
Если вы не знаете ни одного ассемблера, или, возможно, не имеете большого опыта кодинга как такового, то ассемблер RISC-V может быть одним из лучших вариантов для того, чтобы погрузиться в эту тему. Конечно, материалов по ассемблеру x86 гораздо больше. Больше людей, которые могут в этом помочь. Но x86 - это чудовище, имеющее более 1500 различных инструкций.
Архитектура RISC-V, напротив, придумана специально для того, чтобы быть простой в изучении и вместе с тем, практически эффективна для реализации высокопроизводительных микропроцессоров.
Если вам необходим хороший старт, и вы не знаете ничего о микропроцессорах, вы можете прочесть мою статью "Как работает современный микропроцессор?" (How Does a Modern Microprocessor Work?).
Если вы хотите чего-нибудь простого и весёлого, можете начать с различных игр, в основе которых лежит программирование на ассемблере: Learn Assembly Programming the Fun Way.
Другим может понравиться ретропроцессор, такой, как 6502, использовавшийся в Commodore 64. Но проблема в том, что он окончательно устарел. При его разработке не учитывались реалии сегодняшнего дня.
Большой плюс RISC-V состоит в том, что он обладает современным и простым набором команд, спроектированным с учётом современных требований, таких как медленный доступ к памяти, использование предсказателя переходов, суперскалярного out-of-order выполнения команд и т.д.
Если вам интересно всё это, прочтите: Why Is Apple’s M1 Chip So Fast?
Перед тем, как мы начнём, можете распечатать это: James Zhu RISC-V Reference.
Установка и начало
Чтобы упростить весь процесс, я буду использовать онлайн-интерпретатор: this online RISC-V interpreter Корнелльского университета.
Посмотрите на скриншот. Оранжевый кружок внизу показывает простую программу, содержащую одну инструкцию, складывающую два числа, содержащихся в регистрах x1 и x2 , и помещающая результат вx3.
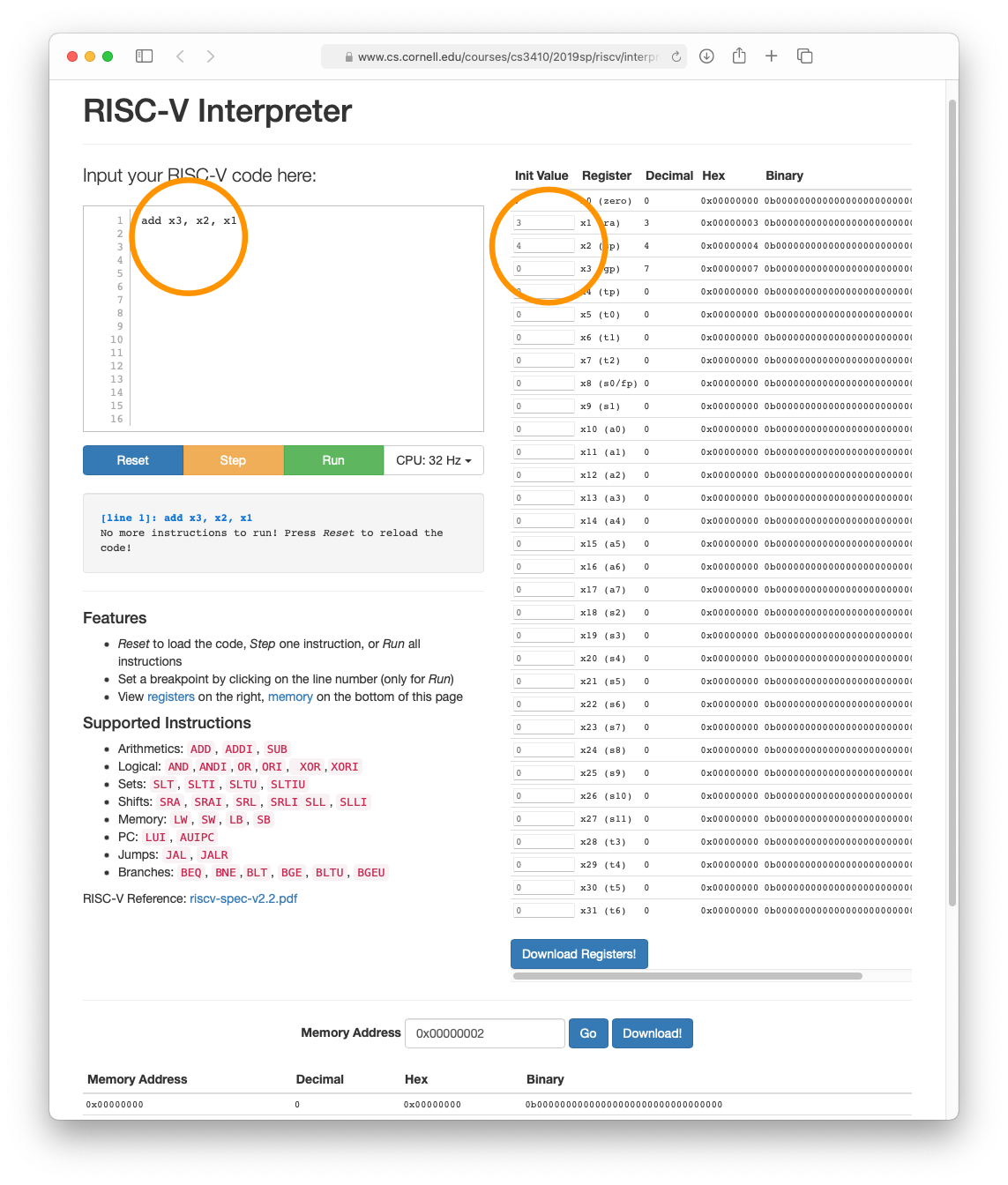
Регистры — это ячейки памяти внутри микропроцессора. Микропроцессор не может напрямую выполнять операции с данными, сохранёнными в памяти (ОЗУ). Он должен загрузить данные в регистр перед тем, как выполнить операцию.
С правой стороны вы можете видеть список регистров. Второй столбец, названный Register отображает имя регистра. В первом столбце мы устанавливаем начальное значение регистра. Регистры, выделенные оранжевым, регистры x1 и x2 устанавливаются в значения 3 и 4 соответственно.
ADD x3, x2, x1
Нажмите зелёную кнопку Run для записи программы. Она складывает регистры x1 и x2 и сохраняет результат в x3. Я уже запустил программу, и вы можете видеть значение 7 регистра x3 в столбце Decimal.
Вы можете скопировать программу побольше и попробовать запустить. Входная величина помещается в регистрx1. Это значение, от которого счётчик начинает считать вниз. Запишите в этот регистр, например,14 , записав в колонку Init Value.
ADDI x2, x0, 1 loop: SUB x1, x1, x2 SW x1, 4(x0) BLT x0, x1, loop HLT
Вы можете видеть, как происходит счёт назад, в колонке Decimal для регистров или памяти. Обратный счёт происходит во второй колонке в памяти по адресу 0x04.
Перед запуском вы должны установить CPU на 2 Hz. При этом будет выполняться две инструкции в секунду. Если процессор будет работать быстрее, вы не сможете следить за тем, что происходит. После этого нажимаете зелёную кнопку Run. При работе программы вы можете видеть, как она печатает в окне внизу, какая строка кода исполняется.

Чтобы запустить программу заново, нажмите синюю кнопку Reset. Сейчас вы знаете основы: как вставить программу, ввести данные и запустить её. Итак, сейчас мы обсудим микропроцессор RISC-V и то, как он программируется.
Использование регистров RISC-V
В моём "введении в микропроцессоры" introduction to microprocessors, я упоминал, что современные RISC-процессоры могут производить операции только в регистрах, но не в памяти.
RISC-V не исключение. У него есть 32 регистра общего назначения, названных x0 - x31. Первый регистр, x0 имеет специальное назначение, он содержит 0. Вне зависимости от того, какое значение вы в него записываете, при чтении из этого регистра вы всегда получите 0.
Это может показаться странным, но это очень практично. Существует множество операций, для которых вам нужен ноль в качестве операнда. Если у вас есть регистр, равный нулю, вам не нужно копировать ноль в регистр. Для тех, кто знаком с Unix, это похоже на /dev/null. В него можно записывать значения, которые не нужно сохранять.
Все регистры имеют псевдонимы, которые напоминают программисту, для чего служит данный регистр. Альтернативным названием x0 является zero. Это означает, что две следующие строки эквивалентны:
ADDI x2, x0 , 1 ADDI x2, zero, 1
Последняя более читаема, так как показывает, для чего предназначен регистр.
Давайте посмотрим на другие регистры:
rareturn address (адрес возврата). Используется для записи адреса возврата перед вызовом подпрограммы.spstack pointer (указатель стека).gpglobal pointer (глобальный указатель).tpthread pointer (указатель потока)t0-t6temporary registers (регистры временных переменных). Подпрограммы не обязаны их сохранять.s0-s11saved registers (сохраняемые регистры). Подпрограммы обязаны сохранять их состояние.a0-a7function arguments (аргументы функций). Перед вызовом подпрограммы вы передаёте аргументы в эти регистры.
Эта система именования отражает соглашение вызова, используемое в коде, который сгенерировал компилятор языка высокого уровня. Например, вы написали такой бесполезный код на С:
int calculate(int x, int y) { int tmp = x * 10; return tmp + y; } int main() { int alpha = 4; int beta = calculate(2, 3); return alpha + beta; }
Как он будет транслирован в ассемблерный код RISC-V? Я не говорю сейчас об инструкциях, я говорю о регистрах. В строке 7 мы сохраняем значение 4 в переменную alpha. Нам нужен будет регистр для записи этого значения.
Так как регистры могут быть использованы функцией calculate , вызываемой в строке 08, нужно ли нам беспокоиться , чтобы значениеalpha сохранялось? Как мы это сделаем? В прошлом программисты на ассемблере могли использовать память. Если быть точным, для сохранения переменных мы использовали стек. Однако в то время оперативная память была достаточно быстрой относительно CPU. В наши дни, CPU безумно быстр по сравнению с памятью. За время, нужное для сохранения в память, можно выполнить сотни инструкций. Поэтому мы делаем всё возможное, чтобы избежать чтения и запись в память.
RISC-V имеет соглашение. Если вы размещаете значение alpha в одном из регистров от s0 до s11 , что соответствует x8, x9 и от x18 до x27 , то они будут сохранены. Вызываемые подпрограммы обязаны не изменять их, и, если эти регистры всё же изменяются, то подпрограмма должна сохранить их и восстановить перед возвратом.
Но все регистры не могут быть сохраняемыми регистрами, иначе мы бы не смогли использовать ни один регистр, не сохраняя его. Решением являются регистры t - регистры временного хранения.
Переменная tmp внутри calculate может быть размещена в t0 , потому что нам не нужно сохранять её значение.
Следующая проблема состоит в том, как передавать аргументы в функцию. Старые соглашения о вызовах сохраняли аргументы в стеке. Но и в этом случае доступ к памяти без необходимости - плохая идея. RISC-V использует регистры a0 - a7 для хранения аргументов. Аргументыx и y передаются в a0 и a1 соответственно, что соответствует регистрам x10 и x11. Результат вычислений возвращается в a0.
Когда мы вызываем calculate в строке 08 мы хотим возвратиться и продолжить исполнение со строки 09. Соглашение в данном случае обязывает нас сохранять адрес возврата в регистре ra , которому соответствует x1. И снова, если у вас есть опыт работы с ассемблером CISC, вы, возможно, сохраняли адрес возврата в стеке.
Конечно, однажды регистры закончатся. Есть соглашение, как мы сохраняем данные в памяти в этом случае, но я не буду описывать это здесь.
Инструкции RISC-V
Прежде чем мы посмотрим на конкретные инструкции, может быть полезно рассмотреть общие принципы построения инструкций RISC-V. Если мы посмотрим на код ниже, мы увидим, что многие из них принимают три аргумента:
ADDI x2, x0, 1 loop: SUB x1, x1, x2 SW x1, 4(x0) BLT x0, x1, loop
Эти аргументы используются сходным образом в большинстве инструкций. В языке ассемблера мы не называем их аргументами. Аргументы есть у функций. У ассемблерных инструкций есть операнды, и тип инструкции, называемый опкодом. Таким образом, вся строка внизу называется инструкцией:
ADDI x2, x0, 1
ADDI - это опкод, а x2, x0 и 1 - операнды. Или, если выражаться точнее, ADDI - мнемоника, буквенное сокращение, заменяющее реальный числовой опкод, используемый в машинном коде. По практическим причинам, я буду использовать эти термины, как взаимозаменяемые.
Типичная инструкция RISC-V имеет следующий формат:
В терминах программирования мы можем думать о ней как о таком коде:
rd = f(rs1, rs2)
Опкод определяет функцию f, которая принимает два входных регистра rs1 и rs2 и производит результат, сохраняемый в регистре-приёмнике rd. Инструкции ADD и SUB будут записаны так:
rd ← rs1 + rs2 rd ← rs1 - rs2
Вместо того, чтобы описывать каждую инструкцию отдельно, я буду использовать эту нотацию в комментариях рядом с инструкциями. Комментарии в ассемблере RISC-V начинаются с символа # , как в скриптовых языках. К сожалению, я не обращал на это внимание до сих пор. Много моего предыдущего кода RISC-V было написано неправильно, потому что я использовал ; , что часто используется в других ассемблерах. Наш интерпретатор RISC-V не будет счастлив видеть комментарии после точки с запятой. Он хочет символ решётки.
В любом случае, я буду использовать комментарии для пояснения инструкций:
Почему операндов три?
Если вы используете язык более высокого уровня, вы знаете, что обычно функции не используют одно и то же число аргументов. Однако ассемблерные инструкции кодируются в фиксированном формате 32 бита. Чтобы упростить декодирование инструкции внутри CPU, полезно иметь различные части инструкции в фиксированных местах.
На картинке внизу показаны различные биты в 32-битной инструкции. Если вы посмотрите на картинку, вы можете заметить, что разработчики RISC-V постарались сделать разные части инструкций регулярным образом, чтобы упростить задачу декодирования.
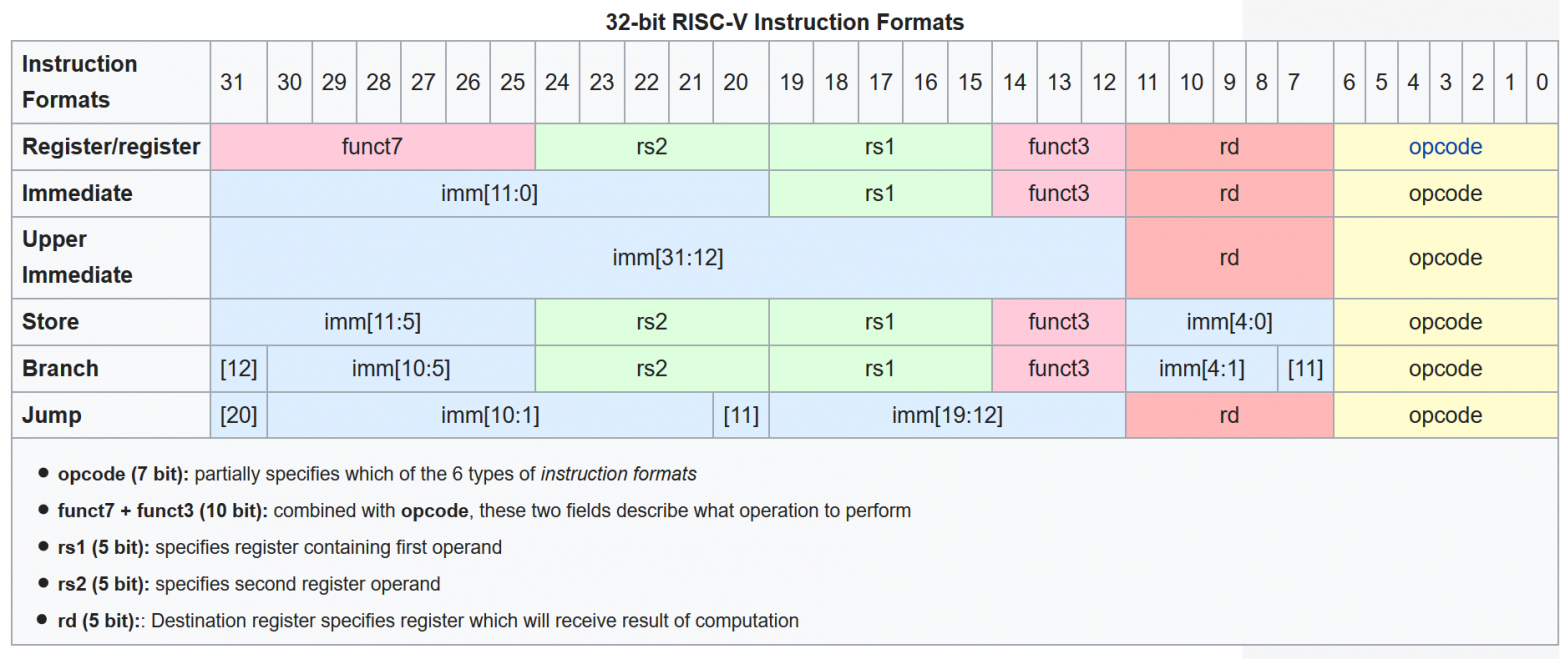
Позвольте мне немного объяснить. Например, регистр rd находится в одних и тех же битах, с 7-го по 11-й. Следующий аргумент rs1 появляется в одинаковых локациях в каждом случае.
Псевдоинструкции
Вы можете заметить, что многие команды RISC-V не принимают три аргумента, но многие из них являются псевдоинструкциями. Это означает, что они являются сокращениями для других инструкций.
Например, рассмотрим инструкцию NEG:
NEG x2, x4
Она берёт содержимое x4 , и помещает отрицательное значение в x2. На самом деле записывается исходное значение в дополнительном коде. Давайте посмотрим, какую инструкцию представляет NEG :
SUB x2, zero, x4 # x2 ← zero - x4
Сейчас вы можете видеть некоторые преимущества использования регистра "zero", он упрощает создание множества таких псевдоинструкций.
К сожалению, наш симулятор не поддерживает многие из таких псевдоинструкций, и вы будете должны записывать их в полной форме.
Дополнение двух и дополнение 10
Чтобы объяснить, как представлены отрицательные числа в двоичной форме, будет полезно сделать это с десятичными числами и рассмотреть сначала дополнение до 10.
Компьютеры работают с числами фиксированной длины. Пусть у нас есть десятичный компьютер, в котором регистры работают с двузначными десятичными числами. Посмотрим на следующее вычисление:
10 - 12 = 98
Как мы получили такое? Посмотрим более детально:
carry 11 --------- 10 -12 --------- 98
Мы сделали заём из позиции сотен, но у нас нет позиции сотен. Следовательно, мы должны сделать заворачивание результата.
Но мы можем использовать это для представления отрицательных чисел. Это означает, что 99 будет означать -1, 98 будет означать -2 и т.д. Мы можем показать, как это работает последовательно:
10 + (-2) = 8 10 + 98 = 108 # Remove first digit and we have 8 50 + (-50) = 0 50 + 50 = 100 # Remove first and we got 0
Дополнение двух работает в точности так же для бинарных чисел. Для четырёхбитных чисел 1111 будет означать -1, 1110 будет означать -2 и т.д.
Загрузка и сохранение данных
Чтобы загрузить данные из памяти в регистры или сохранить данные из регистров в память, мы используем инструкции L and S . Вам нужно использовать разные суффиксы для индикации тго, что мы загружаем:
LB- Load Byte.LW- Load Word.SB- Store Byte.SW- Store Word.
В RISC-V слово (word) означает 32 бита, а байт, очевидно, означает 8 бит. Такие инструкции принимают три операнда, в которых третий операнд является константным значением. Оно закодировано непосредственно в инструкции, а не хранится в памяти и в регистре.
Некоторые примеры использования:
LW x2, 2(x0) # x2 ← [2], load contents at address 2 LW x3, 4(x2) # x3 ← [4 + x2], load content of addr 4 + x2 SW x1, 8(x0) # x1 → [8], store x1 at addr 8
Адреса, переходы и метки
Для программы RISC-V мы знаем, что все инструкции занимают 32 бита. Это 4 байта. Таким образом, первая инструкция будет по адресу 0, вторая по адресу 4, третья по адресу 8, и т.д.
Давайте напишем первую программу, с адресами в первой колонке, чтобы показать, как работают переходы. Вначале поясним, как работают переходы.
Микропроцессор знает, какую инструкцию выполнить следующей, так как он имеет специальный регистр счётчика команд Program Counter (PC). Он содержит адрес следующей инструкции для выполнения. Так как каждая инструкция имеет длину 4 байта, регистр РС инкрементируется на 4 каждый раз.
Рассмотрим пример:
BEQ x2, x4, 12
Инструкция BEQ выполняет переход (branch), если регистры равны (EQual). Если x2 = x4 , счётчик команд (PC) будет увеличен:
PC ← PC + 12
Это означает сдвиг вперёд на три инструкции. Это означает, что мы пропускаем следующие две инструкции. Давайте посмотрим на программу обратного отсчёта. Первая колонка содержит адрес инструкции:
00: ADDI x2, zero, 1 # x2 ← 0 + 1 04: SUB x1, x1, x2 # x1 ← x1 - 1 08: SW x1, 4(zero) # x1 → [4 + 0] 12: BLT zero, x1, -8 # 0 < x1 => PC ← PC - 8 = 4 16: HLT # Halt, stop execution
Вы можете скопировать это в симулятор без колонки адреса. Здесь вы видите, что переход относительный. В строке 12 мы проверяем, что x1 по-прежнему больше, чем ноль, чтобы решить, должны ли мы продолжать обратный отсчёт. Если мы хотим перейти на строку 04, где используется SUB для вычитания 1 из x1. Однако, мы не пишем BLT zero, x1, 4. Вместо этого мы пишем -8. Это происходит потому, что переходы относительны. Мы переходим на две инструкции назад.
Это на самом деле очень практично, потому что это означает, что мы можем переместить нашу программу в другую локацию в памяти, и она по-прежнему будет работать. Однако более важно, что это экономит кучу места. Вам хватит 32 бит для кодирования инструкции:
Каждый регистр требует 5 бит для кодирования, и переход требует два регистра, которые съедают 10 бит.
Опкод съедает 10 бит.
Остаётся 12 бит для того, чтобы определить адрес перехода. Максимальное число, которое можно закодировать в 12 битах, это 4096 (2¹²). Если ваша программа больше, вы не можете сделать переход.
С относительной адресацией переход не является проблемой Вы можете выполнить переход на 2048 байт вперёд или назад в программе. Большая часть переходов и циклов (for, while, if) не будут больше этого.
Однако есть одна проблема с относительной адресацией. Она неудобна для записи программистом. Нас спасут метки:
ADDI x2, x0, 1 loop: SUB x1, x1, x2 SW x1, 4(x0) BLT x0, x1, loop
Вы можете просто присвоить метку локации, на которую вы хотите сделать переход. Здесь мы используем метку loop. Используем двоеточие для того, чтобы показать, что это метка. Ассемблер будет использовать метку для вычисления смещения, необходимого для перехода к этой метке. Различные смещения будут вычислены в зависимости от того, какая инструкция использует метку.
Давайте посмотрим на разные типы переходов. Инструкция, которая выполняет безусловный переход, начинается с J (Jump). Условные переходы начинаются с B (Branch).
Условный переход
Для условного перехода мы составляем мнемонику из B и двух- или трёхбуквенных комбинаций, описывающих условия, такие как:
EQ= EQual.NE≠ Not Equal.LT< Less Than.GE≥ Greater or Equal.
Посмотрим на несколько инструкций и на то, как они транслируются:
BEQ x2, x4, offset # x2 = x4 => PC ← PC + offset BNE x2, x4, offset # x2 ≠ x4 => PC ← PC + offset BLT x2, x4, offset # x2 < x4 => PC ← PC + offset BGE x2, x4, offset # x2 ≥ x4 => PC ← PC + offset
Безусловные переходы
Часто нам нужно выполнять переходы без проверки условия. Примеры:
Вызов функции. Он включает в себя установку значений регистров аргументов функции и выполнение безусловного перехода в локацию памяти, где расположена функция.
Возврат из функции. Когда мы выполняем код функции, вам нужно возвратиться к инструкции, следующей за инструкцией вызова.
Часто вам нужно просто сделать безусловный переход, чтобы обработать различные условные переходы.
Переход и связывание (Jump and Link — JAL)
Инструкция JAL может быть использована как для вызова функций, так и для простого безусловного перехода.
JAL выполняет относительный переход (относительный к PC), так же как и условный переход. Однако регистр в аргументах используется не для сравнения, а для сохранения адреса возврата. Если вы не хотите сохранять адрес возврата, вы можете просто передать регистр zero (x0).
JAL rd, offset # rd ← PC + 4, PC ← PC + offset
Соглашение, используемое в RISC-V таково, что адрес возврата должен быть сохранён с адресом возврата ra ( x1). Скажем, у вас есть код на С, в котором происходит такой вызов:
foobar(2, 3)
В ассемблере это будет выглядеть так:
ADDI a0, zero, 2 ADDI a1, zero, 3 JAL ra, foobar
Почему в RISC-V делается такой упор на относительные переходы? В ранних CPU переходы обычно происходили по абсолютным адресам. Причина в современных операционных системах, в которых нам нужно перемещать код в памяти. Относительный переход будет работать всегда, вне зависимости от того, где в памяти расположен код.
Регистр перехода и связывания (Jump and Link Register — JALR)
Это та же инструкция, но с той разницей, что мы используем смещение относительно регистра? В чём в ней смысл?
Инструкция JAL не имеет достаточного места для кодирования полного 32-битного адреса. Это означает, что вы не можете сделать переход куда-либо в коде, если ваша программа больше максимального значения смещения. Но если адрес перехода хранится в регистре, вы можете сделать переход на любой адрес.
В остальном JALR работает так же, как JAL. Адрес возврата также сохраняется в rd.
JALR rd, offset(rs1) # rd ← PC + 4, PC ← rs1 + offset
Большая разница состоит в том, что переход JALR не происходит относительно PC. Вместо этого он происходит относительно rs1 .
Хотя мы можем использовать обычную команду ADDI для установки значения регистра rs1 , это непрактично. Мы хотим, чтобы адрес был относителен к программному счётчику (РС). К счастью, у нас есть специальная инструкция AUIPC , что означает Add Upper Immediate to PC (добавить константу к старшим битам РС).
AUIPC rd, immediate # rd ← PC + immediate[31:12] << 12
Объяснение может быть трудно для чтения, но это означает, что мы сохраняем старшие 20 бит смещения до некоторой метки в верхние 20 бит регистра rd.
Смещение JALR может быть шириной 12 бит, и вместе мы получаем (20 + 12 = 32), что даёт нам 32-битный адрес. JAL использует 20-битный адрес, и если вам нужно вызвать функциюfoobar , мы используем комбинациюAUIPC и JALR таким образом:
ADDI a0, zero, 2 # Set first argument to function ADDI a1, zero, 3 # Set second argument. AUIPC t0, foobar # Store upper 20-bits address of foobar JALR ra, foobar(t0)
Примеры кода для следующего раза
В моей следующей статье мы выполним некоторые упражнения: RISC-V Assembly Code Examples.

