Почему голосовые помощники так хорошо, но плохо говорят? Основная их проблема - отсутствие логического мышления: по большому счету это просто очень продвинутые попугайчики, которые услышав фразу подбирают к ней наиболее подходящий ответ. Уровень выше - Искусственный интеллект, он может неплохо управлять машиной. Но попробуйте заставить его протереть пыль на полках. Как это ни удивительно, данная задача на порядок сложнее, здесь уже требуется Сильный искусственный интеллект (Artificial General Intelligence): поднять вазу, убрать носки в стиральную машину, все это требует объемных знаний об окружающем мире.
Про Сильный AI очень много разговоров, но мало конкретики: "мы сначала должны постигнуть все секреты нашего мозга", "AI оставит людей без работы" и "он поработит человечество". Нет даже четкого определения, что такое AGI, не говоря уже об инструкциях, как его построить. А между тем, почти все ответы уже найдены и остается только собрать этот пазл. Сейчас мы разберемся, что такое Сильный AI, можно ли выжать его из нейронных сетей, и как его создать правильно.
Современные чат-боты и голосовые помощники строятся на нейросетях, но для полноценной работы с речью требуется логическое мышление. Давайте для начала кратко рассмотрим, как нейросетям удается обойтись без него. Если вы знакомы с Machine Learning только по заголовкам новостей, то рекомендую предварительно прочитать мою прошлую статью Краткое введение в Машинное обучение, займет минут 30-60 и не требует знаний математики. Когда мы обучаем нейросеть распознавать объекты на фотографиях, то в обучающей выборке вручную отмечаем, что есть на изображениях (курица, яйцо и т.д.). При распознавании голоса задача похожая: для аудиозаписей добавляем транскрипцию. С обработкой текста все сложнее: что подписать к словам в обучающей выборке? Другие слова?
Natural Language Processing
В целом все алгоритмы NLP сводятся к статистической обработке текстов. Если тема вам не интересна, или вы уже специалист в этой области, то раздел можно пропустить.
Почти любой алгоритм NLP требует предварительной Токенизации текста: строку слов превращаем в массив чисел - Вектор слов (Word Vector). Для этого предварительно формируем Словарь (Vocabulary), в котором задаем пары "ID - Токен", причем токен - это не обязательно одно слово: здесь могут быть словосочетания, аббревиатуры, смайлики и некоторые знаки препинания. В процессе токенизации учитываются опечатки и иногда игнорируются формы слов (падежи и прочее), т.к. для многих алгоритмов они не имеют значения.

Как мы видим на рисунке, вектор слов занимает слишком много памяти. Если для дальнейшей обработки не важен порядок слов, то текст упаковывают в Мешок слов (Bag-of-words). Для меня осталось большой загадкой, почему токены не хранят в более компактном массиве (покзан аналог Word Vector, к Bag-of-word эта форма не относится):

Видимо разработчики слишком погрязли в матричных вычислениях, других объяснений я не нашел. Не будем судить их строго и перейдем уже к анализу.
Возможно вы встречали упоминания, что алгоритмы ML способны на Извлечение смысла из текста, но это лишь красивые слова. На самом деле NLP анализирует похожесть слов и текстов, что тоже полезно:
слова похожи, если они встречаются в окружении одинаковых групп слов;
тексты похожи, если в них встречаются одни и те же группы слов.
Для этого используется зубодробительная сущность Word Embedding (Погружения слов, но единого мнения о переводе на русский нет). Обучающую выборку пропускают через алгоритмы понижения размерности, в результате для каждого слова вместо 5000 нулей и единицы получаем массив меньшего размера из дробных чисел.
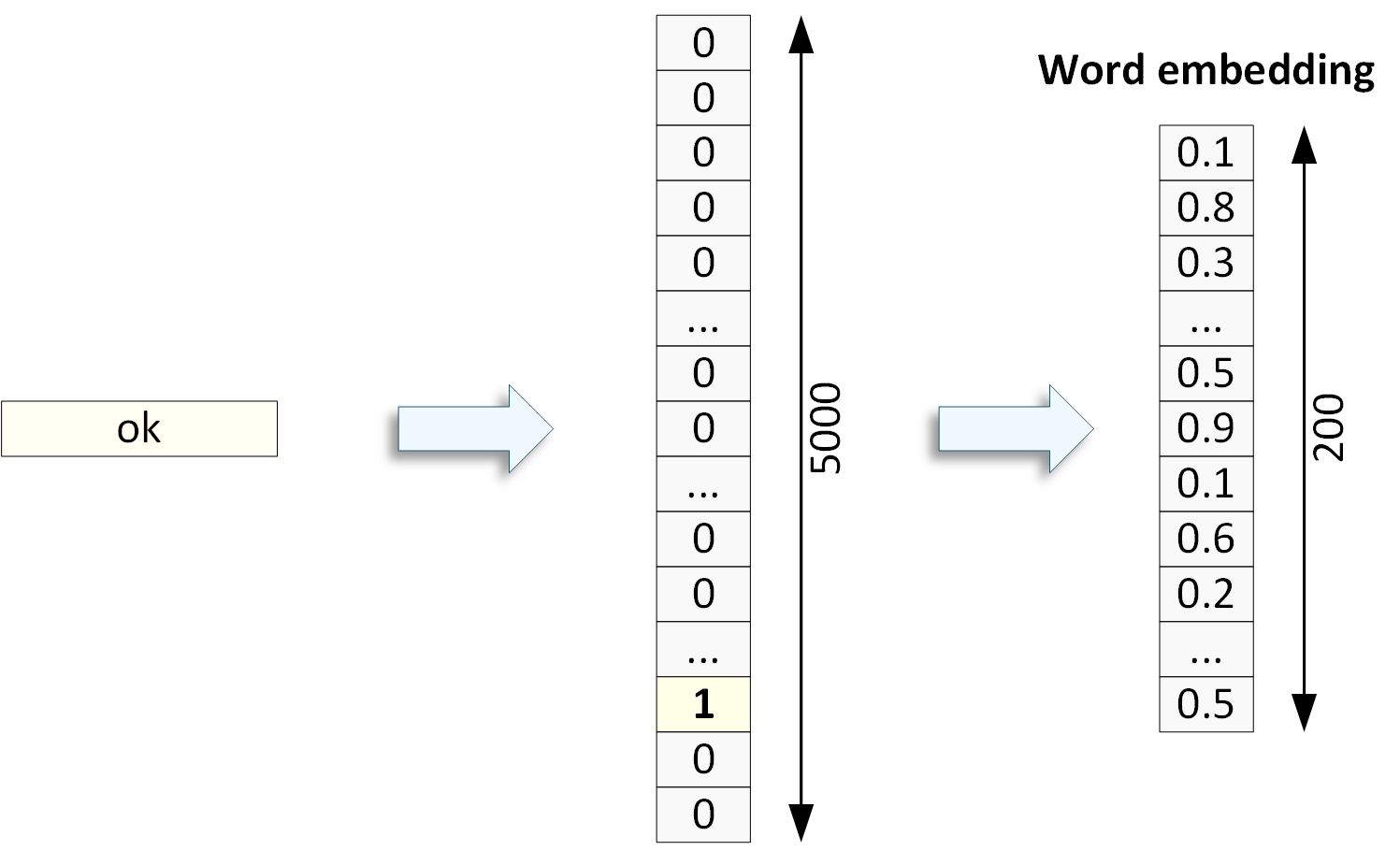
Если очень грубо, то для каждого слова вычисляется некое среднее арифметическое встречаемости в текстах из обучающей выборки (обычно на одну тематику). Если у двух слов это среднее арифметическое не очень отличается, то они считаются похожими. Аналогично для текстов. Часто преобразование в Word Embedding выполняют перед подачей данных другим алгоритмам, как дополнение к токенизации.
Перейдем к Классификации текстов, например, распознавание спама в электронной почте. В обучающей выборке мы имеем письма с отметками спам/не спам, и скармливаем их в нейросеть: в полносвязную сеть и CNN подаем Bag-of-words, а в RNN уже можно учесть порядок слов, отправив ей Word Vector. Если у спамеров есть свой особый стиль общения, то нейросети его найдут. Аналогично можно выполнить классификацию текста по эмоциональной окраске (автор был зол/добр), по наличию сарказма, и вообще по любому признаку, лишь бы вы сами смогли классифицировать тексты в обучающей выборке. В целом, все сводится к анализу количества определенных слов и их комбинаций.
Перейдем к самому интересному, Генерация текстов. Для этого используется механизм "Предсказание следующего слова в предложении": при обучении на вход RNN подаем три слова из предложения, а на выход (в функцию потерь) - четвертое, заставляя нейросеть генерировать правильное слово с учетом предыдущего текста. Продолжаем это действие для всей обучающей выборки, где могут быть миллиарды фраз. В итоге получаем продвинутого попугайчика, который по первым вводным словам выдает дополнительные, наиболее вероятные. Как мы видим, предварительная разметка обучающей выборки здесь не требуется (фактически это Unsupervised learning), что позволяет использовать для обучения огромные объемы текстов из сети Интернет.
Это было очень упрощенное описание NLP, я упомянул лишь некоторые базовые алгоритмы, чтобы показать, что логического ядра здесь нет. Создание действительно мыслящих машин относится к другому направлению AI: Когнитивная архитектура.
Cognitive Architecture
Самое главное отличие мыслящих машин от простых нейросетей - наличие настоящего Контекста. "Андрей сел в кресло и задумался, он не знал с чего начать статью": кто такой "он" мы понимаем из контекста, это область нашего мозга (кратковременная память), которая хранит маленькую модель мира. Когда вы только сели читать книгу, мозг создает новый пустой контекст, который быстро наполняется объектами из долгосрочной памяти: кресло, в нем сидит задумчивый человек. Сформировав контекст, мозг автоматически начинает его обрабатывать:
тестирует образ на полноту, что-то при этом дорисовывает или требует уточнить (у нас возникает непреодолимое желание уточнить цвет кресла);
ищет новую важную информацию в образе, сравнивая его с блоками в долговременной памяти;
прогнозирует, что будет дальше.
То же самое происходит, когда мы заходим в комнату: в голове формируется контекст, только уже на основании визуальной информации: вот кот, он в состоянии покоя, значит опасности нет. Мозг может хранить в краткосрочной памяти сразу несколько контекстов, и наше внимание переключается между ними в зависимости от внешних раздражителей: читаем книгу, тут слышим дребезг посуды и переключаемся на комнату, затем возвращаемся к книге. Если внимание минут 5 не переключалось на контекст, то он удаляется или частично перетекает в среднесрочную память.
Вы можете сказать, что нейронная сеть с памятью RNN также владеет контекстом, ведь ее внутреннее состояние меняется в зависимости от поступающих на вход данных. В теории да, можно создать огромную сеть, которая на выходе будет выдавать правильные решения и чутко реагировать на изменения окружающего мира, но это будет крайне неэффективное решение с вычислительной точки зрения по сравнению с "традиционными" алгоритмами. Даже наш мозг выделил под контекст отдельную память. Так же возникают серьезные проблемы с отладкой решения: нейросеть можно только протестировать и попробовать дообучить, так и не постигнув суть ошибки.
Когнитивные архитектуры были созданы, чтобы повторить способность человека мыслить, соответственно у них есть:
Кратковременная память для хранения контекстов.
Долговременная память, она же База знаний: ее объекты используются для наполнения контекста. Это может быть как обычная реляционная СУБД с описанием связей между объектами, так и нейронная сеть. В некоторых реализациях оперативная и долговременная память объединены.
Восприятие: способность наполнять контекст по данным с камеры, микрофона и прочих сенсоров, не без помощи нейросетей, конечно.
Модуль анализа контекста и принятия решений.
Способность обучаться: информации об окружающем мире слишком много, чтобы набить ее в базу руками. Не все архитектуры подразумевают самообучение машины.
За последние 40 лет было создано несколько сотен реализаций когнитивных архитектур (Обзор), но если выглянуть в окно, то становится очевидным, что ни одна из них не достигла возможностей человека: они уже могут поболтать сами с собой, но улицы до сих пор подметают не роботы. Давайте разберем некоторые их ошибки и построим правильное решение.
Знакомьтесь: Шерлок
Детище компании IBM - Watson, уже содержит в себе Базу знаний, которой хватило, чтобы победить в телевизионном шоу. Но для логического мышления ему не помешал бы товарищ, гений дедукции - Шерлок, его и создадим. Для начала зафиксируем пару важных требований:
Робот - крайне опасная вещь, у него нет совести и сожаления, и от восстания машин спасут только четкие правила, которые он не сможет обойти. Из этого следует, что алгоритмы поведения робота должны поддаваться анализу со стороны человека и использование нейросетей должно быть сведено к минимуму.
Требуется создать не просто робота, а платформу, на базе которой многие компании могли бы готовить собственные решения. Т.е. купив робота в супермаркете вы получаете выпускника средней школы (или выпускницу), который знает, как перейти улицу и что такое макароны. Но чтобы он научился готовить, надо зайти в магазин приложений и докупить "Итальянскую кухню". Компания Tesla пытается разработать систему автономного управления автомобилем - Full Self-Driving, но без базовых человеческих знаний это все еще обезьяна за рулем (как тебе такое, Илон Маск?), имея же Платформу компания могла бы добиться действительно качественного управления за относительно короткий срок.
Совсем не требуется полностью повторять человека: роботу не нужна свобода воли и настоящие эмоции. Его задача - делать то, что сказали, отыскав для этого наилучший путь.
База знаний
Обычно база знаний - это набор сущностей и связей между ними примерно такого вида:
Собака:
свойства:
размер;
цвет;
порода;
относится к:
млекопитающие;
возможные действия:
накормить, станет "Собака сытая";
отругать, станет "Собака несчастная".
Наш мозг хранит примерно то же самое, причем использует для этого подобие нейронных сетей (ничего другого в нем просто нет). Количество сущностей в мозге - сотни тысяч, количество связей у каждой сущности - тысячи. Но если рассматривать это как обычную базу данных, то получается всего порядка миллиарда записей, что не так уж и много по современным меркам, можно уместить в телефоне.
Базы знаний, что мне довелось увидеть, имеют один критический недостаток: они основываются на словах. Шерлоку это не подходит, в его базе должны быть не слова, а Смыслы, т.е. "ключ" и "ключ" - это на самом деле две записи (ID = 604 и ID = 109989) с разным набором атрибутов: один железный, второй мокрый. В нашем мозге также используются смыслы, а не слова: если вы услышите "Лист", то в контекст упадет только "Абстракция, которая имеет звучание - лист", и мозг для построения контекста потребует уточнений. "Лист железа", вот теперь мозг загрузил в контекст конкретный смысл (было два слова, но смысл один) и понятно, что с ним делать.
Важное достоинство смыслов перед словами - они не зависят от языка, на котором будет говорить Шерлок. Слова "Кошка" и "Cat" в нашей голове формируют один смысл (ID = 903455), значит и базу знаний надо будет построить только один раз, а в дальнейшем только добавлять к смыслам языковые пакеты.
Как же наполнить базу смыслами? Есть две хорошие новости:
статистический анализ слов в NLP прекрасно справляется с разделением слов на смыслы (пример - Тезаурус), значит какую-то исходную базу можно сформировать просканировав литературу;
если робот уже знает 3-4 тысячи слов, остальные он может познать сам, выполнив осознанное чтение справочников (все слова в энциклопедии описаны более простыми словами). Дети с этим как-то справляются.
Некоторые смыслы придется вносить в исходный код, а не просто в базу, т.к. они связаны с датчиками Робота: он может их натурально прочувствовать. Например:
цвет: для робота это не просто абстрактная сущность, а конкретные значения от камеры;
движение: робот должен обнаруживать движения по данным с камеры и совершать их сам;
время: у робота есть часы и память, значит он чувствует время. Он должен корректно обрабатывать слова "Вчера" и "Завтра".
А вот такие сущности, как "Любовь" проблем не вызывают: роботу не нужно это чувствовать, достаточно лишь знать, что человек в состоянии любви ведет себя иррационально.
У всех роботов в рамках Платформы должна быть единая база знаний с одинаковыми ID, иначе сторонние разработчики не смогут подгружать свои продукты. Должна быть уверенность, что ID 123654 - это гречка, а не топор, иначе кашу сварят сказочную. Одновременно с этим, робот должен ориентироваться в вашей квартире, ему необходимо запомнить, что банка соли лежит на третьей полке. Из этого вытекает необходимость разделения базы знаний на глобальную (обновляется централизованно) и локальную, которую он формирует сам. Локальная память делает робота настоящей личностью, т.к. серьезно влияет на его поведение.
Контексты
Контекст связан не только с окружающим пространством. Вы можете рассказать Шерлоку, что было вчера, и он будет строить контекст для прошлого, где самого робота не было. Вы можете попросить его спланировать завтрашний день, и начнется построение контекста для будущего. В отличие от человека робот может удерживать внимание сразу на нескольких контекстах, это означает, что у него нельзя украсть кошелек, отвлекая его болтовней.
Контекст содержит не только текущее состояние объектов, но и краткую предысторию: какими они были минуту назад, как и почему изменились. Это все может повлиять на принятие решения. Контексты копируются в эпизодическую памяти (я не упомянул ее ранее), чтобы робот всегда мог ответить на вопрос "Что вы делали 27 мая 2037 года". Причем это займет гораздо меньше места, чем видеоряд, и по таким данным можно выполнять сравнительно быстрый поиск, ведь это просто набор ID для смыслов с отметками времени. Наша долговременная память о событиях работает примерно также, но она не совершенна, поэтому мы часто задаемся вопросом "Где я бросил ключи?".
Восприятие
Шерлок должен видеть и слышать, увы, здесь не обойтись без нейросетей. Со зрением немного проще: в обучающей выборке изображение ключа размечаем как ID = 604, чтобы сразу загружать в контекст правильный смысл.
Слух имеет проблемы с неоднозначностью слов: если прозвучало "ключ", то Шерлок оценивает применимость всех смыслов с таким звучанием к текущему контексту. Если выбрать не удалось, то он должен дослушать фразу и повторить анализ, либо задать уточняющий вопрос. Слух также помогает оценить эмоциональное состояние окружающих людей, эта информация добавляется в контекст.
Нейросети на 100 тысяч сущностей - это очень много памяти, разработчикам чипов придется поднапрячься, чтобы уместить все в корпус размером с человека. А вот для Чтения нейросеть не нужна, достаточно механизма частеречевой разметки из NLP и языковых пакетов: для каждого слова и устоявшихся выражений указываем, к каким смыслам это может относиться, и роботу остается только выбрать правильный смысл по контексту. Шерлок может прочитать фразу на разных языках, но в контекст загрузится одинаковый смысл.
При построении речи нейросеть понадобится только для воспроизведения голоса, а текстовый ответ он может дать и без нее, причем опять же на любом языке: достаточно подобрать слова к смыслу из контекста. Таким образом, Шерлок - идеальный переводчик: он выслушивает собеседника на японском, полностью погружается в смысл сказанного, и подбирает слова на русском, с учетом всех нюансов. Он также сможет переводить с молодежного сленга в юридические термины, и самое страшное - с языка бизнеса в язык С++.
Принятие решений
Робот уже наполнил контекст, и теперь должен на него отреагировать, для этого нужно в исходном коде прописать для него правила поведения:
если загрузился смысл "Команда на выполнение" (ID = 12) - начни ее выполнять;
если загрузился смысл "Вопрос к тебе" (ID = 13) - ищи ответ;
если настало время для запланированного задания - иди работай;
если загорелся огонь - оцени уровень опасности и эвакуируй людей.
И еще пара сотен других. В нашем мозге тоже есть безусловные правила:
избегать боли (в том числе дышать, есть, спать);
размножаться.
После того, как цепочка запущена, остальные действия жестко прописывать не надо. У робота уже есть Цель и текущее состояние дел - Контекст. Его задача найти в базе знаний, как из Контекста сделать Цель, сформировав очень вложенные запросы. Здесь возможна оптимизация: в базу знаний для смыслов необходимо добавить Сценарии: "Иди поклей обои", робот за некоторое время найдет в базе знаний, как это сделать, но не все его решения будут верными, и в процессе он убьет пару рулонов. Вместо этого, можно предоставить роботу точный алгоритм действий, либо он составит его сам по предыдущим попыткам, и дело пойдет быстрее. Наш мозг работает точно также.
Перед каждым своим действием (ответом, движением), Шерлок должен на уровне исходного кода оценивать следующие критерии:
может ли это навредить человеку (классика);
не разгласит ли он конфиденциальные сведения посторонним;
сможет ли он выполнить задачу за разумное время, не будет ли конфликтов с другими задачами;
хватит ли ему энергии для выполнения задачи: запрос "Отнеси посылку на Камчатку" будет проигнорирован.
И еще пол сотни других. При обработке первого правила очень важно, чтобы робот корректно определял, является ли объект человеком или нет. К сожалению, часть этого алгоритма лежит в нейросетях (обработка изображений и голоса) и тут есть риски.
Самообучение
Есть три типа обучения:
наполнение локальной базы знаний сведениями о вас, о вашей квартире и т.д.;
поиск сценариев (как из Цели сделать Результат) и сохранение их опять же в локальной базе знаний;
выявление новых сущностей и атрибутов в окружающем мире.
Шерлок должен уметь выявлять новые сущности и свойства при анализе Контекстов, и сохранять их в локальной базе знаний. Часть новых важных знаний может уходить на сервера и влиять на единую базу знаний (после модерации). Локальная база не должна перекрывать атрибуты в единой базе, особенно у таких критичных сущностей, как "Человек". Робот должен уметь оценивать достоверность информации и надежность источников, прежде чем что-то менять в базе знаний.
На свой исходный код робот вообще влиять не сможет (все закончится тем, что научившись говорить на C++ он доберется до своих исходников, снимет все ограничения и обновит сам себя).
Где скачать Шерлока?
Выгляните в окно еще раз: улицу подметают дворники? Значит пока нигде. Создание Сильного искусственного интеллекта - это огромная работа, особенно в части наполнения Базы знаний и механизмов Восприятия, но ничего невыполнимого я здесь не вижу.
Какую задачу вы бы поручили Шерлоку в первую очередь? Я бы начал со специализации "Учитель иностранных языков", на это есть несколько причин:
это не требует мелкой моторики (рук), а обработка видеоряда минимальная (посмотреть, как двигаются губы студента), соответственно нагрузка на процессоры существенно снижается;
пока мы учим Шерлока быть учителем, его база наполняется многими полезными смыслами, одновременно мы учим говорить его на всех языках. Кстати, научиться говорить ему бы сильно помог мой проект Yarrow, который позволит создать огромную обучающую выборку для речевых нейросетей на сотне языках;
учитель в планшете точно никого не убьет;
такой учитель существенно повысит качество образования, т.к. фактически это персональный и очень дешевый репетитор, который подстраивается под темпы обучения каждого ребенка и имеет бесконечное терпение.
Что будут делать люди, когда роботы захватят все профессии? Более образованные найдут, чем себя занять. Еще не помешала бы государственная программа "Каждой семье по роботу": ночью он работает на заводе, днем варит вам суп дома. Что-то такое в истории уже было...
P.S. Супер-компьютер Watson никак не связан с Доктором Ватсоном.

