Привет, эту статью мы пишем вместе — Дмитрий Генинг, руководитель направления разработки R&D, и Александр Желубенков, руководитель направления ранжирования и навигации в компании Lamoda.
Одна из самых важных систем, с которой мы работаем — это поиск. Ежедневно на Lamoda пользователи вводят тысячи самых разных запросов: белые ботинки, сумочка с леопардовым рисунком, очки-авиаторы и другие вещи для обновления гардероба. Наша задача — сделать поиск таким, чтобы он буквально угадывал желания пользователей и находил сразу то, что нужно.
В этой статье мы расскажем:
что находится «под капотом» поиска в Lamoda;
как мы понимаем пользователей и разбираем поисковые запросы;
как обогащаются атрибуты товаров и по какой логике формируется запрос к Elasticsearch;
над чем работаем сейчас и какие есть планы на будущее.

Особенности поиска в fashion-сегменте
Поиск — популярный инструмент, которым ежедневно пользуются сотни тысяч потенциальных покупателей. Если посмотреть, какие запросы задают наши пользователи, то самыми частотными будут бренды или связки «категория + гендер», например, «кроссовки женские».

Половина поисковых запросов — это что-то простое и популярное. Еще 20% потока составляют более специализированные запросы, например, «теплые кроссовки Reebok». А дальше — длинный хвост низкочастотных запросов, которые встречаются буквально пару раз за год. В умении искать релевантные товары именно по таким запросам и кроется основной вызов для нашего поиска. При этом для пользователя качественная выдача по редким запросам несет наибольшую ценность.
Для поисковой системы в fashion-сегменте можно выделить следующие особенности:
Простой язык запросов. Как уже было отмечено выше, у нас часто ищут конкретный бренд или категорию. Длинные запросы пользователи задают достаточно редко, например, «босоножки женские без каблука с открытым носом». Однако могут быть нетривиальные кейсы, когда пользователь делает много опечаток или вводит не совсем понятные формулировки. Например, запрос «красовки калсние» или «подушки колбасой».
Узкая предметная область. Нам нужно уметь искать товары в сфере Fashion & Lifestyle. Например, запрос «американка»: для Lamoda это может быть водолазка без рукавов или мужская куртка-бомбер. Но если задать этот запрос в Google, он выдаст другие результаты, при этом тоже релевантные. Например, «американкой» может называться резьбовое соединение или игра в бильярд.

Частично структурированное описание товаров. Все атрибуты товаров можно разделить на две группы - с фиксированным списком значений («цвет: красный» или «вид спорта: футбол») и с произвольным («спортивная футболка выполнена из тонкого технологичного трикотажа»). Фиксированные атрибуты удобны тем, что мы контролируем их значения и можем использовать это знание для поиска. Также, взаимодействуя с контент-менеджерами, мы можем управлять описанием товара (т.е. теми атрибутами, которые заполняются вручную).
Но если все так легко, то почему бы просто не искать по тем словам, которые вводят пользователи? Потому что поиск «в лоб» не будет работать в большом числе кейсов:
Синонимия. Без расширения запроса (синонимии) по запросу «штаны» будет пустая выдача, потому что этот вид товара у нас называется «брюки».
Опечатки, транслиты и переключение раскладки. Пользователи часто допускают ошибки или забывают переключить раскладку клавиатуры, поэтому мы должны учитывать самые разные варианты запросов, вроде «красовки» или «yfqr» (то есть «найк»).
Сложные паттерны. Наши клиенты иногда задают запросы типа «футболки и поло». Система должна понимать, что футболки и поло стоит искать через оператор ИЛИ, чтобы в выдаче отобразились и футболки, и поло.
Сервисные запросы. Есть отдельная группа запросов, по которым поиск товаров не требуется, а нужна полезная информация про условия доставки, возврат товара и др.
Общая логика поиска в Lamoda
Наша поисковая система состоит из набора сервисов, которые обогащают информацию о продукте и трансформируют запросы на естественном языке в AND/OR-дерево, предназначенное для запросов в Elasticsearch.
Когда пользователь приходит на Lamoda и вбивает «купить теплых кросовок», текстовый запрос анализируется и разбивается по сущностям. После этого выделенные сущности трансформируются в дерево запроса, которое определяет, какие слова и в каких атрибутах следует искать в поисковом индексе. В результате формируется фильтрующий запрос к Elasticsearch.
Далее мы подробнее разберем два модуля, в которых сосредоточена основная логика поиска — первый из них (search-query-analyzer) отвечает за понимание и разбор запроса, а второй (search-enricher) отвечает за логику индексации товара, то есть за обработку товара, прежде чем тот попадает в индекс.
Анализатор запросов search-query-analyzer
Чтобы понимать пользователя, нужно уметь разбирать запросы, сформулированные на естественном языке, и выделять из них смысл — то есть сущности (категорию, бренд, цвет и другие параметры). Переход от слов к сущностям позволяет эффективнее настраивать синонимию, анализировать структуру потока запросов на качественном уровне, а также управлять тем, в каких атрибутах товаров следует вести поиск.
Внутри сервис состоит из 4-х этапов: токенизация, выделение сущностей, построение дерева сущностей и дерева атрибутов.

Этап 1. Токенизация. На этом этапе устраняются разного рода ошибки: переключается раскладка, исправляются опечатки и разделяются слова, если пользователь забыл поставить пробел между ними. Для исправления частотных опечаток используется словарь. Для остальных случаев — кастомный спелл-корректор на основе машинного обучения. Если модель уверена, что была сделана опечатка, она исправляет введенное пользователем слово. А если нет, то слово остается в оригинальном виде.
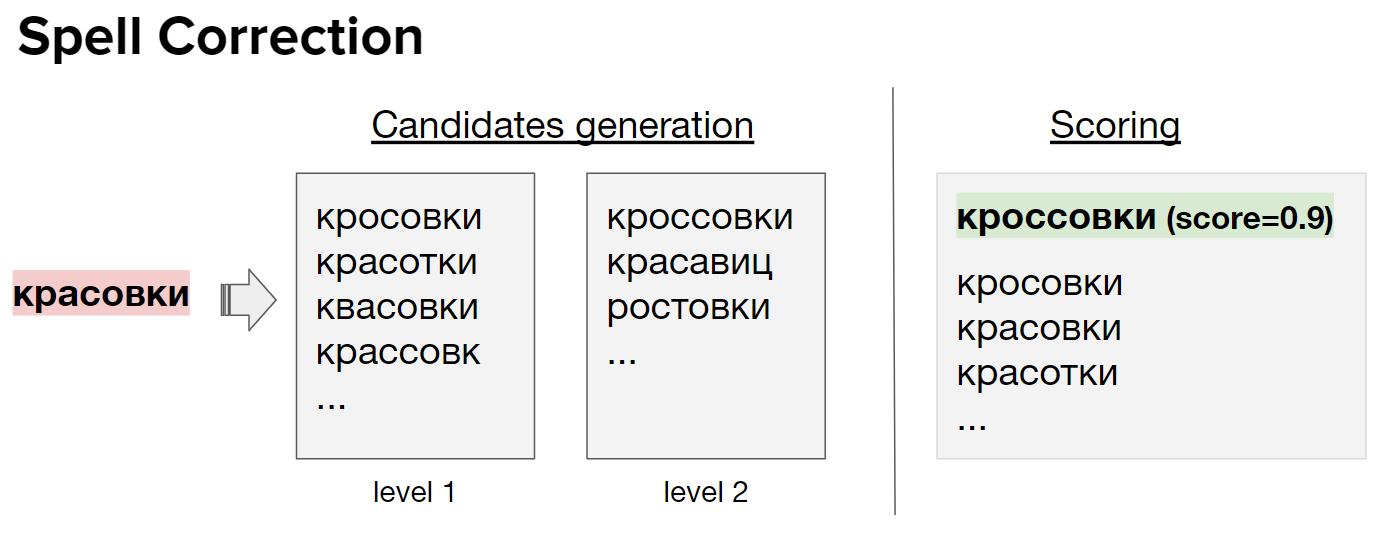
Этап 2. Выделение сущностей. После исправления раскладки и опечаток выполняется этап выделения сущностей. Для этого токены с предыдущего этапа нормализуются: «кроссовок» трансформируется в «кроссовки», «теплых» в «теплый».
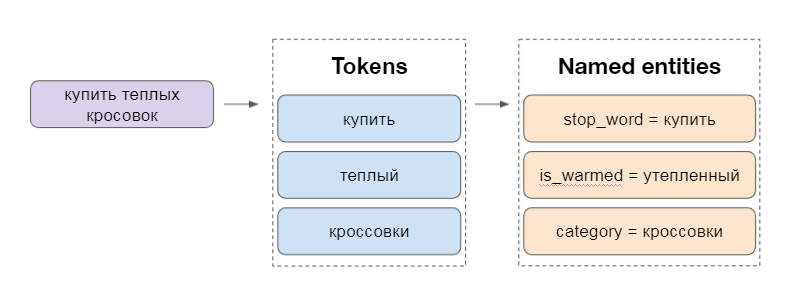
Далее по нормализованным токенам решается задача NER (выделения именованных сущностей), для которой используется словарный подход и поиск с учетом различных вариантов транслитерации. Система умеет выделять несколько десятков типов сущностей. Наиболее популярные — категория, бренд, гендер и цвет.
В нашем примере «купить теплых кроссовок» слово «купить» отмечается как незначимое. Из слова «теплый» выделяется сущность «утепленный», связанная с температурным режимом. И, наконец, «кроссовки» определяются как категория товаров.
На основании выделенных сущностей можно настраивать синонимию, а также управлять тем, в каких атрибутах товаров стоит искать те или иные сущности на следующих этапах.
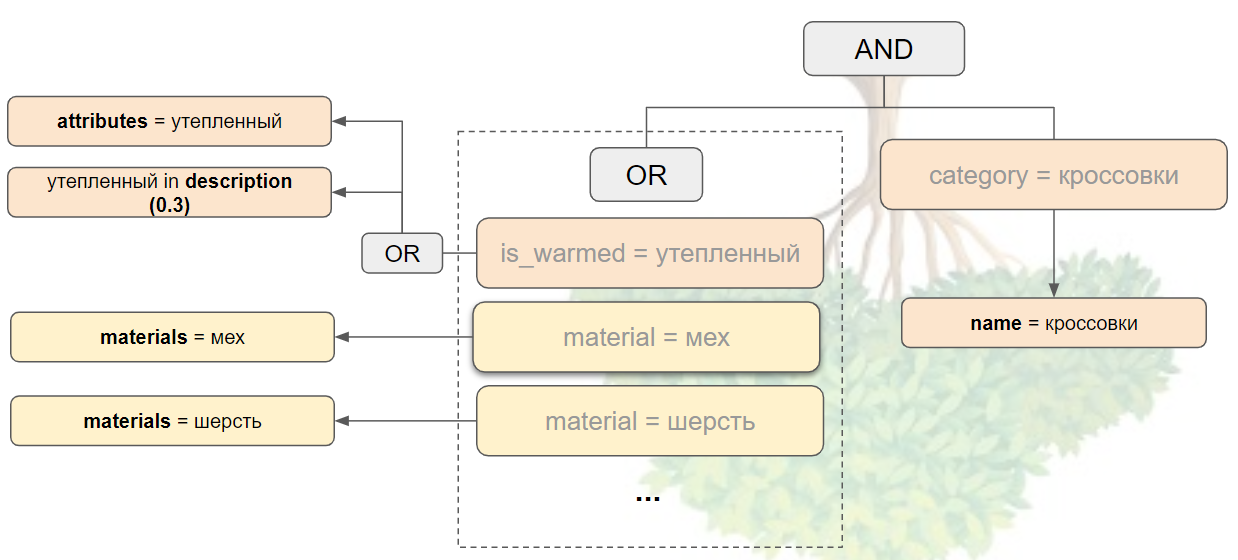
Этап 3. Синонимия и дерево сущностей. Теперь самое время расширить запрос. Для этого используется внутренняя онтология (база знаний), покрывающая предметную область с учетом фэшн-сленга. Сущность «утепленный» через односторонние синонимы расширяется сущностями «с мехом», «с шерстью» и другими теплыми материалами. После этого строится AND/OR-дерево, в котором закладывается основная логика поиска: система должна найти все слова запроса напрямую или через синонимию. В итоге в выдачу попадут товары, которые релевантны как левой части дерева (ветвь от слова «теплый»), так и правой части (ветвь от слова «кроссовки»).

Этап 4. Дерево атрибутов. Каждая вершина дерева сущностей превращается в одну или несколько вершин дерева атрибутов. Для этой трансформации используется отдельный маппинг. В нем также могут быть указаны веса, отвечающие за уровень доверия к тому или иному атрибуту. Эти веса будут влиять на итоговую релевантность товара запросу.
В результате исходный запрос «купить теплых кроссовок» превращается в дерево, которое указывает, что слово «утепленный» следует искать в атрибутах и описании товара, «мех» — в материалах, а слово «кроссовки» — в названии товаров.
Индексация и поиск товаров в Elasticsearch
Теперь поговорим о том, как обогащаются атрибуты товаров и по какой логике формируется запрос к Elasticsearch.
Для корректной работы поиска нужно не только уметь разбирать поисковый запрос, но и правильно индексировать товары. У каждого товара есть исходные атрибуты, которые заполняются вручную контент-менеджерами или приходят от поставщика. Перед индексацией исходные атрибуты трансформируются и обогащаются новыми, вычисленными на основе правил. Это происходит в сервисе search-enricher.
В search-enricher есть набор шаблонов, который поддерживается в актуальном состоянии и обновляется в процессе работы над улучшением качества поиска. Шаблоны описывают, какие поля могут использоваться для поиска, а также логику формирования обогащенных атрибутов. Например, если известна высота каблука в сантиметрах, то исходя из этого определяется, является ли каблук высоким, низким или средним.
Для описания товара используется два типа атрибутов.
Keyword-атрибуты нужны для поиска по точному совпадению. Например, так формируется атрибут is_warmed.
IF material_filler is not empty AND ["нет утеплителя", "без утеплителя"] not in material_filler THEN {"key": "is_warmed", "value": "утепленный"}
Как понять, что товар утепленный? Можно посмотреть на исходное поле material_filler, в котором обычно содержится информация о наличии или отсутствии утеплителя. Если там есть какие-то значения, и они не содержат слов «нет утеплителя» и «без утеплителя», можно сделать вывод, что товар утепленный.
Text-атрибуты нужны для полнотекстового поиска. Перед записью в индекс исходные значения текстовых атрибутов нормализуются — слова приводятся к нормальным формам, используя библиотеку pymorphy2.

В итоге сервис search-enricher, получая на входе товар и его исходные атрибуты, на выходе формирует список полей для индексации в Elasticsearch.

Вернемся к поиску товаров. Нужно понять, как дерево атрибутов, которое получилось на финальном этапе обработки запроса пользователя, трансформировать в запрос к Elasticsearch, чтобы найти релевантные товары.
Оказывается, AND/OR-дерево хорошо ложится на DSL (язык запросов) Elasticsearch. Промежуточные вершины естественным образом могут быть представлены через Boolean Query и must/should-операторы.
Листья дерева, указывающие, в каком атрибуте следует искать конкретное слово, трансформируются в Term Query и Match Query для поиска по точному совпадению и полнотекстового поиска соответственно.
А чтобы учесть в итоговой релевантности различные веса атрибутов, листья оборачиваются в constant_score с фиксированным boost, в котором как раз и закладывается нужный вес.

На выходе из Elasticsearch отдаются товары, удовлетворяющие фильтру. И дополнительно для каждого товара вычисляется его релевантность — число от 0 до 1, которое зависит от того, в каких полях товара были найдены слова запроса.
Например, слово «утепленный»(в белых кроссовках) было найдено только в текстовом поле «описание», поэтому этот товар получает неполную релевантность 0,3. В то же время кроссовки с мехом получают максимальную релевантность равную 1.
Помимо релевантности товара запросу, в сортировке поисковой выдачи учитываются и другие факторы. Итоговое ранжирование строится на основании прогноза ML-модели, в которой также используются продажи и исторические конверсии товара, доступность размерной сетки и цена.
Про использование машинного обучения в ранжировании мы планируем рассказать в отдельной статье.
Над чем работаем сейчас
Развитие поисковой системы важно для Lamoda. Успешные A/B-эксперименты подтверждают, что мы не только помогаем пользователям находить товары их мечты, но и позитивно влияем на показатели бизнеса.
Из наших текущих проектов можно выделить три направления.
Использование поведенческих данных в поиске. Мы можем настраивать интересные связи на уровне синонимии. Например, указать, что тельняшки синонимичны полосатым кофтам. Однако это будет не очень верно: ведь не каждая кофта в полоску подойдет под определение тельняшки. За счет использования явного сигнала о том, какие товары пользователь чаще кликает по конкретному запросу, можно управлять балансом между точностью и полнотой поисковой выдачи, а также улучшать качество ранжирования.

Улучшение рекомендаций на пустой поисковой выдаче. По некоторым запросам поисковой системе не удается найти ни одного товара, целиком удовлетворяющего запросу, поэтому пользователь попадает на страницу пустой выдачи. Причины могут быть разные — фактическое отсутствие релевантного товара (например, если пользователь ищет бренд или категорию товаров, которые мы не продаем) или релевантные товары есть, но на основании атрибутов и синонимии найти их не получилось.
На пустой поисковой выдаче мы должны предложить пользователю полезные варианты для продолжения сценария. В нашем случае для этого используются рекомендации альтернативных запросов и товаров. На текущий момент эти рекомендации базируются на частотном подходе, основанном на кликах и покупках других пользователей, которые в прошлом уже задавали такой же или похожий запрос. За счет подключения машинного обучения и подходов, основанных на векторных представлениях запросов и товаров, можно улучшать рекомендации и обеспечивать хорошее покрытие для низкочастотных запросов.

Выделение атрибутов по фото. Бо́льшая часть товаров проходит через наших контент-менеджеров. Но есть группы товаров, атрибуты которых заполняет сам поставщик, и у таких товаров некоторые важные атрибуты могут быть не заполнены. Однако, у нас всегда есть фото товара, а технологии computer vision позволяют автоматически заполнять пропущенные атрибуты по одной или нескольким фото. Помимо этого, появляется возможность добавлять новые атрибуты без привлечения дополнительных ресурсов со стороны контент-менеджеров.
Выделение атрибутов по фото хорошо ложится в логику search-enricher и позволит обогащать товар прогнозными атрибутами, за счет которых выдачи по различным поисковым запросам станут лучше.
Подытожим все то, о чем мы говорили:
Поиск в Lamoda — популярный инструмент, которым ежедневно пользуются сотни тысяч пользователей.
Особенности поиска в fashion-сегменте: простой язык запросов, короткие описания товаров и узкая предметная область.
Основу нашей поисковой системы составляют два модуля: первый умеет расширять пользовательский запрос и трансформировать его в фильтрующий запрос к Elasticsearch, а второй отвечает за логику индексации товаров.
Развитие поисковой системы важно для Lamoda, ведь помогая пользователям находить товары их мечты, мы позитивно влияем на показатели бизнеса.

