

Уверена, что большинство читателей хоть немного знакомы с терминами «Unicode» и «UTF-8». Но все ли знают, что именно стоит за ними? По сути они относятся к стандартам кодирования символов, также известным как наборы символов. Концепция появилась во времена оптического телеграфа, а не в компьютерную эру, как можно было подумать. Еще в 18 веке существовала потребность в быстрой передаче информации на большие расстояния, для чего использовались так называемые телеграфные коды. Информация кодировалась с помощью оптических, электронных и других средств.
В течение сотен лет, прошедших с момента изобретения первого телеграфного кода, не было никаких реальных попыток международной стандартизации таких схем кодирования. Даже первые десятилетия эры телетайпов и домашних компьютеров мало что изменили. Несмотря на то, что EBCDIC (8-битная кодировка символов IBM, продемонстрированная на перфокарте в заглавной иллюстрации) и ASCII немного улучшили ситуацию, способа кодировать растущую коллекцию символов без значительных затрат памяти все еще не было.
Развитие Юникода началось в конце 1980-х годов, когда рост обмена цифровой информацией во всем мире сделал потребность в единой системе кодирования более насущной. В наши дни Юникод позволяет нам использовать единую схему кодирования для всего — от базового английского текста и традиционного китайского, вьетнамского, даже майянского языков до пиктограмм, которые мы привыкли называть «эмодзи».
От кода к графикам
Еще в эпоху Римской империи было хорошо известно, что быстрая передача информации имеет значение. В течение долгого времени это означало наличие гонцов на лошадях, которые доставляли сообщения на большие расстояния, или их эквивалента. Как улучшить систему доставки информации, придумали еще в 4 веке до нашей эры — так появились водяной телеграф и система сигнальных огней. Но действительно эффективной передача данные на большие расстояния стала лишь в 18 веке.
Об оптическом телеграфе, также называемом «семафоре», мы уже писали в статье об истории оптической связи. Он состоял из ряда ретрансляционных станций, каждая из которых была оборудована системой поворотных стрелок, используемой для отображения символов телеграфного кода. Система братьев Шапп, которая использовалась французскими войсками между 1795 и 1850-ми годами, была основана на деревянной перекладине с двумя подвижными концами (рычагами), каждый из которых мог перемещаться в одно из семи положений. Вместе с четырьмя позициями для перекладины семафор в теории мог обозначить 196 символов (4x7x7). На практике число сокращалось до 92-94 позиций.

Система семафоров использовалась не столько для прямого кодирования символов, сколько для обозначения определенных строк в кодовой книге. Метод подразумевал, что по нескольким кодовым сигналам можно было расшифровать все сообщение. Это ускоряло передачу и делало бессмысленным перехват сообщений.
Улучшение производительности
Затем оптический телеграф был заменен электрическим. Это означало, что времена, когда кодировки фиксировались людьми, наблюдающими за ближайшей релейной вышкой, прошли. С двумя телеграфными устройствами, соединенными металлическим проводом, инструментом для передачи информации стал электрический ток. Это изменение привело к появлению новых кодов электрического телеграфа, а код Морзе в итоге стал международным стандартом (за исключением США, которые продолжали использовать американский код Морзе за пределами радиотелеграфии) с момента его изобретения в Германии в 1848 году.
Международный код Морзе имеет преимущество перед американским аналогом: в нем используется больше тире, чем точек. Такой подход снижает скорость передачи, но улучшает прием сообщения на другом конце линии. Это было необходимо, когда длинные сообщения передавались по многокилометровым проводам операторами разного уровня подготовки.

По мере развития технологий ручной телеграф был заменен на Западе автоматическим. В нем использовался 5-битный код Бодо, а также производный от него код Мюррея (последний основывался на использовании бумажной ленты, в которой пробивались отверстия). Система Мюррея позволяла заранее подготовить ленту с сообщениями, а затем загрузить ее в устройство для чтения, чтобы сообщение передалось автоматически. Код Бодо лег в основу международного телеграфного алфавита версии 1 (ITA 1), а модифицированный код Бодо-Мюррея лег в основу ITA 2, которая использовалась вплоть до 1960-х годов.
К 1960-м годам ограничение в 5 бит на символ уже не требовалось, что привело к развитию 7-битного ASCII в США и таких стандартов, как JIS X 0201 (для японских символов катакана) в Азии. В сочетании с телетайпами, которые тогда широко использовались, это позволяло передавать довольно сложные сообщения, включающие символы верхнего и нижнего регистров.
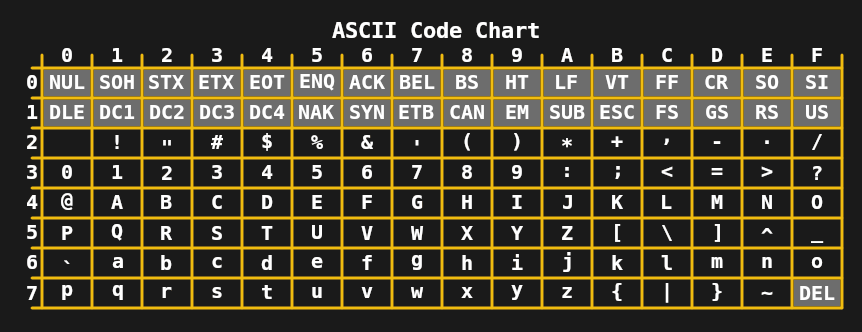
В течение 1970-х и начала 1980-х годов ограничений 7- и 8-битных кодировок, таких как расширенный ASCII (например, ISO 8859-1 или Latin 1), было достаточно для основных домашних компьютеров и офисных нужд. Несмотря на это, потребность в улучшении была очевидна, поскольку общие задачи, такие как обмен цифровыми документами и текстом, часто приводили к хаосу из-за множества кодировок ISO 8859. Первый шаг был сделан в 1991 году — появился 16-битный Unicode 1.0.
Развитие 16-битных кодировок
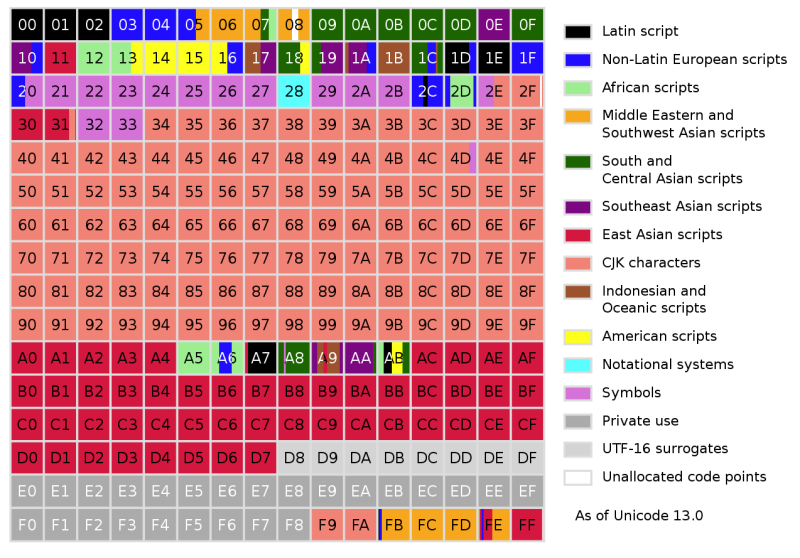
Удивительно, что всего в 16 битах Unicode удалось охватить не только все западные системы письма, но и многие китайские иероглифы и множество специальных символов, используемых, например, в математике. С 16 битами, допускающими до 65 536 кодовых точек, Unicode 1.0 легко вмещал 7 129 символов. Но к моменту появления Unicode 3.1 в 2001 году он содержал не менее 94 140 символов.
Сейчас, в своей 13 версии, Unicode содержит в общей сложности 143 859 символов, не считая управляющих. Изначально Unicode предполагалось использовать только для кодирования систем записи, которые применяются в настоящее время. Но к релизу Unicode 2.0 в 1996 году стало понятно, что эту цель следует переосмыслить, чтобы кодировать даже редкие и исторические символы. Чтобы достичь этого без обязательной 32-битной кодировки каждого символа, Unicode изменился: он позволил не только кодировать символы напрямую, но и использовать их компоненты, или графемы.
Концепция в чем-то похожа на векторные изображения, где не указывается каждый пиксель, а вместо этого описываются элементы, составляющие рисунок. В результате кодировка Unicode Transformation Format 8 (UTF-8) поддерживает 231 кодовую точку, при этом для большинства символов в текущем наборе символов Unicode обычно требуется один-два байта.
Unicode на любой вкус и цвет
На данный момент довольно много людей, вероятно, сбиты с толку из-за различных терминов, которые используются, когда дело доходит до Unicode. Поэтому здесь важно отметить, что Unicode относится к стандарту, а различные Unicode Transformation Format являются его реализациями. UCS-2 и USC-4 — это более старые 2- и 4-байтовые реализации Unicode, при этом UCS-4 идентичен UTF-32, а UCS-2 заменяем UTF-16.
UCS-2 как самая ранняя форма Unicode проникла во многие операционные системы 90-х годов, что сделало переход на UTF-16 наименее опасным вариантом. Вот почему Windows и MacOS, оконные менеджеры, такие как KDE, и среды выполнения Java и .NET используют внутреннее представление UTF-16.
UTF-32, как следует из названия, кодирует каждый символ в четырех байтах. Это немного расточительно, зато абсолютно предсказуемо. Тот же UTF-8 символ может кодировать символ в диапазоне от одного до четырех байтов. В случае с UTF-32 определение количества символов в строке — это простая арифметика: взять все количество байтов и поделить на четыре. Это привело к появлению компиляторов и некоторых языков, например Python, позволяющих использовать UTF-32 для представления строк Unicode.
Однако из всех форматов Unicode наиболее популярным на сегодняшний день является UTF-8. Этому во многом способствовала всемирная сеть Интернет, где большинство веб-сайтов обслуживают свои HTML-документы в кодировке UTF-8. Из-за компоновки различных плоскостей кодовых точек в UTF-8, Western и многие другие распространенные системы записи умещаются в пределах двух байтов. Если сравнивать со старыми кодировками ISO 8859 и Shift JIS, фактически тот же текст в UTF-8 не занимает больше места, чем раньше.
От оптических башен до интернета
Времена конных гонцов, ретрансляционных вышек и небольших телеграфных станций прошли. Коммуникационные технологии сильно развились. Даже те дни, когда телетайпы были обычным явлением в офисах, вспоминаются с трудом. Однако на каждом этапе развития истории человечеству было необходимость кодировать, хранить и передавать информацию. И это привело нас к тому, что теперь мы можем мгновенно передавать сообщение по всему миру в системе символов, которую можно декодировать независимо от того, где вы находитесь.
Для тех, кому довелось переключаться между кодировками ISO 8859 в почтовых клиентах и веб-браузерах, чтобы получить что-то, похожее на исходное текстовое сообщение, поддержка Unicode стала благословением. Я могу понять этих людей. Когда 7-битный ASCII (или EBCDIC) был безальтернативной технологией, иногда приходилось тратить часы, разбираясь в символьной путанице цифрового документа, полученного из европейского или американского офиса.
Даже если Unicode не лишен проблем, трудно не испытывать благодарности, сравнивая его с тем, что было раньше. Вот они, 30 лет существования Unicode.

