
Разработка прогнозной модели нейронной сети для нового набора данных может оказаться сложной задачей.
Один из подходов состоит в том, чтобы сначала проверить набор данных и разработать идеи о том, какие модели могут работать, затем изучить динамику обучения простых моделей в наборе данных, а затем, наконец, разработать и настроить модель для набора данных с помощью надёжного тестового набора.
Этот процесс можно использовать для разработки эффективных моделей нейронных сетей для задач классификации и регрессионного прогнозного моделирования.
В этом руководстве вы узнаете, как разработать модель нейронной сети многослойного персептрона для набора данных двоичной классификации банкнот.
После прохождения этого урока вы будете знать:
как загрузить и обобщить набор данных о банкноте и использовать результаты, чтобы предложить подготовку данных и конфигурации модели для использования;
как изучить динамику обучения простых моделей MLP в наборе данных;
как разработать надежные оценки производительности модели, настроить производительность модели и сделать прогнозы на основе новых данных.
Давайте начнём.
Набор данных классификации банкнот
Первый шаг — определить и изучить набор данных.
Мы будем работать со стандартным набором данных двоичной классификации «Банкнота».
Набор данных банкноты включает в себя прогнозирование подлинности данной банкноты с учётом ряда мер, взятых из фотографии.
Набор данных содержит 1372 строки с 5 числовыми переменными. Это проблема классификации с двумя классами (двоичная классификация).
Ниже представлен список пяти переменных в наборе данных:
дисперсия Вейвлет-преобразованного изображения (непрерывная);
асимметрия Вейвлет-преобразованного изображения (непрерывная);
эксцесс Вейвлет-преобразованного изображения (непрерывный);
энтропия изображения (непрерывная);
класс (целое число).
Ниже приведён образец первых 5 строк набора данных.
3.6216,8.6661,-2.8073,-0.44699,0 4.5459,8.1674,-2.4586,-1.4621,0 3.866,-2.6383,1.9242,0.10645,0 3.4566,9.5228,-4.0112,-3.5944,0 0.32924,-4.4552,4.5718,-0.9888,0 4.3684,9.6718,-3.9606,-3.1625,0 ...
Вы можете посмотреть весь набор данных здесь:
Мы можем загрузить набор данных как DataFrame pandas прямо из URL-адреса.
Например:
# load the banknote dataset and summarize the shape from pandas import read_csv # define the location of the dataset url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/banknote_authentication.csv' # load the dataset df = read_csv(url, header=None) # summarize shape print(df.shape)
При выполнении кода набор данных загружается непосредственно из URL-адреса и выводится форма набора данных.
В этом случае мы можем подтвердить, что набор данных имеет 5 переменных (4 входных и одна для вывода) и что набор содержит 1372 строки.
Это не так много строк для нейронной сети, и предполагается, что небольшая сеть, возможно, с регуляризацией, будет подходящей.
Это также предполагает, что использование перекрёстной проверки в k-кратном размере было бы хорошей идеей, потому что она даст более надёжную оценку производительности модели, чем разделение на обучение/тест, и потому что одна модель будет соответствовать секундам, а не часам или дням обучения.
(1372, 5)
Затем мы можем узнать больше о наборе данных, просмотрев сводную статистику и график данных.
# show summary statistics and plots of the banknote dataset from pandas import read_csv from matplotlib import pyplot # define the location of the dataset url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/banknote_authentication.csv' # load the dataset df = read_csv(url, header=None) # show summary statistics print(df.describe()) # plot histograms df.hist() pyplot.show()
При выполнении примера сначала загружаются данные, а затем выводится сводная статистика для каждой переменной.
Мы видим, что значения различаются в зависимости от средних значений и стандартных отклонений, возможно, перед моделированием потребуется некоторая нормализация или стандартизация.
0 1 2 3 4 count 1372.000000 1372.000000 1372.000000 1372.000000 1372.000000 mean 0.433735 1.922353 1.397627 -1.191657 0.444606 std 2.842763 5.869047 4.310030 2.101013 0.497103 min -7.042100 -13.773100 -5.286100 -8.548200 0.000000 25% -1.773000 -1.708200 -1.574975 -2.413450 0.000000 50% 0.496180 2.319650 0.616630 -0.586650 0.000000 75% 2.821475 6.814625 3.179250 0.394810 1.000000 max 6.824800 12.951600 17.927400 2.449500 1.000000
Затем для каждой переменной создаётся гистограмма.
Мы можем видеть, что, возможно, первые две переменные имеют гауссовоподобное распределение, а следующие две входные переменные могут иметь искажённое гауссово распределение или экспоненциальное распределение.
У нас может быть некоторая выгода от использования степенного преобразования для каждой переменной, чтобы сделать распределение вероятностей менее искажённым, что, возможно, улучшит производительность модели.
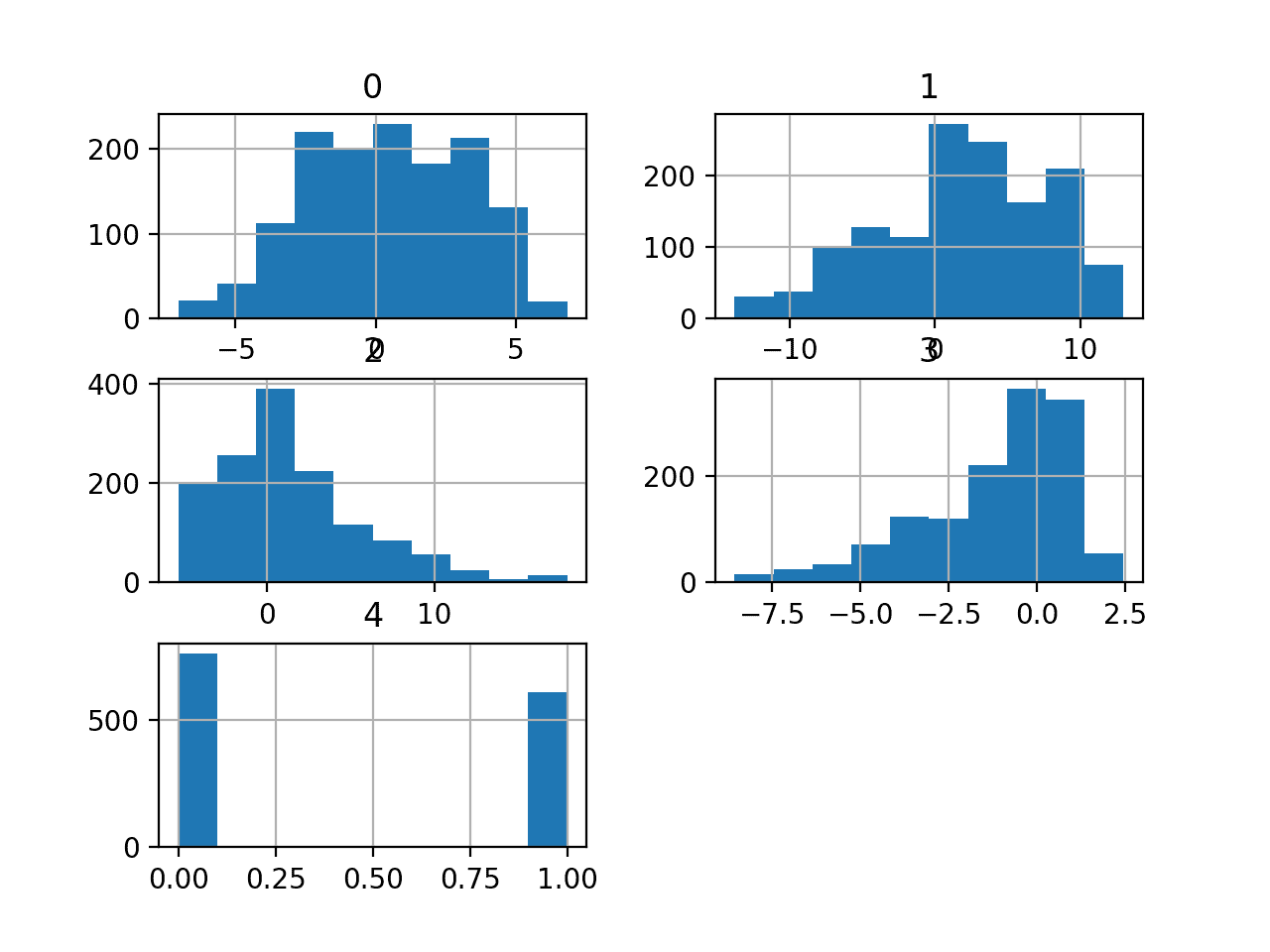
Теперь, когда мы знакомы с набором данных, давайте посмотрим, как можно разработать модель нейронной сети.
Динамика обучения нейронной сети
Мы разработаем модель многослойного персептрона (MLP) для набора данных, используя TensorFlow.
Мы не можем знать, какая модельная архитектура обучения гиперпараметрам будет хорошей или лучшей для этого набора данных, поэтому мы должны поэкспериментировать и выяснить, что работает лучше.
С учётом того, что набор данных невелик, небольшой размер пакета, вероятно, является хорошей идеей, например, 16 или 32 строки. Использование Адамовской версии стохастического градиентного спуска — хорошая идея для начала работы, так как она автоматически адаптирует скорость обучения и хорошо работает на большинстве наборов данных.
Прежде чем мы будем оценивать модели всерьёз, рекомендуется проанализировать динамику обучения и настроить архитектуру модели и конфигурацию обучения до тех пор, пока у нас не будет стабильной динамики обучения, а затем посмотреть, как получить максимальную отдачу от модели.
Мы можем сделать это, используя простое разделение данных на обучение/тест и просматривая графики кривых обучения. Это поможет нам понять, переучиваемся мы или недоучиваемся; тогда мы сможем соответствующим образом адаптировать конфигурацию.
Во-первых, мы должны убедиться, что все входные переменные являются значениями с плавающей запятой, и закодировать целевую метку как целочисленные значения 0 и 1.
... # ensure all data are floating point values X = X.astype('float32') # encode strings to integer y = LabelEncoder().fit_transform(y)
Затем мы можем разделить набор данных на переменные входа и выхода, а затем на наборы для обучения и тестирования 67/33.
... # split into input and output columns X, y = df.values[:, :-1], df.values[:, -1] # split into train and test datasets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33)
Мы можем определить минимальную модель MLP. В этом случае мы будем использовать один скрытый слой с 10 узлами и один выходной слой (выбранный произвольно). Мы будем использовать функцию активации ReLU в скрытом слое и инициализацию веса «he_normal», поскольку их совместное использование является хорошей практикой.
Результатом этой модели является активация сигмоида для двоичной классификации, и мы минимизируем двоичную кросс-энтропийную потерю.
... # determine the number of input features n_features = X.shape[1] # define model model = Sequential() model.add(Dense(10, activation='relu', kernel_initializer='he_normal', input_shape=(n_features,))) model.add(Dense(1, activation='sigmoid')) # compile the model model.compile(optimizer='adam', loss='binary_crossentropy')
Мы подгоним модель для 50 тренировочных эпох (выбранных произвольно) с размером пакета 32, потому что это небольшой набор данных.
Мы подгоняем модель под необработанные данные, что, по нашему мнению, может быть хорошей идеей, и это важная отправная точка.
... # fit the model history = model.fit(X_train, y_train, epochs=50, batch_size=32, verbose=0, validation_data=(X_test,y_test))
В конце обучения мы оценим производительность модели на тестовом наборе данных и выведем производительность как точность классификации.
... # predict test set yhat = model.predict_classes(X_test) # evaluate predictions score = accuracy_score(y_test, yhat) print('Accuracy: %.3f' % score)
Наконец, мы построим кривые обучения кросс-энтропийных потерь для наборов обучения и тестовых наборов во время обучения.
... # plot learning curves pyplot.title('Learning Curves') pyplot.xlabel('Epoch') pyplot.ylabel('Cross Entropy') pyplot.plot(history.history['loss'], label='train') pyplot.plot(history.history['val_loss'], label='val') pyplot.legend() pyplot.show()
Если связать всё это вместе, полный пример оценки нашего первого MLP в наборе данных банкнот приведён ниже.
# fit a simple mlp model on the banknote and review learning curves from pandas import read_csv from sklearn.model_selection import train_test_split from sklearn.preprocessing import LabelEncoder from sklearn.metrics import accuracy_score from tensorflow.keras import Sequential from tensorflow.keras.layers import Dense from matplotlib import pyplot # load the dataset path = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/banknote_authentication.csv' df = read_csv(path, header=None) # split into input and output columns X, y = df.values[:, :-1], df.values[:, -1] # ensure all data are floating point values X = X.astype('float32') # encode strings to integer y = LabelEncoder().fit_transform(y) # split into train and test datasets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33) # determine the number of input features n_features = X.shape[1] # define model model = Sequential() model.add(Dense(10, activation='relu', kernel_initializer='he_normal', input_shape=(n_features,))) model.add(Dense(1, activation='sigmoid')) # compile the model model.compile(optimizer='adam', loss='binary_crossentropy') # fit the model history = model.fit(X_train, y_train, epochs=50, batch_size=32, verbose=0, validation_data=(X_test,y_test)) # predict test set yhat = model.predict_classes(X_test) # evaluate predictions score = accuracy_score(y_test, yhat) print('Accuracy: %.3f' % score) # plot learning curves pyplot.title('Learning Curves') pyplot.xlabel('Epoch') pyplot.ylabel('Cross Entropy') pyplot.plot(history.history['loss'], label='train') pyplot.plot(history.history['val_loss'], label='val') pyplot.legend() pyplot.show()
Запуск примера сначала соответствует модели в наборе обучающих данных, а затем сообщает о точности классификации в наборе тестовых данных.
Примечание: ваши результаты могут различаться из-за стохастической природы алгоритма или процедуры оценки или различий в числовой точности. Подумайте о том, чтобы запустить пример несколько раз и сравнить средние результаты.
В этом случае мы видим, что модель достигла идеальной точности в 100 % процентов. Это может означать, что задача прогнозирования проста и/или что нейронные сети хорошо подходят для этой задачи.
Accuracy: 1.000
#
Мы видим, что модель хорошо сходится и не показывает никаких признаков переобучения или неполного соответствия.

С первой попытки у нас всё получилось на удивление хорошо.
Теперь, когда у нас есть некоторое представление о динамике обучения для простой модели MLP в наборе данных, мы можем взглянуть на разработку более надёжной оценки производительности модели в наборе данных.
Оценка робастной модели
K-кратная процедура перекрёстной проверки может обеспечить более надёжную оценку производительности MLP, хотя она может быть очень медленной.
Это связано с тем, что необходимо подобрать и оценить k моделей. Это не проблема, если размер набора данных невелик, например наш набор данных.
Мы можем использовать класс StratifiedKFold и вручную пронумеровать каждую, подогнать модель, оценить её, а затем сообщить среднее значение оценок в конце процедуры.
... # prepare cross validation kfold = KFold(10) # enumerate splits scores = list() for train_ix, test_ix in kfold.split(X, y): # fit and evaluate the model... ... ... # summarize all scores print('Mean Accuracy: %.3f (%.3f)' % (mean(scores), std(scores)))
Мы можем использовать эту структуру для разработки надёжной оценки производительности модели MLP с нашей базовой конфигурацией и даже с рядом различных подготовок данных, архитектур моделей и конфигураций обучения.
Важно, чтобы мы сначала разработали понимание динамики обучения модели на наборе данных в предыдущем разделе, прежде чем использовать перекрёстную проверку в k раз для оценки производительности. Если бы мы начали настраивать модель напрямую, мы могли бы получить хорошие результаты, но если нет, мы могли бы не знать, почему, например, модель недостаточно подогнана.
Если мы снова внесём в модель большие изменения, рекомендуется вернуться назад и убедиться, что модель сходится надлежащим образом.
Полный пример этой структуры для оценки базовой модели MLP из предыдущего раздела приведён ниже.
# k-fold cross-validation of base model for the banknote dataset from numpy import mean from numpy import std from pandas import read_csv from sklearn.model_selection import StratifiedKFold from sklearn.preprocessing import LabelEncoder from sklearn.metrics import accuracy_score from tensorflow.keras import Sequential from tensorflow.keras.layers import Dense from matplotlib import pyplot # load the dataset path = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/banknote_authentication.csv' df = read_csv(path, header=None) # split into input and output columns X, y = df.values[:, :-1], df.values[:, -1] # ensure all data are floating point values X = X.astype('float32') # encode strings to integer y = LabelEncoder().fit_transform(y) # prepare cross validation kfold = StratifiedKFold(10) # enumerate splits scores = list() for train_ix, test_ix in kfold.split(X, y): # split data X_train, X_test, y_train, y_test = X[train_ix], X[test_ix], y[train_ix], y[test_ix] # determine the number of input features n_features = X.shape[1] # define model model = Sequential() model.add(Dense(10, activation='relu', kernel_initializer='he_normal', input_shape=(n_features,))) model.add(Dense(1, activation='sigmoid')) # compile the model model.compile(optimizer='adam', loss='binary_crossentropy') # fit the model model.fit(X_train, y_train, epochs=50, batch_size=32, verbose=0) # predict test set yhat = model.predict_classes(X_test) # evaluate predictions score = accuracy_score(y_test, yhat) print('>%.3f' % score) scores.append(score) # summarize all scores print('Mean Accuracy: %.3f (%.3f)' % (mean(scores), std(scores)))
Выполнение примера выводит результат о производительности модели на каждой итерации процедуры оценки и выводит среднее значение и стандартное отклонение точности классификации в конце выполнения.
Примечание: ваши результаты могут различаться из-за стохастической природы алгоритма или процедуры оценки или различий в числовой точности. Подумайте о том, чтобы запустить пример несколько раз и сравнить средний результат.
В этом случае мы видим, что модель MLP достигла средней точности около 99,9 %.
Это подтверждает наши ожидания, что конфигурация базовой модели очень хорошо работает для этого набора данных и, действительно, модель хорошо подходит для задачи, и, возможно, задача довольно тривиальна для решения.
Это удивительно (для меня), потому что я ожидал, что потребуется некоторое масштабирование данных и, возможно, преобразование мощности.
>1.000 >1.000 >1.000 >1.000 >0.993 >1.000 >1.000 >1.000 >1.000 >1.000 Mean Accuracy: 0.999 (0.002)
Затем давайте посмотрим, как мы можем подогнать окончательную модель и использовать её для прогнозов.
Окончательная модель и прогнозы
Как только мы выбираем конфигурацию модели, мы можем обучить окончательную модель на всех доступных данных и использовать её для прогнозирования новых данных.
В этом случае мы будем использовать модель с отсевом и небольшим размером в качестве нашей окончательной модели.
Мы можем подготовить данные и подогнать модель, как и раньше, но для всего набора данных, а не на обучающее подмножество.
... # split into input and output columns X, y = df.values[:, :-1], df.values[:, -1] # ensure all data are floating point values X = X.astype('float32') # encode strings to integer le = LabelEncoder() y = le.fit_transform(y) # determine the number of input features n_features = X.shape[1] # define model model = Sequential() model.add(Dense(10, activation='relu', kernel_initializer='he_normal', input_shape=(n_features,))) model.add(Dense(1, activation='sigmoid')) # compile the model model.compile(optimizer='adam', loss='binary_crossentropy')
Затем мы можем использовать эту модель для прогнозирования новых данных.
Во-первых, мы можем определить ряд новых данных.
... # define a row of new data row = [3.6216,8.6661,-2.8073,-0.44699]
Примечание: я взял эту строку из первой строки набора данных, и ожидаемая метка — "0".
Затем мы можем сделать прогноз.
... # make prediction yhat = model.predict_classes([row])
Затем инвертируем преобразование прогноза, чтобы мы могли использовать или интерпретировать результат в правильной метке (которая является просто целым числом для этого набора данных).
... # invert transform to get label for class yhat = le.inverse_transform(yhat)
И в этом случае мы просто выведем прогноз.
... # report prediction print('Predicted: %s' % (yhat[0]))
Если связать всё это вместе, полный пример подгонки окончательной модели для набора данных банкноты и её использования для прогнозирования новых данных приведён ниже.
# fit a final model and make predictions on new data for the banknote dataset from pandas import read_csv from sklearn.preprocessing import LabelEncoder from sklearn.metrics import accuracy_score from tensorflow.keras import Sequential from tensorflow.keras.layers import Dense from tensorflow.keras.layers import Dropout # load the dataset path = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/banknote_authentication.csv' df = read_csv(path, header=None) # split into input and output columns X, y = df.values[:, :-1], df.values[:, -1] # ensure all data are floating point values X = X.astype('float32') # encode strings to integer le = LabelEncoder() y = le.fit_transform(y) # determine the number of input features n_features = X.shape[1] # define model model = Sequential() model.add(Dense(10, activation='relu', kernel_initializer='he_normal', input_shape=(n_features,))) model.add(Dense(1, activation='sigmoid')) # compile the model model.compile(optimizer='adam', loss='binary_crossentropy') # fit the model model.fit(X, y, epochs=50, batch_size=32, verbose=0) # define a row of new data row = [3.6216,8.6661,-2.8073,-0.44699] # make prediction yhat = model.predict_classes([row]) # invert transform to get label for class yhat = le.inverse_transform(yhat) # report prediction print('Predicted: %s' % (yhat[0]))
Выполнение примера соответствует модели для всего набора данных и делает прогноз для одной строки новых данных.
Примечание: ваши результаты могут различаться из-за стохастической природы алгоритма или процедуры оценки или различий в числовой точности. Попробуйте запустить пример несколько раз и сравните средние результаты.
В этом случае мы видим, что модель предсказала метку «0» для входной строки.
Predicted: 0.0
Дальнейшее чтение
В этом разделе представлены дополнительные ресурсы по теме, если вы хотите углубиться в тему.
How to Develop a Neural Net for Predicting Disturbances in the Ionosphere.
TensorFlow 2 Tutorial: Get Started in Deep Learning With tf.keras.
Вывод
В этом руководстве вы узнали, как разработать модель нейронной сети многослойного персептрона для набора данных двоичной классификации банкнот.
В частности, вы узнали:
как загрузить и обобщить набор данных о банкноте и использовать результаты, чтобы предложить подготовку данных и конфигурации модели для использования;
как изучить динамику обучения простых моделей MLP в наборе данных;
как разработать надёжные оценки производительности модели, настроить производительность модели и сделать прогнозы на основе новых данных.

Узнайте, как прокачаться в других специальностях или освоить их с нуля:
Другие профессии и курсы
ПРОФЕССИИ
КУРСЫ

