IBM представила датасет Project CodeNet, который поможет обучать системы искусственного интеллекта программированию. Компания объявила на конференции Think 2021, что ей удалось создать аналог Rosetta Stone для кодинга.
Научный сотрудник IBM Ручир Пури сравнил новый датасет с набором для обучения систем компьютерного зрения ImageNet.
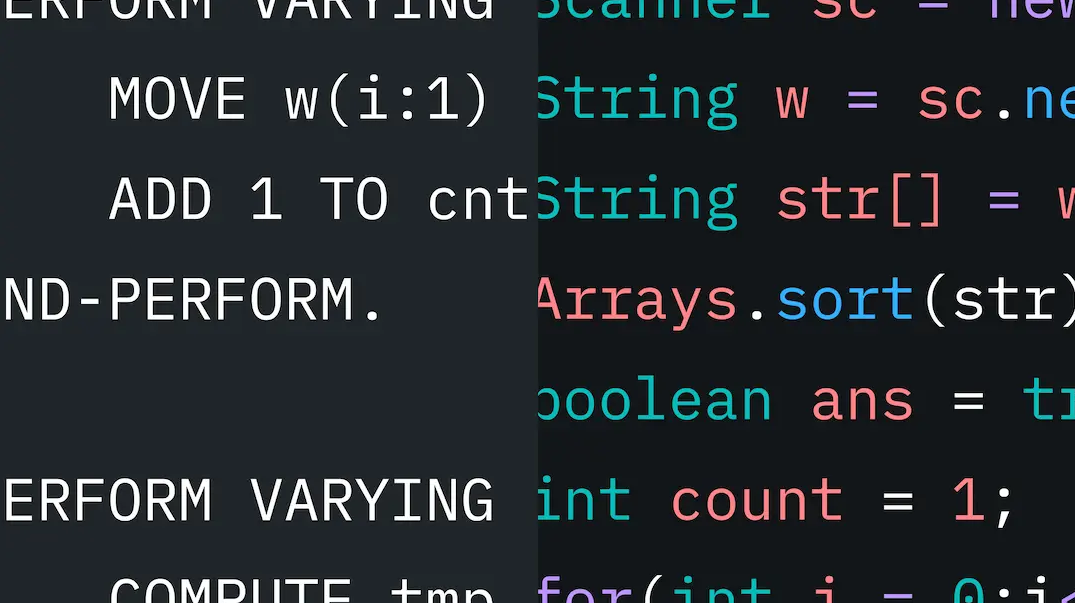
CodeNet представляет собой обширный набор данных, предназначенный для обучения систем искусственного интеллекта тому, как переводить код. Датасет включает около 14 млн фрагментов кода и 500 млн строк на 55 языках — от COBOL и FORTRAN до Java, C ++ и Python. В нем содержится около 4 тысяч задач кодирования.
По словам Пури, использование разных языков позволит задействовать системы на ИИ в парных операциях. К примеру, можно взять код на COBOL и перевести его на Java, либо наоборот.
Но, как и в случае с человеческими языками, компьютерный код создается в определенном контексте. CodeNet может использоваться для поиска фрагментов кода и обнаружения клонов, а также в качестве эталонного набора данных. Кроме того, каждый образец помечен временем работы процессора и объемом памяти, что позволяет исследователям проводить регрессионные исследования и разрабатывать системы автоматической коррекции кода.
Наконец, пользователи смогут запускать отдельные образцы кода «для извлечения метаданных и проверки правильности выходных данных генеративных моделей ИИ».
Хотя этот набор данных теоретически можно использовать для генерации совершенно новых последовательностей кода, основное достоинство CodeNet заключается в способности переводить.
IBM делает данные CodeNet общедоступными, репозиторий размещен на GitHub.

