
Как при распараллеливании кода не мучиться из-за блокировок? На Хабре уже писали о транзакционной памяти, но когда о ней говорит Морис Херлихи, это особый случай. В 1993-м и Хабра никакого не было, и многоядерные процессоры ещё не заявили о себе — а Морис уже стал соавтором основополагающей работы о транзакционной памяти. Так что он главный в мире авторитет по этому вопросу, и если вам нужно введение в тему, логично слушать его.
В прошлом году на нашей конференции Hydra он выступил с докладом для широкой публики, где всё начинается с самых азов и затем доходит до менее очевидных вещей. Сейчас мы ждём его на Hydra 2021 с новым докладом — а в ожидании этого решили сделать для Хабра текстовый перевод прошлогоднего выступления на русский (видеозапись тоже прилагаем). Далее повествование будет от лица спикера.
Содержание
Закон Мура
Все знают, что невозможно выступить с докладом по computer science, не упомянув закон Мура хотя бы один раз. Поэтому я отделаюсь от этой обязанности на первом же слайде.

Вы и сами наверняка знаете, но не будет лишним повторить. В соответствии с этим законом транзисторы становились всё меньше. Долгое время это также означало, что тактовая частота процессора возрастает, но эти времена прошли. Транзисторы продолжают уменьшаться, на одном квадратном миллиметре можно разместить всё больше (хотя и этому может прийти конец), но тактовая частота не увеличивается.
Причина проста: когда транзисторы становятся слишком малы, они перегреваются. И больше нельзя просто ускорить ваш ноутбук без того, чтобы он загорелся.
Поэтому вместо ускорения процессоров инженеры стали делать их всё более многоядерными. Так вы ежегодно получаете примерно ту же тактовую частоту, зато у вас увеличивается количество потоков, с которыми вы можете работать.
Когда-то давно всё компьютерах всё было просто: одноядерный CPU и память (такая система называется uniprocessor). Сейчас таких архитектур практически не осталось, потому что стало выгоднее использовать множество процессоров в микросхему.
После изобретения многопоточности появились многопроцессорные системы с разделяемой памятью (shared-memory multiprocessor):

Сейчас это тоже вымирающий вид.
А сегодня популярны многоядерные процессоры, иногда их называют CMP (chip multiprocessor). И это означает, что кэш процессора (по крайней мере, часть памяти, коммуникационная среда), размещается целиком на одном кусочке кремния (кристалла).
Так в реальности выглядит довольно небольшой старомодный многоядерный процессор:

Каждый из этих прямоугольников — это процессор, всё остальное — это кэши и память. Все процессоры и память расположены на одной микросхеме.
И это имеет значение для софта, что важно для нас, поскольку доклад не столько о железе, сколько о программировании.
В стародавние времена, когда некоторые из вас ещё и не родились, софт получал «ускорение на халяву». Можно было не менять код, а ваш однопроцессорный компьютер начинал работать всё быстрее:

На слайде процессор становится больше, чтобы показать увеличение производительности. Вообще-то они становились меньше, но думаю, вы это и так понимаете.
В идеальном мире каждый год и ваша программа, и компьютеры становились бы всё более многопоточными, и ваш код продолжал бы так же ускоряться:

Но, конечно, жизнь не так проста.
В реальности так не происходит по ряду причин. И на самом деле всё выглядит примерно так:

Мы пишем программы, делаем их параллельными и многопоточными, добавляем потоки (threads), блокировки (locks), синхронизацию. И хотя железо выглядит всё более мощным и параллельным, ПО не может за ним поспеть. Блокировки вызывают борьбу за ресурсы и разные другие проблемы.
Это приводит нас к очевидному, но ценному наблюдению: использовать параллелизм тяжело, для этого нужны компетентность и глубокое осмысление вопроса. Не то что в старые добрые времена, когда вы могли написать программу и расслабиться, потому что увеличение тактовой частоты само ускорило бы программу.
Закон Амдала
После закона Мура был закон Амдала, указывающий, как думать о параллелизме. Конечно, этот закон — идеализация и абстракция, он не учитывает много нюансов, поэтому не стоит воспринимать его слишком буквально. Но он подсказывает, как подходить к масштабированию ПО путём увеличения параллелизма.
Определим ускорение программы от параллелизма как соотношение количества времени, которое потребуется для её исполнения на одном процессоре, и времени, за которое та же самая программа будет выполняться на n-поточной машине:

При увеличении n нам хотелось бы, чтобы скорость исполнения становилась как можно выше, и нам важно, во сколько раз всё ускорилось.
В итоге закон Амдала выглядит так:

Здесь p — это та часть вашего кода, которая может выполняться параллельно. Например, если ваш код полностью последователен, то p равно нулю. Тогда по закону Амдала ускорение равно единице (программа «ускорилась в один раз», то есть не ускорилась вообще), и вы зря тратите деньги на многоядерный процессор.
А если p равно 1, то код полностью параллельный. И сколько ядер будет, во столько раз он и ускорится.
Но это крайние случаи, а в большинстве интересующих нас приложений p находится где-то между 0 и 1.
Давайте посмотрим, что говорит нам это уравнение. Когда мы берём параллелизируемую часть программы p и делим на количество потоков n, это время выполнения этой части. А «1 – p» — это та последовательная часть, которая не может быть ускорена.
В этом уравнении ваше ускорение представлено в идеализированном виде: в реальной жизни существуют и другие аспекты, влияющие на скорость вашей программы (например, локальность кэша). Но это довольно неплохое приближение для наших целей.
Если отвлечься от математики, моё любимое объяснение значимости закона Амдала выглядит так:

На практике закон Амдала гласит, что небольшой фрагмент плохой синхронизации сломает всё. Если вы хотите использовать современное многоядерное аппаратное обеспечение, вам нужно очень хорошо подумать над синхронизацией, потому что именно она контролирует, насколько хорошо ваше приложение будет масштабироваться в современном мире.
Пример
Представим, что вы покупаете 10-ядерную машину. А ваше приложение на 60% параллельное и на 40% — последовательное. Иными словами, 60% вашего приложения могут быть распределены между разными ядрами, а 40% приходятся на части, которые нельзя так ускорить — скажем, на UI и обращение к диску.
Когда вы сказали начальнику, что хотите купить 10-ядерный компьютер, он сказал: «Надеюсь, мы получим десятикратное ускорение нашего приложения». Насколько это возможно с 60% параллельности и 40% последовательности? Какое ускорение вы получите по закону Амдала?

Ответ: вы получите ускорение в 2.17 раз. Итак, у вас стало 10 процессоров, но ускорилось всё только в два раза. Как-то не очень воодушевляет. Поэтому вы попросили своих программистов задерживаться после работы и работать без выходных, чтобы сократить последовательную часть и увеличить многопоточную.
Была проделана большая работа, и в программе стало 80% многопоточности. Вы запускаете программу, чтобы посмотреть, насколько вы приблизились к десятикратному ускорению. И теперь это 3,57. Итак, вы очень усердно работали, ваш код многопоточен на 80%, но вы получили ускорение всего лишь в 3,5 раза. Опять же, мы живём в очень суровом мире.
Вы снова принимаетесь за работу, работаете ещё усерднее и добиваетесь 90% многопоточности в своём коде. И получаете ускорение в 5,26 раза. То есть у вас 10 процессоров, но вы получаете эффект, как от пяти.
Если вы хотите получить ускорение, которое хоть немного похоже на рост числа процессоров у вашего железа, понадобится сделать своё приложение на 99% параллельным и на 1% последовательным. Так вы ускоритесь в 9.17 раз и приблизитесь-таки к десятикратному ускорению.
То есть закон Амдала гласит, что вы не можете просто написать код старым добрым способом, а потом ожидать улучшений от железа. Если ваш код слишком последовательный, то не важно, насколько усердно будут работать инженеры Intel и остальные, потому что вы не сможете в полной мере воспользоваться результатами их труда.
Сегодня я хочу поговорить не о том, как взять и разбить программу на параллельные части, а как взять части, которые сложно сделать многопоточными, и всё же сделать их такими. Мы только что увидели, что это может очень сильно повлиять на ускорение и масштабируемость.
Очевидная аналогия — шарикоподшипники в велосипеде. Вы можете пойти и купить итальянский гоночный велосипед со сложными деталями, но самая важная из них — шарикоподшипники, то есть места, где детали должны двигаться вместе. И многопоточность — это такие шарикоподшипники ПО: если эта часть сделана плохо, то всё остальное не особенно имеет значение.
Варианты блокировок
Давайте поговорим о разных способах подходить к синхронизации. Традиционный способ следующий: если у вас есть структура данных, к которой обращается множество ядер, вы ставите на неё блокировку — это как задвижка в туалете. Она гарантирует нам, что только один поток сможет работать с объектом в определённый момент времени. Потому что если будут работать сразу два, не будучи синхронизированными, могут возникнуть ошибки.
Грубая блокировка (coarse-grained locking)
Грубая блокировка — это установка одной блокировки сразу на всю структуру данных. Преимущество в том, что это относительно легко сделать правильно. Если вы поставите одну большую блокировку на всю свою систему файлов, на всю базу данных, то сведёте проблему к последовательному программированию. И хотя последовательное программирование тоже непростое, мы хотя бы знаем, как оно делается.

Однако у него очень плохая производительность.
Если у вас когда-либо были в доме маленькие дети, вы знаете, что рано или поздно они доберутся до уборной и закроют там сами себя, и потребуется много времени, чтобы вызволить их оттуда.
Возникает вопрос: «Если у нас сложная структура данных, почему бы не блокировать только те её части, которые нужны в текущий момент?»
Мелкоструктурная блокировка (fine-grained locking)
Очевидное решение — использовать мелкоструктурную блокировку, то есть размещать блокировки на каждом кусочке структуры данных. По мере прохождения этой структуры вы устанавливаете блокировку где необходимо, а когда заканчиваете работу на этом промежутке, снимаете её. Так ваши потоки смогут использовать одну структуру данных одновременно.

Однако здесь свой недостаток: бывает сложно написать структуру данных, используя мелкоструктурную блокировку. Можно писать целые исследования о том, как это делать. А если о чём-то можно писать исследования, значит, это не самая удачная инженерная техника!
Помимо этого, у блокировок в целом есть и другие проблемы.
Проблемы блокировок
Блокировки не отказоустойчивы
Если в одном потоке была установлена блокировка, а затем произошёл отказ, то блокировка останется, и никто больше не сможет воспользоваться структурой данных.
С этим можно бороться. Люди разработали очень сложные и изощрённые способы сказать: «На случай, если вы устанавливаете блокировку и не снимаете её, есть аварийный способ очистки». Но эти штуки обычно не очень хорошо работают, они сложные и медленные.
Если поток, поставивший блокировку, задерживается, то застопорится и всё остальное. Так что эти подходы крайне ненадёжны.
Блокировки конвенциональны
Есть ещё одна проблема с блокировками, о которой не очень много говорят, но я считаю её очень серьёзной. Дело в том, что блокировки опираются на конвенции, договорённости. По большей части программисты вынуждены следовать протоколам и конвенциям, приходя к соглашениям, чтобы корректно использовать блокировки. Пример такой конвенции — отношение между данными блокировки и данными объекта. Блокировка — это просто бит или байт в памяти, а объект может быть сложной структурой данных в виде связанного списка или частью сложной структуры данных. Отношение между ними существует только в голове у программиста.
В языках программирования появилось множество механизмов для связывания блокировок с объектами: обработчики событий и другие. Но они никогда не были очень удачными для очень сложных блокировок. В качестве наглядного примера — комментарий из ядра Linux:
«When a locked buffer is visible to the I/O layer BH_Launder is set. This means before unlocking we must clear BH_Launder,mb() on alpha and then clear BH_Lock, so no reader can see BH_Launder set on an unlocked buffer and then risk to deadlock».
Я сам не очень понимаю, что этот комментарий значит. Если бы я работал над проектом, где мне нужно было правильно использовать именно этот синхронизированный буфер, я был бы очень обеспокоен, потому что не знаю, кто написал это, не совсем точно понимаю, что это значит, не знаю, применимо ли это сейчас. Но в целом в сложных системах блокировки работают именно так: программисты оставляют комментарии (примерно как граффити), поясняя, как что-либо использовать. Если этого не делать, то случится что-то плохое. Но зачастую что-то плохое случится в любом случае.
Блокировки усложняют простые задачи
Эту проблему трудно определить формально, но при встрече с ней сразу всё понимаешь.
Приведу пример простой задачи, которую сможет понять и старшеклассник. Допустим, у нас есть двухсторонняя очередь (double-ended queue): элементы можно добавлять и убирать с обеих сторон. Поэтому один поток может добавлять элемент с одной стороны, в то время как другой добавляет с противоположной. Ваша задача — обеспечить здесь синхронизацию на основе блокировки (lock-based synchronization).

Если концы очереди далеко друг от друга, то можно работать на обоих сразу без взаимных помех и без необходимости координировать действия, потому что они не влияют друг на друга. Однако если очередь короткая (например, в ней только один элемент), и мы с вами пытаемся работать с ней одновременно, нужна синхронизация.
Получается, что требующийся вид синхронизации зависит от состояния очереди. И это простая задача, которую легко объяснить, но довольно сложно решить.
Если у вас возникнет идея нового подхода к ней, вероятно, результаты можно будет представить на академической конференции. Потому что, насколько мне известно, первое техническое решение этой задачи было опубликовано Магедом Майклом и Майклом Скоттом на конференции PODC в 1996 году. И мне кажется, у дисциплины есть проблема, когда такая простая задача на самом деле так сложна, что её решение достойно публикации.
Наши друзья математики обожают подобные вещи. Среди них много теоретиков, которые выдвигают довольно простые гипотезы, которые потом веками пытаются доказать. Но дисциплина computer science должна быть инженерной: мы должны решать задачи, а не превозносить нерешённые.
Блокировки не компонуются
Первое, что вы узнаете, как программисты, — вам не нужно писать свои собственные процедуры синуса и косинуса, потому что существуют библиотеки. В любой момент, когда мне нужно вычислить синус угла, я могу вызвать библиотеку, которая даст мне верный ответ. Мне не нужно знать, как она работает: я вызываю библиотеку, она написана экспертами, и мне не нужно об этом думать.
С блокировками ситуация гораздо хуже. Вот, например, у меня есть поток, который хочет переместить что-то из одной очереди в другую:

Я должен убедиться в том, что это перемещение атомарное, то есть никакой другой поток не видит две копии перемещаемого элемента или пропущенный элемент. Каждый наблюдатель видит, что элемент находится либо в одной, либо в другой очереди. Как нам это сделать с блокировкой?
Очевидный способ это сделать: заблокировать очередь-источник, потом заблокировать очередь-адресат, совершить перемещение и затем снять блокировку. Так работает, например, двухфазная блокировка в базах данных.
Но давайте подумаем, каковы последствия такого решения для структуры ПО.
Методы постановки в очередь и удаления из очереди не могут обеспечить внутреннюю синхронизацию. Вы не сможете в Java сделать это synchronized-методом, потому что метод поставит блокировку, произведёт операцию и снимет блокировку, но единственный способ осуществить атомарное перемещение — это удерживать блокировку, пока производится перемещение.
Это значит, что единственный способ скомпоновать эти очереди — это сделать так, чтобы объекты предоставляли свои протоколы блокировки клиенту. Ваша FIFO-очередь должна иметь операции блокировки и разблокировки, которые могут быть вызваны клиентами.
Но это значит, что вы должны доверять вашим клиентам разрабатывать протоколы и следовать им. Если вы делаете синхронизацию внутри своего метода, тогда вы можете гарантировать, что ваш метод корректен. Но если вы говорите: «Вот очередь, которая работает корректно, только если ваши клиенты следуют протоколу», — то это очень нехорошая ситуация с точки зрения программной инженерии. Она означает, что вы должны доверять всем, а если кто-то поведёт себя неправильно, то даже если вы всё сделали правильно, можете пострадать.
Паттерн «Monitor wait and signal» не компонуется
Ещё одна распространённая проблема связана с паттерном «Monitor wait and signal». У нас есть поток, который ожидает задание, например, от буфера сообщений. Буфер пуст, так что процесс говорит: «Мне нет смысла тратить ресурсы, когда делать нечего. Я буду спать, а ты сообщи мне, когда что-нибудь появится». Когда в буфере появляется элемент, мы можем разбудить поток, и он начнёт потреблять данные.
Меня беспокоит, что этот паттерн не компонуется.
Представим, что поток готов ждать, когда что-нибудь появится в одном из двух буферов. Он говорит: «Хорошо, первый буфер пуст, я проверю второй буфер. Второй тоже пуст, так что я засну и буду ждать сигнала от одного из буферов».

Проблема в том, что это невозможно написать, используя классические мониторы. Если вы используете класс Java, то если уж вы установили монитор блокировки, вы видите, что буфер пуст, вы должны заснуть внутри монитора, вы не можете уснуть в одном мониторе и при этом быть активным в другом мониторе. Так что даже очень простые формы компоновки не работают в классических конструкциях синхронизации.
Это было нормально во времена Дейкстры, когда люди сталкивались с простыми проблемами, но это не лучший способ проектировать современное масштабируемое ПО. Так что я предложу альтернативу этой классической форме синхронизации, которую я буду называть «Транзакционный манифест».
Транзакционный манифест

Многие современные практики программирования не подходят для многоядерного мира. Поэтому я предлагаю альтернативу, сосредоточенную на атомарных транзакциях.
Это не новая идея. В IT известно, что почти все важные идеи и системы появились в мире баз данных. Но люди из этого мира говорят на своём языке, ходят на свои конференции и мало общаются с теми, кто занимается языками программирования и распределёнными системами. Значит, если украсть у них идею, то никто не заметит и все решат, что вы это придумали! И я решил украсть у них идею атомарных транзакций (не рассказывайте им). Посмотрим, насколько далеко это может завести.
Общий план таков:
Заменим блокировки на атомарные транзакции
Поговорим о разработке языков и библиотек
Внедрим эффективные реализации
Но в этом докладе мне не хватит времени на все эти темы. Придётся сконцентрироваться на более узкой повестке:
Транзакции против блокировок
Аппаратная транзакционная память
Использование транзакционной памяти
Объединение транзакций с блокировками
Открытые для исследования вопросы
Транзакции против блокировок
Для нас транзакция — это просто блок кода, который осуществляется атомарно. То есть это выглядит так, будто всё в этом блоке происходит мгновенно: тот, кто будет наблюдать за состоянием мира снаружи программы, увидит состояния до и после, но никогда не увидит промежуточное состояние.
Если сформулировать это свойство другими словами, это сериализуемый код. То есть кажется, что в этом коде всё происходит по порядку, одно действие за раз. Это очень воодушевляет людей из сферы баз данных. Если вы хотите порассуждать о правильности ваших транзакций, вам не нужно беспокоиться о том, что они могут как-то перемежаться, потому что они совершаются по порядку, одно действие за раз.
Зачастую транзакции производятся спекулятивно. Это означает, что вносится некоторое количество «пробных» изменений. Эти изменения не являются постоянными. Если мы хотим сделать сделать их постоянными, то говорим об этом, и они коммитятся. То есть мы вносим пробные изменения, и если всё хорошо, то применяем транзакцию. Коммит означает, что мы делаем результат транзакции видимым миру.
Если транзакция срабатывает неуспешно, мы прерываем её. То есть существует два возможных результата транзакции: её можно закоммитить, и тогда она вступает в силу, а можно прекратить, тогда она никак и ни на что не влияет.
Атомарные блоки
Перед нами обычный пример атомарного блока:
atomic { x.remove(3); y.add(3); } atomic { y = null; }
Представьте, что у нас есть два потока, один удаляет 3 из x и добавляет 3 к y. Скажем, что мы изобрели ключевое слово atomic, и код с ним исполняется атомарно. Тогда здесь у нас простой пример того, как переместить что-то из одного контейнера в другой. Это один из тех примеров, которые, оказывается, сложно реализовать чисто с использованием блокировок.
Ещё здесь у нас есть параллельный поток, который по сути устанавливает y равным нулю.
Если бы это были обычные несинхронизированные блоки, тогда параллельный доступ к y считался бы гонкой данных. Если бы вы сделали это на C++ без синхронизации, результат вашей программы был бы не определён. На Java же атомарные блоки будут синхронизированы, и результат будет определён. Так что можно считать, что атомарные блоки относятся к синхронизированным блокам.
Двухсторонняя очередь
Помните, мы говорили, как сложно имплементировать что-то типа двухсторонней очереди, используя блокировки? Сейчас я покажу вам нечто вроде идеализированной методологии написания подобных структур данных с использованием транзакции. Я собираюсь написать двухстороннюю очередь так, чтобы она была длинной — тогда два потока смогут работать на обоих концах очереди без взаимных помех.
Первый шаг — это написать последовательный код.
public void LeftEnq(item x) { Qnode q = new Qnode(x); q.left = left; left.right = q; left = q; }
Написать простой код для очереди может кто угодно. Здесь вы создаёте узел для очереди, меняете указатели и связываете их. Это стандартный последовательный код.
Второй шаг — заключить этот код в атомарный блок:

Несинхронизированный код тут не подойдёт: если параллельные постановки в очередь будут неудачно перемежаться, то случится что-то плохое. Но если мы заключим все наши шаги в атомарный блок, то все эти четыре строки произойдут вместе, и не нужно беспокоиться о корректности очереди. То есть с транзакциями вы можете писать последовательный код, помещая ядро своих операций в атомарные блоки. Система рантайма разберётся, что нужно сделать, и всё работает.
Предупреждение

Но не всё так просто. Не всегда получается установить атомарные блоки вокруг последовательного кода так, чтобы это всегда срабатывало. Это получается лишь в части случаев. Есть множество проблем:
Ожидание условия (conditional wait). Помните наш поток, который был заблокирован, заглянул в буфер и сказал: «Здесь ничего нет, я снимаю блокировку»? Требуется объяснить, как это будет работать с транзакциями.
Могут быть проблемы с ложными конфликтами. Система исполнения транзакций может усматривать конфликт между двумя операциями, когда его на самом деле нет.
Разумеется, есть ограничения ресурсов. Мы увидим это на примере аппаратных транзакций, которые могут быть слишком большими или слишком медленными, с ними могут быть проблемы.
Тем не менее, я продолжаю утверждать, что с транзакциями жизнь проще: ваш код будет проще писать, и он с большей вероятностью окажется корректным. Лучше уж упомянутые проблемы (хотя некоторые из них вполне серьёзные), чем те, что возникают с блокировками. Решить проблемы с транзакциями проще. Транзакции не волшебные, они не избавят вас от проблем, но с ними вы будете лучше спать ночью. Я обещаю.
Компоновка?
Помните наш пример с компоновкой, где мы хотели совершить атомарное перемещение элемента из одной очереди в другую?

Опять же, если использовать идеализированную форму транзакций, то это очень просто:
public void Transfer(Queue<T> q1, q2) { atomic { T x = q1.deq(); q2.enq(x); } }
Мы просто совершаем последовательное перемещение, используем ключевое слово atomic вокруг него, и пусть система транзакций делает синхронизацию. При этом двум очередям не нужно экспортировать примитивы синхронизации, нам не нужно особенно беспокоиться, чтобы клиенты объектов следовали сложным протоколам.
Ожидание условия
Эта конструкция на самом деле используется в многопоточной версии Haskell, в которой есть встроенные транзакции. Идея в том, что я хочу выполнить удаление из очереди, но если нечего удалять, то пойду спать.
public T LeftDeq() { atomic { if (left == null) retry; … } }
Так что я использую retry, который говорит: «Я совершил эту транзакцию, мне не понравилось то, что я увидел, я скажу „откатить транзакцию обратно до вызова, а если что-то изменится, разбудить меня и попробовать снова“».
То есть здесь тот же результат, что и signal and wait в мониторе, но это гораздо проще использовать и, я думаю, это более понятно интуитивно. Ожидание монитора таит множество опасностей и ловушек, а retry поможет их избегать.
Компонируемое ожидание условие
Если вы хотите скомпоновать условное ожидание, можно ввести конструкцию orElse.
atomic { x = q1.deq(); } orElse { x = q2.deq(); }
Сначала я запущу свой первый метод qt.deq(), если там будет retry, он вернётся и скажет: «Извините, я ничего не могу здесь сделать». Тогда вы можете вернуться и попробовать второй, q2.deq(). Если у обоих будет retry, тогда retry будет у всей конструкции — она засыпает, откатывает свои результаты, ждёт изменений и затем заново запускает код. То есть снаружи это выглядит так, будто каждый раз, когда вы делаете удаление из очереди, там что-то есть.
И я утверждаю, что это гораздо проще использовать и об этом гораздо проще рассуждать, чем алгоритмы блокировок. В данный момент всё выглядит так, будто я сказал: «У нас есть волшебный атомарный дескриптор, который решит все ваши проблемы за вас, смотрите, как легко им пользоваться».
Но как это работает на самом деле? Сейчас я расскажу о том, как имплементировать атомарные транзакции в языки программирования.
Аппаратная транзакционная память
Пойдём снизу, с железа. Как программисты вы, наверное, не слишком интересуетесь аппаратным обеспечением. Но параллельное программирование пока остаётся довольно незрелой областью, и вы не сможете писать эффективные программы, пока не поймёте кое-что о работе железа.
Есть два вида процессоров, которые поддерживают транзакционную память. В основном я буду говорить об Intel — там, начиная с Haswell, используются расширения TSX (Transactional Synchronization Extensions). Есть и другой вид аппаратного обеспечения транзакционной памяти в семействе процессоров Power. Intel больше ориентирован на мелкоструктурную параллельность, а Power — на численные вычисления.
Основная идея в том, что вы используете стандартную когерентность кэша для синхронизации. Оказывается, современные процессоры уже выполняют много контроля параллелизма, потому что им нужно управлять кэшами. И оказывается, они уже определяют конфликты синхронизации. И они уже объявляют недействительными кэшированные копии данных.
И ключевой момент для понимания мира аппаратной транзакционной памяти в том, что вы можете взять эти стандартизированные протоколы, которые существуют с прошлого века, внести небольшие изменения и получить аппаратную поддержку транзакций. Это и лежит в основе семейств аппаратной транзакционной памяти Haswell и Power.
Стандартная когерентность кэша

Стандартная когерентность кэша работает следующим образом. У нас есть набор процессоров, оперативная память, общая шина, которая используется для коммуникации, и есть кэши этих процессоров.
Один процессор загружает что-то, посылает сообщение на шину, память отвечает и посылает ему данные. Они оказываются в кэше процессора. Затем второй процессор тоже запрашивает эти данные. Поскольку все слушают шину, первый процессор даёт их второму.

И здесь требуется синхронизация, потому что, если один процессор изменит данные, то он должен сказать всем остальным: «Выкидывайте свои копии данных из кэша, я изменил их».
Посылать данные обратно в память слишком затратно, поэтому их держат в кэше процессора. Так что память по возможности минимально участвует в процессе — только если требуются данные, которых нет ни в одном кэше.
Аппаратная транзакционная память
Аппаратная транзакционная память работает почти по такому же принципу. Один процессор начинает считывать данные и помечает их в кэше: «Я считал это от имени транзакции».

Другой процессор также помечает их как транзакционные, теперь у обоих они так помечены.
В какой-то момент процессор принимает решение о коммите, тогда данные просто помечаются как не транзакционные, и другой процессор следует примеру. То есть когда вы записываете что-то, то меняете это в кэше.
Теперь давайте отмотаем назад и поговорим о том, что происходит, когда есть конфликт между транзакциями. Итак, оба процессора считали данные от имени транзакций, один процессор записал их. Он выдаёт аннулирование и первая транзакция прерывается, потому что появился конфликт синхронизации.

Как вы видите, нам нужна пара дополнительных битов в линиях кэша и пара дополнительных сообщений, и мы сможем превратить стандартную когерентность кэша в транзакционную память.
В отличие от распределённых вычислений, вы можете коммитить локально. Вам достаточно только помечать ваши транзакционные записи в кэш как валидные и не транзакционные. Так что это более эффективно, чем ваши стандарты двухфазного протокола коммита. В общем-то, вот этого достаточно понимать о том, как транзакционная память работает на уровне железа.
Использование транзакционной памяти
Пояснение о железе потребовалось, потому что оно объясняет некоторые странные вещи, которые происходят, когда вы пишете программы. Как я уже говорил, в процессорах Blue Gene/Q, в System Z и Power8 есть форма транзакционной памяти. Сейчас я буду говорить об Intel, потому что у меня есть время поговорить только о чём-то одном.
На TSX Intel вот так вы пишете транзакцию:
if (_xbegin() == _XBEGIN_STARTED) { speculative code _xend() } else { abort handler }
Это код на C. Вы начинаете с того, что говорите, _xbegin() — это системный вызов, который говорит: «Я хочу начать спекулятивную транзакцию». Это немного похоже на fork() или vfork() в Unix, он возвращает код. И если вы видите в коде _XBEGIN_STARTED), это значит, что вы внутри транзакции. Если это происходит, вы выполняете свой спекулятивный код.
Если вы получили любой другой код, это значит, что ваша транзакция прервана. Это значит, вы попробовали выполнить свой спекулятивный код, он почему-то не сработал, и теперь вам нужно сделать что-то, чтобы восстановиться после сбоя транзакции. Вы можете попробовать ещё раз, либо попробовать что-то из следующих вариантов.
Код обычно выглядит примерно так:
if (_xbegin() == _XBEGIN_STARTED) { speculative code } else if (status & _XABORT_EXPLICIT) { aborted by user code } else if (status & _XABORT_CONFLICT) { read-write conflict } else if (status & _XABORT_CAPACITY) { cache overflow } else { … }
Какие варианты тут есть?
_XABORT_EXPLICIT: я могу вызвать _xabort(). Мне что-то не понравилось, так что я решил прервать свою транзакцию и откатиться обратно, например, некоторое ожидание условия.
_XABORT-CONFLICT: может быть, у меня с кем-то конфликт синхронизации, если такое происходит, возможно, мне стоит попробовать снова позже.
_XABORT_CAPACITY: Может быть, мой буфер переполнился, я упёрся в некий аппаратный лимит, так что, возможно, пробовать снова не лучшая идея, потому что результат будет тот же, если такое происходит.
И есть ещё много разных кодов прерывания.
Что может пойти не так, если вы используете эти механизмы в написании программы?
Транзакция слишком большая. Может случиться так, что ваша транзакция окажется слишком большой, так что если ваши данные выйдут за пределы счётчика кэшей или внутренних буферов, то ваша транзакция не сработает. Так что вы должны использовать аппаратные транзакции для небольших транзакций.
Транзакция слишком медленная. Если ваша транзакция слишком медленная, то прерывание по таймеру может очистить ваш кэш и ваша транзакция прервётся.
Транзакция просто не в настроении. Существует множество других причин прерывания транзакции: промах TLB, исполнение неразрешённой команды, отказ страницы. Это происходит крайне редко, но это может произойти.
Так что обычно для использования аппаратной транзакционной памяти разновидности Intel применяется гибридный подход.
Гибридная транзакционная память
Здесь мы объединим транзакционный подход с блокировками. Вот пример такой комбинации.
if (_xbegin() == _XBEGIN_STARTED) { read lock state if (lock taken) _xabort(); work; _xend() } else { lock->lock(); work; lock->unlock(); }
Идея следующая: я начинаю транзакцию, у меня будет блокировка, я прочитаю её состояние (read lock state). И как только я прочитаю его, это гарантирует, что если другой поток блокирует что-то, это прервёт мою транзакцию (if (lock taken) _xabort();).
Если блокировка установлена, то я откачусь и, возможно, сам установлю блокировку. Если моя транзакция прерывается, то я скажу: «Хорошо, я попробовал спекулятивный подход, может быть, здесь большая конкуренция, попробую установить блокировку в любом случае». Но если я могу исполнить код без использования блокировки, тогда моя параллельность будет лучше.
Пропуск блокировки
Есть паттерн «пропуск блокировки» (Lock Elision), который поддерживается на аппаратном обеспечении Intel.
<HLF acquire prefix> lock(); do work; <HLE release prefix> unlock()
Вы устанавливаете блокировку и отправляете специальный код. В первый раз всё, что вы делаете внутри критической секции, делается спекулятивно с использованием механизма аппаратной транзакционной памяти. Если происходит сбой, то вы повторяете уже с установкой блокировки.
Хорошо то, что таким образом вы можете ускорить старый код. В том смысле, что я могу взять код, написанный задолго до того, как аппаратная транзакционная память была вообще изобретена, я могу немного изменить код установки блокировки в двоичном редакторе и я получу существенное ускорение во многих приложениях. Заметьте, что зачастую потоки, на которых установлены конфликтующие блокировки, на самом деле не конфликтуют, потому что блокировка слишком грубая.
Телепортация блокировки
Есть забавное использование транзакционной памяти, которую я называю «lock teleportation».

Идея тут в следующем. Есть такой общий паттерн в структурах данных, который называется «передающаяся блокировка» (hand-over-hand locking). Представьте, я иду вниз по списку, поочередёно устанавливая и снимая блокировку на разных элементах, и я могу следовать этому паттерну по мере движения. Это даёт ограниченное количество параллельности.
Если я хочу что-то убрать, я могу сделать это, используя перехватывающую блокировку.
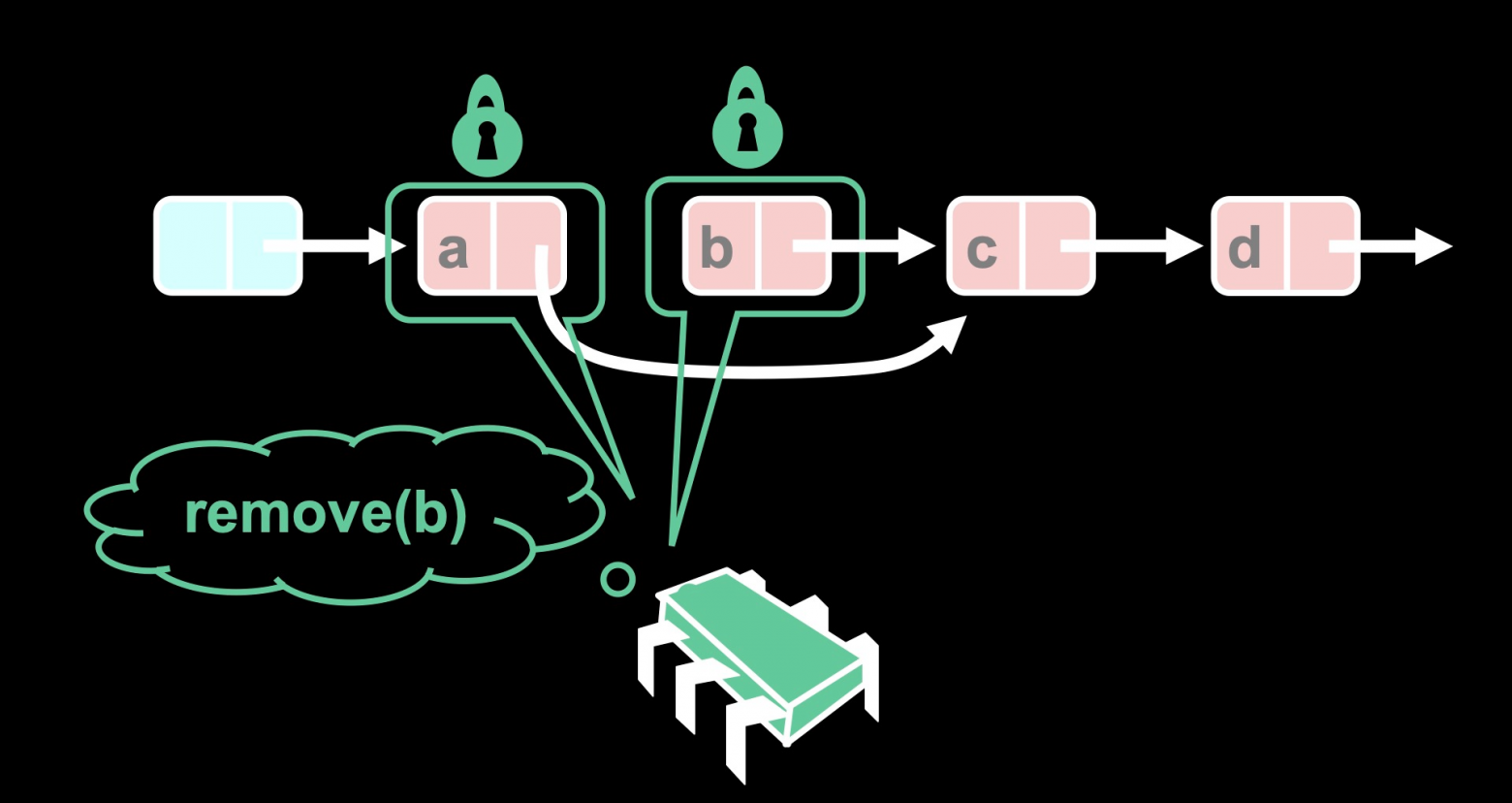
Идея телепортации в том, что я могу комбинировать блокировки и транзакционную память различными способами. Например, могу установить блокировку и начать транзакцию, пока блокировка захвачена. Я могу считывать список и потом где-то внутри транзакции могу снять одну блокировку и установить совсем другую. И здесь преимущество в том, что не было захвачено ни одной блокировки в промежутке (от a до c):

Так что я устанавливаю одну блокировку, начинаю атомарную транзакцию, бегу по списку, устанавливаю вторую блокировку, снимаю первую блокировку, а затем фиксирую транзакцию. И снаружи это выглядит как будто блокировка мгновенно переместилась из одного конца списка в другой. И это гораздо более эффективно, чем передающаяся блокировка.
Здесь есть пара коварных моментов. Например, как далеко я хочу телепортировать блокировку? Как далеко я хочу продвинуться в чтении перед тем как переместить блокировки? Если перемещение будет слишком коротким, я упущу возможность — при ограниченной передающейся блокировке, считается, вам не нужны транзакции для удерживании одной блокировке при установке другой. А если я уйду слишком далеко, (например, переполню свой аппаратный буфер), тогда моя транзакция прервётся и весь этот труд, что я сейчас проделал, не приведёт ни к чему. Так что хитрость в том, чтобы понять, насколько телепортировать блокировку.
Есть некоторое количество мер, которые мы можем тут предпринять. Пожалуй, наиболее успешная стратегия из всех, что я видел — адаптивная телепортация:

Вы устанавливаете ограничение, насколько далеко можете продвинуться. И после каждого успешного раза говорите: «Хорошо, в следующий раз я продвинусь на один дальше». Так что если вы успешно телепортировали блокировку на 5 шагов, в следующий раз вы попробуете 6, а ещё в следующий — 7. В какой-то момент вы выйдете за пределы. В таком случае вы устанавливаете ограничение в половину того, что у вас было в последний раз, и готово.
Вопросы для исследования
Напоследок я дам высокоуровневый короткий обзор открытых вопросов, на которые мы бы хотели знать ответы, но пока их точно не знает никто.
Блокировки
Как я уже говорил, одна из интересных областей — как эффективно комбинировать транзакции и блокировки. Я не думаю о транзакциях и блокировках как о врагах, оба эти механизма решают одни и те же виды задач, а их сильные и слабые стороны дополняют друг друга. И меня очень воодушевляет идея попыток понять, как их можно применять вместе, чтобы они делали друг друга сильнее.
Управление памятью
Одна из областей, где транзакции оказались на удивление полезными — управление памятью (как ручное, так и автоматическое). Malloc, free, сборка мусора... Если вы занимаетесь управлением памятью, то стремитесь совершать операции одного стиля, и хорошо понятно, какой объём работы вам придётся проделать. Это крайне важно, потому что программы постоянно распределяют и освобождают память. И мне кажется, транзакционная память уже показала, что может быть полезна здесь, но я считаю, что предстоит ещё много работы по улучшению.
БД
Базы данных — это область, где аппаратные транзакции могут быть полезны, это немного иронично, потому что мы украли идею атомарных транзакций из баз данных, но в классических базах данных совершенное другое представление о том, что такое транзакции. Транзакции оказались очень полезными для баз данных в оперативной памяти — это те базы данных, которые живут в памяти, а не на диске, они хороши для сетевой обработки транзакций, веб-серверов: Amazon, Яндекс — такого рода приложений.
Энергетическая эффективность
Одна область, которая мне нравится и, как мне кажется, не получает достаточно внимания, это влияние на энергоэффективность, на архитектуру. Мы с моими коллегами из инженерного отдела работали над пониманием того, что энергетически эффективнее: блокировки или транзакции. Ваша микросхема скорее перегреется, если вы используете блокировки, или транзакционную память? И транзакционная память кажется более энергетически эффективной при большинстве условий из-за спекулятивного выполнения.
Графические процессоры
Была проведена большая работа над аппаратными ускорителями. GPU — самый очевидный пример. Оказалось, что графические процессоры могут использовать аппаратные транзакции, опять же, они немного отличаются от многоядерных аппаратных транзакций. Но было очень полезно применять аппаратные транзакции и технологии аппаратных транзакций в графических процессорах.
ОС
И наконец, такие вещи как операционные системы — это большая область. Оказалось, что вы можете упрощать ядра операционных систем, драйверы устройств — разных вещей. Мне кажется, что в этой конкретной области всё ещё очень много интересных вопросов.
Структуры данных
Проведена большая работа со структурами данных. Если вы наивно спроектировали структуру данных, оказалось, что транзакции могут не очень хорошо работать. Например, если в вашей хэш-таблице есть счётчик, который увеличивается с каждой операцией, то у вас не выйдет много параллельности со спекулятивными транзакциями, потому что все будут конфликтовать на счётчике. Поэтому это целое искусство проектировать структуры данных так, чтобы транзакции работали.
Архитектура компьютера
И, конечно, есть простор для работы с архитектурой компьютера, раз уж в некотором смысле транзакционная память берёт своё начало из архитектуры компьютера.
Есть понятие «Кривая хайпа» (hype curve). Она говорит, что при появлении новой идеи люди говорят: «О! Это чудесно! Это решит все проблемы!» Это первый верхний выступ. Потом они говорят: «Ой, погодите-ка. Появляются всевозможные новые проблемы и задачи, может, это на самом деле плохо». А в итоге люди научаются решать задачи и всё становится нормально.

Этот путь прошли все мыслимые технические инновации, включая сборку мусора, виртуальную память и так далее. И я думаю, мы сейчас в той точке, где транзакции становятся нормой.
Транзакционные конструкции поддерживаются в C++, Haskell, других языках, они введены в архитектуры Intel и, очевидно, они уже никуда не денутся. Так что транзакции останутся надолго. И нам только нужно понять, как лучше их использовать.
Если заинтересовал этот доклад, обратите внимание на Hydra 2021: там снова выступит Морис Херлихи, а также будет много других заметных людей из мира распределённых и многопоточных систем. Конференция пройдёт с 15 по 18 июня в онлайне, программу и другую информацию можно увидеть на сайте.

