Технический анализ биржевых графиков основывается на гипотезе существования повторяющихся моделей, паттернов, способных приносить прибыль. Увидели две черные свечки и три белые в определенном порядке - открывайтесь и получите деньги. Но почему-то мало информации (или она отсутствует вовсе) именно о доказательстве данной гипотезы и как и на основе чего она вообще была сформирована. Т.е. сколько раз на исторических данных та или иная фигура отработала как надо. Откуда и кто решил, что существует ниспадающий треугольник, тоннели, голова с плечами и т.д. Кем проверялось на скопившихся за все время существования биржи котировках их прибыльность? Почему не две параллельные линии и параллепипед или кружок с овалом? Об этом доказательстве мы и поговорим в данной статье, т.е. запустим скрипт python по поиску паттернов, исторические данные получим путем копирования графиков из румуса.
Начнем с одной из самых популярных моделей - голова и плечи на 6-часовых графиках по 10 валютным парам.
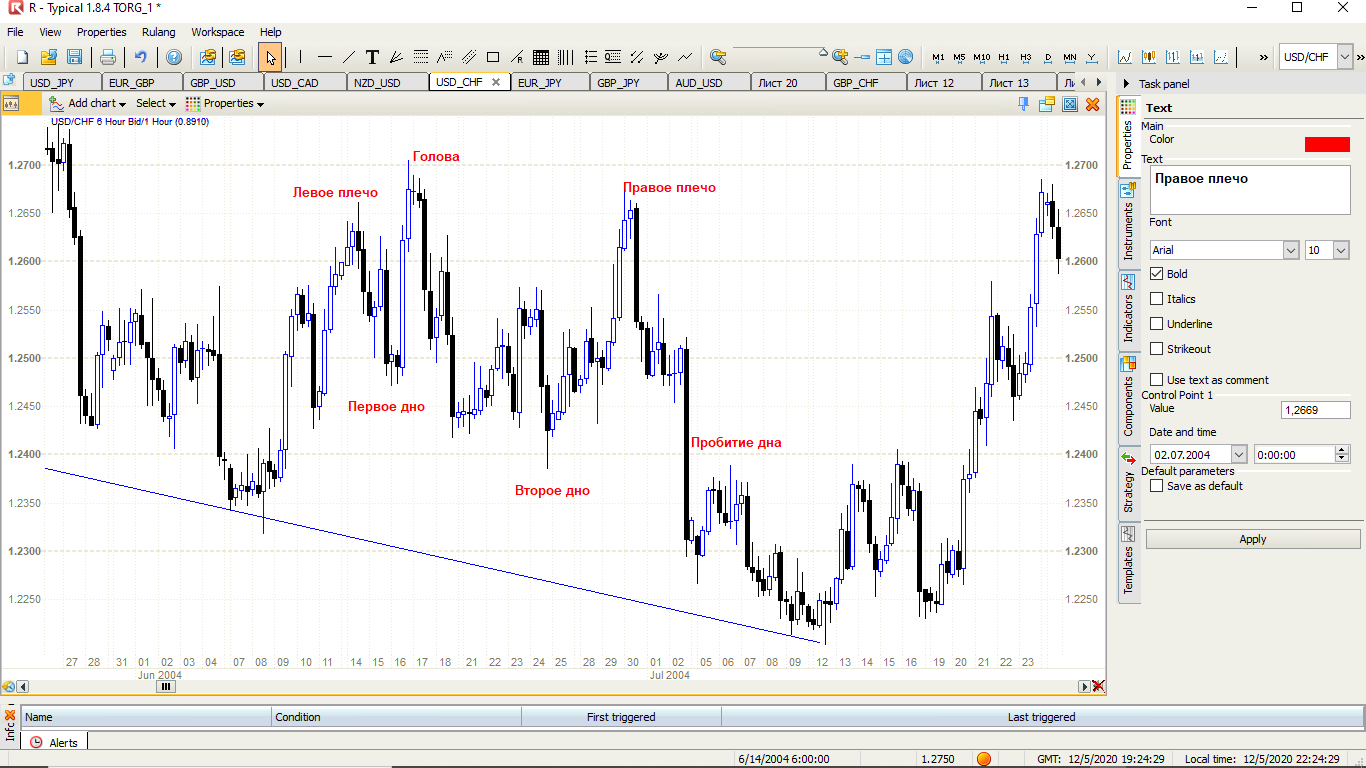
Необходимо привести статистику к виду DataFrame в формате (это выдержка с конца, данные по 10 валютным парам на 6 часах в среднем с 2005 года займут порядка 160 тыс. строк)
TIME | OPEN | HIGH | LOW | CLOSE | TITLE |
|---|---|---|---|---|---|
16/09/19 06:00:00 | 1.3213 | 1.3234 | 1.3211 | 1.3232 | USD_CAD_6H |
16/09/19 12:00:00 | 1.3230 | 1.3265 | 1.3228 | 1.3257 | USD_CAD_6H |
16/09/19 18:00:00 | 1.3255 | 1.3270 | 1.3231 | 1.3247 | USD_CAD_6H |
17/09/19 00:00:00 | 1.3248 | 1.3249 | 1.3232 | 1.3239 | USD_CAD_6H |
17/09/19 06:00:00 | 1.3238 | 1.3253 | 1.3237 | 1.3247 | USD_CAD_6H |
17/09/19 12:00:00 | 1.3249 | 1.3259 | 1.3240 | 1.3255 | USD_CAD_6H |
17/09/19 18:00:00 | 1.3256 | 1.3298 | 1.3231 | 1.3247 | USD_CAD_6H |
18/09/19 00:00:00 | 1.3245 | 1.3252 | 1.3237 | 1.3239 | USD_CAD_6H |
18/09/19 06:00:00 | 1.3240 | 1.3258 | 1.3238 | 1.3254 | USD_CAD_6H |
18/09/19 12:00:00 | 1.3252 | 1.3270 | 1.3249 | 1.3250 | USD_CAD_6H |
18/09/19 18:00:00 | 1.3252 | 1.3285 | 1.3238 | 1.3273 | USD_CAD_6H |
19/09/19 00:00:00 | 1.3277 | 1.3308 | 1.3267 | 1.3295 | USD_CAD_6H |
19/09/19 06:00:00 | 1.3297 | 1.3305 | 1.3279 | 1.3282 | USD_CAD_6H |
19/09/19 12:00:00 | 1.3281 | 1.3292 | 1.3272 | 1.3273 | USD_CAD_6H |
19/09/19 18:00:00 | 1.3274 | 1.3279 | 1.3238 | 1.3243 | USD_CAD_6H |
20/09/19 00:00:00 | 1.3244 | 1.3268 | 1.3242 | 1.3257 | USD_CAD_6H |
20/09/19 06:00:00 | 1.3259 | 1.3271 | 1.3256 | 1.3266 | USD_CAD_6H |
20/09/19 12:00:00 | 1.3265 | 1.3275 | 1.3256 | 1.3264 | USD_CAD_6H |
20/09/19 18:00:00 | 1.3262 | 1.3299 | 1.3254 | 1.3255 | USD_CAD_6H |
21/09/19 00:00:00 | 1.3253 | 1.3278 | 1.3251 | 1.3261 | USD_CAD_6H |
Механика поиска. Если вкратце, то найдем левое плечо, т.е. просто некий максимум, затем голову, т.е. максимум выше левого плеча, минимум между ними является первым дном, второе дно, оно же минимум ниже первого дна, и правое плечо, т.е. максимум выше левого плеча, но ниже головы. Также добавим условия, что голова должна быть не сильно выше левого плеча, второе дно не сильно ниже первого дна, что б фигура была именно голова и плечи, а не что-то еще из анатомии и … Далее будем искать свечу, которую "пробьет" дно, т.е. опустится ниже второго дна. Прозовем ее большой черной свечкой. При помощи кода ниже посчитаем, как часто график опустился хотя бы в два раза ниже расстояния от головы до второго дна от уровня закрытия большой черной свечки, при этом не поднявшись выше правого плеча (это будет уровнем стоп лосса). Прошу обратить внимание, что начиная с поиска головы в коде используется шаг, т.е. просматривается не каждая свеча, что увеличит скорость отработки кода, хотя какие-то случаи H&S идентифицированы не будут (автор это понимает).
#лист, в который будем заносить положительные результаты list_H_AND_S=[] #лист для отрицательных результатов (фигура не отработала, денег не принесла, а унесла) list_NOT_H_AND_S=[] for i in range(600,len(df_ALL['CLOSE'])-600): # найдем левое плечо, т.е. просто максимум if max(df_ALL['HIGH'][i-30:i+15])==df_ALL['HIGH'][i]: #запустим цикл для поиска головы с шагом в 15, что б увеличить скорость работы кода for z in range (15,200,15): left_shoulder=max(df_ALL['HIGH'][i-30:i+15]) # индекс левого плеча left_shoulder_index=df_ALL['HIGH'][i-30:i+15].idxmax() # теперь найдем голову, при этом она не должна быть уж очень сильно выше левого плеча if max(df_ALL['HIGH'][df_ALL['LOW'][left_shoulder_index:left_shoulder_index+z+1].idxmin():left_shoulder_index+z+1])>left_shoulder and\ (left_shoulder-min(df_ALL['LOW'][left_shoulder_index:left_shoulder_index+z+1]))/((max(df_ALL['HIGH'][df_ALL['LOW'][left_shoulder_index:left_shoulder_index+z+1].idxmin():left_shoulder_index+z+1])-min(df_ALL['LOW'][left_shoulder_index:left_shoulder_index+z+1])))>=0.6: head=max(df_ALL['HIGH'][df_ALL['LOW'][left_shoulder_index:left_shoulder_index+z+1].idxmin():left_shoulder_index+z+1]) # индекс головы head_index=df_ALL['HIGH'][df_ALL['LOW'][left_shoulder_index:left_shoulder_index+z+1].idxmin():left_shoulder_index+z+1].idxmax() for b in range (15,200,15): # первое дно, т.е. минимум между левым плечом и головой first_bottom= min(df_ALL['LOW'][left_shoulder_index:head_index+1]) # индекс 1-ого дня first_bottom_index=df_ALL['LOW'][left_shoulder_index:head_index+1].idxmin() # найдем второе дно if min(df_ALL['LOW'][head_index:head_index+b])<first_bottom and \ (head-first_bottom)/(head-min(df_ALL['LOW'][head_index:head_index+b]))>=0.5: second_bottom= min(df_ALL['LOW'][head_index:head_index+b]) # индекс 2-ого дна second_bottom_index=df_ALL['LOW'][head_index:head_index+b].idxmin() for o in range(2,300): # max(df_ALL['HIGH'][second_bottom_index:second_bottom_index+o+1]) - правое плечо if max(df_ALL['HIGH'][second_bottom_index:second_bottom_index+o+1])>=left_shoulder and \ max(df_ALL['HIGH'][second_bottom_index:second_bottom_index+o+1])<head and \ second_bottom_index+o-df_ALL['HIGH'][second_bottom_index:second_bottom_index+o+1].idxmax()>0 and \ (second_bottom_index+o+1)-df_ALL['LOW'][df_ALL['HIGH'][second_bottom_index:second_bottom_index+o+1].idxmax()]>2 and \ min(df_ALL['LOW'][df_ALL['HIGH'][second_bottom_index:second_bottom_index+o+1].idxmax():second_bottom_index+o+1])==df_ALL['LOW'][second_bottom_index+o] and \ min(df_ALL['LOW'][df_ALL['HIGH'][second_bottom_index:second_bottom_index+o+1].idxmax():second_bottom_index+o])>second_bottom and \ df_ALL['CLOSE'][second_bottom_index+o]<second_bottom and \ min(df_ALL['LOW'][second_bottom_index:df_ALL['HIGH'][second_bottom_index:second_bottom_index+o+1].idxmax()+1])==second_bottom and \ min(df_ALL['LOW'][left_shoulder_index:head_index])==first_bottom and \ max(df_ALL['HIGH'][first_bottom_index:second_bottom_index+1])==head and \ df_ALL['CLOSE'][second_bottom_index+o]-df_ALL['OPEN'][second_bottom_index+o]<=0: # следующий цикл и покажет нам, как часто H$S будет прибыльной for x in range (2,300): # что б была прибыль, график не должен подняться выше правого плеча и при этом должен опуститься ниже второго дна # на расстояние, равное (голова-второе дно)*2. Эта точка по идее должна быть уровнем взятия прибыли, а # правое плечо - стоп лоссом if max(df_ALL['HIGH'][second_bottom_index+o:second_bottom_index+o+x+1])<=max(df_ALL['HIGH'][second_bottom_index:second_bottom_index+o+1]) and \ min(df_ALL['LOW'][second_bottom_index+o:second_bottom_index+o+x+1])<=second_bottom-(head-second_bottom)*2: if (df_ALL['TIME'][left_shoulder_index]+' '+ df_ALL['TIME'][head_index]+' '+df_ALL['TIME'][second_bottom_index]+' '+df_ALL['TIME'][second_bottom_index+o]+' '+df_ALL['TITLE'][i]+' '+df_ALL['TITLE'][second_bottom_index+o]+' '+str(df_ALL['CLOSE'][o+second_bottom_index]-df_ALL['OPEN'][o+second_bottom_index])) not in list_H_AND_S: list_H_AND_S.append(df_ALL['TIME'][left_shoulder_index]+' '+ df_ALL['TIME'][head_index]+' '+df_ALL['TIME'][second_bottom_index]+' '+df_ALL['TIME'][second_bottom_index+o]+' '+df_ALL['TITLE'][i]+' '+df_ALL['TITLE'][second_bottom_index+o]+' '+str(df_ALL['CLOSE'][o+second_bottom_index]-df_ALL['OPEN'][o+second_bottom_index])) elif max(df_ALL['HIGH'][second_bottom_index+o:second_bottom_index+o+x+1])>max(df_ALL['HIGH'][second_bottom_index:second_bottom_index+o+1]) and \ min(df_ALL['LOW'][second_bottom_index+o:second_bottom_index+o+x+1])>first_bottom-(head-second_bottom): if (df_ALL['TIME'][left_shoulder_index]+' '+ df_ALL['TIME'][head_index]+' '+df_ALL['TIME'][second_bottom_index]+' '+df_ALL['TIME'][second_bottom_index+o]+' '+df_ALL['TITLE'][i]+' '+df_ALL['TITLE'][second_bottom_index+o]+' '+str(df_ALL['CLOSE'][o+second_bottom_index]-df_ALL['OPEN'][o+second_bottom_index])) not in list_NOT_H_AND_S and \ (df_ALL['TIME'][left_shoulder_index]+' '+ df_ALL['TIME'][head_index]+' '+df_ALL['TIME'][second_bottom_index]+' '+df_ALL['TIME'][second_bottom_index+o]+' '+df_ALL['TITLE'][i]+' '+df_ALL['TITLE'][second_bottom_index+o]+' '+str(df_ALL['CLOSE'][o+second_bottom_index]-df_ALL['OPEN'][o+second_bottom_index])) not in list_H_AND_S: list_NOT_H_AND_S.append(df_ALL['TIME'][left_shoulder_index]+' '+ df_ALL['TIME'][head_index]+' '+df_ALL['TIME'][second_bottom_index]+' '+df_ALL['TIME'][second_bottom_index+o]+' '+df_ALL['TITLE'][i]+' '+df_ALL['TITLE'][second_bottom_index+o]+' '+str(df_ALL['CLOSE'][o+second_bottom_index]-df_ALL['OPEN'][o+second_bottom_index])) len(list_H_AND_S),len(list_NOT_H_AND_S)
В результате гипотетически в плюс можно было выйти не более чем в 1/6 случаев (проверьте сами), что естественно никак не способствует стабильному (да и вообще какому-то) заработку, скорее наоборот. Это будет стабильная потеря. Можно несколько изменить условия, сделать правое плечо ниже левого, второе дно выше первого, но сути это не поменяет - описанный во многих туториалах паттерн H&S действительно систематически встречается на графиках, только денег он не приносит…
Вымпел (флан/флаг)
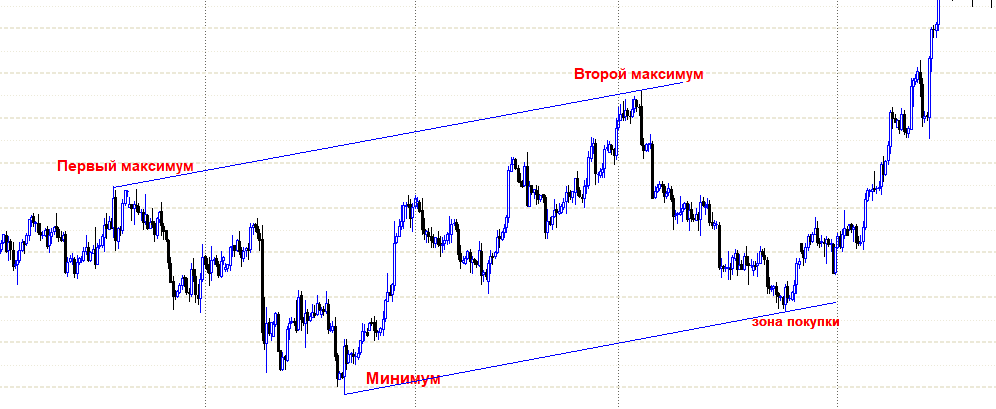
Найти вымпел с точки зрения написания кода намного легче, да и отработает он значительно быстрее, а результат еще более бесперспективен. В плюс вы выйдете в лучшем случае 1 раз из 10, без комментариев. К слову, прорыв вымпела тоже ни к какому плюсу на вашем счете не приведет
# фигура принесла деньги list_vimpel=[] # фигура деньги не принесла list_NOT_vimpel=[] for i in range(600,len(df_ALL['CLOSE'])-1000): if max(df_ALL['HIGH'][i-15:i+15])==df_ALL['HIGH'][i]: for z in range (15,300,15): # самый первый максимум first_max=max(df_ALL['HIGH'][i-15:i+15]) # индекс 1-ого максимума first_max_index=df_ALL['HIGH'][i-15:i+15].idxmax() if (first_max-min(df_ALL['LOW'][first_max_index:first_max_index+z+1]))>0 and \ max(df_ALL['HIGH'][df_ALL['LOW'][first_max_index:first_max_index+z+1].idxmin():first_max_index+z+1])>first_max and \ (max(df_ALL['HIGH'][df_ALL['LOW'][first_max_index:first_max_index+z+1].idxmin():first_max_index+z+1])-min(df_ALL['LOW'][first_max_index:first_max_index+z+1]))/(first_max-min(df_ALL['LOW'][first_max_index:first_max_index+z+1]))<=2.2 and \ (max(df_ALL['HIGH'][df_ALL['LOW'][first_max_index:first_max_index+z+1].idxmin():first_max_index+z+1])-min(df_ALL['LOW'][first_max_index:first_max_index+z+1]))/(first_max-min(df_ALL['LOW'][first_max_index:first_max_index+z+1]))>=1.3: second_max=max(df_ALL['HIGH'][df_ALL['LOW'][first_max_index:first_max_index+z+1].idxmin():first_max_index+z+1]) second_max_index=df_ALL['HIGH'][df_ALL['LOW'][first_max_index:first_max_index+z+1].idxmin():first_max_index+z+1].idxmax() # первый минимум, между первым и вторым максимумом first_min= min(df_ALL['LOW'][first_max_index:second_max_index+1]) # индекс 1-ого минимума first_min_index=df_ALL['LOW'][first_max_index:second_max_index+1].idxmin() for o in range(2,300): if (second_max_index-first_min_index)>=25 and \ min(df_ALL['LOW'][second_max_index:second_max_index+o+1])==df_ALL['LOW'][o+second_max_index] and \ df_ALL['LOW'][o+second_max_index]>first_min and \ df_ALL['HIGH'][o+second_max_index]<second_max and \ (second_max_index-first_min_index)>=25 and \ max(df_ALL['HIGH'][first_min_index:o+second_max_index+1])==second_max and \ min(df_ALL['LOW'][first_min_index:second_max_index+1])==df_ALL['LOW'][first_min_index] and \ max(df_ALL['HIGH'][first_max_index:first_min_index+1])==first_max and \ (o+second_max_index)-second_max_index>=16 and \ df_ALL['LOW'][o+second_max_index]<=(first_min+((second_max-first_max)*(((o+second_max_index)-first_min_index)/(second_max_index-first_max_index)))) and \ df_ALL['CLOSE'][o+second_max_index]>=(first_min+((second_max-first_max)*(((o+second_max_index)-first_min_index)/(second_max_index-first_max_index)))): for x in range (2,300): if min(df_ALL['LOW'][o+second_max_index:o+second_max_index+x+1])==df_ALL['LOW'][o+second_max_index] and \ max(df_ALL['HIGH'][o+second_max_index:o+second_max_index+x+1])>=second_max: if (df_ALL['TIME'][first_max_index]+' '+ df_ALL['TIME'][second_max_index]+' '+df_ALL['TIME'][second_max_index+o]+' '+df_ALL['TITLE'][i]+' '+df_ALL['TITLE'][second_max_index+o]+' '+str(df_ALL['CLOSE'][o+second_max_index]-df_ALL['OPEN'][o+second_max_index])+' '+str((second_max-first_min)/(first_max-first_min))+' '+str((second_max_index-first_min_index)/(first_min_index-first_max_index))+' '+str(((second_max-first_min)/(first_max-first_min))/((second_max-df_ALL['LOW'][o+second_max_index])/(second_max-first_min)))+' '+str(df_ALL['WeekDay'][o+second_max_index])+' '+str((second_max_index-first_max_index)/((o+second_max_index)-second_max_index))) not in list_vimpel: list_vimpel.append(df_ALL['TIME'][first_max_index]+' '+ df_ALL['TIME'][second_max_index]+' '+df_ALL['TIME'][second_max_index+o]+' '+df_ALL['TITLE'][i]+' '+df_ALL['TITLE'][second_max_index+o]+' '+str(df_ALL['CLOSE'][o+second_max_index]-df_ALL['OPEN'][o+second_max_index])+' '+str((second_max-first_min)/(first_max-first_min))+' '+str((second_max_index-first_min_index)/(first_min_index-first_max_index))+' '+str(((second_max-first_min)/(first_max-first_min))/((second_max-df_ALL['LOW'][o+second_max_index])/(second_max-first_min)))+' '+str(df_ALL['WeekDay'][o+second_max_index])+' '+str((second_max_index-first_max_index)/((o+second_max_index)-second_max_index))) elif min(df_ALL['LOW'][o+second_max_index:o+second_max_index+x+1])<df_ALL['LOW'][o+second_max_index] and \ max(df_ALL['HIGH'][o+second_max_index:o+second_max_index+x+1])<second_max: if (df_ALL['TIME'][first_max_index]+' '+ df_ALL['TIME'][second_max_index]+' '+df_ALL['TIME'][second_max_index+o]+' '+df_ALL['TITLE'][i]+' '+df_ALL['TITLE'][second_max_index+o]+' '+str(df_ALL['CLOSE'][o+second_max_index]-df_ALL['OPEN'][o+second_max_index])+' '+str((second_max-first_min)/(first_max-first_min))+' '+str((second_max_index-first_min_index)/(first_min_index-first_max_index))+' '+str(((second_max-first_min)/(first_max-first_min))/((second_max-df_ALL['LOW'][o+second_max_index])/(second_max-first_min)))+' '+str(df_ALL['WeekDay'][o+second_max_index])+' '+str((second_max_index-first_max_index)/((o+second_max_index)-second_max_index))) not in list_NOT_vimpel and \ (df_ALL['TIME'][first_max_index]+' '+ df_ALL['TIME'][second_max_index]+' '+df_ALL['TIME'][second_max_index+o]+' '+df_ALL['TITLE'][i]+' '+df_ALL['TITLE'][second_max_index+o]+' '+str(df_ALL['CLOSE'][o+second_max_index]-df_ALL['OPEN'][o+second_max_index])+' '+str((second_max-first_min)/(first_max-first_min))+' '+str((second_max_index-first_min_index)/(first_min_index-first_max_index))+' '+str(((second_max-first_min)/(first_max-first_min))/((second_max-df_ALL['LOW'][o+second_max_index])/(second_max-first_min)))+' '+str(df_ALL['WeekDay'][o+second_max_index])+' '+str((second_max_index-first_max_index)/((o+second_max_index)-second_max_index))) not in list_vimpel: list_NOT_vimpel.append(df_ALL['TIME'][first_max_index]+' '+ df_ALL['TIME'][second_max_index]+' '+df_ALL['TIME'][second_max_index+o]+' '+df_ALL['TITLE'][i]+' '+df_ALL['TITLE'][second_max_index+o]+' '+str(df_ALL['CLOSE'][o+second_max_index]-df_ALL['OPEN'][o+second_max_index])+' '+str((second_max-first_min)/(first_max-first_min))+' '+str((second_max_index-first_min_index)/(first_min_index-first_max_index))+' '+str(((second_max-first_min)/(first_max-first_min))/((second_max-df_ALL['LOW'][o+second_max_index])/(second_max-first_min)))+' '+str(df_ALL['WeekDay'][o+second_max_index])+' '+str((second_max_index-first_max_index)/((o+second_max_index)-second_max_index))) len(list_vimpel),len(list_NOT_vimpel)
Задача данной статьи не свести технический анализ к псевдотеориям, а скорее показать ненаучность многих статей и учебников, утверждающих о работоспособности популярных паттернов по причине отсутствия ответа на главный вопрос - почему именно это сочетание свечей работает? Откуда эта информация взята? На основе личного опыта, как доказывается вера в творца в саентологии уже в качестве науки? Возможно кто-то открыл (не без доказательств, естественно) паттерн, приносящий хоть какую -то прибыль, как говорится, пишите в комментариях. Особенно приветствуется мнение представителей биржевой сферы. Спасибо за внимание!
P.S. Автор понимает, что код может быть написан не идеально, не оптимизирован и т.д.

