GMS. GMA (Обобщенная архитектура метаданных) — это название внутренней архитектуры для DataHub, а GMS — это хранилище метаданных в контексте GMA. GMA — очень гибкая архитектура, которая позволяет вам распределять каждую конструкцию данных (например, наборы данных, пользователей и т. д.) В собственное хранилище метаданных или хранить несколько конструкций данных в одном хранилище метаданных до тех пор, пока реестр, содержащий отображение структуры данных в GMS обновляется. Для простоты использования мы выбрали один экземпляр GMS, который хранит все различные конструкции данных в DataHub с открытым исходным кодом.
Полный список различий между двумя реализациями приведен в таблице ниже.
| Product Features | LinkedIn DataHub | Open Source DataHub |
|---|---|---|
| Supported Data Constructs | 1) Datasets 2) Users 3) Metrics 4) ML Features 5) Charts 6) Dashboards | 1) Datasets 2) Users |
| Supported Metadata Sources for Datasets | 1) Ambry 2) Couchbase 3) Dalids 4) Espresso 5) HDFS 6) Hive 7) Kafka 8) MongoDB 9) MySQL 10) Oracle 11) Pinot 12) Presto 12) Seas 13) Teradata 13) Vector 14) Venice | Hive Kafka RDBMS |
| Pub-sub | LinkedIn Kafka | Confluent Kafka |
| Stream Processing | Managed | Embedded (standalone) |
| Dependency Injection & Dynamic Configuration | LinkedIn Offspring | Spring |
| Build Tooling | Ligradle (LinkedIn’s internal Gradle wrapper) | Gradlew |
| CI/CD | CRT (LinkedIn’s internal CI/ CD) | TravisCI and Docker Hub |
| Metadata Stores | Distributed multiple GMS: 1) Dataset GMS 2) User GMS 3) Metric GMS 4) Feature GMS 5) Chart/Dashboard GMS | Single GMS for: 1) Datasets 2) Users |
Микросервисы в контейнерах Docker
Docker упрощает развертывание и распространение приложений с помощью контейнеризации. Каждая часть сервиса в DataHub с открытым исходным кодом, включая компоненты инфраструктуры, такие как Kafka, Elasticsearch, Neo4j и MySQL, имеет свой собственный образ Docker. Для оркестрации контейнеров Docker мы использовали Docker Compose.

Рисунок 2: Архитектура DataHub *с открытым исходным кодом**
Вы можете увидеть высокоуровневую архитектуру DataHub на картинке выше. Помимо компонентов инфраструктуры, у него есть четыре разных контейнера Docker:
datahub-gms: служба хранилища метаданных
datahub-frontend: приложение Play, обслуживающее интерфейс DataHub.
datahub-mce-consumer: приложение Kafka Streams, которое использует поток событий изменения метаданных (MCE) и обновляет хранилище метаданных.
datahub-mae-consumer: приложение Kafka Streams, которое использует поток событий аудита метаданных (MAE) и создает базу данных поискового индекса и графа.
Документация по репозиторию с открытым исходным кодом и исходная запись в блоге DataHub содержат более подробную информацию о функциях различных служб.
CI / CD в DataHub с открытым исходным кодом
Репозиторий DataHub с открытым исходным кодом использует TravisCI для непрерывной интеграции и Docker Hub для непрерывного развертывания. Оба имеют хорошую интеграцию с GitHub и просты в настройке. Для большей части инфраструктуры с открытым исходным кодом, разработанной сообществом или частными компаниями (например, Confluent), созданы образы Docker, и они развертываются в Docker Hub для упрощения использования сообществом. Любой образ Docker, найденный в Docker Hub, можно легко использовать с помощью простой команды docker pull.
При каждом коммите в репозитории с открытым исходным кодом DataHub все образы Docker автоматически создаются и развертываются в Docker Hub с тегом «latest». Если в Docker Hub настроено некоторое именование веток регулярных выражений, все теги в репозитории с открытым исходным кодом также выпускаются с соответствующими именами тегов в Docker Hub.
Использование DataHub
Настройка DataHub очень проста и состоит из трех простых шагов:
- Клонируйте репозиторий с открытым исходным кодом и запустите все контейнеры Docker с помощью docker-compose с помощью предоставленного сценария docker-compose для быстрого запуска.
- Загрузите образцы данных, представленные в репозитории, с помощью инструмента командной строки, который также предоставляется.
- Просмотрите DataHub в своем браузере.
Активно отслеживаемый чат Gitter также настроен для быстрых вопросов. Пользователи также могут создавать проблемы прямо в репозитории GitHub. Самое главное, мы приветствуем и ценим все отзывы и предложения!
Планы на будущее
В настоящее время каждая инфраструктура или микросервис для DataHub с открытым исходным кодом построена как контейнер Docker, а вся система оркестрируется с помощью docker-compose. Учитывая популярность и широкое распространение Kubernetes, мы также хотели бы предоставить решение на основе Kubernetes в ближайшем будущем.
Мы также планируем предоставить готовое решение для развертывания DataHub в общедоступной облачной службе, такой как Azure, AWS или Google Cloud. Учитывая недавнее объявление о миграции LinkedIn на Azure, это будет соответствовать внутренним приоритетам группы метаданных.
И последнее, но не менее важное: спасибо всем первым пользователям DataHub в сообществе с открытым исходным кодом, которые оценили альфа-версии DataHub и помогли нам выявить проблемы и улучшить документацию.

