Представляем вам версию 0.2 библиотеки глубокого обучения KotlinDL.
KotlinDL 0.2 теперь доступен на Maven Central (до этого он лежал на bintray, но закатилось солнышко земли опенсорсной). Появилось столько всего нового: новые слои, специальный DSL для препроцессинга изображений, новые типы датасетов, зоопарк моделей с несколькими моделями из семейства ResNet, MobileNet и старой доброй моделью VGG (рабочая лошадка, впрочем).
В этой статье мы коснемся самых главных изменений релиза 0.2. Полный список изменений доступен по ссылке.
Functional API
Прошлая версия библиотеки позволяла описывать нейронные сети лишь при помощи Sequential API. Например, используя метод Sequential.of(..), вы могли легко описать модель как последовательность слоев и построить VGG-подобную модель.
Однако с 2014 года (эпохи взлета и расцвета подобных архитектур) много воды утекло, и было создано множество новых нейросетей. В частности, стандартным подходом стало использование так называемых остаточных нейросетей (Residual Neural Networks или ResNet), которые решают проблемы исчезающих градиентов (vanishing gradients) и, напротив, взрывающихся градиентов (exploding gradients) — а значит, и проблемы деградации обучения нейросети. Подобные архитектуры невозможно описать в виде Sequential API — их корректнее представлять в виде направленного ациклического графа (Directed Acyclic Graph). Для задания таких графов мы добавили в версии 0.2 новый Functional API, который позволяет нам описывать модели, подобные ResNet или MobileNet.
Ну что же, давайте построим некое подобие ResNet. Нейросеть будет обучаться на датасете FashionMnist (небольшие изображения модных вещей). Черно-белые изображения размером 28х28 отлично подойдут на старте работы с нейросетями.
val (train, test) = fashionMnist() val inputs = Input(28, 28, 1) val conv1 = Conv2D(32)(inputs) val conv2 = Conv2D(64)(conv1) val maxPool = MaxPool2D(poolSize = intArrayOf(1, 3, 3, 1), strides = intArrayOf(1, 3, 3, 1))(conv2) val conv3 = Conv2D(64)(maxPool) val conv4 = Conv2D(64)(conv3) val add1 = Add()(conv4, maxPool) val conv5 = Conv2D(64)(add1) val conv6 = Conv2D(64)(conv5) val add2 = Add()(conv6, add1) val conv7 = Conv2D(64)(add2) val globalAvgPool2D = GlobalAvgPool2D()(conv7) val dense1 = Dense(256)(globalAvgPool2D) val outputs = Dense(10, activation = Activations.Linear)(dense1) val model = Functional.fromOutput(outputs) model.use { it.compile( optimizer = Adam(), loss = Losses.SOFT_MAX_CROSS_ENTROPY_WITH_LOGITS, metric = Metrics.ACCURACY ) it.summary() it.fit(dataset = train, epochs = 3, batchSize = 1000) val accuracy = it.evaluate(dataset = test, batchSize = 1000) .metrics[Metrics.ACCURACY] println("Accuracy after: $accuracy") }
Перед вами вывод метода summary(), описывающий архитектуру только что созданной нами модели.

Некоторые не любят сухие отчеты и предпочитают диаграммы. В нашем случае диаграмма типична для всех представителей славного семейства ResNet.
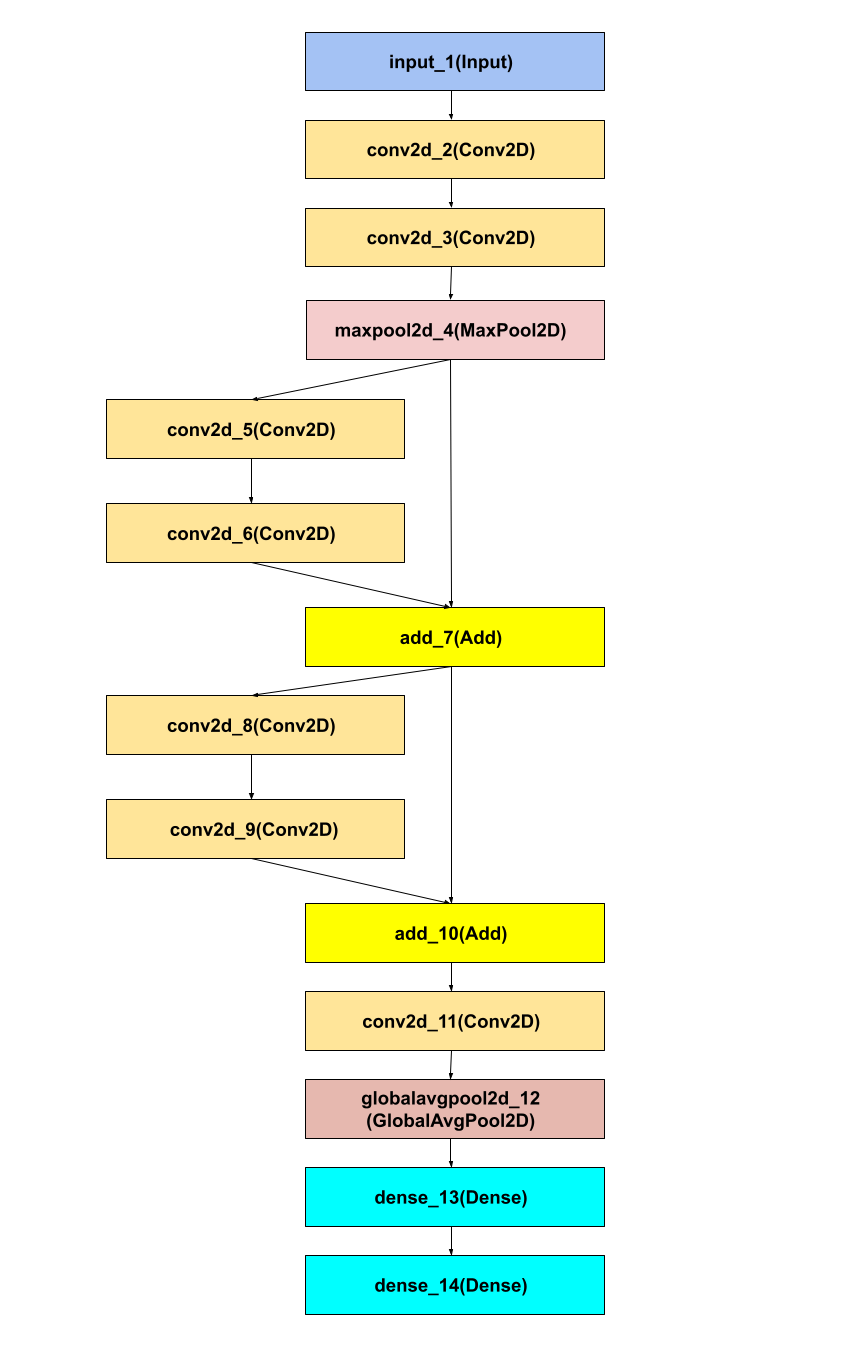
Если вы знакомы с фреймворком Keras, то без особого труда сможете перенести модели, описанные при помощи Functional API, в Keras, используя KotlinDL.
Коллекция предварительно тренированных моделей ResNet и MobileNet
Начиная с релиза 0.2, в Kotlin DL появляется «зоопарк моделей» (или Model Zoo). По сути, это коллекция моделей с весами, полученными в ходе обучения на большом датасете изображений (ImageNet).
Зачем нужна такая коллекция моделей? Дело в том, что современные сверхточные нейросети могут иметь сотни слоев и миллионы параметров, обновляемых многократно в течении каждой итерации обучения. Тренировка моделей до приемлемого уровня точности (70–80%) на таком большом датасете, как ImageNet, может занимать сотни и тысячи часов вычислительного времени большого кластера из видеокарт.
Зоопарк моделей позволяет вам пользоваться уже готовыми и натренированными моделями (вам не придется тренировать их с нуля каждый раз, когда они вам нужны). Вы можете использовать такую модель непосредственно для предсказаний. Также вы можете применить ее для дотренировки части модели на небольшой порции входных данных — это весьма распространненная техника при использовании переноса обучения (Transfer Learning). Это может занять десятки минут на одной видеокарте (или даже центральном процессоре) вместо сотен часов на большом кластере.
Доступны следующие модели:
VGG’16
VGG’19
ResNet50
ResNet101
ResNet152
ResNet50v2
ResNet101v2
ResNet152v2
MobileNet
MobileNetv2
Для каждой модели из этого списка доступны функции загрузки конфигурации модели в JSON-формате и весов в формате .h5. Также для каждой модели можно использовать специальный препроцессинг, применявшийся для ее обучения на датасете ImageNet.
Ниже вы видите пример загрузки одной из таких моделей (ResNet50):
// specify the model type to be loaded, ResNet50, for example val loader = ModelZoo( commonModelDirectory = File("cache/pretrainedModels"), modelType = ModelType.ResNet_50 ) // obtain the model configuration val model = loader.loadModel() as Functional // load class labels (from ImageNet dataset in ResNet50 case) val imageNetClassLabels = loader.loadClassLabels() // load weights if required (for Transfer Learning purposes) val hdfFile = loader.loadWeights()
Ну что же, теперь у вас есть сама модель и веса — вы можете использовать их по вашему усмотрению.
Внимание! К изображениям, которые вы подаете на вход модели для предсказаний, необходимо применять специальный препроцессинг, о котором мы говорили ранее. Иначе вы получите неверные результаты. Для вызова препроцессинга используйте функцию preprocessInput.
Если вам не нужны предобученные веса, но вы не хотите описывать многослойные модели а-ля VGG или ResNet с нуля, у вас есть два пути: а) просто загрузить конфигурацию модели либо б) взять за основу полный код конструирования модели, написанный на Kotlin, — он доступен для каждой из моделей через вызов функции высшего порядка, лежащей в пакете org.jetbrains.kotlinx.dl.api.core.model.
Ниже мы приводим пример использования функции, строящей облегченную версию ResNet50:
val model = resnet50Light(imageSize = 28, numberOfClasses = 10, numberOfChannels = 1, lastLayerActivation = Activations.Linear)
Если вы хотите узнать больше о переносе обучения и использовании зоопарка моделей, советуем этот туториал: вы увидите, как загружается модель VGG’19, затем у нее удаляется последний слой, добавляются новые Dense-слои, после чего их веса инициализируются и дообучаются на небольшом датасете, состоящем из изображений кошек и собак.
DSL для предобработки изображений
Python-разработчикам предлагается огромное количество библиотек визуализации и предобработки изображений, музыки и видео. Разработчикам экосистемы языков программирования JVM повезло меньше.
Большинство библиотек для предобработки изображений, найденные на просторах Github и имеющие разную степень заброшенности, так или иначе используют класс BufferedImage, оборачивая его более понятным и согласованным API. Мы решили упростить жизнь Kotlin-разработчиков, предложив им простой DSL, построенный на лямбда-выражениях и объектах-приемниках.
На данный момент доступны следующие функции преобразования изображений:
Load
Crop
Resize
Rotate
Rescale
Sharpen
Save
val preprocessing: Preprocessing = preprocess { transformImage { load { pathToData = imageDirectory imageShape = ImageShape(224, 224, 3) colorMode = ColorOrder.BGR } rotate { degrees = 30f } crop { left = 12 right = 12 top = 12 bottom = 12 } resize { outputWidth = 400 outputHeight = 400 interpolation = InterpolationType.NEAREST } } transformTensor { rescale { scalingCoefficient = 255f } } }
Весьма популярной техникой при тренировке глубоких сверточных нейросетей является аугментация данных — методика создания дополнительных обучающих данных из имеющихся данных. При помощи перечисленных функций можно организовать простейшую аугментацию: достаточно выполнять повороты изображения некоторый угол и менять его размеры.
Если, экспериментируя с DSL, вы поймете, что некоторых функций вам не хватает, не стесняйтесь написать об этом в наш баг-трекер.
Новые слои
В релизе 0.2 появилось много новых слоев. В основном, это обусловлено тем, что они используются в архитектурах ResNet и MobileNet:
BatchNorm
ActivationLayer
DepthwiseConv2D
SeparableConv2D
Merge (Add, Subtract, Multiply, Average, Concatenate, Maximum, Minimum)
GlobalAvgPool2D
Cropping2D
Reshape
ZeroPadding2D*
* Спасибо Anton Kosyakov за имплементацию нетривиального ZeroPadding2D!
Кстати, если вы хотите добавить новый слой, вы можете самостоятельно реализовать его и создать пул-реквест. Список слоев, которые мы хотели бы включить в релиз 0.3, представлен набором тикетов в баг-трекере с пометкой «good first issue» и может быть использован вами как точка входа в проект.
Dataset API и парочка наследников: OnHeapDataset & OnFlyDataset
Типичным способом прогона данных через нейросеть в режиме прямого распространения (forward mode) является последовательная загрузка батчей в оперативную память, контролируемую языком, а затем — в область нативной памяти, контролируемую вычислительным графом модели TensorFlow.
Мы также поддерживаем подобный подход в OnFlyDataset. Он последовательно, батч за батчем, загружает датасет в течений одной тренировочной эпохи, применяя препроцессинг данных (если вы его заранее определили) и аугментацию (если вы ее добавили).
Этот метод хорош, когда оперативной памяти мало, а данных много. Но что, если оперативной памяти более чем достаточно? Это не такой уж редкий случай для задач переноса обучения: датасеты для дообучения могут быть не такими большими, как при тренировке моделей. Также можно получить некоторый прирост в скорости за счет того, что препроцессинг будет применен лишь один раз — на этапе формирования датасета, а не при каждой загрузке батча. Если у вас достаточно оперативной памяти, используйте OnHeapDataset. Он будет держать все данные в оперативной памяти — не нужно будет повторно считывать их с диска на каждой эпохе.
Набор встроенных датасетов
Если вы только начинаете путешествие в удивительный мир глубокого обучения, мы настоятельно рекомендуем вам строить и запускать ваши первые нейросети на широко известных датасетах, таких как MNIST (набор рукописных цифр), FashionMNIST(набор изображений модных вещей от компании Zalando), Cifar’10 (подмножество ImageNet, насчитывающее 50 000 изображений) или коллекцию изображений кошек и собак со знаменитого соревнования Kaggle (по 25 000 изображений каждого класса различных размеров).
Все эти датасеты, как и модели из зоопарка моделей, вы можете загрузить в папку на вашем диске при помощи функций высшего порядка, таких как mnist() и fashionMnist(). Если датасет уже был загружен, заново по сети он грузиться не будет, а будет взят с диска.
Как добавить KotlinDL в проект
Чтобы начать использовать KotlinDL в вашем проекте, просто добавьте дополнительную зависимость в файл build.gradle:
repositories { mavenCentral() } dependencies { implementation 'org.jetbrains.kotlinx:kotlin-deeplearning-api:0.2.0' }
KotlinDL можно использовать в Java-проектах, даже если у вас нет ни капли Kotlin-кода. Здесь вы найдете пример построения и тренировки сверточной сети, полностью написанный на Java.
Если вы думаете, что в вашем проекте будет полезен Java API, напишите нам об этом или создайте PR.
Полезные ссылки
Мы надеемся, что вам понравилась наша статья и новые возможности KotlinDL.
Хотите узнать больше о проекте? Предлагаем ознакомиться с Readme или со страничкой проекта на GitHub. А этот туториал поможет вам создать вашу первую нейросеть на Kotlin.
Если вам интересно, как устроен KotlinDL, как он появился и в каком направлении развивается, почему он так похож на Keras, и планируется ли поддержка PyTorch, посмотрите свежее видео от Алексея Зиновьева.
Также мы ждем вас в Slack-канале #kotlindl (инвайт можно получить тут). В нем вы можете задавать вопросы, участвовать в дискуссиях и первыми получать информацию о превью-релизах и новых моделях в зоопарке моделей.
Ваша обратная связь, ваши описания багов и краш-репорты, идеи и комментарии — все это очень важно для нас. Мы ждем новых пользователей и контрибьюторов, как начинающих, так и опытных исследователей — всех, кому интересны Deep Learning и Data Science на Kotlin, Java и Scala!

