Навязчивые мелодии (англ. earworms) – хорошо известное и порой раздражающее явление. Как только одна из таких застревает в голове, избавиться от нее бывает довольно трудно. Исследования показали, что так называемое взаимодействие с оригинальной композицией, будь то ее прослушивание или пропевание, помогает прогнать навязчивую мелодию. Но что, если вы не можете вспомнить название песни, а можете только напеть мотив?
При использовании существующих методов сравнения напетой мелодии с ее исходной полифонической студийной записью возникает ряд сложностей. Звук концертной или студийной записи с текстом, бэк-вокалом и инструментами может сильно отличаться от того, что напевает человек. Кроме того, по ошибке или по задумке в нашей версии могут быть не совсем те высота, тональность, темп или ритм. Вот почему так много текущих подходов, применяемых к системе query by humming, сопоставляют напетую мелодию с базой данных уже существующих мелодий или других напетых версий этой песни вместо того, чтобы идентифицировать ее напрямую. Однако этот тип подходов часто основан на ограниченной базе данных, требующей обновления вручную.
Запущенная в октябре функция Hum to Search представляет собой новую полностью машинно-обучаемую систему Google Search, которая позволяет человеку найти песню, если он сам споет или «промычит» ее. В отличие от существующих методов, этот подход создает эмбеддинг из спектрограммы песни, минуя промежуточное представление. Это позволяет модели сравнивать нашу мелодию непосредственно с исходной (полифонической) записью без необходимости иметь другую напевку или MIDI-версию каждого трека. Также не требуется использовать сложную созданную вручную логику для извлечения мелодии. Такой подход значительно упрощает базу данных для Hum to Search, позволяя постоянно добавлять в нее эмбеддинги оригинальных треков со всего мира, даже самые последние релизы.
Как это работает
Многие существующие системы распознавания музыки перед обработкой аудиосэмпла преобразуют его в спектрограмму, чтобы найти более правильное совпадение. Однако есть одна проблема в распознавании напетой мелодии – она зачастую содержит относительно мало информации, как в этом примере песни «Bella Ciao». Разницу между напетой версией и тем же сегментом из соответствующей студийной записи можно визуализировать с помощью спектрограмм, показанных ниже:
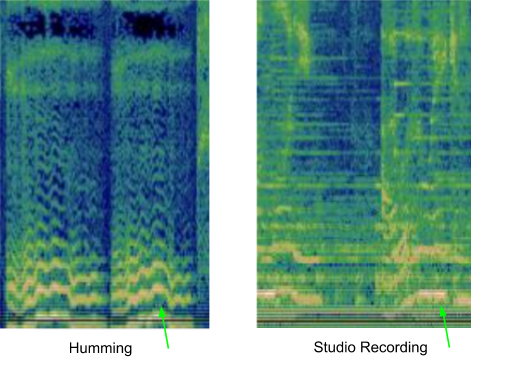
Визуализация напетого отрывка и его студийной записи
Учитывая изображение слева, модель должна найти аудио, соответствующее правому изображению, в коллекции из более чем 50 миллионов похожих изображений (соответствующих сегментам студийных записей других песен). Для этого модель должна научиться фокусироваться на доминирующей мелодии и игнорировать бэк-вокал, инструменты и тембр голоса, а также различия, возникающие из-за фонового шума или реверберации. Чтобы на глаз определить доминирующую мелодию, которая могла бы использоваться для сопоставления этих двух спектрограмм, вы можете поискать сходство в линиях в нижней части приведенных изображений.
Предыдущие попытки реализовать распознавание музыки, в частности звучащей в кафе или клубах, продемонстрировали, как к этой проблеме может быть применено машинное обучение. Now Playing, выпущенный в 2017 году для телефонов Pixel, использует встроенную глубокую нейросеть для распознавания песен без необходимости подключения к серверу, а Sound Search, позже разработавший эту технологию, использует ее для распознавания на базе сервера для быстрого и точного поиска более 100 миллионов песен. Нам же было необходимо применить изученное в этих релизах для распознавания музыки из аналогично большой библиотеки, но уже по напетым отрывкам.
Настраиваем машинное обучение
Первым шагом в развитии Hum to Search было изменение моделей распознавания музыки, используемых в Now Playing и Sound Search, для работы с записями напевок. В принципе, многие подобные поисковые системы (например, распознавание изображений) работают аналогичным образом. В процессе обучения нейронная сеть получает на вход пару (напевку и исходную запись) и создает их эмбеддинги, которые позже будут использоваться для сопоставления с напетой мелодией.

Настройка обучения нейронной сети
Чтобы обеспечить распознавание того, что мы напели, эмбеддинги пар аудио с одной и той же мелодией должны быть расположены рядом друг с другом, даже если у них разный инструментальный аккомпанемент и певческие голоса. Пары аудио, содержащие разные мелодии, должны находиться далеко друг от друга. В процессе обучения сеть получает такие пары аудио до тех пор, пока не научится создавать эмбеддинги с этим свойством.
В конечном итоге обученная модель сможет генерировать для наших мелодий эмбеддинги, похожие на эмбеддинги эталонных записей песен. В этом случае поиск нужной песни – это всего лишь вопрос поиска в базе похожих эмбеддингов, рассчитанных на основе аудиозаписей популярной музыки.
Данные для обучения
Поскольку для обучения модели требовались пары песен (записанные и спетые), первой задачей было получить достаточно данных. Наш исходный набор данных состоял в основном из спетых фрагментов (очень немногие из них содержали просто напев мотива без слов). Чтобы сделать модель более надежной, во время обучения мы применили аугментацию к этим фрагментам: изменяли высоту тона и темп в случайном порядке. Получившаяся модель работала достаточно хорошо для примеров, где песню именно спели, а не промычали или просвистели.
Для улучшения работы модели на мелодиях без слов мы сгенерировали дополнительные тренировочные данные с искусственным «мычанием» из существующего набора аудиоданных. Для этого мы использовали SPICE, модель извлечения высоты тона, разработанную нашей расширенной командой в рамках проекта FreddieMeter. SPICE извлекает из заданного аудио значения высоты, которые мы затем используем для генерации мелодии, состоящей из дискретных звуковых тонов. Самая первая версия этой системы трансформировала данный оригинальный отрывок вот в это.

Генерация «мычания» из спетого аудиофрагмента
Позже мы усовершенствовали подход, заменив простой генератор тона на нейросеть, которая генерирует звук, напоминающий настоящий напев мотива без слов. Например, представленный выше фрагмент можно преобразовать в такое «мычание» или насвистывание.
На последнем шаге мы сравнили обучающие данные, смешав и сопоставив аудиофрагменты. Когда, например, нам встречались похожие фрагменты от двух разных исполнителей, мы выравнивали их с помощью наших предварительных моделей и, следовательно, предоставляли модели дополнительную пару аудиофрагментов той же мелодии.
Улучшаем модель
Обучая модель Hum to Search, мы начали с функции triplet loss, которая отлично себя показала в различных задачах классификации, таких как классификация изображений и записанной музыки. Если дана пара аудио, соответствующая одной и той же мелодии (точки R и P в пространстве эмбеддингов, показанном ниже), функции triplet loss игнорирует определенные части обучающих данных, полученных из другой мелодии. Это помогает улучшить поведение при обучении когда модель находит другую мелодию, которая слишком простая и уже далеко от R и P (см. точку E). А также, когда она чересчур сложная для текущего этапа обучения модели и оказывается слишком близкой к R (см. точку H).

Примеры аудиосегментов, визуализированных как точки в прострастве
Мы обнаружили, что можем повысить точность модели, приняв во внимание дополнительные обучающие данные (точки H и E), а именно, сформулировав общее понятие уверенности модели на серии примеров: насколько модель уверена, что все данные, с которыми она работала, можно классифицировать правильно? Или ей встречались примеры, которые не соответствуют ее нынешнему пониманию? Основываясь на этом, мы добавили функцию потери, которая приближает уверенность модели к 100% во всех областях пространства эмбеддингов, что привело к повышению качества и точности запоминания нашей модели.
Вышеупомянутые изменения, в частности аугментация и комбинация обучающих данных, позволили модели нейросети, используемой в поиске Google, распознавать напетые мелодии. Текущая система достигает высокого уровня точности на базе данных из более полумиллиона песен, которые мы постоянно обновляем. Этой коллекции треков есть куда расти: в нее предстоит включить еще больше музыки со всего света.
Чтобы потестить эту фичу, откройте последнюю версию приложения Google, нажмите на иконку микрофона и скажите «What's this song» или кликните на «Найти песню». Теперь можете напеть или насвистеть мелодию! Надеемся, Hum to Search поможет избавиться от навязчивых мелодий или же просто найти и послушать какой-то трек, не вводя его название.

