
Дисклеймер: эта статья рассчитана на понимание основных принципов работы InterPlanetary File System. Если вы не знакомы с IPFS, начните с этой статьи или загляните на ipfs.io.
Самый известный и труднопреодолимый недостаток IPFS в скорости её работы. Так как все данные разбиваются на блоки и распределяются по пирам, скорость загрузки упирается в скорость интернета (и вообще доступность) сразу нескольких машин, которые мы не контролируем. Частично это решается локальным закреплением (pin) нужных хэшей, что поможет в случае отказа отдельных пиров, но не гарантирует загрузку именно с нашего сервера (например, если запрос поступит с другой части планеты). А ещё зашифрованные и разрезанные данные гипотетически невозможно восстановить, не имея хэша, но ведь и его теоретически можно подобрать, так как вся сеть по сути публична…
Всех этих неприятностей можно избежать, запустив собственный кластер IPFS. Новичку легко запутаться и решить что IPFS это децентрализованная сеть, но на самом деле это протокол, обёртка над p2p — и на нём можно поднимать свои приватные подсети, недоступные извне, сохраняя плюсы децентрализации и все фишки основной сети.
Допустим, у нас есть конфиденциальные данные, которые мы хотим синхронизировать на нескольких серверах, с надёжной защитой и в то же время с возможностью доступа извне вручную или по API. Мы установим и настроим свой IPFS Cluster и проверим его работоспособность.
Установка
Для небольших объёмов данных подойдут сервера минимальной мощности, но для перекачки десятков гигабайтов придётся замерять нагрузку и при необходимости добавлять ресурсы. Все инструменты IPFS не привязаны к конкретной платформе, билды доступны для Linux/MacOS/Windows/FreeBSD/OpenBSD на архитектурах 32-bit/64-bit/ARM/ARM-64. Мы будем воспроизводить настройку традиционных Ubuntu/Debian-based серверов.
Для работы с кластером нужно всего три инструмента:
- go-ipfs, реализация основного функционала IPFS
- ipfs-cluster-service, он поднимает пир
- ipfs-cluster-ctl нужен для управления кластером и данными
wget https://dist.ipfs.io/ipfs-cluster-service/v0.13.1/ipfs-cluster-service_v0.13.1_linux-amd64.tar.gz tar -xzf ipfs-cluster-service_v0.13.1_linux-amd64.tar.gz wget https://dist.ipfs.io/ipfs-cluster-ctl/v0.13.1/ipfs-cluster-ctl_v0.13.1_linux-amd64.tar.gz tar -xzf ipfs-cluster-ctl_v0.13.1_linux-amd64.tar.gz wget https://dist.ipfs.io/go-ipfs/v0.8.0/go-ipfs_v0.8.0_linux-amd64.tar.gz tar -xzf go-ipfs_v0.8.0_linux-amd64.tar.gz sudo cp ipfs-cluster-service/ipfs-cluster-service /usr/local/bin sudo cp ipfs-cluster-ctl/ipfs-cluster-ctl /usr/local/bin cd ~/go-ipfs sudo ./install.sh
Проверим установку:
ipfs-cluster-service -v # ipfs-cluster-service version 0.13.1 ipfs-cluster-ctl -v # ipfs-cluster-ctl version 0.13.1 ipfs version # ipfs version 0.8.0
Настройка
Запишем секретный ключ для авторизации пиров:
export CLUSTER_SECRET=$(od -vN 32 -An -tx1 /dev/urandom | tr -d ' \n') echo $CLUSTER_SECRET
Теперь инициализируем пир и саму IPFS:
ipfs init ipfs-cluster-service init --consensus raft # configuration written to /%username%/.ipfs-cluster/service.json. # new empty peerstore written to /%username%/.ipfs-cluster/peerstore.
В
service.json хранится конфиг пира с секретным ключом и настройками для подключения, кластера, API, разрешения конфликтов и мониторинга. Всё будет работать на дефолтных значениях, но будет полезно изучить его.По очереди запускаем демонов IPFS…
ipfs daemon
… и пира
ipfs-cluster-service daemon
С примерно таким результатом:
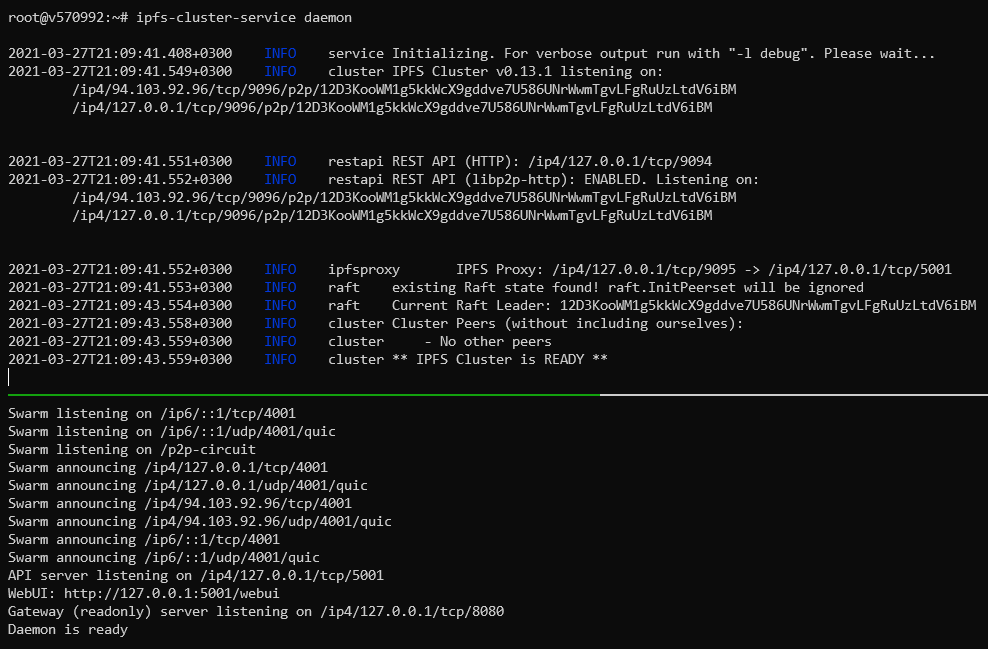
Теперь можно присоединять остальные пиры к кластеру. Точно так же устанавливаем на них
go-ipfs и ipfs-cluster-service, затем сохраняем наш секретный ключ с первого сервера:export CLUSTER_SECRET=78e30b2a6af...
Если ключ потерялся, его всё ещё можно найти в конфиге первого сервера:
cat .ipfs-cluster/service.json | grep secret # "secret": "78e30b2a6af..."
Нам также понадобится peer id каждого нового сервера, его можно получить командой
ipfs id:ipfs id # { # "ID": "12D3KooWEbaDTKDdXFKTyhW3TBGrttkfCYLhSBLGBGT3LB8e4ny5", # "PublicKey": "CAESIEcDgWEyAuAGSbEa0j1HPI2lBoaPrzTvDIkBoduSCI0w", # "Addresses": null, # "AgentVersion": "go-ipfs/0.8.0/", # "ProtocolVersion": "ipfs/0.1.0", # "Protocols": null # }
Теперь инициализируем пир и добавим его в кластер:
ipfs-cluster-service init --consensus raft ipfs-cluster-service daemon –bootstrap /ip4/ip_первого_сервера/tcp/9096/ipfs/peer_id_текущего сервера
Готово! Теперь все сервера будут работать в одной подсети IPFS, причём данные будут недоступны в основной (публичной сети).
Запишем файл hello.txt и добавим его в IPFS:
echo Привет, хабр! > hello.txt ipfs-cluster-ctl add hello.txt # added QmWF7EZ861jrrKgrVZjVpQekpKhEWnp5c5CX22cVsw5KMY hello.txt
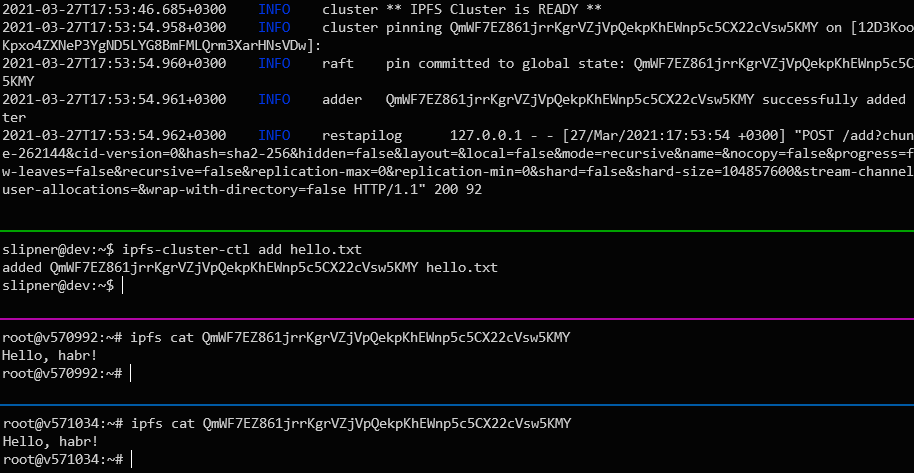
Считаем его с других серверов (появится не моментально, но довольно быстро по меркам IPFS):
ipfs cat QmWF7EZ861jrrKgrVZjVpQekpKhEWnp5c5CX22cVsw5KMY # Hello, habr!
Так это выглядит (первые две панели — с сервера, где мы добавили файл, две остальные с удалённых пиров):
Проверим хэш на публичном gateway клаудфлары:
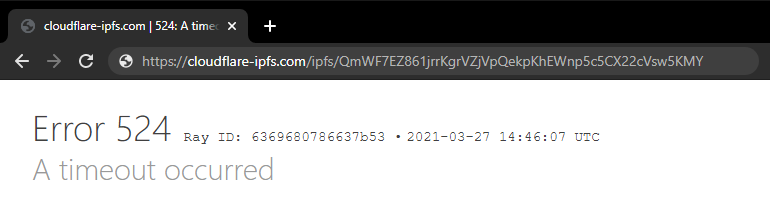
Любой запрос к несуществующему в основной сети хэшу заканчивается таймаутом
Заключение
У IPFS Cluster ещё много прикольных плюшек, здесь мы только показали, насколько просто запустить его прямо из коробки. Продолжить изучение можно по ссылкам:
Сайт
Документация
GitHub
Список открытых (collaborative) кластеров
На правах рекламы
Закажите сервер и сразу начинайте работать! Создание VDS любой конфигурации в течение минуты, в том числе серверов для хранения большого объёма данных до 4000 ГБ. Эпичненько.


