
Сентябрьскую подборку мы начнем с кейса. В этот раз он всего один, но зато какой!
Мы не устаем восхищаться возможностями GPT-3 и рассказывать о сферах ее применения, но многие при этом видят в алгоритме угрозу своей профессии.
И компания VMO, которая занимается A/B тестированием, решила провести соревнование — профессиональные копирайтеры против GPT-3.
Они интегрировали алгоритм в свой визуальный редактор так, чтобы пользователи могли выбирать между сгенерированными и авторскими текстами. Пока что сервис позволяет только генерировать заголовки, описания товаров и услуг, а также кнопки-призывы к действию.
Почему это так интересно? Дело в том, что в продуктовом менеджменте и маркетинге очень много ресурсов уходит на проверку гипотез. Какой заголовок лучше повысит вовлеченность, или какого цвета и формы должна быть кнопка, чтобы клиент совершил целевое действие. Ответы на эти вопросы позволяют продуктам становится успешными.
Исход конкретно этого противостояния пока ничего не решит, но представьте, если бы алгоритм мог не только генерировать тексты, но и отслеживать поведение пользователей и видоизменять интерфейс. А теперь вспомните, что GPT-3 умеет верстать и создавать react-компоненты. Именно поэтому следить за этим экспериментом очень интересно. На момент написания материала GPT-3 лидирует с небольшим отрывом, посмотрим, чем все закончится.
Ну а теперь к остальным находкам прошлого месяца:
Wav2Lip
Модель генерирует движения губ под речь, синхронизируя таким образом аудио и видео потоки. Её можно использовать для онлайн-трансляций, пресс-конференций, а также дубляжа фильмов. На демо можно увидеть, как губы Тони Старка подстраиваются под дубляж на разных языках. Также при ухудшении связи во время скайп-звонков модель может генерировать кадры, которые были потеряны из-за сбоя в сигнале, и дорисовывать их на основе звукового потока. Еще создатели предлагают анимировать губы персонажей мемов для большей персонализации контента. Как и цифровые дикторы, эта модель умеет подстраивать движение губ под речь, сгенерированную из текста.
Примечательно, что в мае авторы опубликовали модель Lip2Wav, которая наоборот “читает по губам” и генерирует текст и звук. Свёрточная нейронная сеть извлекает визуальные характеристики, после чего речевой декодер генерирует на их основе мел-спектрограмму, и с помощью вокодера синтезируется голос.

Flow-edge Guided Video Completion
Новый алгоритм дополнения видео, который убирает водяные знаки и целые движущиеся объекты, а также расширяет поле зрения видео с учетом движения кадра. Как и другие похожие алгоритмы, сначала он определяет и восстанавливает края движущихся объектов. Дорисованные границы в таком случае не выглядят естественно в сцене. Особенность метода в том, что он отслеживает пять типов не локально соседствующих пикселей, то есть, находящихся на разных кадрах, затем определяет, каким из них можно доверять, и использует эти данные для восстановления недостающих областей. В результате видео получается более плавным. Уже можно ознакомиться с исходным кодом, скоро будет добавлен колаб.

X-Fields
Нейросеть обучали на сериях снимков одной сцены с размеченными координатами угла обзора, временными метками и параметрами освещения. Так она научилась интерполировать эти параметры и выводить промежуточные изображения. То есть, получив несколько снимков с постепенно тающим кубиком льда или пустеющим бокалом на входе, модель в реальном времени может генерировать изображения с учетом всевозможных комбинаций параметров. Чтобы было проще понять, о чем речь, советуем просто посмотреть видео-демонстрацию. Исходный код обещают в скором времени опубликовать.

Generative Image Inpainting
Очередной инструмент для удаления объектов с фотографий на основе генеративной нейронной сети. На этот раз это полноценный фреймворк с открытым исходным кодом и публичным API. Работает очень просто — загружаете изображение и рисуете маску объекта, который хотите удалить, и — готово, никакого дополнительного постпроцессинга. Проект развернут на веб сервере, поэтому можете легко протестировать прямо в браузере. Артефакты, конечно, есть, но с простыми изображениями справляется неплохо.

Portrait Shadow Manipulation
Портретные фотографии часто страдают от неправильного освещения. Положение и мягкость теней а также распределение света являются ограничениями окружающей среды, которые влияют на эстетические качества снимка. Для устранения нежелательных затенений больше не обязателен фоторедактор — исследователи из Беркли представили алгоритм с открытым исходным кодом, который реалистично убирает затенения с фото и позволяет управлять освещением.
PSFR-GAN
Не менее распространенная задача при работе с фотографиями — это их реставрация и улучшение качества. Этот опенсорсный инструмент неплохо повышает разрешение портретных снимков.

FrankMocap
В этом месяце вышло сразу несколько интересных инструментов для 3D-моделирования. Все, кто работал с 3D, знают, что для создания качественных моделей нужно различное дорогое фотооборудование и умение пользоваться сложным софтом. Но алгоритмы машинного обучения активно используются, чтобы упростить работу художников в этой области.
Facebook AI представил систему создания 3D-мокапов рук и тела на основе анализа монокулярного видео. Захват движений работает в режиме, близком к реальному времени (9,5 кадра в секунду), и создает трехмерные изображения тела и рук в виде унифицированной параметрической модели. В отличии от других существующих подходов, этот позволяет одновременно захватывать и жесты рук, и движения всего тела. Исходный код уже доступен.
3DDFA
Другой инструмент, который также появился в этом месяце, способен по видеозаписи размечать лицо человека для создания трехмерной маски.

PSOHA
Еще одна технология от Facebook AI, которая также призвана упростить процесс 3D-моделирования — нейросеть извлекает множество связей между человеком на изображении и остальными объектами и генерирует трехмерные мокапы. Таким образом, на основе всего одной фотографии, на которой изображен человек с каким-то повседневным предметом, создается 3D-модель. Алгоритм определяет формы людей и объектов, а также их пространственное расположение в естественных условиях, в неконтролируемой среде. Создатели обещают скоро выложить исходный код, поэтому пока остается верить примерам из демонстрации, которые, не будем лукавить, впечатляют.
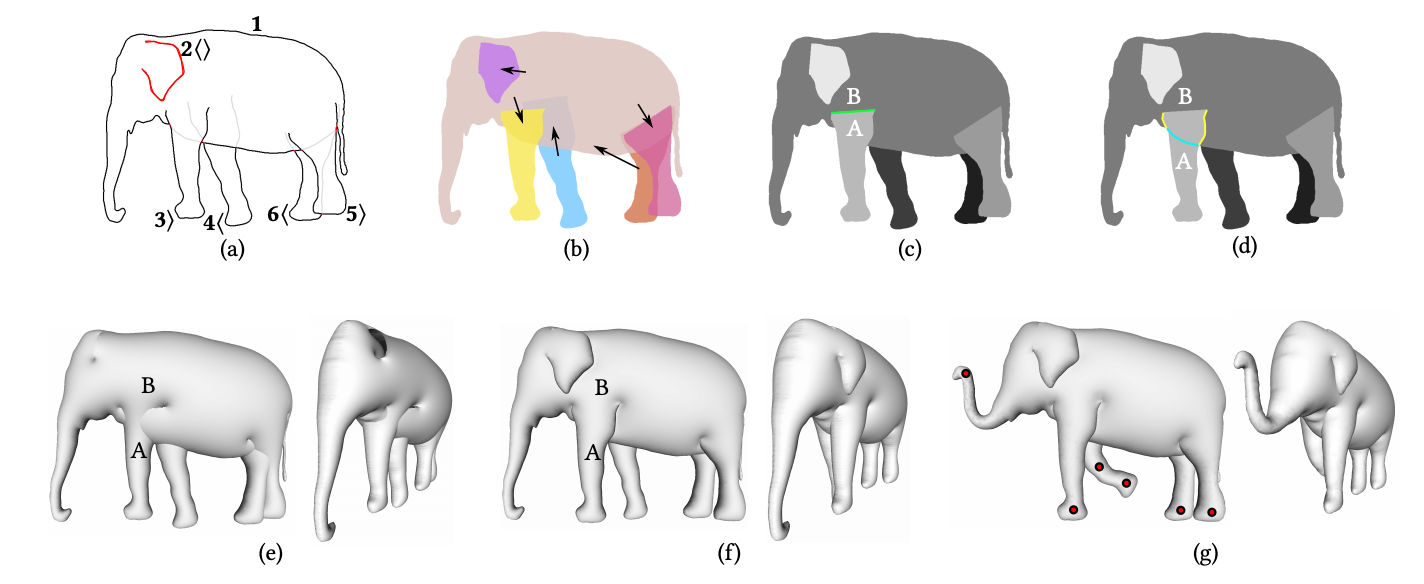
Monster Mash
Новый фреймворк позволяет создавать и анимировать трехмерные объекты, используя всего один набросок. Это существенно упрощает процесс анимирования объектов, так как не нужно работать с кейфреймами, многоракурсной сеткой и скелетной анимацией. Модель создает трехмерную модель, которая сразу готова к созданию анимаций без долгой предварительной настройки разных параметров, которые, например, не позволяют объектам проходить сквозь друг друга.

ShapeAssembly
Алгоритм создает трехмерные модели мебели из прямоугольных параллелепипедов. Подход ShapeAssembly использует сильные стороны процедурных и глубоких генеративных моделей: с помощью первого подхода фиксируется подмножество изменчивости формы, которое можно интерпретировать и редактировать, а с помощью второго модель фиксирует изменчивость и корреляции между формами, которые трудно выразить процедурно. В сети уже шутят, что на следующем шаге нужно обучить эмбеддер на основе инструкций IKEA.
На этом закончим тему с 3D моделированием — для этой области месяц выдался особенно насыщенным. Спасибо за внимание!

