Собрались однажды 2 разработчика. И нужно было им новую HTTP API реализовать для игрового магазина. Дошло дело до выбора БД, которую стоит применить в проекте:
- Слушай, а как мы выберем? Реляционную БД использовать или NoSQL. В частности, может нужна документоориентированная?
- Сперва нужно понять какие данные будут в нашей предметной области!
- Да, вот я уже набросал схемку:

Для построения каталога нам потребуются все данные… У каждой игры свой каталог, отличать будем по game_id.
- Выглядит так, что у нас уже есть четко описанная структурированная модель, да и опыт использования MySQL есть в компании. Предлагаю использовать его!
И реализовали разработчики успешно свою задумку. Аккуратно нормализовали данные, использовали ORM для работы с БД из приложения. Написали красивый и аккуратный код.
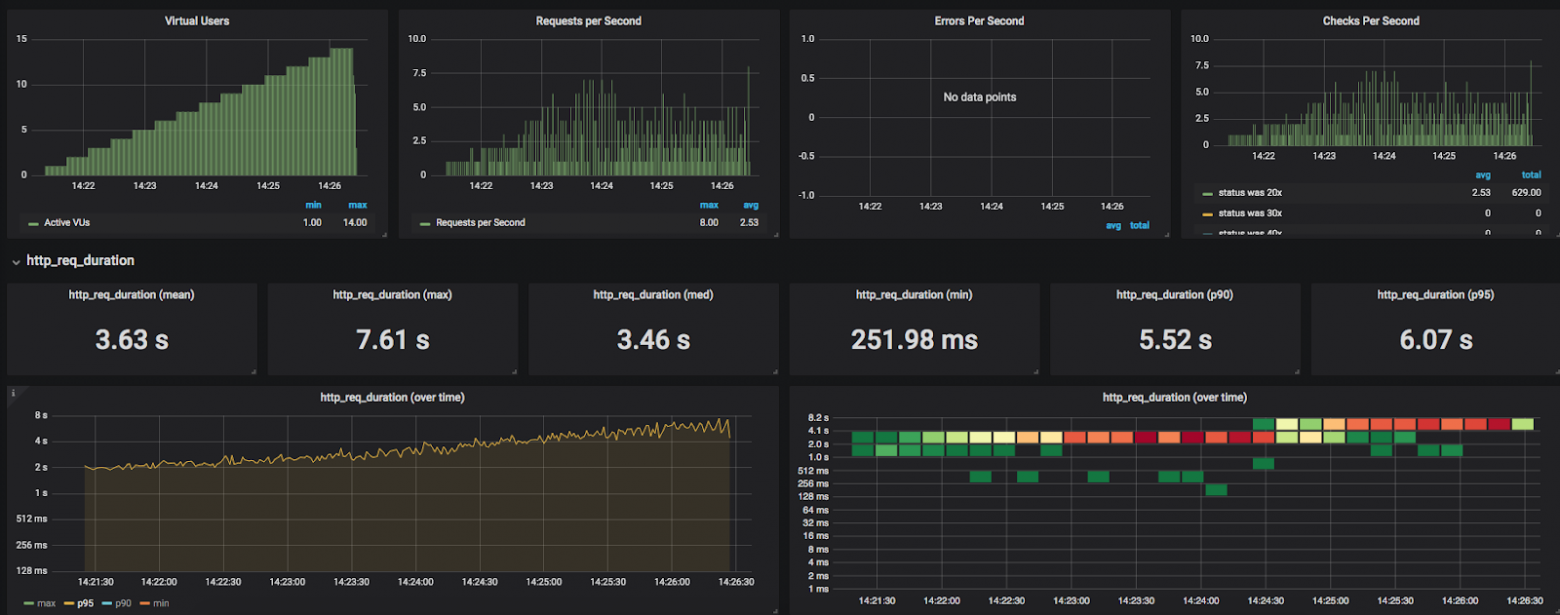
Начали интегрироваться партнеры, и тут начались проблемы… Оказывается, API работает очень медленно и совсем не держит нагрузки! Масштабирование дает смехотворный прирост, подключение кэшей всевозможных уровней дает профит, но зависимость запросов от параметров пользователей (сегментирование и атрибутирование) снижают его практически до ноля.
Корнем проблемы являлось большое (очень) количество запросов к БД - на каждое отношение между сущностями ORM генерировала дополнительный запрос.
Разработчики опустили руки и приуныли. Что же делать? Повезло им, ведь нашли они мудрость, увековеченную на бумажном носителе (милая книга с кабанчиком от Клеппмана).
А книга и порекомендовала еще раз внимательно взглянуть на свою предметную область... Ведь отношения между сущностями образуют дерево! А дерево можно уместить в одном документе (или представить с помощью одного JSON), что позволит избежать такого количества запросов.
Вооружились идеей разработчики и просто сериализовали сущность в JSON и сложили в 1 столбец MySQL (+ несколько генерируемых столбцов с индексами, для поиска):

95 перцентиль уменьшилась более чем в 3 раза, пропорционально увеличился и выдаваемый rps одного инстанса приложения.
А ведь просто поменяли формат хранимых данных, никак не затрагивая инфраструктуру и конфигурацию приложения…
Какой вывод можно сделать?
Подход “мы всегда так делали” безопаснее в большинстве случаев за счет предыдущего опыта, но может быть неэффективен для новых задач.
Важнее понимать какие концепты помогут достичь требуемого качества, а затем выбирать технологии, реализующие их, нежели просто выбирать между технологиями
Стереотипное мышление вроде “MongoDB для неструктурированных, для структурированных что-нибудь реляционное” или “Ну Redis небезопасный, поэтому не будем там хранить ничего” и т.п. скорее вредно. Зачастую все зависит от реализации приложения и конфигурации сервисов.
