В прошлом году мы выпустили мажорную версию своего продукта Solar Dozor 7. В новую версию нашей DLP-системы вошел модуль продвинутого анализа поведения пользователей UBA. При его создании мы попробовали разные базы данных, но по совокупности критериев (о них скажем ниже) в итоге остановились на ClickHouse.
Освоить ClickHouse местами было непросто, многое стало для нас откровением, но главное преимущество этой СУБД затмевает все её недостатки. Как вы поняли из заголовка, речь о скорости. По этому параметру ClickHouse оставляет далеко позади традиционные коммерческие базы данных, которые мы в своих продуктах, в том числе в Solar Dozor, тоже используем.
В общем, если вы давно хотели, но никак не решались попробовать, изучите наш опыт, он может вам пригодиться.

Кадры из мультфильма «Турбо» (2013 год)
Принцип работы модуля UBA в том, что он анализирует активность сотрудников в реальном времени, проверяя корпоративную почту, и формирует личный профиль устойчивого поведения пользователя. В случае отклонений Solar Dozor сообщает о них, чтобы можно было вовремя заметить нехарактерные действия сотрудников.
Все данные, которые нужны UBA-модулю, лежат в ClickHouse. Его мы ставим заказчику на ту же машину, куда инсталлируем и сам Solar Dozor. В базе храним не письма, а метаданные сообщений, то есть кто, когда, с кем переписывался, какова тема письма, какие вложения оно содержит и т. д. Время хранения можно настраивать, нам для расчетов нужен 90-дневный период. Поддержкой UBA-модуля занимаемся мы, частично это могут делать и админы клиента. В любом с��учае задача разработчиков — максимально автоматизировать администрирование БД.
Идем дальше. Основную работу делает UBA-сервер, который мы писали на Clojure. Он обрабатывает данные, лежащие в ClickHouse, и производит расчеты. UBA-сервер запоминает последнюю дату для обработанных данных и периодически проверяет, есть ли в ClickHouse более свежие данные, чем в расчете. Если есть, то старые результаты удаляются и производится перерасчет.
Еще один компонент системы — модуль Indexer, написанный на Scala. Он умеет работать с разными источниками данных. В случае с UBA у Indexer две задачи. Первая — вытаскивать метаданные писем пользователей из основной БД и отправлять их в ClickHouse. Вторая — выступать механизмом буферизации и грузить данные пачками. Когда перейдем к подробностям работы с ClickHouse, я расскажу об этом подробнее.
Для визуализации информации мы активно используем Grafana – как при разработке, так и при добавлении новых фич в готовый продукт. Конечно, мы хотим перетащить все в свой интерфейс, но пока от этой палочки-выручалочки отказаться сложно. На некоторые графики в Grafana мы потратим пару часов, а разработчику понадобилась бы неделя, чтобы сделать то же самое стандартными средствами. Обычно это непозволительная роскошь. Поэтому, если дизайнеры не очень сильно придираются к цвету графика или ширине надписи, Grafana — это спасение, ведь время у разработчиков расписано по минутам. Хотя это дополнительный софт, и в случае с некоторыми нашими клиентами иногда все упирается в сертификацию.
Сейчас вокруг ClickHouse появляются дополнительные средства разработки. В частности, мы используем Metabase — это удобное средство прототипирования и быстрого моделирования расчетов.
Сначала несколько слов о том, какими критериями мы руководствовались, выбирая СУБД для UBA-модуля. Нас интересовали:
По первым четырем пунктам ClickHouse уверенно обошел «конкурентов», и мы остановились на нем. Поговорим о главном преимуществе ClickHouse, ну, кроме того, что он бесплатный :-)
Скорость, скорость и еще раз скорость. Это главное, почему мы взяли его на борт. С ClickHouse вы сможете обрабатывать миллион записей в секунду на относительно скромных мощностях. Традиционные базы для такого требуют куда более серьезного железа. Скорость работы объясняется несколькими причинами:
Благодаря этому UBA-модуль может быстро строить аналитику по сообщениям пользователя и искать отклонения. В традиционных базах данных несколько миллионов записей будут обрабатываться достаточно долго, в ClickHouse при правильно написанном запросе это можно сделать за секунды.
ClickHouse дает преимущества и на этапе разработки — благодаря его быстроте мы можем постоянно проводить эксперименты по обработке данных и проверять гипотезы. И не тратим на это кучу времени.
ClickHouse разработали в «Яндексе» изначально для своих нужд. Но тогда собственные сборки они не выпускали. Это делала сторонняя иностранная компания Altinity.
Многие наши заказчики — российские компании, поэтому нам такой вариант не очень подходил, и мы стали собирать ClickHouse сами. Брали исходный код от «Яндекса» и генерили бинарные пакеты. Сказать, что были сложности, значит, ничего не сказать. Приключений хватало, на них тратилась куча ресурсов и времени. И при этом мы получали утечку памяти, которой в сборках от Altinity не было. По мере работы ClickHouse потреблял все больше памяти. В результате она кончалась, и тот падал. Поэтому мы решили уйти от самостоятельной сборки. Теперь проще — есть бинарники от самого «Яндекса», в крайнем случае можно взять вариант от Altinity.
Обновления выходят довольно часто, но с ними нужно быть осторожными. В каждой новой версии ClickHouse есть новые фишки, исправления, но, как следств��е, и новые баги. Разработчики «Яндекса» не очень переживают, если новая версия может привести к проблемам с совместимостью. Да, для нас это проблема, а они могут не заморачиваться и добавлять новые функции, исходя из своих потребностей и не тестируя все возможные сочетания функций. Но по мере внедрения ClickHouse в большем количестве крупных компаний отношение разработчиков «Яндекса» к клиентам постепенно смягчается.
Изначально ClickHouse был NoSQL-СУБД, но теперь он понимает SQL. Это тоже добавило нам немного проблем. Мы использовали прежний вариант, а потом некоторые старые команды поменяли свой смысл. (Оффтоп: лучше не забывать выносить код SQL-запросов из основного кода приложения. Иначе потребуется доработка исходника при самых тривиальных изменениях. Если этого не сделать на этапе разработки, то в нашем случае при необходимости исправить тот или иной запрос у клиента придется ждать выхода новой версии продукта).
Поэтому при обновлении мы берем недавнюю версию и начинаем на ней тестироваться. И если ошибки возникают, мы можем поискать более новую или более старую версию, где их не будет. Из-за этого процесс затягивается. В любом случае тестируйте свой код при обновлении ClickHouse, даже если оно минорное. Тут нужно соотносить выгоду от новых фишек с рисками и с объемом тестирования.

С традиционными базами данных история простая: настроили использовать 20 Гб памяти — они будут их использовать и никому не отдадут. С ClickHouse все иначе. Резервировать память под него не получится. Он будет использовать все, что найдет. Но и умеет делиться — ClickHouse отдает память, если в данный момент она ему не нужна. С одной стороны, эта особенность позволяет нам развернуть на одной машине несколько сервисов. А с другой стороны, нам приходится ограничивать ClickHouse, так как другие модули Solar Dozor тоже хотят кушать, а он делится памятью только тогда, когда самому не надо. Поэтому прописываем такие параметры:
Число потоков
Как я уже сказал, обычно клиент выделяет нам под Solar Dozor одну машину, на ней, кроме UBA, установлены и все остальные модули. Поэтому у истории с бескорыстным ClickHouse есть и обратная сторона. Другой софт может сожрать всю отданную память, и тому уже ничего не достанется, придет OOM Killer. Конечно, было бы хорошо резервировать под ClickHouse определенный объем памяти, но пока такой функции нет.
Мы секционировали табличку с метаданными сообщений (кто, кому, когда, с какой темой, какие вложения, размер) по дням. Вообще, для ClickHouse это очень мелкое дробление, но у нас большой объем данных. Поэтому в наших условиях день — это оптимальная единица и с точки зрения структуры данных, и с точки зрения администрирования системы.
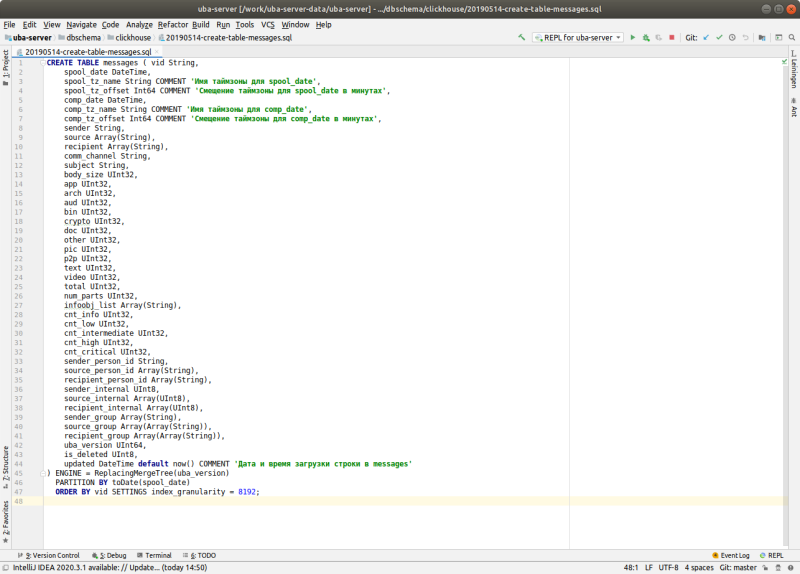
Таблицу расчетов мы секционировали по месяцам. Понятно, что их объем меньше, чем объем самих данных, поэтому тут агрегация по месяцам удобнее.
Общее правило простое: не нужно делать слишком много секций, даже если кажется, что ваш случай точно требует мелкого дробления данных. Больше секций — больше файлов на диске, а значит, операционная система будет тупить. Если нам нужно что-то быстро отобразить в интерфейсе, вытаскивать большой объем данных из одного файла быстрее, чем из множества.
С сортировкой своя история. Данные столбца физически хранятся в отдельном файле в сжатом виде в порядке, указанном в параметре сортировки. При хорошем сжатии файл получается небольшим, и чтение с диска занимает минимальное время. Если данные отсортировать правильно, то одинаковые значения будут храниться рядом, а алгоритмы компрессии ClickHouse хорошо сожмут их. Данные всех столбцов должны быть физически отсортированы в одном и том же порядке. Поэтому, если в таблице много столбцов, надо выбирать, по какому набору столбцов нужно сделать сортировку. Если скомпоновать и сжать эти данные неправильно, интерфейс или пакетная обработка будут тормозить.
И несколько слов о запросах. Их условия должны содержать поле секционирования. Оптимизатор запросов в ClickHouse пока далек от того, что есть в других базах (например, PostgreSQL и Oraсle). Он не понимает зависимости данных между столбцами. Чтобы минимизировать объемы данных, считываемых с диска, нужно явно указывать, какие диапазоны данных нужны для запроса. Условие запроса для этого должно содержать границы данных по условию секционирования. В идеале — чтобы каждый запрос доставал данные из одной секции, то есть указываем: сходи в конкретный день и ищи только там.
К архитектурному решению, как мы будем разбивать и сжимать данные, нужно отнестись ответственно. Потому что потом, когда у клиента уже появляется какое-то количество записей в определенном формате, что-то изменить очень сложно. Ведь данные хранятся в архивированном виде, то есть, чтобы их перелопатить, нужна переупаковка.
Если до этого вы работали только с традиционными базами данных, придется перестраиваться. С ClickHouse не прокатит каждый раз вставлять по строчке: он не любит частых вставок. Если у нас много источников данных и каждый вставляет по одной строчке, то ClickHouse становится плохо. То есть, например, он выдерживает 100 вставок в секунду. Вы спросите: «Как же так? 100 вставок и все?.. А где же миллион в секунду, о котором говорили?» Оказывается, ClickHouse сделан так, что он может пережить 100 вставок в секунду, а в каждой вставке при этом 10 000 строк. Вот вам и тот самый миллион.
Вообще, для себя мы выработали правило: данные нужно вставлять не чаще чем раз в 10 секунд. Так мы получаем необходимую скорость и стабильную работу.
Но нужна промежуточная буферизация, которая накопит этот миллион. Этим у нас как раз занимается Indexer, который я уже упоминал.
В Clickhouse есть такая фишка, как буферные таблицы, но это полумера. С одной стороны, они позволяют волшебным образом исправить ситуацию с частыми вставками без переделки серверного кода. На нашем железе в буферную таблицу можно вставлять в 10 раз чаще, чем в обычную. Но при этом память приходится распределять вручную. Для каждой буферной таблицы нужно назначить заранее определенное число и размер буферов. И использовать эту память под что-то другое будет нельзя. Хорошо бы угадать с этими параметрами сразу, иначе эти таблицы придется пересоздавать.
Поэтому самый правильный вариант — буферизация в приложении, что мы и сделали на этапе разработки. Несмотря на эти танцы с бубном, оно того стоит: в традиционной базе данных вставить даже 1000 строк в секунду, скорее всего, не получится даже на очень хорошем железе.
В самых первых версиях ClickHouse не было команд изменения данных. Можно было загрузить табличку и удалить. Потом добавили механизм изменения данных, который называется мутацией. И это еще одна штука, которую нужно понять и принять.
В традиционных базах данных вставил строчку, удалил строчку — сразу видишь результат. Тут все иначе. В ClickHouse пишешь команду удаления, она ставится в очередь мутаций, и через некоторое время будет выполнена. То есть по факту это выглядит так: вот данные есть, и сейчас они еще есть, до сих пор есть, а теперь раз — и исчезли. Данные могут измениться в любой момент и по другой причине: например, в результате оптимизации или дедупликации число строк может уменьшиться. В ClickHouse нет физических первичных и уникальных ключей. Поэтому в таблицах всегда есть дубли (а если нет, то будут). Данные могут никогда не схлопнуться и/или никогда не дедуплицироваться. Кстати, опция FINAL не работает, если есть незаконченные мутации.
За скорость приходится платить дополнительными телодвижениями разработчиков — в коде надо предусмотреть обработку задержек на выполнение мутации, чтобы пользователя это никак не коснулось. В частности, нужно писать код (запросы, логику обработки данных) так, чтобы не падать, если данные не соответствуют идеальному представлению о них.

У нас исходные данные, которые хранятся в ClickHouse, не удаляются и не меняются (за исключением добавления новых данных и удаления старых по партициям). Меняются только расчеты. Мы пересчитываем результаты при появлении новых данных, и у нас могут измениться алгоритмы расчетов при установке новой версии. Все это не требует построчных изменений в данных (операции update и delete). Поэтому в нашем случае очень длинных очередей мутаций не бывает.
В ClickHouse есть такой интерфейс — словари, куда можно положить любую команду, которая вытащит список из какого-то источника. Например, если нужно залезть во внешний файл со списком сотрудников организации или в Active Directory.
Словари нужны для таких меняющихся данных, как должность, телефон, семейное положение сотрудника и т. п. Если их корректное отображение критично, то словарь необходим. Все, что не меняется, нужно класть в обычные таблицы ClickHouse. Наиболее удобным для нас оказался словарь в JSON, получаемый через http-запрос, — самый естественный и самый надежный. Пишем команду сходить на такой-то сервер и взять то, что нам нужно.
В других БД все это сделать сложнее, надо писать специальную программу, которая будет доставать списки из внешних источников. В ClickHouse никаких дополнительных действий не нужно. Он достанет данные из внешнего источника и будет работать с ними как с таблицей.
Словари нужно создавать, поддерживать, дебажить. Но надо помнить, что каждый словарь — дополнительная зависимость от внешнего источника и потенциальное место возникновения проблемы, если при запросе окажется, что с источником что-то не так.
В отличие от традиционных баз данных ClickHouse не гарантирует сохранность всех данных на все 100%. Вообще, для решения этой задачи существуют специальные механизмы транзакций, откатов изменений и восстановления после сбоев. В ClickHouse все это либо не реализовано, либо сделано в минимальном объеме. Это тоже своего рода плата за скорость. Впрочем, если сильно заморочиться, то можно повысить надежность. Но придется строить кластер — систему из нескольких серверов, на которые мы установим ClickHouse и сервис для распределенных систем ZooKeeper. Будем делать бэкапы, репликацию данных. Очевидно, что это потребляет дополнительные ресурсы, место на дисках, производительность и т. д.
Тут надо обратить внимание на три момента.
В общем, средства повышения надежности совершенно точно понижают производительность, а если накосячить, то и саму надежность.
Нам пока не приходилось сталкиваться с таким запросом от заказчика. Но когда-то это наверняка произойдет, и мы готовимся к такому варианту.
В любом случае тут все упирается в ваши возможности: стоимость железа, сетевой инфраструктуры, обучения персонала и т. д. нужно соизмерять с реальными потребностями в высокой доступности. Если таких ресурсов нет, может быть, повышенная надежность не так уж и нужна? Понятно, что ClickHouse — история не про банковские или другие критичные данные.
Казалось бы, железо без SSE 4.2 сейчас почти не встретить. Но однажды нам достался мощнейший сервер с процессором, который эти инструкции не поддерживает. А для ClickHouse поддержка SSE 4.2 — одно из системных требований. Оказалось, что закончился старый проект, железо хорошее, не выбрасывать же.
«Яндекс» рекомендует выделять под ClickHouse отдельный сервер как минимум с 30 Гб оперативки. В наших условиях никто не даст под БД отдельное железо. Как я уже говорил, на одном сервере у заказчиков крутится весь Solar Dozor со всеми его модулями и их компонентами. Но, если все настроить правильно, полет пройдет нормально.
В общем, в нашем случае ClickHouse оказался хорошей альтернативой традиционным СУБД. Ему не нужны серьезные мощности, чтобы показывать впечатляющие результаты. ClickHouse делает более удобным процесс разработки, но к нему нужно привыкнуть, подружиться с его особенностями и реально оценивать уровень его возможностей.
Автор: Леонид Михайлов, ведущий инженер отдела проектирования Solar Dozor
Освоить ClickHouse местами было непросто, многое стало для нас откровением, но главное преимущество этой СУБД затмевает все её недостатки. Как вы поняли из заголовка, речь о скорости. По этому параметру ClickHouse оставляет далеко позади традиционные коммерческие базы данных, которые мы в своих продуктах, в том числе в Solar Dozor, тоже используем.
В общем, если вы давно хотели, но никак не решались попробовать, изучите наш опыт, он может вам пригодиться.
Кадры из мультфильма «Турбо» (2013 год)
О модуле UBA и его архитектуре
Принцип работы модуля UBA в том, что он анализирует активность сотрудников в реальном времени, проверяя корпоративную почту, и формирует личный профиль устойчивого поведения пользователя. В случае отклонений Solar Dozor сообщает о них, чтобы можно было вовремя заметить нехарактерные действия сотрудников.
Все данные, которые нужны UBA-модулю, лежат в ClickHouse. Его мы ставим заказчику на ту же машину, куда инсталлируем и сам Solar Dozor. В базе храним не письма, а метаданные сообщений, то есть кто, когда, с кем переписывался, какова тема письма, какие вложения оно содержит и т. д. Время хранения можно настраивать, нам для расчетов нужен 90-дневный период. Поддержкой UBA-модуля занимаемся мы, частично это могут делать и админы клиента. В любом с��учае задача разработчиков — максимально автоматизировать администрирование БД.
Идем дальше. Основную работу делает UBA-сервер, который мы писали на Clojure. Он обрабатывает данные, лежащие в ClickHouse, и производит расчеты. UBA-сервер запоминает последнюю дату для обработанных данных и периодически проверяет, есть ли в ClickHouse более свежие данные, чем в расчете. Если есть, то старые результаты удаляются и производится перерасчет.
Еще один компонент системы — модуль Indexer, написанный на Scala. Он умеет работать с разными источниками данных. В случае с UBA у Indexer две задачи. Первая — вытаскивать метаданные писем пользователей из основной БД и отправлять их в ClickHouse. Вторая — выступать механизмом буферизации и грузить данные пачками. Когда перейдем к подробностям работы с ClickHouse, я расскажу об этом подробнее.
Для визуализации информации мы активно используем Grafana – как при разработке, так и при добавлении новых фич в готовый продукт. Конечно, мы хотим перетащить все в свой интерфейс, но пока от этой палочки-выручалочки отказаться сложно. На некоторые графики в Grafana мы потратим пару часов, а разработчику понадобилась бы неделя, чтобы сделать то же самое стандартными средствами. Обычно это непозволительная роскошь. Поэтому, если дизайнеры не очень сильно придираются к цвету графика или ширине надписи, Grafana — это спасение, ведь время у разработчиков расписано по минутам. Хотя это дополнительный софт, и в случае с некоторыми нашими клиентами иногда все упирается в сертификацию.
Сейчас вокруг ClickHouse появляются дополнительные средства разработки. В частности, мы используем Metabase — это удобное средство прототипирования и быстрого моделирования расчетов.
Скорость. Я — скорость!
Сначала несколько слов о том, какими критериями мы руководствовались, выбирая СУБД для UBA-модуля. Нас интересовали:
- стоимость лицензии;
- скорость обработки;
- минимальный объем хранения;
- скорость разработки;
- минимальное администрирование;
- минимальные требования к железу.
По первым четырем пунктам ClickHouse уверенно обошел «конкурентов», и мы остановились на нем. Поговорим о главном преимуществе ClickHouse, ну, кроме того, что он бесплатный :-)
Скорость, скорость и еще раз скорость. Это главное, почему мы взяли его на борт. С ClickHouse вы сможете обрабатывать миллион записей в секунду на относительно скромных мощностях. Традиционные базы для такого требуют куда более серьезного железа. Скорость работы объясняется несколькими причинами:
- Принципиально иной метод хранения данных — ClickHouse делает их компрессию, архивирует и хранит по колонкам. Соответственно, нагрузка на диск снижается.
- В ClickHouse распараллеливание задач на несколько потоков не требует дополнительных усилий. СУБД использует все доступные процессоры сервера без вмешательства админа. Если в случае с традиционной базой для этого придется серьезно заморочиться, то ClickHouse делает это по умолчанию. Нам, наоборот, приходится его ограничивать, чтобы остальным сервисам что-то осталось.
- ClickHouse использует специальные инструкции процессора — SSE, AVX, благодаря чему быстро перелопачивает большие объемы данных в оперативке. Тут логика простая: будучи созданным недавно, ClickHouse рассчитан на новое железо и его новые возможности.
Благодаря этому UBA-модуль может быстро строить аналитику по сообщениям пользователя и искать отклонения. В традиционных базах данных несколько миллионов записей будут обрабатываться достаточно долго, в ClickHouse при правильно написанном запросе это можно сделать за секунды.
ClickHouse дает преимущества и на этапе разработки — благодаря его быстроте мы можем постоянно проводить эксперименты по обработке данных и проверять гипотезы. И не тратим на это кучу времени.
Какую сборку выбрать
ClickHouse разработали в «Яндексе» изначально для своих нужд. Но тогда собственные сборки они не выпускали. Это делала сторонняя иностранная компания Altinity.
Многие наши заказчики — российские компании, поэтому нам такой вариант не очень подходил, и мы стали собирать ClickHouse сами. Брали исходный код от «Яндекса» и генерили бинарные пакеты. Сказать, что были сложности, значит, ничего не сказать. Приключений хватало, на них тратилась куча ресурсов и времени. И при этом мы получали утечку памяти, которой в сборках от Altinity не было. По мере работы ClickHouse потреблял все больше памяти. В результате она кончалась, и тот падал. Поэтому мы решили уйти от самостоятельной сборки. Теперь проще — есть бинарники от самого «Яндекса», в крайнем случае можно взять вариант от Altinity.
Обновления выходят довольно часто, но с ними нужно быть осторожными. В каждой новой версии ClickHouse есть новые фишки, исправления, но, как следств��е, и новые баги. Разработчики «Яндекса» не очень переживают, если новая версия может привести к проблемам с совместимостью. Да, для нас это проблема, а они могут не заморачиваться и добавлять новые функции, исходя из своих потребностей и не тестируя все возможные сочетания функций. Но по мере внедрения ClickHouse в большем количестве крупных компаний отношение разработчиков «Яндекса» к клиентам постепенно смягчается.
Изначально ClickHouse был NoSQL-СУБД, но теперь он понимает SQL. Это тоже добавило нам немного проблем. Мы использовали прежний вариант, а потом некоторые старые команды поменяли свой смысл. (Оффтоп: лучше не забывать выносить код SQL-запросов из основного кода приложения. Иначе потребуется доработка исходника при самых тривиальных изменениях. Если этого не сделать на этапе разработки, то в нашем случае при необходимости исправить тот или иной запрос у клиента придется ждать выхода новой версии продукта).
Поэтому при обновлении мы берем недавнюю версию и начинаем на ней тестироваться. И если ошибки возникают, мы можем поискать более новую или более старую версию, где их не будет. Из-за этого процесс затягивается. В любом случае тестируйте свой код при обновлении ClickHouse, даже если оно минорное. Тут нужно соотносить выгоду от новых фишек с рисками и с объемом тестирования.
Эгоист и альтруист одновременно
С традиционными базами данных история простая: настроили использовать 20 Гб памяти — они будут их использовать и никому не отдадут. С ClickHouse все иначе. Резервировать память под него не получится. Он будет использовать все, что найдет. Но и умеет делиться — ClickHouse отдает память, если в данный момент она ему не нужна. С одной стороны, эта особенность позволяет нам развернуть на одной машине несколько сервисов. А с другой стороны, нам приходится ограничивать ClickHouse, так как другие модули Solar Dozor тоже хотят кушать, а он делится памятью только тогда, когда самому не надо. Поэтому прописываем такие параметры:
<max_memory_usage>
<max_memory_usage_for_user>
<max_memory_usage_for_all_queries>
<max_bytes_before_external_sort>
<max_bytes_before_external_group_by>
Число потоков
max_threads также влияет на потребление. Поэтому можно поколдовать и с этим параметром. Он определяет «параллельность» работы ClickHouse. Если уменьшим ее в два раза, то и потребление памяти при параллельных операциях тоже снизится в два раза.Как я уже сказал, обычно клиент выделяет нам под Solar Dozor одну машину, на ней, кроме UBA, установлены и все остальные модули. Поэтому у истории с бескорыстным ClickHouse есть и обратная сторона. Другой софт может сожрать всю отданную память, и тому уже ничего не достанется, придет OOM Killer. Конечно, было бы хорошо резервировать под ClickHouse определенный объем памяти, но пока такой функции нет.
О правильном секционировании и удачной сортировке
Мы секционировали табличку с метаданными сообщений (кто, кому, когда, с какой темой, какие вложения, размер) по дням. Вообще, для ClickHouse это очень мелкое дробление, но у нас большой объем данных. Поэтому в наших условиях день — это оптимальная единица и с точки зрения структуры данных, и с точки зрения администрирования системы.
Таблицу расчетов мы секционировали по месяцам. Понятно, что их объем меньше, чем объем самих данных, поэтому тут агрегация по месяцам удобнее.
Общее правило простое: не нужно делать слишком много секций, даже если кажется, что ваш случай точно требует мелкого дробления данных. Больше секций — больше файлов на диске, а значит, операционная система будет тупить. Если нам нужно что-то быстро отобразить в интерфейсе, вытаскивать большой объем данных из одного файла быстрее, чем из множества.
С сортировкой своя история. Данные столбца физически хранятся в отдельном файле в сжатом виде в порядке, указанном в параметре сортировки. При хорошем сжатии файл получается небольшим, и чтение с диска занимает минимальное время. Если данные отсортировать правильно, то одинаковые значения будут храниться рядом, а алгоритмы компрессии ClickHouse хорошо сожмут их. Данные всех столбцов должны быть физически отсортированы в одном и том же порядке. Поэтому, если в таблице много столбцов, надо выбирать, по какому набору столбцов нужно сделать сортировку. Если скомпоновать и сжать эти данные неправильно, интерфейс или пакетная обработка будут тормозить.
И несколько слов о запросах. Их условия должны содержать поле секционирования. Оптимизатор запросов в ClickHouse пока далек от того, что есть в других базах (например, PostgreSQL и Oraсle). Он не понимает зависимости данных между столбцами. Чтобы минимизировать объемы данных, считываемых с диска, нужно явно указывать, какие диапазоны данных нужны для запроса. Условие запроса для этого должно содержать границы данных по условию секционирования. В идеале — чтобы каждый запрос доставал данные из одной секции, то есть указываем: сходи в конкретный день и ищи только там.
К архитектурному решению, как мы будем разбивать и сжимать данные, нужно отнестись ответственно. Потому что потом, когда у клиента уже появляется какое-то количество записей в определенном формате, что-то изменить очень сложно. Ведь данные хранятся в архивированном виде, то есть, чтобы их перелопатить, нужна переупаковка.
Любитель есть большими порциями
Если до этого вы работали только с традиционными базами данных, придется перестраиваться. С ClickHouse не прокатит каждый раз вставлять по строчке: он не любит частых вставок. Если у нас много источников данных и каждый вставляет по одной строчке, то ClickHouse становится плохо. То есть, например, он выдерживает 100 вставок в секунду. Вы спросите: «Как же так? 100 вставок и все?.. А где же миллион в секунду, о котором говорили?» Оказывается, ClickHouse сделан так, что он может пережить 100 вставок в секунду, а в каждой вставке при этом 10 000 строк. Вот вам и тот самый миллион.
Вообще, для себя мы выработали правило: данные нужно вставлять не чаще чем раз в 10 секунд. Так мы получаем необходимую скорость и стабильную работу.
Но нужна промежуточная буферизация, которая накопит этот миллион. Этим у нас как раз занимается Indexer, который я уже упоминал.
В Clickhouse есть такая фишка, как буферные таблицы, но это полумера. С одной стороны, они позволяют волшебным образом исправить ситуацию с частыми вставками без переделки серверного кода. На нашем железе в буферную таблицу можно вставлять в 10 раз чаще, чем в обычную. Но при этом память приходится распределять вручную. Для каждой буферной таблицы нужно назначить заранее определенное число и размер буферов. И использовать эту память под что-то другое будет нельзя. Хорошо бы угадать с этими параметрами сразу, иначе эти таблицы придется пересоздавать.
Поэтому самый правильный вариант — буферизация в приложении, что мы и сделали на этапе разработки. Несмотря на эти танцы с бубном, оно того стоит: в традиционной базе данных вставить даже 1000 строк в секунду, скорее всего, не получится даже на очень хорошем железе.
Про мутации
В самых первых версиях ClickHouse не было команд изменения данных. Можно было загрузить табличку и удалить. Потом добавили механизм изменения данных, который называется мутацией. И это еще одна штука, которую нужно понять и принять.
В традиционных базах данных вставил строчку, удалил строчку — сразу видишь результат. Тут все иначе. В ClickHouse пишешь команду удаления, она ставится в очередь мутаций, и через некоторое время будет выполнена. То есть по факту это выглядит так: вот данные есть, и сейчас они еще есть, до сих пор есть, а теперь раз — и исчезли. Данные могут измениться в любой момент и по другой причине: например, в результате оптимизации или дедупликации число строк может уменьшиться. В ClickHouse нет физических первичных и уникальных ключей. Поэтому в таблицах всегда есть дубли (а если нет, то будут). Данные могут никогда не схлопнуться и/или никогда не дедуплицироваться. Кстати, опция FINAL не работает, если есть незаконченные мутации.
За скорость приходится платить дополнительными телодвижениями разработчиков — в коде надо предусмотреть обработку задержек на выполнение мутации, чтобы пользователя это никак не коснулось. В частности, нужно писать код (запросы, логику обработки данных) так, чтобы не падать, если данные не соответствуют идеальному представлению о них.
У нас исходные данные, которые хранятся в ClickHouse, не удаляются и не меняются (за исключением добавления новых данных и удаления старых по партициям). Меняются только расчеты. Мы пересчитываем результаты при появлении новых данных, и у нас могут измениться алгоритмы расчетов при установке новой версии. Все это не требует построчных изменений в данных (операции update и delete). Поэтому в нашем случае очень длинных очередей мутаций не бывает.
Не злоупотребляйте словарями
В ClickHouse есть такой интерфейс — словари, куда можно положить любую команду, которая вытащит список из какого-то источника. Например, если нужно залезть во внешний файл со списком сотрудников организации или в Active Directory.
Словари нужны для таких меняющихся данных, как должность, телефон, семейное положение сотрудника и т. п. Если их корректное отображение критично, то словарь необходим. Все, что не меняется, нужно класть в обычные таблицы ClickHouse. Наиболее удобным для нас оказался словарь в JSON, получаемый через http-запрос, — самый естественный и самый надежный. Пишем команду сходить на такой-то сервер и взять то, что нам нужно.
В других БД все это сделать сложнее, надо писать специальную программу, которая будет доставать списки из внешних источников. В ClickHouse никаких дополнительных действий не нужно. Он достанет данные из внешнего источника и будет работать с ними как с таблицей.
Словари нужно создавать, поддерживать, дебажить. Но надо помнить, что каждый словарь — дополнительная зависимость от внешнего источника и потенциальное место возникновения проблемы, если при запросе окажется, что с источником что-то не так.
Как повысить надежность?
В отличие от традиционных баз данных ClickHouse не гарантирует сохранность всех данных на все 100%. Вообще, для решения этой задачи существуют специальные механизмы транзакций, откатов изменений и восстановления после сбоев. В ClickHouse все это либо не реализовано, либо сделано в минимальном объеме. Это тоже своего рода плата за скорость. Впрочем, если сильно заморочиться, то можно повысить надежность. Но придется строить кластер — систему из нескольких серверов, на которые мы установим ClickHouse и сервис для распределенных систем ZooKeeper. Будем делать бэкапы, репликацию данных. Очевидно, что это потребляет дополнительные ресурсы, место на дисках, производительность и т. д.
Тут надо обратить внимание на три момента.
- Проектирование
Если спроектировать кластер неправильно, отказ любого компонента может привести к отказу всего кластера. В каждом конкретном случае выбор схемы будет разным. И нужно понимать, от каких аварий конкретная схема защищает, а от каких — нет. Но это тема для отдельной статьи. - Обслуживание
Все процедуры надо четко описать и протестировать. Ну и вообще, не забывать про золотое правило: работает — не трогай! - Тестирование изменений на идентичном стенде
Любые изменения и обновления надо проверять не на уже работающей системе, а на тестовой. Потому что, если что, смотри пункт 2.
В общем, средства повышения надежности совершенно точно понижают производительность, а если накосячить, то и саму надежность.
Нам пока не приходилось сталкиваться с таким запросом от заказчика. Но когда-то это наверняка произойдет, и мы готовимся к такому варианту.
В любом случае тут все упирается в ваши возможности: стоимость железа, сетевой инфраструктуры, обучения персонала и т. д. нужно соизмерять с реальными потребностями в высокой доступности. Если таких ресурсов нет, может быть, повышенная надежность не так уж и нужна? Понятно, что ClickHouse — история не про банковские или другие критичные данные.
И напоследок: проверьте железо заранее
Казалось бы, железо без SSE 4.2 сейчас почти не встретить. Но однажды нам достался мощнейший сервер с процессором, который эти инструкции не поддерживает. А для ClickHouse поддержка SSE 4.2 — одно из системных требований. Оказалось, что закончился старый проект, железо хорошее, не выбрасывать же.
«Яндекс» рекомендует выделять под ClickHouse отдельный сервер как минимум с 30 Гб оперативки. В наших условиях никто не даст под БД отдельное железо. Как я уже говорил, на одном сервере у заказчиков крутится весь Solar Dozor со всеми его модулями и их компонентами. Но, если все настроить правильно, полет пройдет нормально.
В общем, в нашем случае ClickHouse оказался хорошей альтернативой традиционным СУБД. Ему не нужны серьезные мощности, чтобы показывать впечатляющие результаты. ClickHouse делает более удобным процесс разработки, но к нему нужно привыкнуть, подружиться с его особенностями и реально оценивать уровень его возможностей.
Автор: Леонид Михайлов, ведущий инженер отдела проектирования Solar Dozor
