Несколько историй из моей практики – о проблемах в направлении Service Desk (SD) и их решении путем запуска проекта автоматизации по Scrum.

Я работаю в компании ICL Services уже больше 4 лет, и начинал с позиции специалиста технической поддержки на крупном проекте. Сейчас я руковожу группой ITSM в направлении Service Desk – у меня сосредоточены компетенции по развертыванию и настройке ITSM-систем, управлению IT-процессами (Incident, Change, Problem Management). По факту, без преувеличения могу сказать: в моей группе работают самые скилловые люди в области SD.
Особенность большой компании, которую я обнаружил, поработав в ней примерно полгода с момента трудоустройства, следующая: люди редко делились своими наработками. Не потому, что жадные, а просто им глубоко лень было объяснять коллегам, в чем выгода. Ведь, как оно зачастую бывает, по большей части здесь все были технарями с давно устоявшимися отношениями.
И вот прихожу я – и вижу, что у одного есть шикарные скрипты, которые позволяют часть работы делать автоматически, другой ведет расписание своих смен в облачном приложении и никогда не путает смены (а в те дремучие времени мы еще пользовались Excel), третий написал простое веб-приложение, которое отображает все поля заявки на одном экране, чтобы не тратить время на переключение вкладок в ITSM-системе и их открытие при проверке заявок.
Но эти наработки оставались индивидуальными и не шарились на всю команду проекта, не говоря уже о каких-либо внедрениях на похожих проектах. Как сказал мой руководитель, мы всегда изобретали свой велосипед самостоятельно – и был по делу прав. Разумеется, тут был и человеческий фактор: например, был и кто-то опытнее, и ему не с руки использовать наработки «молодняка». И особая классика – «а вот с ним у нас личный конфликт, я не буду применять инструменты, которые он применяет».
Удачно для меня, и в целом для всего нашего отдела, внедрялись и обкатывались новые подходы к процессам. Тонны документации, вой со стороны пользователей и групп поддержки – все как обычно. Мне удалось протащить улучшения, которые я видел, но самое важное – удалось вовлечь почти всех ребят в совместную работу над сервисом. Ведь вы знаете, на что способна команда, которая объединилась против проблемы? У проблемы не остается шансов. Заказчик ввел новый показатель – процент ошибок при заполнении заявок. На старте он был около 10% на команду, то есть около 200 заявок имели как мелкие ошибки, так и существенные.
Линейный и проектный руководители говорили: «невозможно уменьшить процент ошибок еще больше – люди есть люди, и они всегда будут ошибаться». Мы растиражировали веб-приложение, которое написал наш ведущий спец, расставили точки контроля и регулярно снимали информацию по этим показателям, отрабатывали специфичные случаи: когда ITSM-система сама подставляет нужные поля из Active Directory, на что обратить внимание. Результат не заставил себя ждать – за полгода мы довели % ошибок в месяц до критично низкого уровня 0-0.6% на команду.
И примерно в этот момент моей карьеры я понял две вещи:
В 2019 мне предложили руководить проектом Digital SD, в рамках которого мы должны были сделать наши сервисы более конкурентными с помощью современных технологий: Machine Learning, различные голосовые и текстовые боты, омниканальные платформы, автоклассификации и авторешение заявок. Иными словами, – все те вещи, что выводят опыт клиента на новый уровень без увеличения трудозатрат на предоставление сервиса.
Признаюсь честно: оглянувшись на весь хайп вокруг AI, вначале я очень скептично отнесся к задаче. И вроде бы направление правильное, и цель благая, но что-то было здесь не так.
А подвох был в том, что никто не знал, что конкретно надо разработать. Направлений масса, за что хвататься? Обычно в такие моменты в статьях или книгах уверенно пишут: «уже тогда мы знали, как и куда двигаться». Так вот, это не про нас. Я с владельцем продукта стоял и составлял список вопросов, на которые нам нужно было ответить при проектировании продукта:
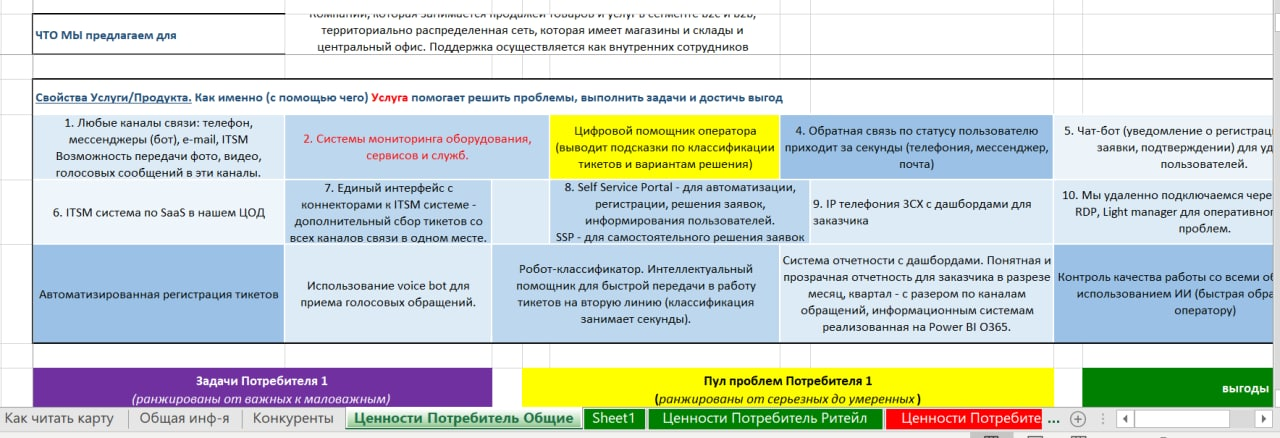
Но мы сделали достаточно продуманно: собрали группу экспертов из SD из числа менеджеров проектов, линейных руководителей, технических экспертов, записали user stories, составили карту ценностей – вот ее небольшой кусок:
Параллельно совместно с разработчиками описали верхнеуровневую архитектуру, получив таким образом отправную точку в проекте.
Итак, наши вводные: Владелец продукта, PM, Скрам-мастер и команда разработки. Рабочий спринт длительностью 2 недели. Задача – организовать процесс выпуска продукта так, чтобы…

А если серьезно, нужно было учесть требования всех стейкхолдеров, разобраться с болями и понять, что реально нужно делать, что можно либо сделать потом, а что не делать вовсе.
У нас было 3 больших направления деятельности:
Наладить нормальную работу нам удалось только к 3 спринту: мы более-менее поняли, что фокусироваться надо на 1 и 2 направлениях, потому что проектные руководители говорят про боль, а руководители поддерживающих служб – про пожелания.

Я не буду растягивать статью и рассказывать, какой крутой сам по себе Agile и как он здорово помогает. Но вот что я реально могу сказать, поработав в таком режиме около 30 спринтов:
У меня подобного опыта меньше, поэтому это большое и тяжкое бремя в большей степени легло на Владельца продукта: сопоставлять ожидания стейкхолдеров с реальностью, четко понимать возможности своей команды, иметь незамыленный взор, понимать обстановку на рынке, балансировать между направлением ресурсов на полезный функционал, эксперименты и «необходимое зло» – безопасность решений, организацию архитектуры сервисов, сред, документацией.
Мы начинали разработку не с нуля. У нас было много наработок по компании, которые можно было использовать в том или ином виде – одних только автоклассификаторов было целых два.
Ощутил дежавю, когда собирал все это из разных проектов, подразделений, как когда-то собирал наработки на своем первом проекте.
Разработку диалоговой системы мы начали с нескольких open source-библиотек – и одной из таких был DeepPavlov. У нас не было большого опыта работы с ним, и на наших задачах качество распознавания выходило посредственное. Вскоре мы перешли на Rasa, и там дела пошли ощутимо лучше – а дообучив модель на наших специфических данных мы получили хорошее и уверенное распознавание диалогов.
Разметку самих диалогов делали вручную – в тот момент были ребята в SD, которые взялись за эту задачу. Наш ведущий разраб на Python быстро написал программу для разметки, и мы скормили модели пару десятков тысяч разговоров. Фрагменты брали достаточно короткие, по 3 секунды – так результат выходил лучше.
Изначально у нас было по 2 виртуальные машины на Windows и на Linux, часть сервисов могла работать только под виндой. Но когда мы начали выводить первые наработки в пилот, мы быстро поняли, что по 2 виртуальные машины для одного проекта — это слишком затратно, нужно переделывать. Сейчас используем одну виртуалку на Ubuntu для продуктива. Разумеется, они все изолированы и у каждого проекта – своя область.
Также мы достаточно быстро поняли, что настройка двух виртуалок, поднятие и отладка всех сервисов, открытие портов и прочие настройки занимают совершенно непотребное время. После чего мы сделали CI/CD решение на основе Docker – как для основного кода, так и для ML части.
Где-то на 9-10 спринте мы столкнулись с запросом от многих заказчиков сделать свою систему распознавания речи. Большинство заказчиков совсем не были готовы передавать свою конфиденциальную информацию в «облака» третьим лицам. Так, мы написали такую систему и теперь можем ее предлагать там, где важно иметь всю архитектуру в пределах периметра безопасности – например, компаниям, тесно связанным с государством. Или же размещать у нас в инфраструктуре, точно зная, что чувствительные данные не попадут третьим лицам.
Развернули систему мониторинга компонентов, настроили health checks, интегрировали систему с чат-каналом в Telegram.
Ну и напоследок расскажу еще об одной тонкости, которая может кому-то пригодиться при проектировании своего чат-бота. Изначально весь код у нас был достаточно монолитным и вносить в него изменения было трудозатратно. Мы разделили чат-бота на две большие части: базовый бот и кастомизацию. Пришлось переписывать логику – но благодаря такому разделению мы могли быстро разворачивать базовые и общие для всех компоненты бота и править только то, что было кастомным для каждого конкретного проекта.
Мы четко поняли нишевость нашей истории: мы не сможем конкурировать с коробочными продуктами, которые разрабатываются уже десяток лет, да и в этом нет никакой нужды. Наша ниша – предоставить инструменты автоматизации на любом этапе сервисного проекта, от presale до окончания срока контракта. Иными словами, изначально у нас не было цели сделать Google – но была цель сделать конструктор, который бы помогал продавать Service Desk, помогал сокращать затраты на предоставление сервиса и давал бы дополнительные возможности заказчикам и их бизнесу.
Также отметил для себя интересный момент: редко какое коробочное решение на рынке может полностью закрыть боли заказчика и одновременно устроить по цене. Либо заказчик переплачивает за функционал, которым потом не будет пользоваться, либо часть доработок придется делать его специалистам или специалистам выбранного вендора, если он за это возьмется.
И вот тут у нас появляется интересная и достаточно непростая интеграционная задача помимо предложения чисто своих решений по автоматизации, выстроить систему для заказчика из наших наработок и сторонних решений, которые уже есть на рынке, устраивают по функционалу заказчика и поддерживать такую систему как сервис. Возможно, я расскажу о результатах этой работы в следующих статьях, если будет интерес.
Большую часть наших инструментов и наработок уже внедрили в текущих сервисах, какие-то пилотируем, что-то будем дорабатывать в BAU. Хуже всех пока себя ощущает чат-бот, на сегодня он меньше всех пригодился проектам – возможно потому, что ожидания сейчас достаточно завышены. Все хотят умного бота, который может воспринимать человеческую речь, спокойно отвечать на все вопросы пользователей, уметь обрабатывать перебивания, имеет интеграцию во все системы, сам учится без участия человека и со временем распознает все больше намерений (intents).
Но любой разработчик, сведущий в теме, понимает, насколько это непростая задача – ведь даже наращивая функционал и увеличивая количество намерений, которые может распознать бот, мы можем ухудшить распознавание для уже имеющихся намерений. Но это было отступление – в целом мне кажется, что с основной задачей проекта мы все-таки справились.
1. Интеллектуальный голосовой помощник и конструктор сценариев для него. Закрывает потребности в автоматизации входящего потока звонков, распознает речь пользователя, voice to text ее и передает в почту, чат, ITSM систему, в зависимости от настройки. Может интегрироваться с кучей разных систем либо с готовыми коннекторами, либо с теми, что писали мы.
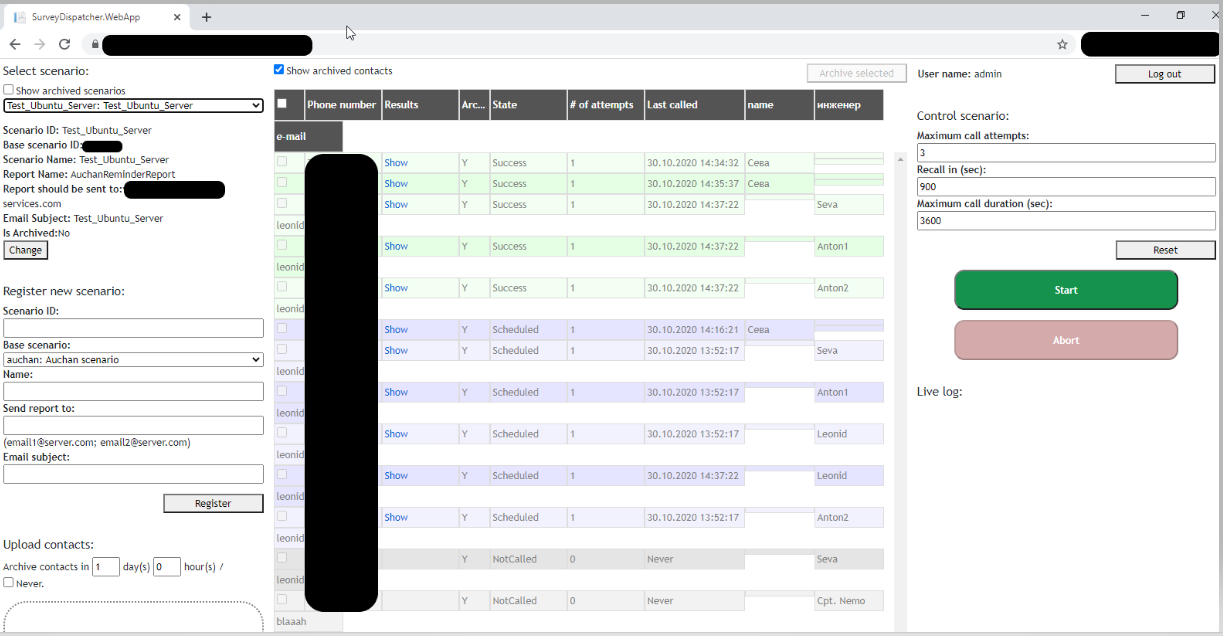
2. Обзвонщик с движком от голосового помощника. Закрывает потребность звонить на указанный пул номеров и далее собирает ответы пользователя в зависимости от сценария. Возможен регулярный обзвон, есть настройка количества повторяющихся вопросов для уточнения, сколько раз и через какое время перезванивать. Хранит данные о сделанных звонках вместе с результатами обзвона и записью разговора. Сейчас используется для напоминания о патчинге для инженеров на проекте, реализованном для крупного международного продовольственного ритейлера, в HR-службе при организации собеседования на массовые позиции, в планах – собирать информацию о качестве решенных заявок в крупной сети ресторанов быстрого питания.
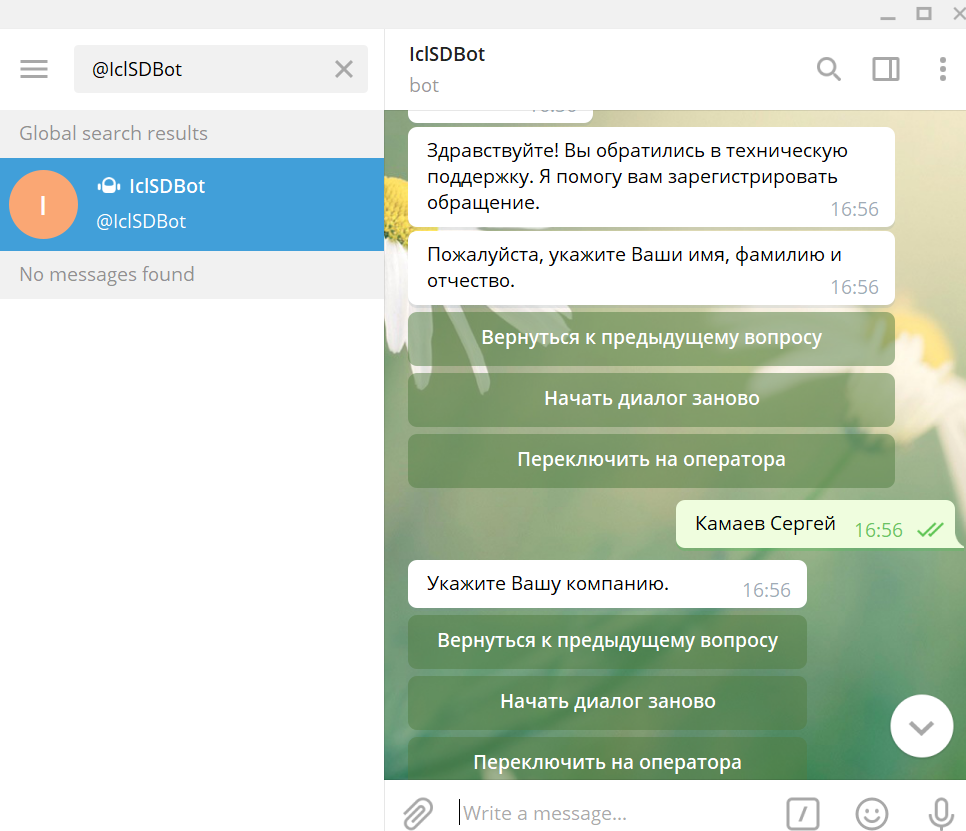
3. Чат-бот по созданию заявки, сбросу пароля и конструктор сценариев для него. Умеет спрашивать первичную информацию для регистрации обращения, регистрировать обращение в ITSM-системе, возвращать номер заявки. к выходу статьи научится показывать список открытых заявок с возможностью добавить информацию к ним или закрыть. Может подключаться к разным ITSM-системам, с доступом к api или без него.
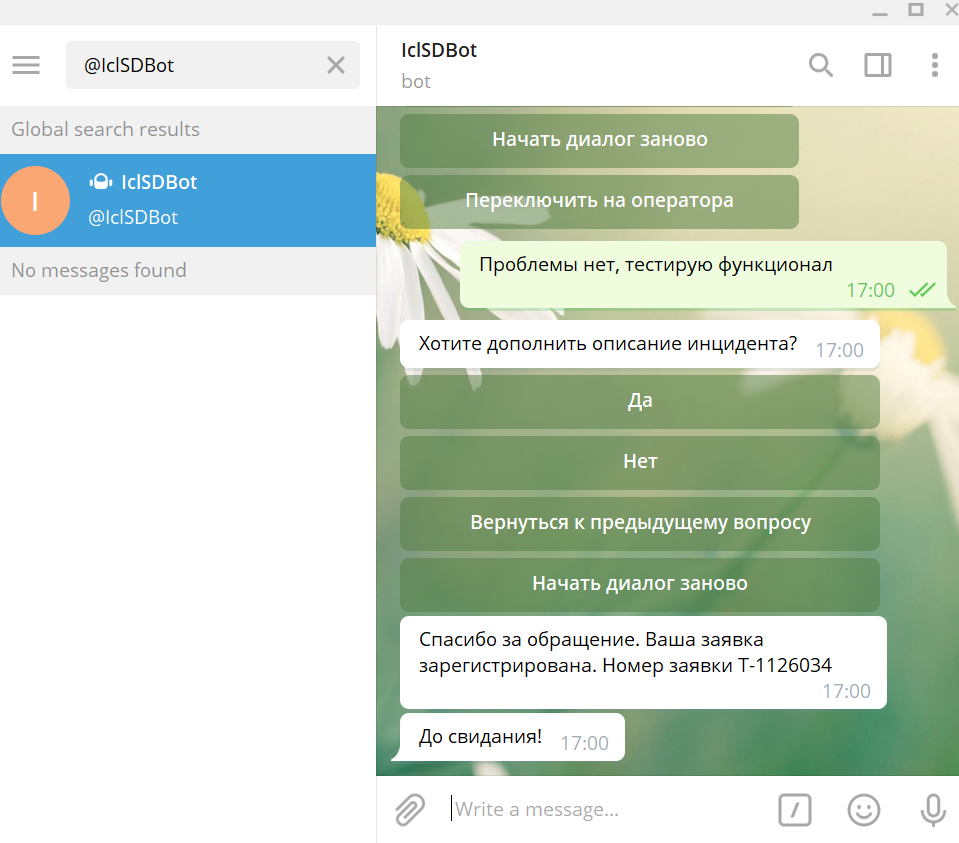
4. Инструмент для контроля качества. Умеет пока немного: отслеживает звонки, распознает, поздоровался оператор или нет, определяет слова-конфликтогены, мат в диалоге, имеет полноценный интерфейс для работы контроллера качества. Делали для себя, но может пригодиться и в КЦ.
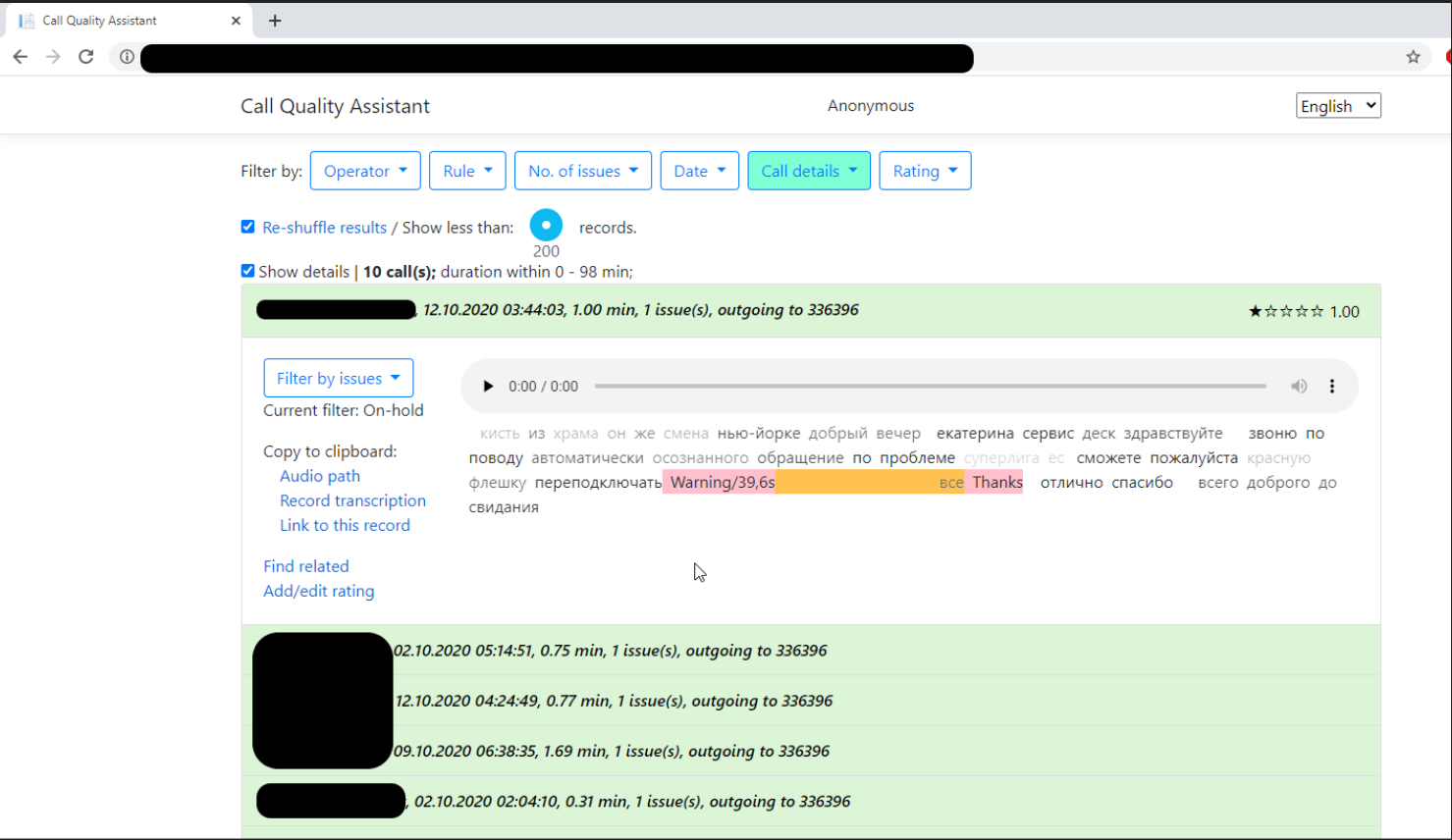
5. Автоклассификатор. Умеет парсить заявки в ITSM-системе, заполнять их и отправлять на нужные группы решения. Может учитывать доступность, загрузку и специализацию инженеров. Например, можно настроить логику, что все заявки по ЭЦП отправлять главным спецам Василию или Андрею: если Василия нет на смене – заявка уйдет Андрею, и наоборот. Если нет обоих, заявка попадет в общую очередь поддержки бизнес-приложений. Если же у Василия есть 2 заявки, а у Андрея 1 – новая заявка отправится Андрею. Можно уверенно дообучать модель, увеличивая точность. Минус системы – в ее точечности. Не стоит ждать от модели 100% точности или работы на всем объеме заявок. Мы делали на тестовой выборке 90% точности на 50% заявок при очень консистентных данных, где пользователи привыкли работать по шаблонам. Второй минус – объем заявок. Нет смысла обучать модели, если у вас меньше 1000 заявок в месяц.
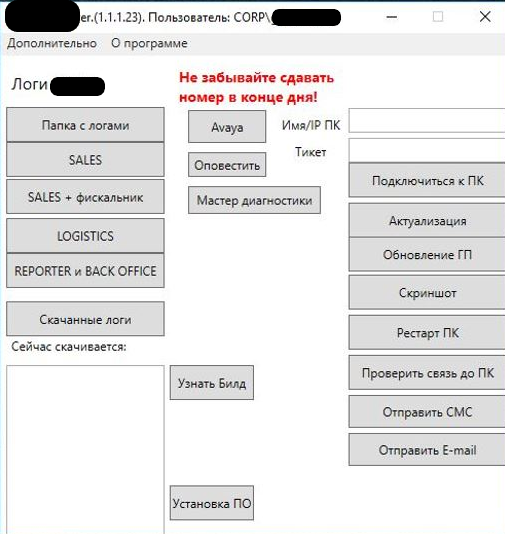
6. Инструменты для авторешения заявок. Это набор инструментов из GUI со скриптами, автоматизирующие стандартные действия агента техподдержки: сбор логов из систем, снятие скриншотов экрана, в т. ч. в теневом режиме, обновление политик и прочие специфичные для каждого проекта вещи. Второй инструмент – автоматизация тех заявок, где требуется согласование. Инструмент сам генерирует письмо согласующему со ссылками согласовать/отказать и по результатам сам дает команду на предоставление доступа, либо же генерирует письмо с отказом.
Наступает зима, проект закрывается в конце этого года,хочется уже Cyberpunk 2077, а не вот это все – а значит у меня будет еще много организационной работы.
Спасибо за ваш интерес и уделенное время, не болейте!
Экскурс в прошлое
Я работаю в компании ICL Services уже больше 4 лет, и начинал с позиции специалиста технической поддержки на крупном проекте. Сейчас я руковожу группой ITSM в направлении Service Desk – у меня сосредоточены компетенции по развертыванию и настройке ITSM-систем, управлению IT-процессами (Incident, Change, Problem Management). По факту, без преувеличения могу сказать: в моей группе работают самые скилловые люди в области SD.
Особенность большой компании, которую я обнаружил, поработав в ней примерно полгода с момента трудоустройства, следующая: люди редко делились своими наработками. Не потому, что жадные, а просто им глубоко лень было объяснять коллегам, в чем выгода. Ведь, как оно зачастую бывает, по большей части здесь все были технарями с давно устоявшимися отношениями.
И вот прихожу я – и вижу, что у одного есть шикарные скрипты, которые позволяют часть работы делать автоматически, другой ведет расписание своих смен в облачном приложении и никогда не путает смены (а в те дремучие времени мы еще пользовались Excel), третий написал простое веб-приложение, которое отображает все поля заявки на одном экране, чтобы не тратить время на переключение вкладок в ITSM-системе и их открытие при проверке заявок.
Но эти наработки оставались индивидуальными и не шарились на всю команду проекта, не говоря уже о каких-либо внедрениях на похожих проектах. Как сказал мой руководитель, мы всегда изобретали свой велосипед самостоятельно – и был по делу прав. Разумеется, тут был и человеческий фактор: например, был и кто-то опытнее, и ему не с руки использовать наработки «молодняка». И особая классика – «а вот с ним у нас личный конфликт, я не буду применять инструменты, которые он применяет».
Удачно для меня, и в целом для всего нашего отдела, внедрялись и обкатывались новые подходы к процессам. Тонны документации, вой со стороны пользователей и групп поддержки – все как обычно. Мне удалось протащить улучшения, которые я видел, но самое важное – удалось вовлечь почти всех ребят в совместную работу над сервисом. Ведь вы знаете, на что способна команда, которая объединилась против проблемы? У проблемы не остается шансов. Заказчик ввел новый показатель – процент ошибок при заполнении заявок. На старте он был около 10% на команду, то есть около 200 заявок имели как мелкие ошибки, так и существенные.
Линейный и проектный руководители говорили: «невозможно уменьшить процент ошибок еще больше – люди есть люди, и они всегда будут ошибаться». Мы растиражировали веб-приложение, которое написал наш ведущий спец, расставили точки контроля и регулярно снимали информацию по этим показателям, отрабатывали специфичные случаи: когда ITSM-система сама подставляет нужные поля из Active Directory, на что обратить внимание. Результат не заставил себя ждать – за полгода мы довели % ошибок в месяц до критично низкого уровня 0-0.6% на команду.
И примерно в этот момент моей карьеры я понял две вещи:
- Я хочу работать в крутой команде, и ее цельный результат работы намного лучше, чем тот, что может сделать даже самый гениальный сотрудник. Это решение позже точно приведет меня в менеджмент.
- Я хочу объединять наработки талантливых, крутых ребят в единую систему, которая лучше, надежнее, быстрее, чем та, что была у вас до этого.
Старт проекта
В 2019 мне предложили руководить проектом Digital SD, в рамках которого мы должны были сделать наши сервисы более конкурентными с помощью современных технологий: Machine Learning, различные голосовые и текстовые боты, омниканальные платформы, автоклассификации и авторешение заявок. Иными словами, – все те вещи, что выводят опыт клиента на новый уровень без увеличения трудозатрат на предоставление сервиса.
Признаюсь честно: оглянувшись на весь хайп вокруг AI, вначале я очень скептично отнесся к задаче. И вроде бы направление правильное, и цель благая, но что-то было здесь не так.
А подвох был в том, что никто не знал, что конкретно надо разработать. Направлений масса, за что хвататься? Обычно в такие моменты в статьях или книгах уверенно пишут: «уже тогда мы знали, как и куда двигаться». Так вот, это не про нас. Я с владельцем продукта стоял и составлял список вопросов, на которые нам нужно было ответить при проектировании продукта:
- Какой полезный функционал мы несем пользователю и заказчику?
- Как это интегрируется в текущий сервис?
- Как придется поменять текущие рабочие процессы, чтобы это работало и приносило пользу?
- Как и на каких технологиях это нужно делать?
- Как должна строиться экономическая модель решения?
Но мы сделали достаточно продуманно: собрали группу экспертов из SD из числа менеджеров проектов, линейных руководителей, технических экспертов, записали user stories, составили карту ценностей – вот ее небольшой кусок:
Параллельно совместно с разработчиками описали верхнеуровневую архитектуру, получив таким образом отправную точку в проекте.
Работа по SCRUM
Итак, наши вводные: Владелец продукта, PM, Скрам-мастер и команда разработки. Рабочий спринт длительностью 2 недели. Задача – организовать процесс выпуска продукта так, чтобы…
А если серьезно, нужно было учесть требования всех стейкхолдеров, разобраться с болями и понять, что реально нужно делать, что можно либо сделать потом, а что не делать вовсе.
У нас было 3 больших направления деятельности:
- Продукты для автоматизации в текущих сервисных проектах. Сюда входит все, что поможет сократить трудозатраты на предоставление сервиса, повысит удовлетворенность заказчика, даст дополнительную ценность.
- Продукты для новых заказчиков. Все, что производит вау эффект на старте и «цепляет» клиента.
- Продукты для автоматизации внутренних задач организации. Задачи HR, Маркетинг, IT, Административной службы и т. п.
Наладить нормальную работу нам удалось только к 3 спринту: мы более-менее поняли, что фокусироваться надо на 1 и 2 направлениях, потому что проектные руководители говорят про боль, а руководители поддерживающих служб – про пожелания.
Я не буду растягивать статью и рассказывать, какой крутой сам по себе Agile и как он здорово помогает. Но вот что я реально могу сказать, поработав в таком режиме около 30 спринтов:
- Scrum – рабочий подход. Ты подаешь на вход ресурсы и методологию, и на выходе получаются поставки.
- Разработка спринтами – разумна. На практике я видел истории, когда тратились миллионы или десятки миллионов, а на выходе получалось совершенно не то, что нужно. Поэтому, когда вы не понимаете, как должна работать система, которую вы проектируете, буквально «до винтика», у вас нет детальных ТЗ – гораздо разумнее работать короткими итерациями с регулярным корректированием курса.
- Без хорошего менеджмента на выходе всегда получается дрянь. Команда не самоорганизуется, не залезет вам в голову и не сделает то, что нужно. Даже если она достаточна автономна, ее члены не знают и не обязаны знать, куда и как развивать ваш продукт – это не их задача. Поэтому задача PM и Владельца продукта на этом этапе – отделить зерна от плевел, понять, что реально развивает продукт, а что – пустышка, которая не выстрелит и потратит ваш самый ценный ресурс – время.
У меня подобного опыта меньше, поэтому это большое и тяжкое бремя в большей степени легло на Владельца продукта: сопоставлять ожидания стейкхолдеров с реальностью, четко понимать возможности своей команды, иметь незамыленный взор, понимать обстановку на рынке, балансировать между направлением ресурсов на полезный функционал, эксперименты и «необходимое зло» – безопасность решений, организацию архитектуры сервисов, сред, документацией.
- PM должен разбираться в предметной области. Подпункт прошлого абзаца, но решил все же вывести отдельным пунктом. Без этого у вас будет провисать разработка в периоды отпусков или форс-мажоров. Однажды мы беседовали со знакомым Devops об уровне технических навыков менеджера, и я сказал, что для себя вывел следующее: менеджер должен иметь технические скиллы на таком уровне, чтобы не было стыдно при беседе с разрабами/инженерами. Подытоживая блок, когда читаю статьи или слышу истории про то, что методология Agile где-то не сработала, я сразу ищу одну из двух проблем: либо гребцов не организовали, либо кормчий не понимал, куда править.
- Скрам-мастер – нужен. Я таки считаю каждый шекель, мне физически больно было видеть расходы на скрам-мастера. Ровно до момента, пока она не ушла в отпуск и вся организация операционной работы команды легла на меня. Это достаточно трудоемко, и я не рекомендую совмещать PM и скрам-мастера, только если он не ведет один проект и больше ничем помимо этого не занимается. Если появляется шаренность, вам нужно разделять эти роли. Так что спасибо тебе, Катя, без тебя нам пришлось бы куда тяжелее!
Технические детали
Мы начинали разработку не с нуля. У нас было много наработок по компании, которые можно было использовать в том или ином виде – одних только автоклассификаторов было целых два.
Ощутил дежавю, когда собирал все это из разных проектов, подразделений, как когда-то собирал наработки на своем первом проекте.
Разработку диалоговой системы мы начали с нескольких open source-библиотек – и одной из таких был DeepPavlov. У нас не было большого опыта работы с ним, и на наших задачах качество распознавания выходило посредственное. Вскоре мы перешли на Rasa, и там дела пошли ощутимо лучше – а дообучив модель на наших специфических данных мы получили хорошее и уверенное распознавание диалогов.
Разметку самих диалогов делали вручную – в тот момент были ребята в SD, которые взялись за эту задачу. Наш ведущий разраб на Python быстро написал программу для разметки, и мы скормили модели пару десятков тысяч разговоров. Фрагменты брали достаточно короткие, по 3 секунды – так результат выходил лучше.
Изначально у нас было по 2 виртуальные машины на Windows и на Linux, часть сервисов могла работать только под виндой. Но когда мы начали выводить первые наработки в пилот, мы быстро поняли, что по 2 виртуальные машины для одного проекта — это слишком затратно, нужно переделывать. Сейчас используем одну виртуалку на Ubuntu для продуктива. Разумеется, они все изолированы и у каждого проекта – своя область.
Также мы достаточно быстро поняли, что настройка двух виртуалок, поднятие и отладка всех сервисов, открытие портов и прочие настройки занимают совершенно непотребное время. После чего мы сделали CI/CD решение на основе Docker – как для основного кода, так и для ML части.
Где-то на 9-10 спринте мы столкнулись с запросом от многих заказчиков сделать свою систему распознавания речи. Большинство заказчиков совсем не были готовы передавать свою конфиденциальную информацию в «облака» третьим лицам. Так, мы написали такую систему и теперь можем ее предлагать там, где важно иметь всю архитектуру в пределах периметра безопасности – например, компаниям, тесно связанным с государством. Или же размещать у нас в инфраструктуре, точно зная, что чувствительные данные не попадут третьим лицам.
Развернули систему мониторинга компонентов, настроили health checks, интегрировали систему с чат-каналом в Telegram.
Ну и напоследок расскажу еще об одной тонкости, которая может кому-то пригодиться при проектировании своего чат-бота. Изначально весь код у нас был достаточно монолитным и вносить в него изменения было трудозатратно. Мы разделили чат-бота на две большие части: базовый бот и кастомизацию. Пришлось переписывать логику – но благодаря такому разделению мы могли быстро разворачивать базовые и общие для всех компоненты бота и править только то, что было кастомным для каждого конкретного проекта.
Результаты проекта
Мы четко поняли нишевость нашей истории: мы не сможем конкурировать с коробочными продуктами, которые разрабатываются уже десяток лет, да и в этом нет никакой нужды. Наша ниша – предоставить инструменты автоматизации на любом этапе сервисного проекта, от presale до окончания срока контракта. Иными словами, изначально у нас не было цели сделать Google – но была цель сделать конструктор, который бы помогал продавать Service Desk, помогал сокращать затраты на предоставление сервиса и давал бы дополнительные возможности заказчикам и их бизнесу.
Также отметил для себя интересный момент: редко какое коробочное решение на рынке может полностью закрыть боли заказчика и одновременно устроить по цене. Либо заказчик переплачивает за функционал, которым потом не будет пользоваться, либо часть доработок придется делать его специалистам или специалистам выбранного вендора, если он за это возьмется.
И вот тут у нас появляется интересная и достаточно непростая интеграционная задача помимо предложения чисто своих решений по автоматизации, выстроить систему для заказчика из наших наработок и сторонних решений, которые уже есть на рынке, устраивают по функционалу заказчика и поддерживать такую систему как сервис. Возможно, я расскажу о результатах этой работы в следующих статьях, если будет интерес.
Большую часть наших инструментов и наработок уже внедрили в текущих сервисах, какие-то пилотируем, что-то будем дорабатывать в BAU. Хуже всех пока себя ощущает чат-бот, на сегодня он меньше всех пригодился проектам – возможно потому, что ожидания сейчас достаточно завышены. Все хотят умного бота, который может воспринимать человеческую речь, спокойно отвечать на все вопросы пользователей, уметь обрабатывать перебивания, имеет интеграцию во все системы, сам учится без участия человека и со временем распознает все больше намерений (intents).
Но любой разработчик, сведущий в теме, понимает, насколько это непростая задача – ведь даже наращивая функционал и увеличивая количество намерений, которые может распознать бот, мы можем ухудшить распознавание для уже имеющихся намерений. Но это было отступление – в целом мне кажется, что с основной задачей проекта мы все-таки справились.
Что получилось на выходе
1. Интеллектуальный голосовой помощник и конструктор сценариев для него. Закрывает потребности в автоматизации входящего потока звонков, распознает речь пользователя, voice to text ее и передает в почту, чат, ITSM систему, в зависимости от настройки. Может интегрироваться с кучей разных систем либо с готовыми коннекторами, либо с теми, что писали мы.
2. Обзвонщик с движком от голосового помощника. Закрывает потребность звонить на указанный пул номеров и далее собирает ответы пользователя в зависимости от сценария. Возможен регулярный обзвон, есть настройка количества повторяющихся вопросов для уточнения, сколько раз и через какое время перезванивать. Хранит данные о сделанных звонках вместе с результатами обзвона и записью разговора. Сейчас используется для напоминания о патчинге для инженеров на проекте, реализованном для крупного международного продовольственного ритейлера, в HR-службе при организации собеседования на массовые позиции, в планах – собирать информацию о качестве решенных заявок в крупной сети ресторанов быстрого питания.
3. Чат-бот по созданию заявки, сбросу пароля и конструктор сценариев для него. Умеет спрашивать первичную информацию для регистрации обращения, регистрировать обращение в ITSM-системе, возвращать номер заявки. к выходу статьи научится показывать список открытых заявок с возможностью добавить информацию к ним или закрыть. Может подключаться к разным ITSM-системам, с доступом к api или без него.
4. Инструмент для контроля качества. Умеет пока немного: отслеживает звонки, распознает, поздоровался оператор или нет, определяет слова-конфликтогены, мат в диалоге, имеет полноценный интерфейс для работы контроллера качества. Делали для себя, но может пригодиться и в КЦ.
5. Автоклассификатор. Умеет парсить заявки в ITSM-системе, заполнять их и отправлять на нужные группы решения. Может учитывать доступность, загрузку и специализацию инженеров. Например, можно настроить логику, что все заявки по ЭЦП отправлять главным спецам Василию или Андрею: если Василия нет на смене – заявка уйдет Андрею, и наоборот. Если нет обоих, заявка попадет в общую очередь поддержки бизнес-приложений. Если же у Василия есть 2 заявки, а у Андрея 1 – новая заявка отправится Андрею. Можно уверенно дообучать модель, увеличивая точность. Минус системы – в ее точечности. Не стоит ждать от модели 100% точности или работы на всем объеме заявок. Мы делали на тестовой выборке 90% точности на 50% заявок при очень консистентных данных, где пользователи привыкли работать по шаблонам. Второй минус – объем заявок. Нет смысла обучать модели, если у вас меньше 1000 заявок в месяц.
6. Инструменты для авторешения заявок. Это набор инструментов из GUI со скриптами, автоматизирующие стандартные действия агента техподдержки: сбор логов из систем, снятие скриншотов экрана, в т. ч. в теневом режиме, обновление политик и прочие специфичные для каждого проекта вещи. Второй инструмент – автоматизация тех заявок, где требуется согласование. Инструмент сам генерирует письмо согласующему со ссылками согласовать/отказать и по результатам сам дает команду на предоставление доступа, либо же генерирует письмо с отказом.
Вместо прощания
Наступает зима, проект закрывается в конце этого года,
Спасибо за ваш интерес и уделенное время, не болейте!

