
Наверняка любой, кто занимается программированием, помнит, как в самом начале пути на него обрушивается поток информации об алгоритмах, паттернах и методах разработки. Помнит то самое чувство, когда разобравшись с какой-то свежей или просто новой для себя идеей внутри теплится ощущение "ну вот теперь-то заживем!". А также то чувство легкого отчаяния - после попытки все это применить в реальном проекте, с реальными людьми, с внезапными виражами бизнес логики и постоянным “очень срочно”.
Как же так выходит, что в мире, где большинство проектов укладываются в схему "ввод данных, валидация и сохранение в базу данных" так много проектов скатываются в полную неразбериху? При том, что все разработчики преисполнены знаний об алгоритмах, фреймворках и паттернах, а принципы SOLID на собеседовании отскакивают от зубов. Рискну высказать по этому поводу свое предположение о причине, а также мой личный способ, как с этим можно бороться.
Тезис
На мой взгляд причиной такого положения вещей является не сложность алгоритмов логики самой по себе. И не то, что заказчик меняет ее в максимально непредсказуемом направлении. Сутью проблемы является следующее: несмотря на то, что типовой проект представляет собой набор достаточно простых правил, само количество этих правил огромно. С моей точки зрения проблема в том, что информация, с которой ты сталкиваешься при изучения программирования, сфокусирована на то, словно каждый из разработчиков будет разрабатывать чертовски сложную штуку (что наверное неплохо само по себе). Но реальность такова, что вся математика сводится к суммированию "тотала" в инвойсе. И при этом мы никак не готовы к тому, что этих простых “суммирований” будет просто лавина.
Как с этим быть? Ниже я хотел бы поделиться теми принципами, которые я стал использовать в своей команде для классификации кода. В итоге у меня получилось своего рода пространство, в “клетки” которого можно складывать написанный код для того, чтобы позже в нем легко можно было ориентироваться.
Вертикаль
Говорят, если Вас завалило лавиной снега - первое, что нужно сделать - это попытаться плюнуть, чтобы определить где верх, а где низ. Отчасти, у нас тут похожая ситуация. Все знакомы с идеей слоеной архитектуры. Слой данных, слой логики, слой UI. Сравнение со слоями подразумевает, что одно “лежит” на другом, т.е. существует понятие “выше” и “ниже”. Ввиду абстрактной природы предмета, разночтения могут начинаться уже на вопросе что на что опирается: “слой данных” на “слой логики” или наоборот?
Чтобы однозначно трактовать это понятие, я пользуюсь следующим принципом: что продолжит работать, а что “упадет”, если слой вытащить? Все, что “падает” - находится выше, все, что продолжает работать - находится ниже.

1-й критерий. Глобальная или локальная область применения
Для любого кода, который вы написали, всегда можно ответить на вопрос: имеет ли смысл вычисление (функция), которая там реализована вне рамок конкретного проекта, над которым вы сейчас работаете? Валидация е-мейла например? Очевидно, что соответствие строки символов стандарту RFC 5322, которым определен валидный е-мейлы безразлично к тому, в каком проекте вы это используете. В то же самое время правило наподобие "адрес почты обязательно должен быть указан при заказе" - является специфичным в рамках конкретного проекта. Иными словами, я утверждаю, что для любого написанного кода можно легко ответить на вопрос "Является ли область применения для него глобальной?". Это разделение на черное и белое на практике все же оказывается не до конца удобным, т.к. есть значительное количество случаев, когда код формально возможно использовать в любом проекте, но вероятность этого Вами ощущается как невысокая. Да, Вы не можете знать наверняка, но - как показывает практика - оценить вероятность в каждом конкретном случае довольно легко. Например, в текущем проекте есть требование вместо обычных чекбоксов везде использовался выпадающий список с ответами “да-нет”. Технически, ничто не мешает Вам переиспользовать код, описывающий этот элемент в следующем проекте, где будет такое же требование. Но, согласитесь, что вероятность этого не настолько высокая, чтобы заморачиваться.
Таким образом мы получаем 1-й критерий: глобальная и локальная (проектная) область применения.
Честно говоря, первое время, когда я начал задавать себе этот вопрос, я не переставал удивляться, как много глобального кода. Всевозможные валидации, хелперы или какие-то ваши излюбленные трюки - все это идет туда и возникает необходимость в дополнительном подуровне классификации. Этим подуровнем может быть платформа, для которой это код предназначен или специфическая библиотека, на которую этот код опирается.

2-й критерий. Уровень "проекта" и уровень "приложения"
Как быть с кодом, который относится непосредственно к проекту? Опять же, его всегда можно разделить на две области: код, специфичный для конкретного приложения и код, который описывает логику или правила на уровне всего “бизнеса”.
Поместить код в ту или иную область нам снова поможет очень простой вопрос: то, что он делает применимо "вообще" к системе или только к конкретному приложению (компоненту)? Здесь тоже не обошлось без удивлений. Количество случаев, когда какая-то функция должна быть в "ядре" логики существенно больше, чем ощущалось. Жару тут еще поддает заказчик, формулируя требования в форме "я хочу получить уведомление, когда наши клиенты оформляют такую-то заявку на этой странице сайта", когда на самом деле деле он имеет ввиду просто "оформляя заявку", имея в виду и мобильное приложение, где это возможно сделать и ссылку в каком-нибудь промо письме.

3-й критерий. Платформа
На уровне приложения код снова можно разделить на 2 уровня. В этом поможет вопрос “Связан ли код приложения с конкретной технической платформой?” Так как в конечном итоге результаты вычислений или операции должны отобразиться на UI, должно быть место, где эта логика будет с ним связана. Console.Write() или textbox.Text или html-код, который сгенерируется как результат.
Такой код я предлагаю называть контроллерами. Одновременно с этим сущности, которые определены только в контексте этого приложения, но при этом не привязаны к платформе, я называю “логикой приложения”. Например, в десктоп приложении может быть логика, связанная с управлением принтерами в офисе для персонала, тогда как в веб-приложении, ориентированном на клиента, речь о них вообще не идет.
Капитанский вывод здесь заключается в том, что вы не можете переиспользовать контроллеры одной платформы для другой. Несмотря на свою очевидность, до того момента, пока это четко не произнесено вслух, люди иногда могут пытаться идти против этого, пытаясь выстраивать абстрактные абстракции, с целью иметь один код для разных платформ. Понимание и принятие этого ограничения важно тем, что прекращает попытки его обойти. И вместо усилий, чтобы построить некую хитроумную абстракцию, Вы с чистой совестью и на полную катушку используйте напрямую все возможности, предоставляемые конкретной платформой.
В тоже же время контроллеры удобно переиспользовать в рамках одной и той же платформы: если у вас несколько Win приложений или просто окон, то общий контроллер отлично для этого подходит, гарантируя унифицированное поведение.

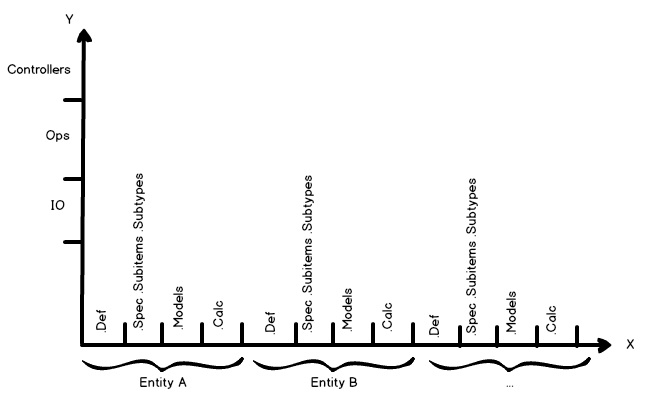
Таким образом мы получаем 4 основных уровня: глобальный, бизнес, приложение, контроллеры. Рассмотрим теперь подуровни для слоев логики - мы по-прежнему еще находимся на “вертикальной оси”.
Подуровни логики
Понятия и вычисления
Стартовой точкой описания логики в коде является описание сущностей, которые отражают понятия из предметной области. Здесь стоит упомянуть одно важное следствие, которое следует из разделения на глобальную и локальную область. В контексте ядерного кода у нас по определению не может быть кода, который нельзя было бы отнести к понятию из проектной логики. Так как все, что не относится к проекту, универсально, вынесено на глобальный уровень. Из этого следует, что каждый раз, когда вы или любой другой разработчик, думаете создать новую папку (неймспейс) - правомерным будет задать вопрос: это новая фича действительно требует “плодить новую сущность или контекст” или все таки эта функциональность является частью уже существующего? Это просто удивительно, как достаточно “капитанский” вывод заставляет думать по другому о том, куда поместить код. Даже опытные разработчики тяготеют называть код не тем, что он есть по существу, а тем, для чего он был использован ими впервые. Так как вариантов использования просто бесконечное множество - количество неймспейсов растет как снежный ком, вплоть до того, что новый неймспейс может быть назван просто темой письма, в котором заказчик прислал новую функциональность.
Входы и выходы
Сложно представить хоть одно приложение, которое бы не взаимодействовало с другими подсистемами. На ум приходит разве что калькулятор из Windows и примеры кода из статей о пользе юнит тестов.
В реальности мы имеем как минимум базу данных и процессинговый центр для платежных карт. Наверное еще что-нибудь для SMS уведомлений. Интеграцию с каким-нибудь модным сервисом - можно продолжать до бесконечности.
Как говорилось выше, очень грубо функциональность софта можно описать как “получить нечто на вход, посчитать и отдать на выходы”, которые - в свою очень - будут подключены к другому компоненту. Потому нам необходимо прописать, какие входы и выходы есть у нас в наличии - набор интерфейсов.
Например, на уровне логики у вас определено понятие Client, но практически от этого все равно не будет никакого проку, если на уровне IO у вас не будет определено что-то наподобие ClientGet(int id) входа, который подразумевает получение экземпляра по идентификатору или другому критерию.
Код, описывающий IO опирается на подуровень понятий. Метод ClientGet ожидаемо будет возвращать запись типа Client. В тоже же время ничто не запрещает иметь очень специфичную структуру вроде ClientVerySpecificStatsInfo, но этот класс будет хранится уже на уровне IO рядом с самим интерфейсом. Можно, конечно, заметить, что это тоже самое, только вид сбоку. Тем не менее, в выборе, куда поместить эту специальную структуру, проявляется явный, так сказать, замысел создателя. Уровень логики подразумевает, что это понятие общее для всей системы. Уровень входов-выходов означает, что эта структура является частью определения конкретного входа, не подразумевает переиспользования и не загромождает основные понятия.
Очень часто ирония состоит в том, что люди почему-то все время тяготеют запихнуть очень узко определенные вещи (зачастую “хаки”) на уровень базовых понятий и при этом упорно прячут “повыше” код, который просто кричит "Переиспользуй меня!".
Обычно, большинство интерфейсов достаточно простые. У процессингового центра скорее всего будет пара методов отправить данные карты и сумму платежа, у сервиса смс-сообщений - отправить номер получателя и текст, возможно проверить номер на предмет запрета для подобной рассылки. Для простых случаев не составляет труда держать в уме, что отвечает по смыслу входу, а что - выходу системы. И практически всегда большое количество кода будет возникать вокруг базы данных, так как фактически все, что у нас описано в логике, в том или ином виде скорее всего нам придется хранить. Потому там имеет смысл задуматься об разделении деклараций входов и выходов. Можно не заморачиваться, чтобы разделение было абсолютно строгим - здесь только входы, здесь - только выходы, но вот иметь поставщиков данных, про которые Вы уверены, что они только читают и с ними принципиально невозможно внести никаких изменений в систему, оказывается достаточно полезным.
Операторы
Код, который вносит изменения в систему, я называю оператором. Изначально, я называл этот подуровень презентерами, так как в моем понимании это максимально соответствовало смыслу этого термина из MVP паттерна. Однако на практике оказалось удобно выделить два типа операторов - те, которые производят действие для существующего экземпляра объекта - им досталось название презентера, и те, результатом действия которых становится создание этой сущности - их я назвал “прекурсоры”. Скажем, UserPresenter у нас редактирует запись пользователя, тогда как UserPrecursor отвечает за создание новой.
Под “внести изменения в систему” понимается задействовать хотя бы один из объявленных выходов. Зачастую повторное выполнение оператора на одних и тех же данных невозможно, т.к. как некорректно дважды оформить один заказ или дважды удалить учетную запись и т.п. Для них характерно, что практически всегда присутствует связка кода - тот, который “делает дело” - выполняет операцию, и код, который вычисляет возможна ли эта операция, составной частью чего и является валидация входных данных.

Таким образом универсальное описание архитектуры звучит так: в контроллере приложения описано, какие входы задействовать и как отобразить полученные с них данные на UI. Там же описана привязка конкретной кнопки UI к другому контроллеру или к оператору, который должен “проиграться” по ее нажатию и изменения, которые должны произойти после этого на UI. Доступность этой кнопки (включена или выключена) вычисляется оператором. Собственно все.
Горизонталь
С разделением на слои по вертикали покончено. Но не менее важно является группировка “по горизонтали” внутри слоев и их подуровней. Подуровень бизнес логики “понятия и вычисления” является основой всего. Если говорить более предметно - здесь содержатся декларации классов сущностей и правила производимых над ними вычислений. Практически весь код в проекте будет использовать их, чтобы “общаться” между собой. Чтобы иметь дело с группированием сущностей давно была придумана идея неймспейсов, но проблема в том, что никто, кажется, так и не потрудился написать к ней инструкцию.

Для любого понятия в проекте можно определить, является ли оно самодостаточным (базовым) или оно имеет смысл лишь в контексте какого-то другого понятия. Такие понятия обычно легко определить, если попытаться описать функциональность приложения парой фраз - они непременно там окажутся. Скажем, в примере нашего интернет магазина наверняка будет существовать понятие Order (заказ), который должен быть способен сделать Client и затем обработать User. Внутри понятия Order скорее всего будет определено понятие Line (строка), которое представляет позицию заказа. Скорее всего, от сущности Line вне контекста Order нет никакого проку. Здесь принципиальным являются не споры о том, имеет смысл или не имеет, а фиксация факта, какое решение Вы принимаете по этому поводу. И это решение можно отображать с помощью структуры неймспейсов.
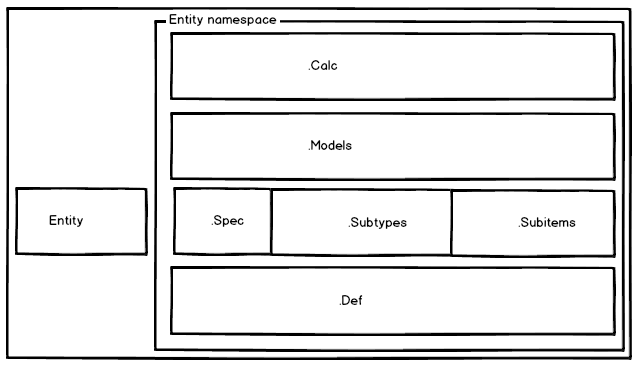
Структура Logic.Order и Logic.Orders.Line декларирует, что понятие Line определено только в контексте Order - мы это видим за счет того, что Line помещен внутрь неймспейса Orders.
Декларация Logic.Order и Logic.Line указывает, что оба эти понятия самодостаточны и Line в бизнес логике заказчика, оказывается, вполне имеет право на автономное существование.
К сожалению, если укладывать внутрь соответствующих неймспейсов только “контекстные” понятия, список “самодостаточных”, которые нужно класть в “корень”, становится просто огромным. Потому вторым видом неймспейса, которым удобно пользоваться, является обобщающий. Он объединяет в себе базовые понятия из некой логической подобласти. Скажем, в нашем интернет магазине наверняка пригодятся такие сущности, как Zip, City, Address - классы, для описания адреса доставки. Каждый из них у нас в логике пусть определен как самодостаточный, но при этом очевидно, что эти понятия из области геолокации.
Потому на выходе мы получаем структуру такую неймспейсов:
/Geo Address City Zip /Orders Line Order //заглавная сущность контекста "Orders"
Для того, чтобы легко различать эти типы, я следую простой идеей: контекстные называю множественным числом сущности, чей контекст они представляют.
Обобщающий неймспейс обычно называется в единственном числе с названием, которое не совпадает ни с одним из определенных в нем понятий. Да, есть проблема, что изначально сложно угадать, какая группа образуется с развитием проекта - по факту, обобщающие неймспейсы в итоге возникают ретроспективно. Тем не менее, Вы хотя бы знаете точно, как его не следует называть. Хоть что-то.
У обобщающего неймспейса нет заглавной сущности, как у контекстного. А вот если ее добавить - то получится отличный вариант для описания базового класса и унаследованных от него подтипов. Если вы знакомы с UML, то можно сказать, что контекстный неймспейс содержит сущности, которое ассоциированы с заглавной, а обобщающий - сущности, связанные отношением… кхм… обобщения. Пример обобщающего пространства, которое я привел изначально - для сущностей Zip, Address, City - можно рассматривать просто как вырожденный случай - формально, все эти сущности можно унаследовать от пустого класса - что-то наподобие GeoObject или около того.
В принципе, ситуация, когда для одной и той же заглавной сущности необходимо описать и то и то - возможна. Я в таких случаях использую принцип “Кто первый встал - того и тапки” А точнее - папка. Если изначально пространство было чисто обобщающим - я создаю подпространство .Subitems и контекстный код идет туда. В противоположном случае - .Subtypes
На практике, в большинстве случаев таких коллизий может попросту не возникать и тем самым удлинение имени пространства будет происходить лишь по необходимости.
.Def
В коде, который вы начнете складывать в эти неймспейсы, легко выделить тот, который не предполагает создание экземпляров сущностей - всевозможные константы, перечисления и прочие статические вещи. Весь этот код я предпочитаю отделять и хранить в подпространстве .Def (Definitions). Также сюда удобно помещать код, который использован в конструировании заглавной сущности или сущностей из неймспейса. Если переходить на UML, это это сущности, с которыми отношение зависимости.
/Geo Address City Zip /Orders /.Def OrderType OrderBase Line Order
.Spec
Также примечательными являются сущности, у которых есть жесткая 1-1 связь с заглавной. Причем отношении 1-1 действует в обе стороны. Если правилами логики определено, что пользователь должен обязательно состоять строго в одной команде, это еще не подпадает под это определение, т.к. команда будет иметь множество подобных связей - с другими пользователями из этой команды.
Интуитивно, такие сущности ощущается как часть заглавного объекта и их удобно не перемешивать со всем остальным. В UML это соответствует бинарной ассоциации.
Такие сущности я предлагаю складывать в специальное подпространство .Spec - (сокращение от specification - уточнение, детализация), а также именовать их с префиксом в виде имени заглавной сущности.
Скажем, для экземпляра User может существовать экземпляр UserLikes, который будет структурой, которая содержит счетчик лайков/дизлайков этого User’а клиентами.
Все поля классов “жесткой связки” в принципе можно было бы скопировать в заглавный объект и это не нарушило бы смысла. Это разделение обычно обусловлено больше “технологическими” аспектами, чтобы раздробить какой-то класс на подклассы для удобства работы с ними.
Есть и еще один прагматичный аспект для обособления таких сущей. Дело в том, что понятие наподобие UserStats (“статистика”) можно трактовать двояко. Оно хорошо подходит для того, чтобы хранить статистику в рамках одного пользователя, скажем, сколько заказов им было обработано за вчера, за неделю и за все время. А также оно может хранить информацию сколько всего пользователей у нас есть, сколько активных и тому подобное, т.е. статистику, агрегирующую множество объектов. Так как это совершенно разные по смыслу и назначению объекты и при этом с равными правами претендовать на название Stats, специальный неймспейс и префикс позволяет легче отличать их. (Да, UserStats применим и как агрегат сразу для нескольких пользователей в принципе, а вот Stats для одного экземпляра превращается в вырожденный случай без особого смысла.)
Таким образом пример структуры неймспейса выглядит следующим образом:
/Users /.Spec UserLikes UserStats //статистика в контексте 1-го пользователя Stats //агрегирующая множество пользователей статистика User
Все остальные сущности я складываю в корень пространства. Да, здесь в принципе можно было бы пойти дальше, ориентируясь на неупомянутые отношения из UML, но дело в том, что я не большой поклонник UML. В моей практике попытки решить, композиция это или все таки агрегация, могут быть занимательным упражнением, занимать кучу времени и при этом не приносить какой-то существенной добавленной пользы.
.Calc
До этого, мы говорил о коде, который декларировал сущности. Давайте поговорим о вычислениях. Я использую общее название калькулятор для кода, который производит вычисление. Это удобно, чтобы четко отличать такой код от операторов, т.к. проигрывать вычисления можно сколь угодно много и ничего в системе не изменится. В слово “вычисление” я вкладываю максимально широкий смысл, то есть валидация е-мейл это вычисление, которое считает 0 или 1 для заданной строки. Генерация файла в PDF формате это тоже вычисления такого массива байт, который открытый программой Adobe Acrobat Reader, отобразит на экране ожидаемую картинку. Для хранения кода с вычислениями я использую подпространство .Calc (от calculators).
Как я уже упоминал, сами по себе вычисления обычно смехотворно просты. Но мало того, что самих вычислений много, так и количество объектов, так или иначе влияющих на результат каждого из них в отдельности, медленно но верно разрастается. В методы необходимо передавать много параметров, сочетание которых максимально неожиданно и порождает дискуссии на тему “Пять параметров в методе - это еще читаемо или уже нет? А шесть?”
В реальной бизнес-логике обычно редко удается сделать все необходимые вычисления, основываясь лишь на одной-двух сущностях. Тогда можно было бы оформлять это как метод этой сущности и не было бы никаких проблем. Но увы.
.Models
В итоге я пришел к необходимости подпространства .Models, где содержатся сущности-модели, описывающие связки необходимых объектов, соответствующие тому, как они соотносятся в реальности. Класс, который описывает сущность Team, скорее всего будет представлять собой сущность со свойствами ID и Name этой команды. Его удобно будет использовать для того, чтобы отобразить список команд, но мало проку, чтобы получить список имен участников команды, которые назначены ”главными” в ней. Для 2-й ситуации нам необходимо нечто, что опишет команду как коллекцию объектов User или даже коллекцию таких коллекций, чтобы описать все команды.
Эти модели-классы не обязаны закрывать абсолютно всю предметную область за раз, так как на практике такое неудобно каждый раз вытаскивать из базы данных. А вот пара-тройка частичных моделей, можно пересекающихся между собой, скорее всего закроют все Ваши потребности, чтобы удобно и компактно описывать входные параметры калькуляторов.
Как правило, калькуляторы используются операторами. Типичный презентер, который выполняет операцию редактирование данных клиента presenter.Submit(input) внутри обязательно должен вызывать калькулятор clientValidator.Validate(input), который ответит “да-нет” на вопрос, являются ли эти данные корректными.
Сложность самих алгоритмов в “калькуляторах” на самом деле не так уж и велика, а основная масса кода приходится именно на соединение воедино посредством контроллеров входов приложения с UI и последующим проигрыванием презентера по кнопке “ок”.
Замечания
Если Вы внимательно следили за логикой повествования, то могли заметить, что не описан случай для кода, который еще не является уровнем приложения, чтобы считаться контроллером, но при этом не задействует выходы, т.е. и оператором не считается тоже. Это по сути жесткое соединение какого-то калькулятора с входами поставщика данных. Такую штуку я называю полуконтроллер. Типичным для такого кода является использования для генерации всевозможных отчетов, писем, файлов для других программ наподобие Ms Excel. В каком-то смысле это тоже версия UI, только в отличие от экрана приложения, не предполагающая обратной реакции. Как правило, такие полуконтроллеры начинают скапливаться вокруг библиотеки, которую вы используете для работы с выходным форматом - Html, Pdf, Rtf, Json, Xls и так далее.

Параллельно всему, что было описано, на любом уровне может возникать технический и технологический код.
Техническим .Tech я называю тот код, который используются в продакшн, но прим это напрямую не связан с назначением приложения. Логирование, телеметрия, описание каких-то своих внутренних протоколов - все это отлично туда укладывается. Несмотря на то, что эти вещи в принципе общие для всех приложений, тем не менее для того, чтобы сделать их полезными, они должны опираться на понятия из области конкретной бизнес логики. От сообщения “произошла ошибка” нет особой пользы, если там не указано в контексте каких экземпляров каких сущностей, она произошла, а это уже предполагает как минимум семантическую зависимость от бизнес логики.
Технологическим я называю то, что помогает в процессе разработки. Всевозможные заглушки, моки, “инженерные” меню и т.п. Для него я использую подпространство .Dev. На мой взгляд это достаточно удобно на том же уровне IO держать заглушки для него, которые позволяли бы быстро экспериментировать.
Есть еще момент, про который я предпочел промолчать, когда описывал принцип именования неймспейса - что делать с неисчисляемыми существительными? Скажем Money? Как назвать контекст такой сущности? Вопрос может возникнуть и тогда, когда хочется называть сущность во множественном числе, вроде Options? Что ж - я не придумал ничего умнее, как добавлять к имени пространства постфикс Context - MoneyContext, OptionsContext и т.д.
MVC, MVP, MVVM
Описанные принципы никаким образом не противоречат или мешают применению широко известными MVC, MVP и MVVM паттернам, т.к. они предназначены для уровня контроллеров (в терминологии статьи) и выше. Но честно говоря, после того, как Вы разбираетесь с тем, что происходит “внизу” - привязать это к пользовательскому интерфейсу не составляет никакого труда. Там тоже есть некоторые принципы, которые упрощают жизнь, но сейчас не хотелось бы в них углубляться. Если эта статья окажется полезной сообществу - возможно это побудит меня изложить их также.
Последствия
Если честно, мне казалось, что введение формальных критериев должно закрыть вопрос раз и навсегда - разработчики буду самостоятельно раскладывать код по нужным полочкам. Как бы не так. Тем не менее, основная масса замечаний по коду при обсуждении стала приобретать достаточно формальный характер. Как правило, для неудачного решения или кода вместо заявлений “да это не читабельно!”, замечания начали становиться более предметными или обсуждаемыми. “Слишком высоко”, “слишком низко”, “ломает скелет”. Сразу в глаза начинают бросаться очевидны лажи или недопонимания, когда в какой-то оператор добавляется зависимость от совершенно неожиданного выхода.
Еще одним интересным эффектом стали ситуации, когда в процессе разработки не получается “вписать” какую-то новую функциональность в предложенное “пространство”. Опять же - я не могу это никак доказать, что это как-то связано со свойствами такого подхода - но в моих случаях все подобные ситуации заканчивались переосмыслением изначального плана и выходом на более логичное и элегантное решение (не без творческих мук, но тем не менее), которое уже отлично в него укладывалось.
Заключение
Все время, пока я писал эту статью, меня не покидало ощущение “А что если это все на самом деле давно описано и ты тут изобретаешь очередной велосипед?”. Может быть. Но лично мне за все время так и не попалось прочесть ничего такого, что давало бы некий универсальный и в тоже время сжатый до одной статьи подход к “складированию” кода. Потому хотелось бы верить, что изложенный подход позволит кому-то навести чуть больше порядка в своих проектах.
Второй, момент, которого мне действительно не хватало, это идея использовать строгие определения - это оказалось просто чертовски круто. По моим ощущениям, я еще не встречал ни разу двух людей, у которых понимание, как правильно реализовывать какой-то паттерн, полностью совпадали бы - когда дело доходило до кодирования. И не важно, у кого понимание более правильное - в результате Вы имеете немного различные реализации и при этом времени, чтоб исправить условно "неправильную" никогда нет. Наличие же хотя бы парочки строгих формальных определений позволяет начать всем реально общаться на одном языке и существенно более точно доносить друг другу как идеи реализации, так и требования.
p.s. C дебютом меня на Хабре!

