Site Reliability Engineering (SRE) — это одна из форм реализации DevOps. SRE-подход возник в Google и стал популярен в среде продуктовых IT-компаний после выхода одноимённой книги в 2016 году.
В статье опишем, как SRE-подход соотносится с DevOps, какие задачи решает инженер по SRE и о каких показателях заботится.

От DevOps к SRE
Во многих IT-компаниях разработкой и эксплуатацией занимаются разные команды с разными целями. Цель команды разработки — выкатывать новые фичи. Цель команды эксплуатации — обеспечить работу старых и новых фич в продакшене. Разработчики стремятся поставить как можно больше кода, системные администраторы — сохранить надёжность системы.
Цели команд противоречат друг другу. Чтобы разрешить эти противоречия, была создана методология DevOps. Она предполагает уменьшение разрозненности, принятие ошибок, опору на автоматизацию и другие принципы.
Проблема в том, что долгое время не было чёткого понимания, как воплощать принципы DevOps на практике. Редкая конференция по этой методологии обходилась без доклада «Что такое DevOps?». Все соглашались с заложенными идеями, но мало кто понимал, как их реализовать.
Ситуация изменилась в 2016 году, когда Google выпустила книгу «Site Reliability Engineering». В этой книге описывалась конкретная реализация DevOps. С неё и началось распространение SRE-подхода, который сейчас применяется во многих международных IT-компаниях.
DevOps — это философия. SRE — реализация этой философии. Если DevOps — это интерфейс в языке программирования, то SRE — конкретный класс, который реализует DevOps.
Цели и задачи SRE-инженера
Инженеры по SRE нужны, когда в компании пытаются внедрить DevOps и разработчики не справляются с возросшей нагрузкой.
В отличие от классического подхода, согласно которому эксплуатацией занимается обособленный отдел, инженер по SRE входит в команду разработки. Иногда его нанимают отдельно, иногда им становится кто-то из разработчиков. Есть подход, где роль SRE переходит от одного разработчика к другому.
Цель инженера по SRE — обеспечить надёжную работу системы. Он занимается тем же, что раньше входило в задачи системного администратора, — решает инфраструктурные проблемы.
Как правило, инженерами SRE становятся опытные разработчики или, реже, администраторы с сильным бэкграундом в разработке. Кто-то скажет: «программист в роли инженера — не лучшее решение». Возможно и так, если речь идёт о новичке. Но в случае SRE мы говорим об опытном разработчике. Это человек, который хорошо знает, что и когда может сломаться. У него есть опыт и внутри компании, и снаружи.
Предпочтение не просто так отдаётся разработчикам. Имея сильный бэкграунд в программировании и зная систему с точки зрения кода, они более склонны к автоматизации, чем к рутинной администраторской работе. Кроме того, они имеют больший багаж знаний и навыков для внедрения автоматизации.
В задачи инженера по SRE входит ревью кода. Нужно, чтобы на каждый деплой SRE сказал: «OK, это не повлияет на надёжность, а если повлияет, то в допустимых пределах». Он следит, чтобы сложность, которая влияет на надёжность работы системы, была необходимой.
- Необходимая — сложность системы повышается в том объёме, которого требуют новые продуктовые фичи.
- Случайная — сложность системы повышается, но продуктовая фича и требования бизнеса напрямую на это не влияют. Тут либо разработчик ошибся, либо алгоритм не оптимален.
Хороший SRE блокирует любой коммит, деплой или пул-реквест, который повышает сложность системы без необходимости. В крайнем случае SRE может наложить вето на изменение кода (и тут неизбежны конфликты, если действовать неправильно).
Во время ревью SRE взаимодействует с оунерами изменений, от продакт-менеджеров до специалистов по безопасности.
Кроме того, инженер по SRE участвует в выборе архитектурных решений. Оценивает, как они повлияют на стабильность всей системы и как соотносятся с бизнес-потребностями. Отсюда уже делает вывод — допустимы нововведения или нет.
Целевые показатели: SLA, SLI, SLO
Одно из главных противоречий между отделом эксплуатации и разработки происходит из разного отношения к надёжности системы. Если для отдела эксплуатации надёжность — это всё, то для разработчиков её ценность не так очевидна.
SRE подход предполагает, что все в компании приходят к общему пониманию. Для этого определяют, что такое надёжность (стабильность, доступность и т. д.) системы, договариваются о показателях и вырабатывают стандарты действий в случае проблем.
Показатели доступности вырабатываются вместе с продакт-оунером и закрепляются в соглашении о целевом уровне обслуживания — Service-Level Objective (SLO). Оно становится гарантом, что в будущем разногласий не возникнет.
Специалисты по SRE рекомендуют указывать настолько низкий показатель доступности, насколько это возможно. «Чем надёжнее система, тем дороже она стоит. Поэтому определите самый низкий уровень надёжности, который может сойти вам с рук, и укажите его в качестве SLO», сказано в рекомендациях Google. Сойти с рук — значит, что пользователи не заметят разницы или заметят, но это не повлияет на их удовлетворенность сервисом.
Чтобы понимание было ясным, соглашение должно содержать конкретные числовые показатели — Service Level Indicator (SLI). Это может быть время ответа, количество ошибок в процентном соотношении, пропускная способность, корректность ответа — что угодно в зависимости от продукта.
SLO и SLI — это внутренние документы, нужные для взаимодействия команды. Обязанности компании перед клиентами закрепляются в в Service Level Agreement (SLA). Это соглашение описывает работоспособность всего сервиса и штрафы за превышение времени простоя или другие нарушения.
Примеры SLA: сервис доступен 99,95% времени в течение года; 99 критических тикетов техподдержки будет закрыто в течение трёх часов за квартал; 85% запросов получат ответы в течение 1,5 секунд каждый месяц.
Почему никто не стремится к 100% доступности
SRE исходит из предположения, что ошибки и сбои неизбежны. Более того, на них рассчитывают.
Оценивая доступность, говорят о «девятках»:
- две девятки — 99%,
- три девятки — 99,9%,
- четыре девятки — 99,99%,
- пять девяток — 99,999%.
Пять девяток — это чуть больше 5 минут даунтайма в год, две девятки — это 3,5 дня даунтайма.

Стремиться к повышению доступности нормально, однако чем ближе она к 100%, тем выше стоимость и техническая сложность сервиса. В какой-то момент происходит уменьшение ROI — отдача инвестиций снижается.
Например, переход от двух девяток к трём уменьшает даунтайм на три с лишним дня в год. Заметный прогресс! А вот переход с четырёх девяток до пяти уменьшает даунтайм всего на 47 минут. Для бизнеса это может быть не критично. При этом затраты на повышение доступности могут превышать рост выручки.
При постановке целей учитывают также надёжность окружающих компонентов. Пользователь не заметит переход стабильности приложения от 99,99% к 99,999%, если стабильность его смартфона 99%. Грубо говоря, из 10 сбоев приложения 8 приходится на ОС. Пользователь к этому привык, поэтому на один лишний раз в год не обратит внимания.
Среднее время между сбоями и среднее время восстановления — MTBF и MTTR
Для работы с надёжностью, ошибками и ожиданиями в SRE применяют ещё два показателя: MTBF и MTTR.
MTBF (Mean Time Between Failures) — среднее время между сбоями.
Показатель MTBF зависит от качества кода. Инженер по SRE влияет на него через ревью и возможность сказать «Нет!». Здесь важно понимание команды, что когда SRE блокирует какой-то коммит, он делает это не из вредности, а потому что иначе страдать будут все.
MTTR (Mean Time To Recovery)— среднее время восстановления (сколько прошло от появления ошибки до отката к нормальной работе).
Показатель MTTR рассчитывается на основе SLO. Инженер по SRE влияет на него за счёт автоматизации. Например, в SLO прописан аптайм 99,99% на квартал, значит, у команды есть 13 минут даунтайма на 3 месяца. В таком случае время восстановления никак не может быть больше 13 минут, иначе за один инцидент весь «бюджет» на квартал будет исчерпан, SLO нарушено.
13 минут на реакцию — это очень мало для человека, поэтому здесь нужна автоматизация. Что человек сделает за 7-8 минут, скрипт — за несколько секунд. При автоматизации процессов MTTR очень часто достигает секунд, иногда миллисекунд.
В идеале инженер по SRE должен полностью автоматизировать свою работу, потому что это напрямую влияет на MTTR, на SLO всего сервиса и, как следствие, на прибыль бизнеса.
Обычно при внедрении автоматизации стараются оценивать время на подготовку скрипта и время, которое этот скрипт экономит. По интернету ходит табличка, которая показывает, как долго можно автоматизировать задачу:
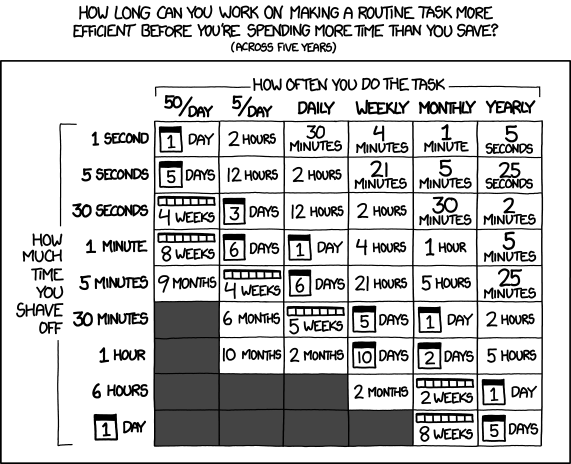
Всё это справедливо, но не относится к работе SRE. По факту, практически любая автоматизация от SRE имеет смысл, потому что экономит не только время, но и деньги, и моральные силы сотрудников, уменьшает рутину. Всё это вместе положительно сказывается на работе и на бизнесе, даже если кажется, что с точки зрения временных затрат автоматизация не имеет смысла.
Бюджет на ошибки
Как мы выяснили, пытаться достичь 100% стабильности не самая лучшая идея, потому что это дорого, технически сложно, а часто и бесполезно — скорее всего, пользователь не оценит старания из-за проблем в «соседних» системах.
Поэтому команды всегда принимают некоторую степень риска и прописывают её в SLO. На основе SLO рассчитывается бюджет на ошибки (Error budget).

Бюджет на ошибки помогает разработчикам договариваться с SRE.
Если бюджет на ошибки содержит 43 минуты даунтайма в месяц, и 40 минут из них сервис уже лежал, то очевидно: чтобы оставаться в рамках SLO, надо сократить риски. Как вариант, остановить выпуск фич и сосредоточиться на баг-фиксах.
Если бюджет на ошибки не исчерпан, то у команды остаётся пространство для экспериментов. В рамках SRE подхода Error budget можно тратить буквально на всё:
- релиз фич, которые могут повлиять на производительность,
- обслуживание,
- плановые даунтаймы,
- тестирование в условиях продакшена.
Чтобы не выйти за рамки, Error budget делят на несколько частей в зависимости от задач. Каждая команда должна оставаться в пределах своего бюджета на ошибки.

В ситуации «профицитного» бюджета на ошибки заинтересованы все: и SRE, и разработчики. Для разработчиков такой бюджет сулит возможность заниматься релизами, тестами, экспериментами. Для SRE является показателем хорошей работы.
Эксперименты в продакшене — это важная часть SRE в больших командах. С подачи команды Netflix её называют Chaos Engineering.
В Netflix выпустили несколько утилит для Chaos Engineering: Chaos Monkey подключается к CI/CD пайплайну и роняет случайный сервер в продакшене; Chaos Gorilla полностью выключает одну из зон доступности в AWS. Звучит дико, но в рамках SRE считается, что упавший сервер — это само по себе не плохо, это ожидаемо. И если это входит в бюджет на ошибки, то не вредит бизнесу.
Chaos Engineering помогает:
- Выявить скрытые зависимости, когда не совсем понятно, что на что влияет и от чего зависит (актуально при работе с микросервисами).
- Выловить ошибки в коде, которые нельзя поймать на стейджинге. Любой стейджинг — это не точная симуляция: другой масштаб и паттерн нагрузок, другое оборудование.
- Отловить ошибки в инфраструктуре, которые стейджинг, автотесты, CI/CD-пайплайн никогда не выловят.
Post mortem вместо поиска виноватых
В SRE придерживаются культуры blameless postmortem, когда при возникновении ошибок не ищут виноватых, а разбирают причины и улучшают процессы.
Предположим, даунтайм в квартал был не 13 минут, а 15. Кто может быть виноват? SRE, потому что допустил плохой коммит или деплой; администратор дата-центра, потому что провел внеплановое обслуживание; технический директор, который подписал договор с ДЦ и не обратил внимания, что его SLA не поддерживает нужный даунтайм. Все понемногу виноваты, значит, нет смысла возлагать вину на кого-то одного. В таком случае организуют постмортемы и правят процессы.
Мониторинг и прозрачность
Без мониторинга нельзя понять, вписывается ли команда в бюджет и соблюдает ли критерии, описанные в SLO. Поэтому задача инженера по SRE — настроить мониторинг. Причём настроить его так, чтобы уведомления приходили только тогда, когда требуются действия.
В стандартном случае есть три уровня событий:
- алерты — требуют немедленного действия («чини прямо сейчас!»);
- тикеты — требуют отложенного действия («нужно что-то делать, делать вручную, но не обязательно в течение следующих нескольких минут»);
- логи — не требуют действия, и при хорошем развитии событий никто их не читает («о, на прошлой неделе у нас микросервис отвалился, пойди посмотри в логах, что случилось»).
SRE определяет, какие события требуют действий, а затем описывает, какими эти действия должны быть, и в идеале приходит к автоматизации. Любая автоматизация начинается с реакции на событие.
С мониторингом связан критерий прозрачности (Observability). Это метрика, которая оценивает, как быстро вы можете определить, что именно пошло не так и каким было состояние системы в этот момент.
С точки зрения кода: в какой функции или сервисе произошла ошибка, каким было состояние внутренних переменных, конфигурации. С точки зрения инфраструктуры: в какой зоне доступности произошел сбой, а если у вас стоит какой-нибудь Kubernetes, то в каком поде, каким было его состояние при этом.
Observability напрямую связана с MTTR. Чем выше Observability сервиса, тем проще определить ошибку, исправить и автоматизировать, и тем ниже MTTR.
SRE для небольших компаний и компаний без разработки
SRE работает везде, где нужно выкатывать апдейты, менять инфраструктуру, расти и масштабироваться. Инженеры по SRE помогают предсказать и определить возможные проблемы, сопутствующие росту. Поэтому они нужны даже в тех компаниях, где основная деятельность не разработка ПО. Например, в энтерпрайзе.
При этом необязательно нанимать на роль SRE отдельного человека, можно сделать роль переходной, а можно вырастить человека внутри команды. Последний вариант подходит для стартапов. Исключение — жёсткие требования по росту (например, со стороны инвесторов). Когда компания планирует расти в десятки раз, тогда нужен человек, ответственный за то, что при заданном росте ничего не сломается.
Внедрять принципы SRE можно с малого: определить SLO, SLI, SLA и настроить мониторинг. Если компания не занимается ПО, то это будут внутренние SLA и внутренние SLO. Обсуждение этих соглашений приводит к интересным открытиям. Нередко выясняется, что компания тратит на инфраструктуру или организацию идеальных процессов гораздо больше времени и сил, чем надо.
Кроме того, для любой компании полезно принять, что ошибки — это нормально, и начать работать с ними. Определить Error budget, стараться тратить его на развитие, а возникающие проблемы разбирать и по результатам разбора внедрять автоматизацию.
Что почитать
В одной статье невозможно рассказать всё об SRE. Вот подборка материалов для тех, кому нужны детали.
Книги об SRE от Google:
Site Reliability Engineering
The Site Reliability Workbook
Building Secure & Reliable Systems
Статьи и списки статей:
SRE как жизненный выбор
SLA, SLI, SLO
Принципы Chaos Engineering от Chaos Community и от Netflix
Список из более чем 200 статей по SRE
Доклады по SRE в разных компаниях (видео):
Keys to SRE
SRE в Дропбоксе
SRE в Гугл
SRE в Нетфликсе
Где поучиться
Одно дело читать о новых практиках, а другое дело — внедрять их. Если вы хотите глубоко погрузиться в тему, приходите на курс по SRE от Слёрма. Он пройдет 6–27 декабря 2022.
Научим формулировать показатели SLO, SLI, SLA, разрабатывать архитектуру и инфраструктуру, которая их обеспечит, настраивать мониторинг и алёртинг. Мы создали собственное приложение по продаже билетов для кинотеатров, на котором учащиеся в общей сумме больше 16 часов примеряют на себя роль SRE-инженеров и решают реальные задачи. Еженедельные теоретические лекции и ама-сессии со спикерами помогут понять, какие практики нужны именно вашему бизнесу и как их успешно внедрить.
На практическом примере рассмотрим внутренние и внешние факторы ухудшения SLO: ошибки разработчиков, отказы инфраструктуры, наплыв посетителей, DoS-атаки. Разберёмся в устойчивости, Error budget, практике тестирования, управлении прерываниями и операционной нагрузкой.

