Продолжение (начало – здесь)
1.3. Поисковые системы – специализированные и не очень
В общем случае результаты поиска в первую очередь зависят от поставленной задачи и корректности запроса. Но эти результаты чаще всего, с одной стороны,
а) избыточны
и с другой стороны — б) неполны.
К счастью, и авторы и издатели, как правило, заинтересованы в том, чтобы информация о публикациях индексировалась поисковиками, но тут есть нюансы: не всегда разрешается индексация содержимого pdf-файлов, и в некоторых случаях разрешена индексация сайтов только определёнными поисковиками (например, крупнейшая отечественная электронная библиотека elibrary.ru одно время запрещала для google индексацию большинства файлов).
Кроме всего прочего, результаты запроса зависят от порядка слов и от IP-адреса, с которого осуществляется поиск.
Если говорить о поиске публикаций, то вопрос «какой поисковой системой пользоваться» имеет один ответ – Google (это если не считать специализированные библиографические поисковые системы, о них ниже).
Во-первых, google достаточно полно индексирует содержимое Сети. Во-вторых, большое количество настроек расширенного поиска (в т.ч. с использование операторов) сильно облегчают работу. В третьих, как я уже указывал, содержимое пдф-файлов googl’ом индексируется даже в том случае, когда пдф состоит из изображений и текстовый слой в файле отсутствует.

Ка известно, в гугле любят пошутить. Вот такой у меня однажды вылез результат при попытке найти книгу Pander, C. H. (1830). Beiträge zur Geognosie des Russischen Reiches. St.Petersburg, Karl Kray. 150 S.

Настройки расширенного поиска google. На Яндексе, к сожалению, большая часть настроек расширенного поиска из имевшихся ранее давно сгинула, остались мелочи типа поиска по расширению файла (только вместо гугловского filetype: используется оператор mime: )
Для поиска публикаций наиболее полезными являются расширенные настройки и операторы, позволяющие ограничивать поиск файлами определённого формата (например, pdf c помощью filetype:pdf ), определёнными сайтами / доменами. Например, если мне понадобится посмотреть, на каких китайских сайтах выложены публикации в формате pdf, где упоминаются аммониты, то поможет вот такой запрос: ammonites filetype:pdf site:cn. Ну а "+" и "-" используются для указания обязательных или нежелательных терминов. К примеру, при поиски информации по головоногим моллюскам — аммонитам обычно не нужны сведения об одноимённом взрывчатом веществе или племени, некогда обитавшем на Ближнем Востоке и регулярно упоминающемся в Библии. Соответственно, запрос можно подкорректировать таким образом: аммониты filetype:pdf -взрывчатка -Библия
Если ищется какая-то конкретная публикация, то желательно часть её названия или всё название взять в кавычки.
Ещё немаловажно, что у гугла есть два отдельных проекта, имеющих прямое отношение к поиску публикаций:
1) Google books – это фактически отдельная поисковая система, индексирующая содержимое огромного количества книг, журналов, сборников и других изданий. При этом существенная часть публикаций доступна для скачивания в виде пдф (как правило, это старые издания, от начала ХХ века и старше); в зависимости от IP список доступных для скачивания изданий может существенно различаться, максимально число работ доступно пользователям из США.
Довольно много публикаций доступно для просмотра целиком или частично. Такие работы можно скачать с помощью специальных программ типа EDS Google Book downloader или плагинов (таких как Greasemonkey для Mozilla в сочетании с программой для автоматической загрузки файлов, например Download Master).
И, наконец, немалую пользу можно получить даже от той информации, которая присутствует в публикациях, которые вообще недоступны для просмотра в каком-либо виде кроме фрагментов в несколько строк (snippet view). С такими публикациями, правда, есть две основные сложности:
а) можно, конечно, попробовать поискать такие работы где-то ещё, но вероятность того что с ними можно будет ознакомиться только в библиотеке довольно велика.
б) в названиях источников (особенно тех, которые исходно даны не латиницей) путаницы очень и очень много, и отображаемая информация обычно неполна.
Тем не менее информация, содержащаяся в таких фрагментах может быть очень важной и практически не находимой другими способами

Так выглядит типичный вариант выдачи на google books в формате snippet view: как правило, отсутствует часть нужной библиографической информации (номер выпуска для журнала, иногда — важные части названия издания). Хорошо, если у журнала выходит 2 номера в год. А если 20? А если название указано с ошибкой?
2) Google Scholar (в русскоязычном варианте Академия Google ). Это библиографическая поисковая система, которая неплохо ищет как сами статьи, так и ссылки на них, заодно позволяя сразу скопировать названия публикаций, отформатированные согласно популярным типам цитирования (APA, Harvard, ГОСТ и т.д.). К числу удобств данной системы стоит отнести то, что индексируются не только сайты издателей, но и специализированные социальные сети и самые разные сайты, где нередко безвозмездно выкладываются научные работы, и все ссылки на полнотекстовые версии группируются в единый кластер. Тем не менее, Google Scholar индексирует не все публикации – это легко проверить с помощью идентичного поискового запроса «ключевые слова» filetype:pdf в Google и Google Scholar. Особенно это ярко это различие проявляется с редко встречающимися ключевыми словами.
Ну а наиболее полезная функция google scholar – это возможность подписки на самые разные оповещения (об этом подробнее — в продолжении данного поста)
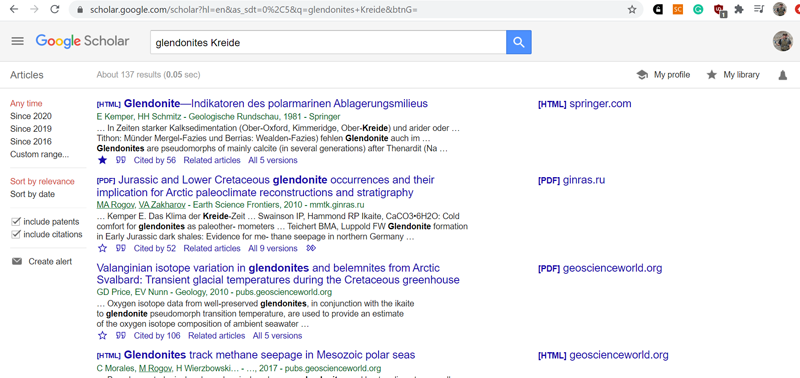
Выдача поиска по ключевым словам на google scholar. Обратите внимание на варианты сортировки, возможности выбора временного диапазона и кластеры статей.
Библиографические поисковые системы (БПС), ориентированные на работу с публикациями, сейчас весьма разнообразны и многочисленны. Кроме перечисленных выше проектов Google можно отметить следующие сайты, которые могут рассматриваться как БПС:
1) сайты, индексирующие огромное количество публикаций по всему миру. В первую очередь это Scopus и Web of Science, доступные по подписке (в случае со Scopus доступ также предоставляется рецензентам Elsevier’овских журналов), а также крупнейший сайт, присваивающий DOI публикациям (CrossRef) или агрегатор информации о публикациях, грантах, исследователях и т.д. Dimensions.
Все они кроме Dimensions позволяют искать информацию по ограниченному массиву данных – это преимущественно название / ключевые слова / резюме. В худшую сторону тут выделяется CrossRef – там поиск идёт только по названию, причём со строгой привязкой к форме слова. Правда, в CrossRef существенно больше проиндексировано русскоязычных публикаций, чем в других БПС из этого пункта, и плюс к тому это наиболее удобный способ решить задачу типа «у меня есть название публикации, надо найти её DOI» (все DOI так не найти – это не единственный регистратор цифровых идентификаторов к публикациям, есть ещё DataCite, например – но универсального сервиса для решения такой задачи, как ни странно, просто нет).
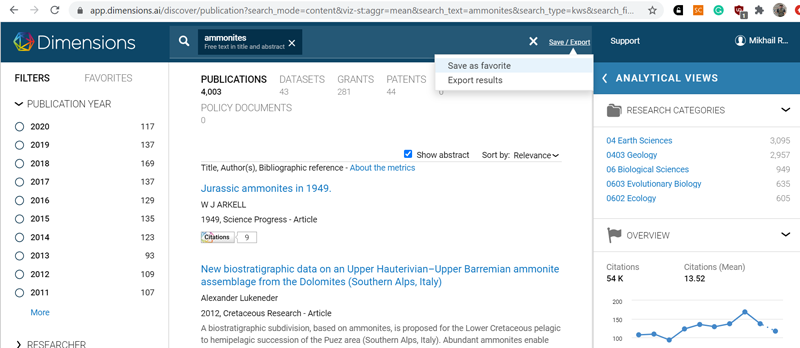
Простой поиск в Dimensions
Dimensions – совсем недавно появившийся очень интересный проект, в первую очередь благодаря множеству самых разнообразных настроек, широкому охвату публикаций (индексируются только публикации с DOI, их пока немного меньше чем есть на CrossRef) и полнотекстовому поиску. Вернее, тут можно выбирать разные опции поиска (полнотекстовый / по резюме / по названию и ключевым словам). Результаты можно сортировать самыми разнообразными способами (дата / релевантность / число ссылок / число альтметрик), и ограничивать по разным параметрам (источник / автор / годы / тематика и многое другое ). У Dimensions есть разные версии (включая платную и корпоративную), здесь рассматривается только бесплатный вариант (с другими пока не доводилось иметь дело). Отдельно можно искать информацию как по публикациям, так и по базам данных и грантам (последняя опция доступна только по подписке).
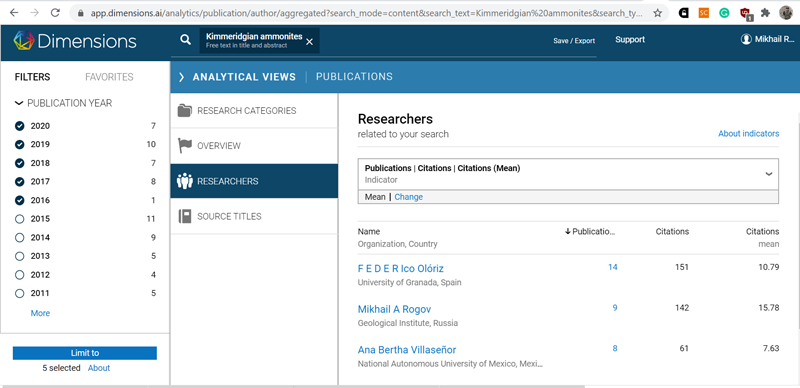
Во вкладке Analytical view можно посмотреть, например, кто или в каких журналах публиковался по интересующей нас тематике в то или иное время (в данном случае — с 2016 по 2020 годы). Ну а нажав на фамилию автора, можно посмотреть с кем вместе он публиковался, в каких журналах и т.д.
Дополнительные опции предлагаются во вкладке Analytical view. Они позволяют легко понять, кто сейчас или в любом выбранном временном диапазоне занимается той или иной тематикой, в какие журналы эти люди пишут статьи и с какими соавторами. Это удобный способ для поиска потенциальных соавторов и рецензентов, особенно для тех, кто только начал заниматься какой-либо тематикой и не очень хорошо себе представляет что с ней в мировом масштабе делается. Для тех исследователей, у которых в статьях имеется ORCID, в профиле приводится и этот идентификатор, и Scopus author ID, а также (при наличии) цепляющийся к ним «автоматом» ResearcherID / профиль на Publons. Повторюсь – Dimensions это крайне полезный проект, причём интуитивно понятный. Можно просто тыкать на все кнопки подряд и залезать во все вкладки.
2) также в качестве специализированных БПС можно рассматривать сайты крупнейших международных издателей (Elsevier, Wiley, Springer, Taylor & Francis и т.д.) и распространителей (Ingentaconnect, GeoscienceWorld) научных изданий. Впрочем, ограничение результатов поиска тем или иным издателем или распространителем на пользу, как правило, не идёт и скорее может быть полезно для того, чтобы кратко ознакомиться с той или иной темой.
3) в какой-то мере функции БПС выполняют научные социальные сети (Academia.edu, ResearchGate ), а также «гибрид» социальный сети и библиографического менеджера Mendeley (доступна как оффлайн-версия в виде программы, так и её онлайн-вариант; сейчас, после покупки Mendeley компанией Elsevier там доступны многие опции Scopus). Впрочем, содержимое научных социальных сетей хорошо индексируется googl’ом, и тут разве что есть смысл регулярно просматривать ленту обновлений в поисках чего-нибудь совсем нового.
4) в отдельную категорию БПС можно выделить региональные или специализированные сайты, где в основном имеются данные о публикациях, изданных в какой-либо стране или нескольких странах (например, Национальная электронная библиотека elibrary.ru в России, Национальный институт информатики в Японии, Национальная библиотека Франции ), а также специализированные сайты, посвящённые каким-то конкретным научным направлениям (например, BiodiversityHeritageLibrary (BHL))
Характерной особенностью таких порталов является то, что они крайне неохотно дают индексировать своё содержимое сторонним поисковикам, так что если нужно найти что-то французское или японское – надёжнее заглянуть на соответствующие сайты и поискать там.
До недавнего времени на сайте Национальной библиотеки Франции весь интерфейс был франкоязычный, пока они туда в конце концов не приделали сначала англоязычную версию сайта, а затем и автоматический перевод по IP
Отдельно следует сказать про BHL. Это крайне полезный проект для всех исследователей, которые так или иначе связаны с изучением современных или ископаемых организмов. Данную библиотеку отличает широкий охват источников (включая разные редкости) и наличие специальных поисковых инструментов (таких как поиск по таксону во вкладке Advanced search – если кто-то собирает материалы по той или иной группе животных и растений, это очень хороший способ быстро найти публикации по теме). Из недостатков BHL можно отметить то, что нередко текстовый слой может быть распознан неверно (с ошибочно выбранным языком), а также чудовищное качество иллюстраций по умолчанию (качество плохого размытого .djvu ).
Поскольку для таксономических исследований качество изображений обычно имеет большое значение, то здесь наиболее правильным подходом является скачивание нужной публикации в формате jp2, а потом – обработка файлов (сначала переформатирование в обычный jpg / tiff, потом обработка ScanTailor и OCR). Кстати, все публикации с BHL размещаются на archive.org, и иногда удобнее проводить полнотекстовый поиск именно по archive.org (это может быть актуально в случае поиска каких-либо редкостей – тут может попасться кое-что интересное, в том числе загруженное пользователями.
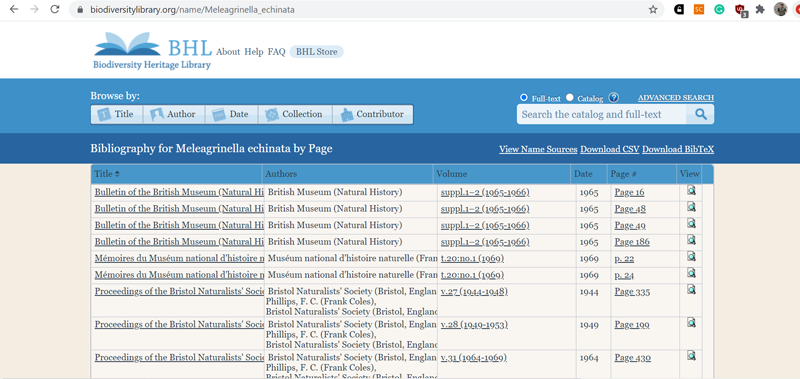
Пример выдачи при поиске по таксону на BHL

Если нужен качественный пдф — лучше сохранить файл способом «Download Content — Download book — Download JPEG 2000», а потом обработать
И, конечно, в случае необходимости найти русскоязычные публикации не обойтись без поиска в elibrary в сочетании с cyberleninka. Хотя в elibrary охват источников намного больше, регулярно встречается ситуация, когда в elibrary за ту или иную статью предлагают заплатить – а на сайте Киберленинки та же статья лежит в отрытом доступе.
Несмотря на ряд недостатков, заложенных в elibrary, кажется, с рождения (отсутствие возможности скачать даже работу открытого доступа без ввода логина / пароля; отсутствие англоязычной версии и опции подписки на те или иные обновления) поиск там достаточно приличный. Но если есть необходимость регулярно отслеживать информацию по русскоязычным журналам, стоит сделать также отдельный каталог ссылок на сайты необходимых изданий – на elibrary не угадаешь, когда и почему они могут вдруг закрыть доступ к тем или иным изданиям. И ещё один момент – в том случае, когда журнал отсутствует в открытом доступе и распространяется только за деньги как через elibrary, так и через сайт издательства, то на сайте издательства статьи могут быть дешевле (такова ситуация, например, с журналом «Нефтяное хозяйство»).

Настройки расширенного поиска на elibrary (на заглавной странице сайта — слева сверху ссылка «расширенный поиск»). Здесь же сохраняется история предыдущих поисковых запросов
5) в качестве БПС можно рассматривать и крупнейшие «пиратские» проекты, обеспечивающие свободный доступ к научным публикациям – SciHub и LibGen, поскольку на них в том или ином виде реализована возможность поиска по названию публикации или ключевым словам.
И если sci-hub может быть скорее использован в качестве удобного дополнения к поиску на Dimensions, то на LibGen регулярно появляются редкие монографии, которых в других местах нет – они сканируются энтузиастами и размещаются на ЛибГене в частном порядке.
И напоследок отдельно стоит сказать про поиск диссертаций. Хотя многие диссертации (как современные российские, так и иногда достаточно старые зарубежные) выложены в Интернете в открытом доступе и индексируются поисковиками, для получения информации о свежих диссертациях, которые только планируется защитить, имеет смысл заглядывать на сайт ВАКа. Там сейчас диссертации можно искать по специальностям, ключевым словам, дате защиты и другим параметрам (при этом отдельно поиск ведётся по ВАКовским диссертациям, а отдельно – по тем, которые защищаются на советах организаций, обладающих правом самостоятельного присуждения степеней). Но есть нюанс – если у вас установлен uBlock Origin, то он блокирует поиск по данному сайту.

Пример поиска по сайту ВАК
Продолжение: часть 3
1.3. Поисковые системы – специализированные и не очень
В общем случае результаты поиска в первую очередь зависят от поставленной задачи и корректности запроса. Но эти результаты чаще всего, с одной стороны,
а) избыточны
и с другой стороны — б) неполны.
К счастью, и авторы и издатели, как правило, заинтересованы в том, чтобы информация о публикациях индексировалась поисковиками, но тут есть нюансы: не всегда разрешается индексация содержимого pdf-файлов, и в некоторых случаях разрешена индексация сайтов только определёнными поисковиками (например, крупнейшая отечественная электронная библиотека elibrary.ru одно время запрещала для google индексацию большинства файлов).
Кроме всего прочего, результаты запроса зависят от порядка слов и от IP-адреса, с которого осуществляется поиск.
Если говорить о поиске публикаций, то вопрос «какой поисковой системой пользоваться» имеет один ответ – Google (это если не считать специализированные библиографические поисковые системы, о них ниже).
Во-первых, google достаточно полно индексирует содержимое Сети. Во-вторых, большое количество настроек расширенного поиска (в т.ч. с использование операторов) сильно облегчают работу. В третьих, как я уже указывал, содержимое пдф-файлов googl’ом индексируется даже в том случае, когда пдф состоит из изображений и текстовый слой в файле отсутствует.
Ка известно, в гугле любят пошутить. Вот такой у меня однажды вылез результат при попытке найти книгу Pander, C. H. (1830). Beiträge zur Geognosie des Russischen Reiches. St.Petersburg, Karl Kray. 150 S.
Настройки расширенного поиска google. На Яндексе, к сожалению, большая часть настроек расширенного поиска из имевшихся ранее давно сгинула, остались мелочи типа поиска по расширению файла (только вместо гугловского filetype: используется оператор mime: )
Для поиска публикаций наиболее полезными являются расширенные настройки и операторы, позволяющие ограничивать поиск файлами определённого формата (например, pdf c помощью filetype:pdf ), определёнными сайтами / доменами. Например, если мне понадобится посмотреть, на каких китайских сайтах выложены публикации в формате pdf, где упоминаются аммониты, то поможет вот такой запрос: ammonites filetype:pdf site:cn. Ну а "+" и "-" используются для указания обязательных или нежелательных терминов. К примеру, при поиски информации по головоногим моллюскам — аммонитам обычно не нужны сведения об одноимённом взрывчатом веществе или племени, некогда обитавшем на Ближнем Востоке и регулярно упоминающемся в Библии. Соответственно, запрос можно подкорректировать таким образом: аммониты filetype:pdf -взрывчатка -Библия
Если ищется какая-то конкретная публикация, то желательно часть её названия или всё название взять в кавычки.
Ещё немаловажно, что у гугла есть два отдельных проекта, имеющих прямое отношение к поиску публикаций:
1) Google books – это фактически отдельная поисковая система, индексирующая содержимое огромного количества книг, журналов, сборников и других изданий. При этом существенная часть публикаций доступна для скачивания в виде пдф (как правило, это старые издания, от начала ХХ века и старше); в зависимости от IP список доступных для скачивания изданий может существенно различаться, максимально число работ доступно пользователям из США.
Довольно много публикаций доступно для просмотра целиком или частично. Такие работы можно скачать с помощью специальных программ типа EDS Google Book downloader или плагинов (таких как Greasemonkey для Mozilla в сочетании с программой для автоматической загрузки файлов, например Download Master).
И, наконец, немалую пользу можно получить даже от той информации, которая присутствует в публикациях, которые вообще недоступны для просмотра в каком-либо виде кроме фрагментов в несколько строк (snippet view). С такими публикациями, правда, есть две основные сложности:
а) можно, конечно, попробовать поискать такие работы где-то ещё, но вероятность того что с ними можно будет ознакомиться только в библиотеке довольно велика.
б) в названиях источников (особенно тех, которые исходно даны не латиницей) путаницы очень и очень много, и отображаемая информация обычно неполна.
Тем не менее информация, содержащаяся в таких фрагментах может быть очень важной и практически не находимой другими способами
Так выглядит типичный вариант выдачи на google books в формате snippet view: как правило, отсутствует часть нужной библиографической информации (номер выпуска для журнала, иногда — важные части названия издания). Хорошо, если у журнала выходит 2 номера в год. А если 20? А если название указано с ошибкой?
2) Google Scholar (в русскоязычном варианте Академия Google ). Это библиографическая поисковая система, которая неплохо ищет как сами статьи, так и ссылки на них, заодно позволяя сразу скопировать названия публикаций, отформатированные согласно популярным типам цитирования (APA, Harvard, ГОСТ и т.д.). К числу удобств данной системы стоит отнести то, что индексируются не только сайты издателей, но и специализированные социальные сети и самые разные сайты, где нередко безвозмездно выкладываются научные работы, и все ссылки на полнотекстовые версии группируются в единый кластер. Тем не менее, Google Scholar индексирует не все публикации – это легко проверить с помощью идентичного поискового запроса «ключевые слова» filetype:pdf в Google и Google Scholar. Особенно это ярко это различие проявляется с редко встречающимися ключевыми словами.
Ну а наиболее полезная функция google scholar – это возможность подписки на самые разные оповещения (об этом подробнее — в продолжении данного поста)
Выдача поиска по ключевым словам на google scholar. Обратите внимание на варианты сортировки, возможности выбора временного диапазона и кластеры статей.
Библиографические поисковые системы (БПС), ориентированные на работу с публикациями, сейчас весьма разнообразны и многочисленны. Кроме перечисленных выше проектов Google можно отметить следующие сайты, которые могут рассматриваться как БПС:
1) сайты, индексирующие огромное количество публикаций по всему миру. В первую очередь это Scopus и Web of Science, доступные по подписке (в случае со Scopus доступ также предоставляется рецензентам Elsevier’овских журналов), а также крупнейший сайт, присваивающий DOI публикациям (CrossRef) или агрегатор информации о публикациях, грантах, исследователях и т.д. Dimensions.
Все они кроме Dimensions позволяют искать информацию по ограниченному массиву данных – это преимущественно название / ключевые слова / резюме. В худшую сторону тут выделяется CrossRef – там поиск идёт только по названию, причём со строгой привязкой к форме слова. Правда, в CrossRef существенно больше проиндексировано русскоязычных публикаций, чем в других БПС из этого пункта, и плюс к тому это наиболее удобный способ решить задачу типа «у меня есть название публикации, надо найти её DOI» (все DOI так не найти – это не единственный регистратор цифровых идентификаторов к публикациям, есть ещё DataCite, например – но универсального сервиса для решения такой задачи, как ни странно, просто нет).
Простой поиск в Dimensions
Dimensions – совсем недавно появившийся очень интересный проект, в первую очередь благодаря множеству самых разнообразных настроек, широкому охвату публикаций (индексируются только публикации с DOI, их пока немного меньше чем есть на CrossRef) и полнотекстовому поиску. Вернее, тут можно выбирать разные опции поиска (полнотекстовый / по резюме / по названию и ключевым словам). Результаты можно сортировать самыми разнообразными способами (дата / релевантность / число ссылок / число альтметрик), и ограничивать по разным параметрам (источник / автор / годы / тематика и многое другое ). У Dimensions есть разные версии (включая платную и корпоративную), здесь рассматривается только бесплатный вариант (с другими пока не доводилось иметь дело). Отдельно можно искать информацию как по публикациям, так и по базам данных и грантам (последняя опция доступна только по подписке).
Во вкладке Analytical view можно посмотреть, например, кто или в каких журналах публиковался по интересующей нас тематике в то или иное время (в данном случае — с 2016 по 2020 годы). Ну а нажав на фамилию автора, можно посмотреть с кем вместе он публиковался, в каких журналах и т.д.
Дополнительные опции предлагаются во вкладке Analytical view. Они позволяют легко понять, кто сейчас или в любом выбранном временном диапазоне занимается той или иной тематикой, в какие журналы эти люди пишут статьи и с какими соавторами. Это удобный способ для поиска потенциальных соавторов и рецензентов, особенно для тех, кто только начал заниматься какой-либо тематикой и не очень хорошо себе представляет что с ней в мировом масштабе делается. Для тех исследователей, у которых в статьях имеется ORCID, в профиле приводится и этот идентификатор, и Scopus author ID, а также (при наличии) цепляющийся к ним «автоматом» ResearcherID / профиль на Publons. Повторюсь – Dimensions это крайне полезный проект, причём интуитивно понятный. Можно просто тыкать на все кнопки подряд и залезать во все вкладки.
2) также в качестве специализированных БПС можно рассматривать сайты крупнейших международных издателей (Elsevier, Wiley, Springer, Taylor & Francis и т.д.) и распространителей (Ingentaconnect, GeoscienceWorld) научных изданий. Впрочем, ограничение результатов поиска тем или иным издателем или распространителем на пользу, как правило, не идёт и скорее может быть полезно для того, чтобы кратко ознакомиться с той или иной темой.
3) в какой-то мере функции БПС выполняют научные социальные сети (Academia.edu, ResearchGate ), а также «гибрид» социальный сети и библиографического менеджера Mendeley (доступна как оффлайн-версия в виде программы, так и её онлайн-вариант; сейчас, после покупки Mendeley компанией Elsevier там доступны многие опции Scopus). Впрочем, содержимое научных социальных сетей хорошо индексируется googl’ом, и тут разве что есть смысл регулярно просматривать ленту обновлений в поисках чего-нибудь совсем нового.
4) в отдельную категорию БПС можно выделить региональные или специализированные сайты, где в основном имеются данные о публикациях, изданных в какой-либо стране или нескольких странах (например, Национальная электронная библиотека elibrary.ru в России, Национальный институт информатики в Японии, Национальная библиотека Франции ), а также специализированные сайты, посвящённые каким-то конкретным научным направлениям (например, BiodiversityHeritageLibrary (BHL))
Характерной особенностью таких порталов является то, что они крайне неохотно дают индексировать своё содержимое сторонним поисковикам, так что если нужно найти что-то французское или японское – надёжнее заглянуть на соответствующие сайты и поискать там.
До недавнего времени на сайте Национальной библиотеки Франции весь интерфейс был франкоязычный, пока они туда в конце концов не приделали сначала англоязычную версию сайта, а затем и автоматический перевод по IP
Отдельно следует сказать про BHL. Это крайне полезный проект для всех исследователей, которые так или иначе связаны с изучением современных или ископаемых организмов. Данную библиотеку отличает широкий охват источников (включая разные редкости) и наличие специальных поисковых инструментов (таких как поиск по таксону во вкладке Advanced search – если кто-то собирает материалы по той или иной группе животных и растений, это очень хороший способ быстро найти публикации по теме). Из недостатков BHL можно отметить то, что нередко текстовый слой может быть распознан неверно (с ошибочно выбранным языком), а также чудовищное качество иллюстраций по умолчанию (качество плохого размытого .djvu ).
Поскольку для таксономических исследований качество изображений обычно имеет большое значение, то здесь наиболее правильным подходом является скачивание нужной публикации в формате jp2, а потом – обработка файлов (сначала переформатирование в обычный jpg / tiff, потом обработка ScanTailor и OCR). Кстати, все публикации с BHL размещаются на archive.org, и иногда удобнее проводить полнотекстовый поиск именно по archive.org (это может быть актуально в случае поиска каких-либо редкостей – тут может попасться кое-что интересное, в том числе загруженное пользователями.
Пример выдачи при поиске по таксону на BHL
Если нужен качественный пдф — лучше сохранить файл способом «Download Content — Download book — Download JPEG 2000», а потом обработать
И, конечно, в случае необходимости найти русскоязычные публикации не обойтись без поиска в elibrary в сочетании с cyberleninka. Хотя в elibrary охват источников намного больше, регулярно встречается ситуация, когда в elibrary за ту или иную статью предлагают заплатить – а на сайте Киберленинки та же статья лежит в отрытом доступе.
Несмотря на ряд недостатков, заложенных в elibrary, кажется, с рождения (отсутствие возможности скачать даже работу открытого доступа без ввода логина / пароля; отсутствие англоязычной версии и опции подписки на те или иные обновления) поиск там достаточно приличный. Но если есть необходимость регулярно отслеживать информацию по русскоязычным журналам, стоит сделать также отдельный каталог ссылок на сайты необходимых изданий – на elibrary не угадаешь, когда и почему они могут вдруг закрыть доступ к тем или иным изданиям. И ещё один момент – в том случае, когда журнал отсутствует в открытом доступе и распространяется только за деньги как через elibrary, так и через сайт издательства, то на сайте издательства статьи могут быть дешевле (такова ситуация, например, с журналом «Нефтяное хозяйство»).
Настройки расширенного поиска на elibrary (на заглавной странице сайта — слева сверху ссылка «расширенный поиск»). Здесь же сохраняется история предыдущих поисковых запросов
5) в качестве БПС можно рассматривать и крупнейшие «пиратские» проекты, обеспечивающие свободный доступ к научным публикациям – SciHub и LibGen, поскольку на них в том или ином виде реализована возможность поиска по названию публикации или ключевым словам.
И если sci-hub может быть скорее использован в качестве удобного дополнения к поиску на Dimensions, то на LibGen регулярно появляются редкие монографии, которых в других местах нет – они сканируются энтузиастами и размещаются на ЛибГене в частном порядке.
И напоследок отдельно стоит сказать про поиск диссертаций. Хотя многие диссертации (как современные российские, так и иногда достаточно старые зарубежные) выложены в Интернете в открытом доступе и индексируются поисковиками, для получения информации о свежих диссертациях, которые только планируется защитить, имеет смысл заглядывать на сайт ВАКа. Там сейчас диссертации можно искать по специальностям, ключевым словам, дате защиты и другим параметрам (при этом отдельно поиск ведётся по ВАКовским диссертациям, а отдельно – по тем, которые защищаются на советах организаций, обладающих правом самостоятельного присуждения степеней). Но есть нюанс – если у вас установлен uBlock Origin, то он блокирует поиск по данному сайту.
Пример поиска по сайту ВАК
Продолжение: часть 3

