
В предыдущих постах серии о service mesh мы говорили о настройке инфраструктуры для модернизации нашей микросервисной архитектуры и архитектуры балансировки нагрузки, а также о том, как мы обеспечиваем высокую доступность для использования всех замечательных возможностей service mesh без перебоев.
В этом посте мы переключим внимание на то, как наши микросервисы используют service mesh для взаимодействия друг с другом. В частности, какая полезная нагрузка используется для запросов и как мы мигрировали с одной на другую. Мы сравним наши текущие полезные нагрузки на основе Representational State Transfer (REST) с высокопроизводительным Remote Procedure Call (gRPC) и рассмотрим проблемы, с которыми мы столкнулись при внедрении, использовании и миграции на gRPC.
От RESTful к gRPC
Как уже упоминалось в наших предыдущих постах, в настоящее время мы запускаем множество микросервисов в Google Kubernetes Engine (GKE), где одни микросервисы взаимодействуют с другими, формируя группы или графы микросервисов, реализующих совместно необходимую бизнес-логику:

Каждый граф, сформированный из группы микросервисов, может участвовать в транзитивной связи. Например, сервис X, может посылать запросы N сервисам, а N сервисов, в свою очередь, могут послать запросы к М сервисам и так далее. Запросы между этими микросервисами, как показано на рисунке 1, включают в себя RESTful полезные нагрузки, которые передаются с помощью HTTP/1.1.
По мере увеличения количества микросервисов в нашей инфраструктуре, также растет стоимость обслуживания платформы, обеспечивающей коммуникационные возможности микросервисов. В частности, когда мы начали рассматривать миграцию наших критически важных микросервисов на gRPC, мы хотели получить поддержку нескольких языков и платформ, масштабируемость, постоянные и переиспользуемые соединения между клиентом и сервером (используя HTTP/2 и Linkerd) и двунаправленную потоковую передачу с помощью gRPC.

Легаси сервисы, поддерживающие только REST API, постепенно переводятся на gRPC. На рисунке 2 показана группа сервисов, которые взаимодействуют друг с другом через REST и gRPC. Позже в этом посте мы рассмотрим, как модифицируются сервисы для работы с обоими форматами сериализации до тех пор, пока все их API не будут переведены на gRPC.
По мере появления новых микросервисов и языков в нашей инфраструктуре, возможности gRPC становились для нас все более важными, как с точки зрения облегчения сопровождения при увеличении масштабируемости инфраструктуры, так и с точки зрения упрощения интеграции между микросервисами. В документации gRPC на примерах рассказываются преимущества использования gRPC. А на нашей недавней встрече, посвященной gRPC, мы подробно обсуждали некоторые варианты использования и возможности, которые могут быть использованы в инфраструктурах, подобных нашей.
Почему gRPC?
В WePay каждый микросервис использовал REST с полезной нагрузкой в виде JSON. У REST есть несколько преимуществ для коммуникаций между сервисами:
JSON-данные просты для понимания.
Зрелый формат сериализации и есть множество фреймворков для создания REST-сервисов.
REST — очень популярный стандарт, не зависящий от языка и платформы.
По мере увеличения количества микросервисов в инфраструктуре граф сервисов становится все более сложным, в результате чего возникают проблемы и ограничения в использовании REST:
Например, на рисунке 1, клиент обращается к сервису X, а сервис X, в свою очередь, может обратиться к другим сервисам для формирования ответа клиенту.
Для каждого REST-вызова между сервисами устанавливается новое соединение и появляются накладные расходы на SSL handshake. Это приводит к увеличению общей задержки.
Для каждого сервиса клиент должен быть реализован на всех требуемых языках, а также должен обновляться при каждом изменении API.
Полезная нагрузка JSON — это простой текст, который имеет относительно низкую производительность сериализации и десериализации.
Учитывая эти проблемы, gRPC казался нам хорошим вариантом для улучшения взаимодействия микросервисов в нашей инфраструктуре.
В gRPC клиентское приложение может напрямую вызывать методы сервиса на другой машине, так как если бы это был локальный объект, что упрощает создание распределенных сервисов.

(источник)
Преимущества gRPC:
Аналогично RPC-протоколам, gRPC основан на идее определения сервиса и его методов с параметрами и типами возвращаемых значений, которые могут вызываться удаленно.
Построение графов вызовов микросервисов с низкой задержкой и высокой масштабируемостью.
Использование Protocol Buffers, что обеспечивает лучшую производительность по сравнению с JSON.
Возможность автоматической генерации клиентских стабов, что снижает необходимость создавать и обслуживать клиентские библиотеки.
Protobuf
Protobufs — это текстовые файлы с расширением ".proto", определяющие структуру сообщения. Они компактны, строго типизированы и поддерживают обратную совместимость. Используются для определения сервиса, а также структуры запроса и ответа.

Листинг 1. gRPC-сервис HelloWorld с одним RPC-методом "SayHello".
Protobufs лучше сериализуется / десериализуется в бинарный формат. Что делает его быстрее JSON. Кроме того, клиенты могут работать с типизированными объектами, а не с JSON-данными в свободной форме.

Для каждого языка есть свой protobuf-компилятор, который преобразует proto-файлы в исходный код. Например, если мы пытаемся "скомпилируем" пример, приведенный в листинге 1, в исходный код на Java, то компилятор сгенерирует:
Базовый класс, от которого можно наследоваться и реализовать RPC-методы.
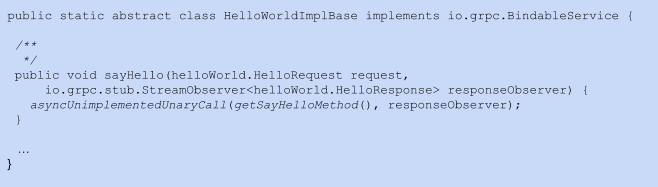
Листинг 2. Класс HelloWorld на Java, сгенерированный автоматически
Стабы (заглушки), которые могут быть инстанциированы клиентами для выполнения методов на удаленном сервере.

Листинг 3. Стаб HelloWorld для Java-клиентов
Объекты сообщений для запросов и ответов, которыми обмениваются сервер и клиент.

Листинг 4. Сгенерированный код на Java для protobuf-сообщений
Переиспользование соединения
gRPC использует HTTP/2. HTTP/2 позволяет более эффективно использовать сетевые ресурсы и уменьшает задержки, используя сжатие заголовков и возможности мультиплексирования запросов. В gRPC соединение и обмен данными называются каналом (channel) и вызовом (call). Таким образом, gRPC помогает уменьшить задержку создания новых соединений при каждом запросе, что было одним из наших ограничений в случае REST.
Как перейти с REST на gRPC?
Основываясь на вышеупомянутых преимуществах, мы решили перевести наши REST-сервисы на gRPC. Мы рассмотрели множество стратегий миграции. Одним из подходов было создание gRPC приложения и использование grpc-gateway для генерации обратного прокси-сервера, который конвертирует RESTful JSON API в gRPC. Это потребовало добавления пользовательских параметров к определениям gRPC в protobufs и создания еще одного контейнера для запуска этого обратного прокси-сервера.
Для себя мы сформулировали несколько важных требований по миграции сервисов на gRPC:
Минимальное количество доработок.
Не вносить изменения в текущий пайплайн сборки и развертывания.
На первом шаге поддерживать как REST, так и gRPC и постепенно мигрировать все коммуникации на gRPC. Таким образом, существующие клиенты смогут продолжать общаться с серверами через REST, пока они не будут мигрированы.
Для gRPC-микросервисов использовать те же базовые подходы, что и для REST-микросервисов. Например, REST-микросервисы по умолчанию наследуют несколько общих конечных точек, которые помогают нам их мониторить. gRPC-сервисы также должны поддерживать это.
Исходя из этих критериев мы решили запускать gRPC-сервер отдельным потоком в REST-приложении.

В результате мы создали общую библиотеку, которую подключаем к нашим микросервисам. Эта разделяемая библиотека включает в себя сервис мониторинга, реализующий RPC-методы для проверки работоспособности gRPC-сервиса. В ней реализован "GrpcServerBuilder", который содержит:
Возможность добавления "перехватчиков" (interceptor) для обработки исключений, трассировки запросов/ответов, аутентификации и т. д.
Сервис мониторинга, который предоставляет RPC-методы для проверки работоспособности сервиса и его зависимостей.
Разработчики используют GrpcServerBuilder из общей библиотеки и реализуют gRPC-сервис. Это обеспечивает стандартный подход к мониторингу работоспособности всех наших микросервисов.
Коммуникации с использованием Service Mesh
Как мы упоминали в предыдущей статье об использовании Linkerd в качестве service mesh прокси в WePay, Linkerd из коробки поддерживает HTTP/2 и gRPC. Но настроить маршрутизацию gRPC-вызовов к соответствующему сервису Kubernetes было непросто. В service mesh REST-вызовы от клиентов перенаправлялись на сервисы, запущенные в Kubernetes, через указание имени сервиса в адресе (path). Например, если у нас есть сервис Kubernetes с именем "foo", то с помощью Linkerd клиентские вызовы можно перенаправить, используя адрес "foo/".
gRPC в качестве транспорта использует HTTP/2. Запросы и ответы между gRPC-сервисами опредены спецификацией и одно из основных полей в запросе — "path". Path для запроса установлен в:
<package_name>.<grpc_service_name>/<method_name>
Linkerd в качестве идентификатора для маршрутизации запросов от клиентов к сервисам может использовать или path или заголовок. В случае с gRPC при выборе идентификатора возникло несколько проблем:
В общем случае имена сервисов Kubernetes не совпадают с именами сервисов gRPC. Например, может существовать сервис Kubernetes с именем "greeter", который запускает gRPC-сервис с именем "GreeterService".
Приложение, в котором запущен сервер gRPC, может содержать в себе реализацию одного или нескольких gRPC-сервисов. Например, по умолчанию ко всем нашим gRPC-микросервисам мы добавляем gRPC-сервис мониторинга.
Это затрудняет использование адреса (path) в качестве идентификатора. Но эту проблему мы решили, принудив клиентов устанавливать пользовательский заголовок "service" для имени сервиса Kubernetes и настроив Linkerd на использование этого заголовка "service" в качестве идентификатора для вызовов gRPC.

Также в библиотеке, которую мы создали для клиентов, добавлена опция установки заголовка в качестве имени целевой службы Kubernetes. Linkerd использует этот заголовок и идентификатор для маршрутизации запросов от клиента к сервису.
Жизненный цикл CI/CD для gRPC-сервисов
Для разработки gRPC-сервиса необходимо выполнить следующие этапы:
Написать определения сервисов, запросов и ответов в виде protobufs.
Валидировать protobuf-файлы, прежде чем использовать их для генерации кода.
Реализовать сервер и клиент(ов).
Также необходимо принять решения и по следующим моментам:
Где хранить protobuf-файлы?
Как генерировать код и использовать его для реализации серверов и клиентов?
Если изменить proto-файл, то как убедиться, что клиент также был обновлен?
В этом разделе описывается, как мы смогли решить эти вопросы и настроить жизненный цикл gRPC-сервисов.

В WePay мы используем сервис-ориентированную архитектуру (Service Oriented Architecture), и поэтому нам необходимо писать и поддерживать protobuf-файлы для множества сервисов. Хранить protobuf-файлы с определениями всех gRPC-серверов мы решили в центральном git-репозитории.
protos/ |-<service-x>/ |- **/*.proto |-<service-y>/ |- **/*.proto |-commons/ |- **/*.proto
Эти proto-файлы валидируются с помощью prototool на серверах непрерывной интеграции, а затем в git-репозитории создаются release-теги.
Для реализации gRPC-серверов и клиентов нам нужно сгенерировать код из protobufs. Мы делаем это, загружая в репозиторий приложения protobufs-файлы по release-тегам, а потом используем компилятор protoc для генерации кода на нужном языке.
В настоящее время мы генерируем документацию для REST API с помощью RAML, Swagger и других подобных инструментов. Генерация документации встроена в процесс сборки. Построение документации для gRPC мы настроили аналогично с помощью плагина protoc-gen-doc.
Проблемы при переходе на gRPC
У gRPC есть много преимуществ, но не все REST-микросервисы, могут быть перенесены на gRPC. Например, миграция внешних сервисов может потребовать модификации клиентов, использующих REST API.
При миграции существующих REST-микросервисов на gRPC у нас возникло несколько проблем, связанных с gRPC. Ниже приведены наиболее существенные из них.
Поддержка в браузерах
До недавнего времени в браузерах не было поддержки gRPC. На текущий момент одно из популярных решений для предоставления браузеру доступа к gRPC-сервису — это использование grpc-web. Браузер подключается к gRPC-сервису через специальный прокси шлюз. Для внешних сервисов мы не использовали grpc-web, потому что GA-версия еще не была доступна, когда мы принимали это решение. Также у нас много JSON-схем для фронтенда, и преобразование всех их в proto нетривиально. Это также требовало обновления всех наших SDK.
Ограничения Protobuf
Некоторые из наших API также должны различать в запросах и ответах следующие ситуации:
Поле присутствует или нет
Поле присутствует со значением null
Поле присутствует со значением не null
Используя proto3, мы не можем простым способом это все идентифицировать. Хотя для определения, установлено поле или нет, можно использовать google wrappers. Определять значение null нам, например, нужно в запросах на update и в запросах на установку отдельных полей в null. В таких сценариях мы можем использовать маски полей.
gRPC и HTTP-фреймворки
В настоящее время микросервисы, написанные с использованием REST-фреймворков, предполагают, что обработчики запросов являются частью HTTP-стека и выполняют такие операции, как аутентификация, логгирование запросов / ответов, отслеживание метрик и т.д.
Но готовых gRPC-фреймворков, которые функционально соответствовали бы используемым HTTP-фреймворкам, пока нет. Хотя gRPC предоставляет "Interceptors" (перехватчики) для реализации необходимого функционала. Мы пишем перехватчиков для функций, которые хотим добавить в наши gRPC-сервера, и помещаем их в общую библиотеку, которая используется всеми микросервисами.
Версии Protobuf
Язык описания Protocol buffers имеет две версии синтаксиса: Proto2 и Proto3. gRPC поддерживает обе версии. Proto2 и Proto3 похожи, но имеют несколько отличий.
Таблица 1. Сравнение proto2 и proto3
Функциональность | Proto2 | Proto3 |
Можно установить поля в NULL | Нет | Нет |
Обязательные поля в сообщении | Да | Нет |
Возможность установки пользовательских значений по умолчанию | Да | Убрана возможность установки значений по умолчанию. Примитивные поля со значением по умолчанию не сериализуются. |
Преобразование в JSON | Нет. Только бинарная сериализация protobuf | Дополнительно есть преобразование в JSON |
Проверка UTF-8 | Не строгая | Строгая |
Для отсутствующего поля возможность определить, что оно не было включено или что оно имеет значение по умолчанию | Да | Нет. В Proto3, когда мы используем примитивные поля, мы не можем отличить значение по умолчанию от того, что поле не установлено. Это можно обойти, используя обёртки (wrappers, известные прототипы) вместо примитивов. |
Сложно решить, какую версию protocol buffers использовать. Как вы видите из таблицы 1, есть некоторые обратно несовместимые изменения между proto2 и proto3. Так что, если gRPC-сервисы уже используют proto2, то лучше ничего не менять. Если мы хотим использовать такие возможности, как установка пользовательских значений по умолчанию, идентификация отсутствующего поля, обязательные поля, то мы можем использовать proto2. Можно выбрать proto3, если хотим использовать новые возможности и альтернативы тем возможностям, которые доступны только в proto2.
Заключение
Исходя из количества микросервисов, требований к производительности и удобству обслуживания, мы решили строить наши новые микросервисы с использованием gRPC и где это применимо, перенести все наши существующие микросервисы на gRPC.
Это дает нам:
Строго типизированные определения сервисов и запросов / ответов, которые пишутся один раз и для нужных языков генерируется исходный код.
Лучшую производительность с HTTP/2 при переиспользовании соединений.
Уменьшение проблем с созданием клиентских библиотек.
Поддержку потоковой передачи данных.
Теперь, когда мы улучшили взаимодействие между сервисами во всей нашей инфраструктуре, мы должны поддерживать инфраструктуру и платформы, на которых работают эти сервисы, в актуальном состоянии и постоянно совершенствовать.
В марте OTUS запускает сразу 2 курса по Java-разработке c разными уровнями сложности. Узнать подробнее о курсах можно по ссылкам ниже:
Также приглашаем всех желающих записаться на бесплатные демо-уроки курсов, первый из которых пройдет уже 19 марта. Ссылки на мероприятия ниже:
- Как работает Интернет (посмотрим, что происходит, когда в браузере вводите адрес и открывается сайт);

