
Приложений для конвертации данных в БД очень много и у каждого есть какая-то особенность. Так как сам пишу универсальное приложение ImportExportDataSql для импорта/экспорта данных (пока только Microsoft SQL Server и под Windows), то хочу собрать статистику о том, какими функциями вы пользуетесь в подобных приложениях и за что Вам нравится то или иное приложение?
Надеюсь, что у Вас найдется пару минут, чтобы принять участие в опросе.
Немного о ImportExportDataSql
Приложение ImportExportDataSql бесплатное, без рекламы, оповещает о новых версиях, наличие командной строки и Вы можете скачать его и использовать в своих проектах.
С помощью ImportExportDataSql Вы сможете:
- быстро загружать CSV файлы большого объема (более 1Гб) в SQL Server
- загружать Excel файлы и CSV с возможностью настройки полей, а также с ограничением количества обрабатываемых строк (удобно при отладке)
- выгружать выборочные данные из БД, в SQL формате и затем выполнять этот скрипт на другой БД (т.е. использовать как средство синхронизации данных)
- копировать джобы с одной машины на другую
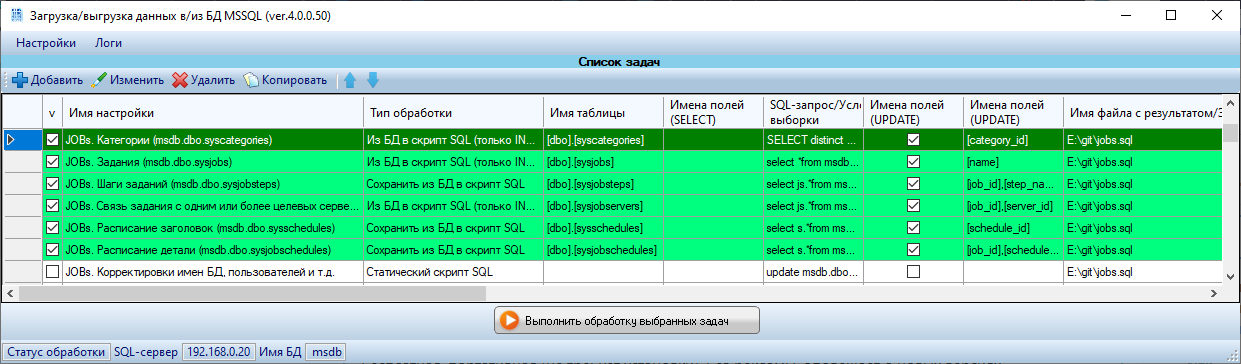
- выгружать структуру БД.
Главной особенностью ImportExportDataSql, является то, что можно объединять несколько SELECT запросов, выгружая результат в виде SQL в один файл.
Добавляйтесь в группу VK, пишите свои пожелания, буду рад доработать приложение под Ваши нужды.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Выберите форматы файлов, которыми пользуетесь при переносе данных:
74.19%CSV46
33.87%Excel21
59.68%SQL37
17.74%DBF11
29.03%XML18
37.1%JSON23
Проголосовали 62 пользователя. Воздержались 3 пользователя.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Как часто загружаете изображения и другие файлы в БД (в поле типа BINARY)?
3.64%Часто2
40%Редко22
56.36%Никогда31
Проголосовали 55 пользователей. Воздержались 3 пользователя.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Для переноса данных между двумя БД, не имеющих прямого доступа, предпочитаете использовать:
46.81%утилиты с командной строкой от производителя СУБД (например, bcp)22
27.66%ETL решения13
36.17%операцию BULK INSERT17
53.19%дамп в SQL формате25
Проголосовали 47 пользователей. Воздержались 8 пользователей.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Экспорт/импорт пространственных полей (geography, geometry)
4.26%Часто2
14.89%Редко7
80.85%Никогда38
Проголосовали 47 пользователей. Воздержались 4 пользователя.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Средний объем файла (CSV, SQL, XML, DBF и т.д.), который обычно загружается в БД
35.42%До 50 Мб17
25%До 500 Мб12
22.92%До 1Гб11
16.67%От 1Гб и выше8
Проголосовали 48 пользователей. Воздержались 5 пользователей.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Чаще всего файлы в БД загружаете:
33.33%по расписанию16
35.42%автоматически, по мере прихода данных17
68.75%вручную, по мере прихода данных33
Проголосовали 48 пользователей. Воздержались 4 пользователя.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Выберите СУБД, которыми пользуетесь:
19.64%Oracle11
44.64%MySQL25
58.93%Microsoft SQL Server33
48.21%PostgreSQL27
10.71%Firebird6
19.64%MongoDB11
10.71%Microsoft Access6
23.21%другие13
Проголосовали 56 пользователей. Воздержались 5 пользователей.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Как часто приходится выгружать структуру БД?
26%Часто13
60%Редко30
14%Никогда7
Проголосовали 50 пользователей. Воздержались 4 пользователя.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
На каких операционных системах разрабатываете приложения?
64.15%Windows34
28.3%Linux15
7.55%MacOS4
Проголосовали 53 пользователя. Воздержались 3 пользователя.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Выберите пункты, которые наиболее важны при выборе средства экспорта/импорта?
78.26%простота использования (быстрое освоение приложения, например: в течении 1 часа)36
36.96%быстрота развертывания (установка и настройка)17
41.3%наличие командной строки19
26.09%замер времени выполнения операции12
45.65%портативное (без установки)21
65.22%быстродействие30
Проголосовали 46 пользователей. Воздержались 4 пользователя.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
На данный момент, какие используете приложения для конвертации данных?
20%Платные9
60%Бесплатные27
62.22%Свои наработки28
15.56%Никакие7
Проголосовали 45 пользователей. Воздержались 4 пользователя.

