Меня зовут Николай Первухин, я Senior Java Developer в Райффайзенбанке. Так сложилось, что, единожды попробовав бизнес-процессы на Camunda, я стал адептом этой технологии и стараюсь ее применять в проектах со сложной логикой. Действительно сама идея подкупает: рисуешь процесс в удобном GUI-редакторе (моделлере), а фреймворк выполняет эти действия по порядку, соблюдая большой спектр элементов нотации BPMN.
К тому же в Camunda есть встроенная поддержка еще одной нотации — DMN (Decision Model and Notation): она позволяет в простой и понятной форме создавать таблицы принятия решений по входящим наборам данных.

Но чего-то все же не хватает... Может, добавим немного скорости?
Почему ускоряем процессы
В банковской сфере бизнес-процессы широко используются там, где довольно часто встречаются длинные, с нетривиальной логикой процессы взаимодействия как с клиентом, так и между банковскими подсистемами.
Что обычно характеризует такие процессы:
от момента создания до завершения процесса может пройти несколько дней;
участвует большое количество сотрудников;
осуществляется интеграция со множеством банковских подсистем.
Фреймворк Camunda прекрасно справляется с такими задачами, однако, заглянем под капот: там находится классическая база данных для осуществления транзакционности.
Но что если к логической сложности добавляется еще и требование к быстродействию? В таких случаях база данных рано или поздно становится «узким горлышком»: большое количество процессов начинает создавать блокировки, и это в конечном итоге приводит к замедлению.
Отличные новости: воспользуемся ZeeBe
В июле 2019 года было официально объявлено, что после двух лет разработки фреймворк ZeeBe готов к использованию на боевой среде. ZeeBe специально разрабатывался под задачи highload и, по утверждению автора, был протестирован при 10 000 процессов в секунду. В отличие от Camunda, ядро фреймворка ZeeBe принципиально не использует базу данных — из него убраны все вспомогательные подсистемы, в том числе и процессор правил DMN.
В случаях, когда DMN все же необходим, он может быть добавлен как отдельное приложение. Именно такую архитектуру мы и рассматриваем в данной статье.
Итак, дано:
микросервис, инициирующий событие и запускающий процесс (event-handler);
микросервис обработки бизнес-правил (rules-engine);
микросервис, эмулирующий действия (action).
Данные микросервисы могут быть запущены в неограниченном количестве экземпляров для того, чтобы справиться с динамической нагрузкой.
Из оркестрации у нас:
микросервис с брокером сообщений ZeeBe (zeebe);
микросервис визуализации работающих процессов simplemonitor (zeebe-simple-monitor).
А присматривать за всеми микросервисами будет кластер k8s.
Схема взаимодействия
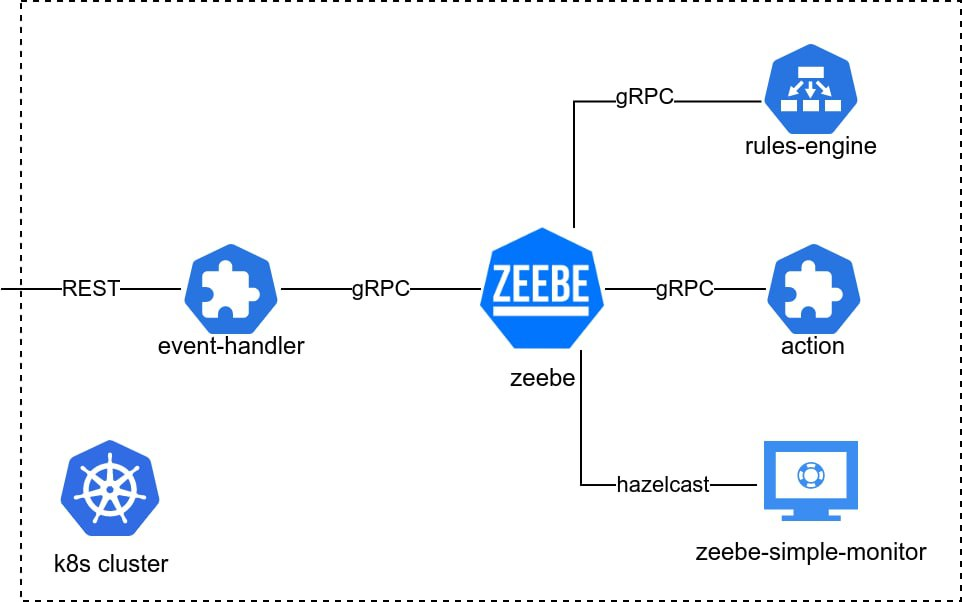
С точки зрения бизнес-логики в примере будет рассмотрен следующий бизнес-сценарий:
из внешней системы происходит запрос в виде rest-обращения с передачей параметров;
запускается бизнес-процесс, который «пропускает» входящие параметры через бизнес-правило;
в зависимости от полученного решения из бизнес-правил запускается микросервис действий с различными параметрами.
Теперь поговорим подробнее о каждом микросервисе.
Микросервис zeebe
Данный микросервис состоит из брокера сообщений ZeeBe и экспортера сообщений для отображения в simple-monitor. Для ZeeBe используется готовая сборка, которую можно скачать с github. Подробно о сборке контейнера можно посмотреть в исходном коде в файле build.sh
Принцип ZeeBe — минимальное число компонентов, входящих в ядро, поэтому по умолчанию ZeeBe — это брокер сообщений, работающий по схемам BPMN. Дополнительные модули подключаются отдельно: например, для отображения процессов в GUI понадобится экспортер (доступны разные экспортеры, к примеру, в ElasticSearch, в базу данных и т.п.).
В данном примере возьмем экспортер в Hazelcast. И подключим его:
добавим
zeebe-hazelcast-exporter-0.10.0-jar-with-dependencies.jarв папку exporters;добавим в файл
config/application.yamlследующие настройки:
exporters: hazelcast: className: io.zeebe.hazelcast.exporter.HazelcastExporter jarPath: exporters/zeebe-hazelcast-exporter-0.10.0-jar-with-dependencies.jar args: enabledValueTypes: "JOB,WORKFLOW_INSTANCE,DEPLOYMENT,INCIDENT,TIMER,VARIABLE,MESSAGE,MESSAGE_SUBSCRIPTION,MESSAGE_START_EVENT_SUBSCRIPTION" # Hazelcast port port: 5701
Данные активных процессов будут храниться в памяти, пока simplemonitor их не считает. Hazelcast будет доступен для подключения по порту 5701.
Микросервис zeebe-simplemonitor
Во фреймворке ZeeBe есть две версии GUI-интерфейса. Основная версия, Operate, обладает большим функционалом и удобным интерфейсом, однако, использование Operate ограничено специальной лицензией (доступна только версия для разработки, а лицензию для прода следует запрашивать у производителя).
Также есть облегченный вариант — simplemonitor (лицензируется по Apache License, Version 2.0)
Simplemonitor можно оформить тоже в виде микросервиса, который периодически подключается к порту hazelcast брокера ZeeBe и выгружает оттуда данные в свою базу данных.

Можно выбрать любую базу данных Spring Data JDBC, в данном примере используется файловая h2, где настройки, как и в любом Spring Boot приложении, вынесены в application.yml
spring: datasource: url: jdbc:h2:file:/opt/simple-monitor/data/simple-monitor-db;DB_CLOSE_DELAY=-1
Микросервис event-handler
Это первый сервис в цепочке, он принимает данные по rest и запускает процесс. При старте сервис осуществляет поиск файлов bpmn в папке ресурсов:
private void deploy() throws IOException { Arrays.stream(resourceResolver.getResources("classpath:workflow/*.bpmn")) .forEach(resource -> { try { zeebeClient.newDeployCommand().addResourceStream(resource.getInputStream(), resource.getFilename()) .send().join(); logger.info("Deployed: {}", resource.getFilename()); } catch (IOException e) { logger.error(e.getMessage(), e); } }); }
Микросервис имеет endpoint, и для простоты принимает вызовы по rest. В нашем примере передаются 2 параметра, сумма и лимит:
http://адрес-сервиса:порт/start?sum=100&limit=500
@GetMapping public String getLoad(@RequestParam Integer sum, @RequestParam Double limit) throws JsonProcessingException { Map<String, Object> variables = new HashMap<>(); variables.put("sum", sum); variables.put("limit", limit); zeebeService.startProcess(processName, variables); return "Process started"; }
Следующий код отвечает за запуск процесса:
public void startProcess(String processName, Map<String, Object> variables) throws JsonProcessingException { zeebeClient.newCreateInstanceCommand() .bpmnProcessId(processName) .latestVersion() .variables(variables) .send(); }
Сам процесс нарисован в специальной программе ZeeBe modeler (почти копия редактора Camunda modeler) и сохраняется в формате bpmn в папке workflow в ресурсах микросервиса. Графически процесс выглядит как:

У каждой задачи (обозначаем прямоугольником на схеме) есть свой тип задач, который устанавливается в свойствах задачи, например, для запуска правил:
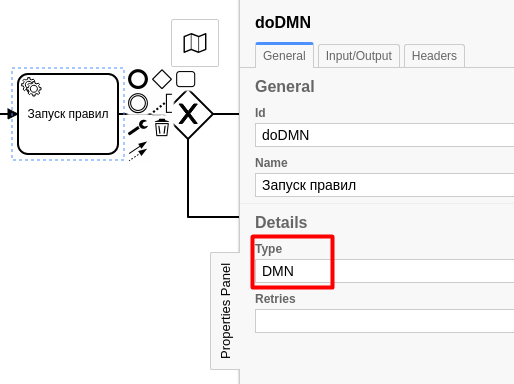
Каждый дополнительный микросервис в данном примере будет использовать свой тип задач. Тип задач очень похож на очередь в Kafka: при возникновении задач к нему могут подключаться подписчики — worker’ы.
После старта процесс продвинется на один шаг, и появится сообщение типа DMN.
Микросервис rules-engine
Благодаря прекрасной модульной архитектуре Camunda есть возможность использовать в своем приложении (отдельно от самого фреймворка Camunda) движок правил принятия решения.
Для его интеграции с вашим приложением достаточно добавить его в зависимости maven:
<dependency> <groupId>org.camunda.bpm.dmn</groupId> <artifactId>camunda-engine-dmn</artifactId> <version>${camunda.version}</version> </dependency>
Сами правила создаются в специальном графическом редакторе Camunda modeler. Одна диаграмма DMN имеет два вида отображения.
Entity Relation Diagram (вид сверху) показывает зависимости правил друг от друга и от внешних параметров:
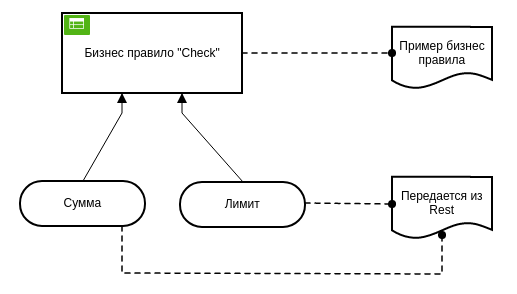
На такой диаграмме можно представить одно или несколько бизнес-правил. В текущем примере оно одно зависит от двух параметров — сумма и лимит. Представление на этой диаграмме параметров и комментариев необязательно, но является хорошим стилем оформления.
Само же бизнес-правило содержит более детальный вид:

Как видно из примера выше, бизнес-правило представляется в виде таблицы, в которой перечислены входящие и результирующие параметры. Инструмент достаточно богатый, и можно использовать различные методы сравнения, диапазоны, множества, несколько типов политик правил (первое совпадение, множественное, последовательность по диаграмме и т.п.). Такая диаграмма сохраняется в виде файла dmn.
Посмотрим на примере, где такой файл располагается в папке dmn-models в ресурсах микросервиса. Для регистрации диаграммы при старте микросервиса происходит его однократная загрузка:
public void init() throws IOException { Arrays.stream(resourceResolver.getResources("classpath:dmn-models/*.dmn")) .forEach(resource -> { try { logger.debug("loading model: {}", resource.getFilename()); final DmnModelInstance dmnModel = Dmn.readModelFromStream((InputStream) Resources .getResource("dmn-models/" + resource.getFilename()).getContent()); dmnEngine.parseDecisions(dmnModel).forEach(decision -> { logger.debug("Found decision with id '{}' in file: {}", decision.getKey(), resource.getFilename()); registry.put(decision.getKey(), decision); }); } catch (IOException e) { logger.error("Error parsing dmn: {}", resource, e); } }); }
Для того, чтобы подписаться на сообщения от ZeeBe, требуется осуществить регистрацию worker’а:
private void subscribeToDMNJob() { zeebeClient.newWorker().jobType(String.valueOf(jobWorker)).handler( (jobClient, activatedJob) -> { logger.debug("processing DMN"); final String decisionId = readHeader(activatedJob, DECISION_ID_HEADER); final Map<String, Object> variables = activatedJob.getVariablesAsMap(); DmnDecisionResult decisionResult = camundaService.evaluateDecision(decisionId, variables); if (decisionResult.size() == 1) { if (decisionResult.get(0).containsKey(RESULT_DECISION_FIELD)) { variables.put(RESULT_DECISION_FIELD, decisionResult.get(0).get(RESULT_DECISION_FIELD)); } } else { throw new DecisionException("Нет результата решения."); } jobClient.newCompleteCommand(activatedJob.getKey()) .variables(variables) .send() .join(); } ).open(); }
В данном коде осуществляется подписка на событие DMN, вызов модели правил при получении сообщения от ZeeBe и результат выполнения правила сохранятся обратно в бизнес-процесс в виде переменной result (константа RESULT_DECISION_FIELD).
Когда данный микросервис отчитывается ZeeBe о выполнении операции, бизнес-процесс переходит к следующему шагу, где происходит выбор пути в зависимости от выполнения условия, заданного в свойствах стрелочки:

Микросервис action
Микросервис action совсем простой. Он также осуществляет подписку на сообщения от ZeeBe, но другого типа — action.

В зависимости от полученного результата будет вызван один и тот же микросервис action, но с различными параметрами. Данные параметры задаются в закладке headers:

Также передачу параметров можно сделать и через закладку Input/Output, тогда параметры придут вместе с переменными процесса, но передача через headers является более «каноничной».
Посмотрим на получение сообщения в микросервисе:
private void subscribe() { zeebeClient.newWorker().jobType(String.valueOf(jobWorker)).handler( (jobClient, activatedJob) -> { logger.debug("Received message from Workflow"); actionService.testAction( activatedJob.getCustomHeaders().get(STATUS_TYPE_FIELD), activatedJob.getVariablesAsMap()); jobClient.newCompleteCommand(activatedJob.getKey()) .send() .join(); } ).open(); }
Здесь происходит логирование всех переменных бизнес-процесса:
public void testAction(String statusType, Map<String, Object> variables) { logger.info("Event Logged with statusType {}", statusType); variables.entrySet().forEach(item -> logger.info("Variable {} = {}", item.getKey(), item.getValue())); }
Исходный код
Весь исходный код прототипа можно найти в открытом репозитории GitLab.
Компиляция образов Docker
Все микросервисы проекта собираются командой ./build.sh
Для каждого микросервиса есть различный набор действий, направленных на подготовку образов docker и загрузки этих образов в открытые репозитории hub.docker.com.
Загрузка микросервисов в кластер k8s
Для развертывания в кластере необходимо сделать следующие действия:
Создать
namespaceв кластере kubectlcreate namespace zeebe-dmn-exampleСоздать
config-mapобщих настроек
kind: ConfigMap apiVersion: v1 metadata: name: shared-settings namespace: zeebe-dmn-example data: shared_servers_zeebe: <IP адрес кластера>
Далее создаем два персистентных хранилища для хранения данных zeebe и simplemonitor. Это позволит осуществлять перезапуск соответствующих подов без потери информации:
kubectl apply -f zeebe--sm-volume.yml
kubectl apply -f zeebe-volume.yml
Yml-файлы находятся в соответствующих проектах:

Теперь осталось последовательно создать поды и сервисы. Указанные yml-файлы находятся в корне соответствующих проектов. kubctl apply -f zeebe-deployment.yml
kubctl apply -f zeebe-sm-deployment.yml
kubctl apply -f event-handler-deployment.yml
kubctl apply -f rules-engine-deployment.yml
kubctl apply -f action-deployment.yml
Смотрим, как отображаются наборы подов в кластере:
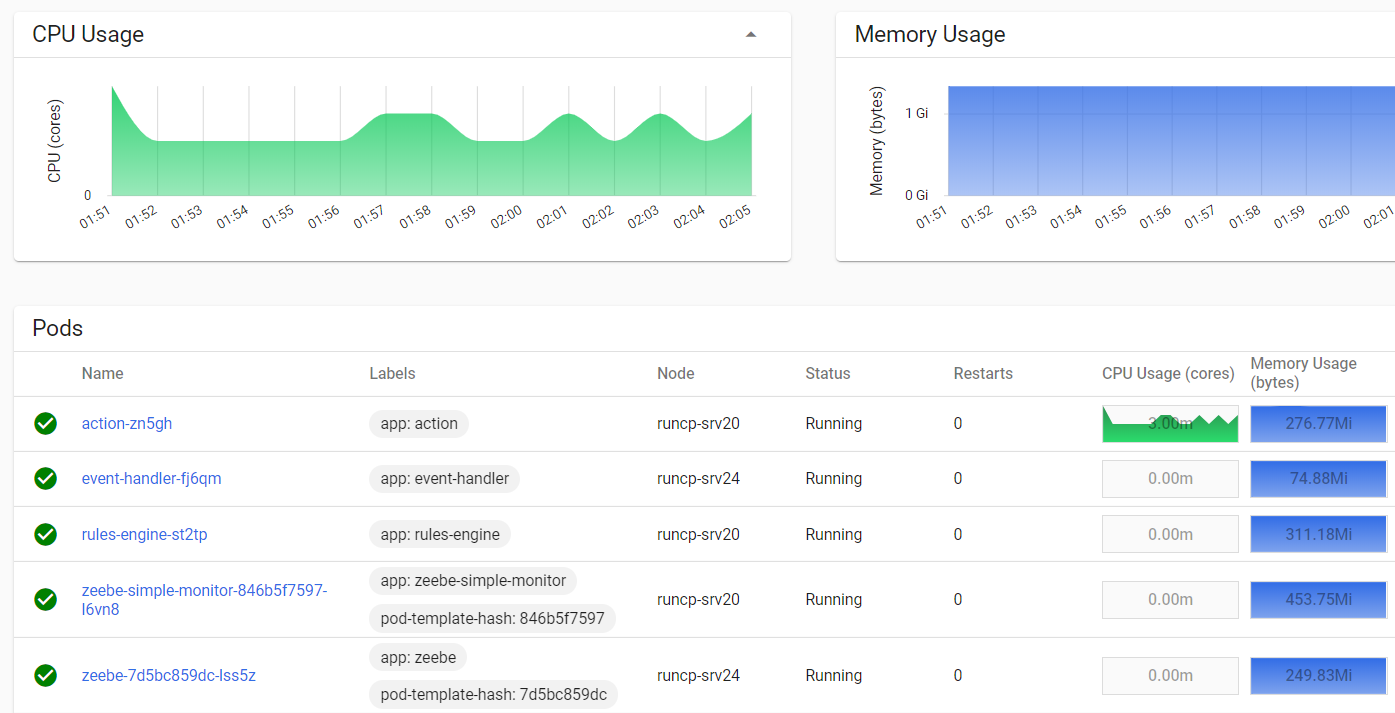
И мы готовы к тестовому запуску!
Запуск тестового процесса
Запуск процесса осуществляется открытием в браузере соответствующий URL. К примеру, сервис event-handler имеет сервис с внешним IP и портом 81 для быстрого доступа.
http://адрес-кластера:81/start?sum=600&limit=5000
Process started
Далее можно проверить отображение процесса в simplemonitor. У данного микросевиса тоже есть внешний сервис с портом 82.

Зеленым цветом выделен путь, по которому прошел процесс. Серым выделены выполненные задачи, а снизу отображены переменные процесса.
Теперь можно просмотреть лог микросервиса action, там можно увидеть значение переменной statusType, которое соответствует варианту прохождения процесса.

Поделюсь, какими ресурсами пользовался для подготовки прототипа
Небольшое послесловие вместо итогов
Из плюсов:
архитектура разработанного прототипа получилась гибкой и расширяемой. Можно добавлять любое количество микросервисов для обработки сложной логики;
простая нотация BPMN и DMN позволяет привлекать аналитиков и бизнес к обсуждению сложной логики;
Zeebe показал себя как очень быстрый фреймворк, задержки на получение/отправку сообщений практически отсутствуют;
Zeebe изначально разрабатывался для работы в кластере, в случае необходимости можно быстро нарастить мощности;
без ZeeBe Operate можно вполне обойтись, Simple-Monitor отвечает минимальным требованиям.
Из минусов:
хотелось бы иметь возможность редактирования DMN непосредственно в ZeeBe modeler (как это реализовано в Camunda), на данный момент, приходится использовать оба моделлера;
к сожалению, только в Enterprise версии Camunda есть возможность просмотра пути, по которому принималось решение:

Это очень полезная функция при отладке правил. В Community версии приходится добавлять дополнительное поле типа output для логирования, либо разработать свое решение визуализации.
При развертывании прототипа в реальных условиях в кластере k8s необходимо добавить ограничения по ресурсам (CPU и RAM), также нужно будет подобрать лучшую систему хранения исторических данных.
Где применять такие технологии:
как оркестрация внутри одной команды или продукта в виде перекладывания сложной логики на диаграммы BPMN / DMN;
в сфере, где идет потоковая обработка данных с большим количеством интеграций. В банке это может быть проведение или проверка транзакций, обработка данных из внешних систем или просто многоэтапная трансформация данных;
как частичная альтернатива существующего стека ESB или Kafka для интеграции между командами.
Коллеги, понимаю, что есть множество разных технологий и подходов. Буду рад, если поделитесь в комментариях вашим опытом: как вы решаете подобные задачи?

