Подождите! Подождите! Правда, это не очередная статья про типы бэкапов SQL Server. Я даже не буду рассказывать про отличия моделей восстановления и как бороться с разросшимся "логом".
Возможно (только возможно), после прочтения этого поста, вы сможете сделать так, чтобы бэкап, который снимается у вас стандартными средствами, завтра ночью снялся, ну, в 1.5 раза быстрее. И только за счёт того, что вы используете чуть-чуть больше параметров BACKUP DATABASE.
Если для вас содержимое поста было очевидным - извините. Я прочитал всё, до чего добрался гугл по фразе "habr sql server backup", и ни в одной статье не нашёл упоминания о том, что на время бэкапа можно каким-то образом повлиять с помощью параметров.
Сразу же обращу ваше внимание на комментарий Александра Гладченко (@mssqlhelp):
Никогда не меняйте парамеры BUFFERCOUNT, BLOCKSIZE, MAXTRANSFERSIZE на проде. Они сделаны только для написания подобных статей. На практике огребёте проблемы с памятью по поной.
Было бы, конечно, круто, оказаться самым умным и выложить эксклюзивный контент, но это, к сожалению, не так. Есть и англоязычные, и русскоязычные статьи/посты (всегда путаюсь как их правильно называть), посвящённые этой теме. Вот часть из тех, что попались мне: раз, два, три (на sql.ru).
Итак, для начала приложу несколько урезанный синтаксис BACKUP из MSDN (кстати, там выше я писал про BACKUP DATABASE, но всё это применимо и к бэкапу журнала транзакций, и к дифференциальному бэкапу, но, возможно, с менее явным эффектом):
BACKUP DATABASE { database_name | @database_name_var } TO <backup_device> [ ,...n ] <...> [ WITH { <...> | <general_WITH_options> [ ,...n ] } ] [;] <general_WITH_options> [ ,...n ]::= <...> --Media Set Options <...> | BLOCKSIZE = { blocksize | @blocksize_variable } --Data Transfer Options BUFFERCOUNT = { buffercount | @buffercount_variable } | MAXTRANSFERSIZE = { maxtransfersize | @maxtransfersize_variable } <...>
<...> - значит, что там что-то было, но я это убрал, потому что сейчас это к теме не относится.
Как вы обычно снимаете бэкап? Как "учат" снимать бэкап в миллиардах статей? Вообще, если нужно будет разово снять бэкап какой-то не очень большой базы, я автоматически напишу что-то вроде вот такого:
BACKUP DATABASE smth TO DISK = 'D:\Backup\smth.bak' WITH STATS = 10, CHECKSUM, COMPRESSION, COPY_ONLY; --ладно, CHECKSUM я написал только чтобы казаться умнее
И, в общем-то, тут перечислено, наверное 75-90% всех параметров, которые обычно упоминаются в статьях о бэкапах. Ну там INIT, SKIP ещё. А вы ходили в MSDN? Вы видели, что там опций на полтора экрана? Я вот тоже видел...
Наверное, вы уже поняли, что дальше речь пойдёт о трёх параметрах, которые остались в первом блоке кода - BLOCKSIZE, BUFFERCOUNT и MAXTRANSFERSIZE. Вот их описания из MSDN:
BLOCKSIZE = { blocksize | @ blocksize_variable } — указывает размер физического блока в байтах. Поддерживаются размеры 512, 1024, 2048, 4096, 8192, 16 384, 32 768 и 65 536 байт (64 КБ). Значение по умолчанию равно 65 536 для ленточных устройств и 512 для других устройств. Обычно в этом параметре нет необходимости, так как инструкция BACKUP автоматически выбирает размер блока, соответствующий устройству. Явная установка размера блока переопределяет автоматический выбор размера блока.
BUFFERCOUNT = { buffercount | @ buffercount_variable } — определяет общее число буферов ввода-вывода, которые будут использоваться для операции резервного копирования. Можно указать любое целое положительное значение, однако большое число буферов может вызвать ошибку нехватки памяти из-за чрезмерного виртуального адресного пространства в процессе Sqlservr.exe.
Общий объем пространства, используемого буферами, определяется по следующей формуле:
BUFFERCOUNT * MAXTRANSFERSIZE.
MAXTRANSFERSIZE = { maxtransfersize | @ maxtransfersize_variable } указывает наибольший объем пакета данных в байтах для обмена данными между SQL Server и носителем резервного набора. Поддерживаются значения, кратные 65 536 байтам (64 КБ), вплоть до 4 194 304 байт (4 МБ).
Клянусь - я читал это раньше, но мне и в голову не приходило, какое влияние на производительность они могут оказывать. Более того, видимо, нужно сделать своеобразный "каминг-аут" и признать, что даже сейчас я не до конца понимаю, что именно они делают. Наверное, надо побольше почитать про буферизированный ввод-вывод и работу с жёстким диском. Когда-нибудь я это сделаю, а сейчас могу просто написать скрипт, который проверит как эти значения влияют на скорость, с которой снимается бэкап.
Сделал небольшую базу, размером около 10 ГБ, положил её на SSD, а каталог для бэкапов положил на HDD.
Создаю временную таблицу для хранения результатов (у меня она не временная, чтобы можно было поковырять результаты подробнее, но вы уж сами решайте):
DROP TABLE IF EXISTS ##bt_results; CREATE TABLE ##bt_results ( id int IDENTITY (1, 1) PRIMARY KEY, start_date datetime NOT NULL, finish_date datetime NOT NULL, backup_size bigint NOT NULL, compressed_size bigint, block_size int, buffer_count int, transfer_size int );
Принцип работы скрипта простой - вложенные циклы, каждый из которых меняет значение одного параметра, подсовываю в команду BACKUP эти параметры, сохраняю последнюю запись с историей из msdb.dbo.backupset, удаляю файл бэкапа и следующая итерация. Поскольку данные о выполнении бэкапа берутся из backupset, точность несколько теряется (там нет долей секунд), но это мы переживём.
Сначала нужно разрешить использование xp_cmdshell, чтобы удалять бэкапы (потом не забудьте отключить, если он вам не нужен):
EXEC sp_configure 'show advanced options', 1; EXEC sp_configure 'xp_cmdshell', 1; RECONFIGURE; EXEC sp_configure 'show advanced options', 0; GO
Ну и, собственно:
DECLARE @tmplt AS nvarchar(max) = N' BACKUP DATABASE [bt] TO DISK = ''D:\SQLServer\backup\bt.bak'' WITH COMPRESSION, BLOCKSIZE = {bs}, BUFFERCOUNT = {bc}, MAXTRANSFERSIZE = {ts}'; DECLARE @sql AS nvarchar(max); /* BLOCKSIZE values */ DECLARE @bs int = 4096, @max_bs int = 65536; /* BUFFERCOUNT values */ DECLARE @bc int = 7, @min_bc int = 7, @max_bc int = 800; /* MAXTRANSFERSIZE values */ DECLARE @ts int = 524288, --512KB, default = 1024KB @min_ts int = 524288, @max_ts int = 4194304; --4MB SELECT TOP 1 @bs = COALESCE (block_size, 4096), @bc = COALESCE (buffer_count, 7), @ts = COALESCE (transfer_size, 524288) FROM ##bt_results ORDER BY id DESC; WHILE (@bs <= @max_bs) BEGIN WHILE (@bc <= @max_bc) BEGIN WHILE (@ts <= @max_ts) BEGIN SET @sql = REPLACE (REPLACE (REPLACE(@tmplt, N'{bs}', CAST(@bs AS nvarchar(50))), N'{bc}', CAST (@bc AS nvarchar(50))), N'{ts}', CAST (@ts AS nvarchar(50))); EXEC (@sql); INSERT INTO ##bt_results (start_date, finish_date, backup_size, compressed_size, block_size, buffer_count, transfer_size) SELECT TOP 1 backup_start_date, backup_finish_date, backup_size, compressed_backup_size, @bs, @bc, @ts FROM msdb.dbo.backupset ORDER BY backup_set_id DESC; EXEC xp_cmdshell 'del "D:\SQLServer\backup\bt.bak"', no_output; SET @ts += @ts; END SET @bc += @bc; SET @ts = @min_ts; WAITFOR DELAY '00:00:05'; END SET @bs += @bs; SET @bc = @min_bc; SET @ts = @min_ts; END
Если вдруг вам нужны пояснения по тому, что здесь происходит - пишите в комментарии, или личку. Пока расскажу только про параметры, которые подсовываю в BACKUP DATABASE.
Для BLOCKSIZE у нас "закрытый" список значений, причём у меня не выполнялся бэкап с BLOCKSIZE < 4КБ. MAXTRANSFERSIZE любое число кратное 64КБ - от 64КБ до 4МБ. По-умолчанию на моей системе 1024КБ, я взял 512 - 1024 - 2048 - 4096.
Сложнее было с BUFFERCOUNT - он может быть любым положительным числом, а вот по ссылке написано как он рассчитывается в BACKUP DATABASE и чем опасны большие значения. Там же написано как получить информацию о том, с каким BUFFERCOUNT реально снимается бэкап - у меня это 7. Уменьшать его смысла не было, а верхняя граница была обнаружена опытным путём - при BUFFERCOUNT = 896 и MAXTRANSFERSIZE = 4194304 бэкап упал с ошибкой (о которой написано по ссылке выше):
Msg 3013, Level 16, State 1, Line 7 BACKUP DATABASE is terminating abnormally.
Msg 701, Level 17, State 123, Line 7 There is insufficient system memory in resource pool 'default' to run this query.
Для сравнения, сначала покажу результаты выполнения бэкапа без указания параметров вообще:
BACKUP DATABASE [bt] TO DISK = 'D:\SQLServer\backup\bt.bak' WITH COMPRESSION;
Ну, бэкап и бэкап:
Processed 1070072 pages for database 'bt', file 'bt' on file 1.
Processed 2 pages for database 'bt', file 'bt_log' on file 1.
BACKUP DATABASE successfully processed 1070074 pages in 53.171 seconds (157.227 MB/sec).
Сам скрипт, тестирующий параметры, отработал за пару часов, все замеры в гугл таблице. А вот выборка результатов, имеющих три лучших времени выполнения (я пытался сделать красивый график, но, в посте, придётся обойтись табличкой, а в комментариях @mixsture добавил очень крутые графики).
SELECT TOP 7 WITH TIES compressed_size, block_size, buffer_count, transfer_size, DATEDIFF(SECOND, start_date, finish_date) AS backup_time_sec FROM ##bt_results ORDER BY backup_time_sec ASC;
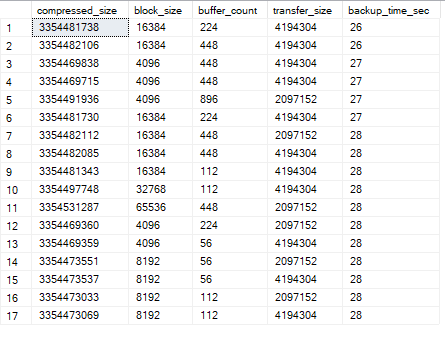
Внимание, сразу очень важное замечание от @mixsture из комментария:
уверенно можно сказать, что связь между параметрами и скоростью бекапа в этих пределах значений случайна, никакой закономерности нет. Но отход от встроенных параметров, очевидно, хорошо повлиял на результат
Т.е. только за счёт управления стандартными параметрами BACKUP был получен выигрыш во времени снятия бэкапа в 2 раза: 26 секунд, против 53 в начале. А неплохо ведь, да? Но нужно посмотреть что там с восстановлением. А вдруг теперь восстанавливаться будет в 4 раза дольше?
Для начала замерим, сколько происходит восстановление бэкапа с настройками по умолчанию:
RESTORE DATABASE [bt] FROM DISK = 'D:\SQLServer\backup\bt.bak' WITH REPLACE, RECOVERY;
Ну это вы и сами знаете, пути там, replace-не replace, recovery-не recovery. И у меня выполняется это так:
Processed 1070072 pages for database 'bt', file 'bt' on file 1.
Processed 2 pages for database 'bt', file 'bt_log' on file 1.
RESTORE DATABASE successfully processed 1070074 pages in 40.752 seconds (205.141 MB/sec).
А теперь попробую восстановить бэкапы, снятые с изменёнными BLOCKSIZE, BUFFERCOUNT и MAXTRANSFERSIZE.
BLOCKSIZE = 16384, BUFFERCOUNT = 224, MAXTRANSFERSIZE = 4194304RESTORE DATABASE successfully processed 1070074 pages in 32.283 seconds (258.958 MB/sec).
BLOCKSIZE = 4096, BUFFERCOUNT = 448, MAXTRANSFERSIZE = 4194304RESTORE DATABASE successfully processed 1070074 pages in 32.682 seconds (255.796 MB/sec).
BLOCKSIZE = 16384, BUFFERCOUNT = 448, MAXTRANSFERSIZE = 2097152RESTORE DATABASE successfully processed 1070074 pages in 32.091 seconds (260.507 MB/sec).
BLOCKSIZE = 4096, BUFFERCOUNT = 56, MAXTRANSFERSIZE = 4194304RESTORE DATABASE successfully processed 1070074 pages in 32.401 seconds (258.015 MB/sec).
Инструкция RESTORE DATABASE при восстановлении не меняется, в ней не указываются эти параметры, SQL Server сам их определяет по бэкапу. И видно, что даже при восстановлении может быть выигрыш - практически на 20% быстрее (честно говоря, не много времени уделил восстановлению, протыкал несколько самых "быстрых" бэкапов и убедился, что ухудшения нет).
На всякий случай уточню - здесь описаны не какие-то оптимальные для всех параметры. Оптимальные параметры для себя вы можете получить только тестированием. Я получил такие результаты, вы получите другие. Но вы видите, что свои бэкапы можно "потюнить" и они реально могут формироваться и разворачиваться быстрее.
Ещё настоятельно рекомендую, прочитать-таки документацию целиком, потому что именно для вашей системы могут быть нюансы.
Раз уж начал писать про бэкапы, хочу сразу написать ещё об одной "оптимизации", которая встречается чаще, чем "тюнинг" параметров (её же, насколько я понимаю, использует как минимум часть утилит для резервного копирования, возможно, вместе с параметрами, описанными ранее), но на Хабре она тоже пока не была описана.
Если посмотреть на вторую строчку в документации, сразу под BACKUP DATABASE, там мы видим:
TO <backup_device> [ ,...n ]
Как вы думаете, что будет, если указать несколько backup_device'ов? Синтаксис ведь позволяет. А будет очень интересная вещь - бэкап просто "размажется" по нескольким девайсам. Т.е. каждый "девайс" по-отдельности будет бесполезен, потеряли один, потеряли весь бэкап. Но как такое размазывание скажется на скорости резервного копирования?
Попробуем сделать бэкап на два "девайса", которые лежат рядышком в одной папке:
BACKUP DATABASE [bt] TO DISK = 'D:\SQLServer\backup\bt1.bak', DISK = 'D:\SQLServer\backup\bt2.bak' WITH COMPRESSION;
Батюшки-светы, да что ж это делается-то?
Processed 1070072 pages for database 'bt', file 'bt' on file 1.
Processed 2 pages for database 'bt', file 'btlog' on file 1.
BACKUP DATABASE successfully processed 1070074 pages in 40.092 seconds (208.519 MB/sec).
Бэкап сделался на 25% быстрее просто на ровном месте? А если ещё пару устройств добавить?
BACKUP DATABASE [bt] TO DISK = 'D:\SQLServer\backup\bt1.bak', DISK = 'D:\SQLServer\backup\bt2.bak', DISK = 'D:\SQLServer\backup\bt3.bak', DISK = 'D:\SQLServer\backup\bt4.bak' WITH COMPRESSION;
BACKUP DATABASE successfully processed 1070074 pages in 34.234 seconds (244.200 MB/sec).
Итого, выигрыш около 35% времени снятия бэкапа только за счёт того, что бэкап пишется сразу в 4 файла на одном диске. Проверял большее количество - на моём ноуте выигрыш отсутствует, оптимально - 4 устройства. Для вас - не знаю, нужно проверять. Ну и, кстати, если у вас эти устройства - это реально разные диски, поздравляю, выигрыш должен быть ещё значительнее.
Теперь поговорим как это счастье восстановить. Для этого придётся менять команду восстановления и перечислять все девайсы:
RESTORE DATABASE [bt] FROM DISK = 'D:\SQLServer\backup\bt1.bak', DISK = 'D:\SQLServer\backup\bt2.bak', DISK = 'D:\SQLServer\backup\bt3.bak', DISK = 'D:\SQLServer\backup\bt4.bak' WITH REPLACE, RECOVERY;
RESTORE DATABASE successfully processed 1070074 pages in 38.027 seconds (219.842 MB/sec).
Чуть-чуть быстрее, но где-то рядом, не существенно. В общем, бэкап снимается быстрее, а восстанавливается так же - успех? Как по мне - вполне себе успех. Это важно, поэтому повторюсь - если вы теряете хотя бы один из этих файлов - теряете весь бэкап.
Если посмотреть в журнале информацию о бэкапе, выводимую с помощью Trace Flag 3213 и 3605, то можно обратить внимание, что при бэкапе в несколько устройств, увеличивается, как минимум количество BUFFERCOUNT. Наверное, можно попробовать подобрать более оптимальные параметры и для BUFFERCOUNT, BLOCKSIZE, MAXTRANSFERSIZE, но у меня сходу не получилось, а проводить такое тестирование ещё раз, но для разного количества файлов я поленился. Да и диски жалко. Если вы хотите организовать такое тестирование у себя, скрипт переделать не сложно.
В конце поговорим о цене. Если бэкап снимается параллельно с работой пользователей - нужно очень ответственно подойти к тестированию, поскольку если бэкап снимается быстрее - диски напрягаются сильнее, нагрузка на процессор возрастает (надо же это всё ещё и сжимать налету), соответственно, снижается общая отзывчивость системы.
Шутки-шутками, но прекрасно понимаю, что никаких откровений не сделал. То, что написано выше - это просто демонстрация того, как можно подобрать оптимальные параметры для снятия бэкапов.
Помните, что всё, что вы делаете - вы делаете на свой страх и риск. Проверяйте свои резервные копии и не забывайте про DBCC CHECKDB.

