
Задачу генерации текстовых строк по шаблону никак нельзя назвать новой, даже с натяжкой. Сюда можно отнести и заполнение стандартных форм наподобие приходных кассовых ордеров, и экспорт XML/JSON во внешние системы, когда состав данных меняется реже формы их представления. Если основательно задуматься в момент натягивания совы на глобус, то в ту же категорию можно отнести и задачу формирования отчетов, и настраиваемые реализации метода ToString(), и… да много еще чего.
Объединяет эти случаи одно: входными данными являются не только какие-то циферки сами по себе, но и шаблон, на основании которого они должны быть отформатированы для потребителя. Для программистов это удобно тем, что из разработки выкидывается довольно жирный кусок рутины, который можно перепоручить кому попало другим отделам. Для пользователей тоже хорошо, так как позволяет творить всякую фигню и настраивать продукт под себя (что бы это ни значило). Ну и совсем уж замечательно становится, когда внезапные изменения внешнего вида документов, придуманные затейниками из Минфина, не требуют внепланового деплоя новой версии продукта, а всего лишь элегантной правки шаблона.
В общем, оставим сову в покое и признаем, что в некоторых случаях шаблоны – это хорошо. А вот что нам может предложить .NET для того, чтобы воспользоваться преимуществами этой идеи?
Широко известные T4 и Source Generators – это, конечно, замечательно, но работают они в момент компиляции, что нас не устраивает по определению. Более детальная эксплуатация гугла показывает, что template engines, в принципе, есть, но все они обладают фатальным недостатком. А потому попробуем разработать что-нибудь свое. Так и назовем – One More Template Transformer – или, сокращенно, Omtt.
Основные идеи
Шаблон
Предполагается, что шаблон – это просто строка некоторого не слишком большого размера, которая будет чаще использоваться, чем изменяться. Важно ли знать формат шаблона? На первый взгляд кажется, что нет. На второй – тоже. А затем вспоминается, что для того же Html хорошо бы некоторые символы экранировать. Запомним.
Исходные данные
Подумаем теперь про сами данные. Требовать их предоставления в каком-то специальном виде было бы не слишком гуманно для пользователей Omtt. А вот передача самого обычного CLR объекта, содержащего нужные свойства, выглядит рабочей идеей.
Сам объект, равно как и его свойства, может быть некоторым элементарным типом, классом со своим собственным набором свойств, а то и вообще коллекцией. Отсюда следует сразу пара выводов:
Во-первых, необходим механизм навигации по графу объектов. Синтаксис следующего вида вполне привычен, поэтому и возьмем его за основу:
this.SomeChild.SomeCollection[12].SomeProperty
Во-вторых, объем преобразуемых шаблоном данных, с учетом поддержки коллекций, может оказаться весьма большим, поэтому на входе нас обязан спасать IEnumerable, а на выходе Stream – таким образом мы сможем минимизировать количество информации в оперативной памяти в любой момент времени.
Интересный момент - а откуда брать эти самые исходные данные в программе? В простейшем случае - структура классов прибита гвоздями и хорошо документирована для пользователя. А что, если большая часть этих данных пользователю не нужна? Или, например, нужно что-то немножко другое? И вообще, для кого люди старались, придумывая всякие SQL'ы и GraphQL'ы?
Все это к тому, что было бы полезно уметь не только генерировать по шаблону результат, но и схему данных, которая в этом шаблоне используется.
Разметка
В принципе, любая строка может являться шаблоном, который, в вырожденном случае, просто порождает сам себя. Но что делает идею по-настоящему полезной – это управляющие конструкции, преобразующие исходные данные в результат.
Рассмотрим, например, циклы, где для каждого объекта из входного списка мы хотим сгенерировать некоторый под-шаблон. Получается, что разметка должна содержать четыре основные части:
управляющие символы, сигнализирующие о начале и конце элемента разметки,
команду – что мы хотим сделать,
входные параметры – какие данные мы этой команде передаем,
внутренний шаблон – указания команде, как форматировать свой результат.
В результате получается вот такой синтаксис:
<#<operation attr1="expr1" attr2="expr2"... attrN="exprN">inner template#>
<#и#>сообщают об открытии и закрытии элемента разметки,operation– является именем операции, например,forEach,attr="expr"– говорит о том, что параметру операции по имени "attr" присваивается некоторое выражение "expr",inner template– представляет собой вложенный шаблон, формируемый по общим правилам. Таким образом появляется возможность создавать размеченные документы с любым уровнем вложенности.
Разметка операции вывода
Синтаксис разметки получился логичным, и не сказать, чтобы очень многословным. Но что, если попробовать использовать его для максимально частой операции – для вывода текста?
<#<write source="this.Amount" format="F2" culture="ru" align="10">#>
Здесь мы хотим вывести значение свойства Amount переданного объекта, отформатировав его 2 разрядами после запятой, используя российскую CultureInfo и размещая в поле из 10 символов с выравниванием по правому краю.
Сложно. Очень сложно. А что, если перенять основную идеологическую фишку C# последних лет и добавить щепотку синтаксического сахара? Например, так:
{{this.Amount|F2|ru|10}}
Двойные фигурные скобки – это, собственно, синтаксический сахар и есть. А четыре выражения в них – это как раз все перечисленные выше параметры операции. Естественно, их можно опускать. Так, например, валиден и вот такой вывод, не подразумевающий никакого форматирования вовсе:
{{this.Amount}}
Стало лучше? Кажется, да. Но остался вопрос – а что же такое выражение?
Выражения
Самый простой и самый необходимый вариант того, что можно назвать выражением – это доступ к свойствам объекта данных. Вот такая строчка, напомню:
this.SomeChild.SomeCollection[12].SomeProperty
В принципе, на этом можно было бы и остановиться: управляющий код формирует все необходимые объекты, а шаблон описывает исключительно подстановку этих данных в нужные места.
Опыт подсказывает, что не все так просто: часто требуется, к примеру, показать отдельно цену без НДС, отдельно сам налог, а затем сумму двух предыдущих значений. Конечно, ничего не мешает выполнить элементарное сложение в коде, но этот путь однозначно приведет к переусложнению программы, а это именно то, чего хочется избежать. Так что придется все-таки реализовывать простенькие вычисления внутри выражений, что-то вроде
this.PriceWithoutVAT + this.VAT
Известно ли шаблону заранее, какого типа здесь операнды? Скорее всего – нет, в противном случае появляется довольно много мест для удара головой: начиная от неверно назначенных типов и заканчивая необходимостью объяснения пользователям шаблонов, что же такое тип. А потому – да здравствует динамическая типизация (передаем привет горячо любимому JavaScript).
Следующим шагом в продолжение размышлений над розничной торговлей приходит понимание о необходимости добавления внутренних переменных в механизм выражений – а как иначе посчитать общую сумму чека?
Затем, на всякий случай, хочется добавить условные операторы и блоки выражений, а также что-нибудь еще… Чтобы остановиться вовремя, но не слишком огорчаться минимализму встроенных функций, принимается решение о поддержке пользовательских функций – написанных на C#, но доступных в момент обработки шаблона.
Расширяемость
Расширяемость – штука обоюдоострая. С одной стороны, это техническая победа над нефункциональными требованиями. С другой стороны, это может выглядеть и как признание в собственном бессилии: «вот вам API, делайте что хотите, а я пошел».
При всем этом благородную попытку реализовать встроенные функции для всего и сразу поймут не только лишь все. Интринсики – хороший тому пример (ну, мы же любим их, да?).
Поэтому, проанализировав все за и против, было принято решение ограничиться минимальной комплектацией Omtt по умолчанию; потенциально интересную для широкой публики функциональность вынести в отдельные пакеты (благо NuGet позволяет); ну а специфичные для конкретных проектов вещи оставить в приватных репозиториях.
Что же, собственно, можно расширять?
Во-первых, новые операции разметки.
Например, можно добавить разметку для линковки шаблонов друг с другом. Или операцию для подготовки графиков в векторном формате. Один из примеров, доступных в NuGet, - формирование QR-кода из текста вложенного шаблона.
Во-вторых, пользовательские функции для выражений.
Пользовательская функция – это именованная штука, принимающая N значений выражений на вход в качестве параметров и возвращающая единственное значение на выходе. В качестве примера можно привести функцию преобразования числа в сумму прописью. Или получение текущей даты-времени.
В-третьих, самую важную функцию write для вывода текста.
Подкручивать её можно с разных сторон – добавляя новые варианты форматирования, экранирования символов (вот тут нам пригодилось это знание!), а то и поддержку пользовательских типов данных.
Технические детали
С точки зрения реализации Omtt особых сложностей не вызвал, но на нескольких пунктах остановлюсь подробнее.
Парсинг шаблонов
Поскольку предложенный синтаксис шаблонов оказался не слишком сложным, было принято решение не напрягать тот же ANTLR, а написать разбор текста самостоятельно. Классическая схема с лексическим и синтаксическим анализаторами подошла как нельзя лучше.
Напомню, что представляют собой обе стадии.
Допустим, нам нужно разобрать строку
5 * 9 + x
Лексический анализ преобразует строку в набор токенов:
ЛИТЕРАЛ 5
УМНОЖИТЬ
ЛИТЕРАЛ 9
ПЛЮС
ИМЯ “x”
Этот набор токенов передается в синтаксический анализатор для построения дерева выражения:
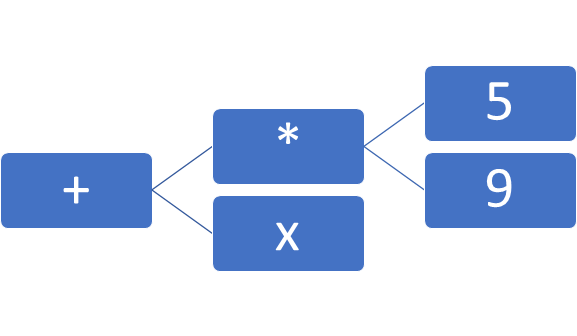
При этом упростить задачу (или немножко сжульничать – тут как посмотреть) позволила разработка раздельных анализаторов для синтаксиса разметки и выражений.
Доступ к свойствам объектов
Обращение к свойствам переданных объектов данных – это одна из основных задач шаблонного генератора. Для её решения можно по старинке использовать reflection.
А можно собрать Expression, откомпилировать его и затем долго и упорно использовать:
private static Object? GetPropertyValueExpr(Object obj, String propertyName) { return PropertyFuncCache.GetOrAdd((obj.GetType(), propertyName), tuple => { var parameterExpression = Expression.Parameter(typeof(Object)); var objectExpression = Expression.Convert(parameterExpression, tuple.Item1); var propertyExpression = Expression.PropertyOrField(objectExpression, tuple.Item2); var resultExpression = Expression.Convert(propertyExpression, typeof(Object)); var expr = Expression.Lambda<Func<Object, Object>>(resultExpression, parameterExpression); return expr.Compile(); })(obj); }
Разница по производительности, по крайней мере в процентах, получается довольно значительная:
Method | Mean | Error | StdDev |
OmttReflectionTest | 3.963 us | 0.0501 us | 0.0444 us |
OmttExpressionTest | 2.814 us | 0.0278 us | 0.0232 us |
Еще есть немножечко сумасшедшая идея перетащить в такие компилируемые выражения большую часть вычислений, что позволит избежать совершенно не нужного во многих случаях боксинга.
Арифметические операции
Как ни странно, самым быстрым способом выполнить арифметические операции для стандартных типов оказался метод «в лоб»:
private static Object ProcessPlus(Object? current, Object? second) { if (current is String strValue) return strValue + second; if (current is Int32 int32Value) return int32Value + Convert.ToInt32(second); … }
Вариант с использованием dynamic получился хоть и лаконичнее, но несколько медленнее приведенного выше примера на миксе из Int32, Double и Decimal типов:
private static Object ProcessPlus(dynamic? current, dynamic? second) { return current + second; }
Method | Mean | Error | StdDev |
IfExpressionTest | 2.468 us | 0.0149 us | 0.0132 us |
DynExpressionTest | 2.644 us | 0.0314 us | 0.0278 us |
Ну и раз уж мы за скорость, оставим некрасивый первый вариант. При этом очень хочется поддержать перегрузку операций для пользовательских типов. Это тоже можно, достаточно воспользоваться стандартными именами перегруженных операторов: op_Addition, op_Subtraction, op_Multiply, op_Division.
Что касается операторов сравнения, с ними еще проще – достаточно привести объект к типу IComparable. Если же это не получается, можно схитрить и сравнить строковые представления объектов, прикрываясь тем, что результатом-то обработки шаблона все равно является строка.
Примеры
Все вышеописанное, конечно, хорошо, но как выглядит результат?
Обычные
Простой пример, пример, показывающий возможность форматирования:
var generator = TemplateTransformer.Create("{{this.Id|D3}}, {{this.FamilyName|u}}, {{this.Name}}"); var result = await generator.GenerateTextAsync(new {Id = 7, Name = "James", FamilyName = "Bond"}); Assert.AreEqual("007, BOND, James", result);
Тоже не очень сложный образец кода, демонстрирующий обращение к полям объекта:
var generator = TemplateTransformer.Create("Hello, {{this.A.Name}} and {{this.B.Name}}!"); var result = await generator.GenerateTextAsync(new {A = new {Id = 1, Name = "Alice"}, B = new {Id = 2, Name = "Bob"}}); Assert.AreEqual("Hello, Alice and Bob!", result);
Вариант с циклом выглядит позабористее:
var generator = TemplateTransformer.Create( "Hello, <#<forEach source=\"this\">{{this.Name}}<#<if clause=\"!$last\"> and #>#>!" ); var result = await generator.GenerateTextAsync(new[] {new {Name = "Alice"}, new {Name = "Bob"}}); Assert.AreEqual("Hello, Alice and Bob!", result);
Он показывает сразу несколько особенностей:
В-нулевых, синтаксис операций разметки для цикла и для условия.
Во-первых, то, что this – контекстуальный: внутри цикла по this возвращается текущий итерируемый элемент. Для получения основного объекта нужно использовать ключевое слово parent.
Во-вторых, сервисные переменные: $last – булев флаг, говорящий о том, является ли текущий элемент цикла последним ($first – соответственно, первым).
Если пример выглядит довольно просто, то вот шаблон для таблицы умножения, содержащий уже вложенные циклы:
var generator = TemplateTransformer.Create( "<#<forEach source=\"this\"><#<forEach source=\"parent\">{{this*parent|||3}}#>\r\n#>" ); var result = await generator.GenerateTextAsync(Enumerable.Range(1, 5)); Assert.AreEqual( " 1 2 3 4 5\r\n" + " 2 4 6 8 10\r\n" + " 3 6 9 12 15\r\n" + " 4 8 12 16 20\r\n" + " 5 10 15 20 25", result);
QR
В качестве примера расширения функциональности можно рассмотреть операцию разметки, преобразующую вложенный шаблон в QR-код. Поскольку данная функция является внешней, её перед использованием необходимо зарегистрировать.
var generator = TemplateTransformer.Create(@"<!DOCTYPE html> <html> <head> <meta http-equiv=""content-type"" content=""text/html; charset=UTF-8""> <title>Test</title> </head> <body> <#<fragment type=""'html'""><#<qr>Hello, {{this}}!#>#> </body> </html>"); generator.WithQr(); var result = await generator.GenerateTextAsync("Habr"); await File.WriteAllTextAsync("qr.html", result);

Генерация схемы данных
Эта фича, не являющаяся основной, на самом деле моя любимая. При правильной обвязке Omtt её можно использовать для автоматического запроса данных, нужных шаблону, посредством SQL или GraphQL. А выглядит использование фичи так:
var generator = TemplateTransformer.Create( "<#<forEach source=\"this.ClassesB\"> {{parent.Str}} {{this.MyInt1 + this.MyInt2}}" + "<#<forEach source=\"this.Decimals\"> {{parent.parent.Str}} {{this}}#>#>"); var dataStructure = await generator.GetSourceSchemeAsync(); Assert.AreEqual( " { ClassesB[] { Decimals[], MyInt1, MyInt2 }, Str }", dataStructure.ToString());
В результате мы видим и иерархию классов относительно this, и запрашиваемые свойства, и даже признак того, является ли свойство коллекцией (то есть участвует ли оно в операциях типа forEach).
Сравнение с существующими решениями
Одним из идеологически схожих продуктов является Scriban, который, как утверждается создателями, весьма шустрый: https://github.com/scriban/scriban/blob/master/doc/benchmarks.md
Поэтому со Scriban и сравним производительность, заодно позаимствовав тестовые примеры. Исходный код бенчмарков есть в репозитории.
Парсинг
Несмотря на то, что парсинг шаблонов видится довольно редкой операцией по сравнению с генерацией, было бы интересно понять, а стоил ли того ручной синтаксический разбор.
Method | Mean | Error | StdDev | Allocated |
OmttParsingTest | 3.377 us | 0.0481 us | 0.0450 us | 6 KB |
ScribanParsingTest | 10.795 us | 0.1344 us | 0.1258 us | 6 KB |
Трехкратная разница в производительности подсказывает, что да, стоил. По крайней мере, это было интересно, а за результат не стыдно.
Арифметика
Следующий несложный тест должен показать, насколько хорошо Omtt справляется с вычислениями. Все-таки ручная интерпретация выражений, не самый аккуратный вид соответствующих методов, повсеместный боксинг…
Method | Mean | Error | StdDev | Allocated |
OmttExpressionTest | 2.422 us | 0.0115 us | 0.0090 us | 6 KB |
ScribanExpressionTest | 28.735 us | 0.5337 us | 0.4731 us | 39 KB |
Десятикратный отрыв от конкурента по производительности и шестикратный по памяти все-таки немножко успокаивают.
Циклы
Следующее, что хочется проверить – как Omtt справляется с обработкой циклов. И вот здесь со Scriban нашлись довольно существенные различия (либо я чего-то не понял):
Во-первых, нельзя просто так взять и передать список объектов в Scriban для итерации; для этого нужно конвертировать каждый объект в экземпляр типа ScriptObject.
Во-вторых, передать можно максимум 1000 объектов, иначе Scriban ругается.
Ну что ж, выполним замеры с данными ограничениями:
Method | Mean | Error | StdDev | Allocated |
OmttListTest | 859.1 us | 8.06 us | 7.14 us | 332 KB |
ScribanListTest | 2,205.7 us | 5.46 us | 4.84 us | 195 KB |
Видим, что тесты присуждают Omtt двухкратную победу по скорости (даже при вынесенном за рамки теста преобразовании данных для Scriban), при этом ситуация по памяти несколько хуже. Скорее всего, разница обусловлена тем, что Omtt в тесте пишет в MemoryStream с использованием StreamWriter, таким образом выделение буферов в обоих классах и дает такую аллокацию памяти. При этом Scriban пишет только в StringBuilder, что в данном случае чуть экономичнее, но подразумевает, что весь текст всегда обязан помещаться в оперативной памяти.
Если же совместить преобразование данных и генерацию текста, то позиция Scriban по потребляемой памяти также начинает пошатываться:
ScribanListWithPreparationTest | 2,402.4 us | 14.83 us | 13.87 us | 534 KB |
Выводы
Начавшись как простой эксперимент из чистого любопытства, Omtt в настоящий момент используется в продакшене в двух проектах.
При этом он показывает неплохие характеристики по производительности и потреблению памяти, а также обладает умеренно-человечным синтаксисом шаблонов. Не стоит забывать и о возможностях расширения как разметки, так и выражений. Вишенка на торте - функция получения схемы данных, которая позволяет использующему Omtt коду извлекать те, и только те данные, которые нужны шаблону.
В качестве целевой платформы выбран netstandard 2.0, поэтому Omtt заведется как для .NET Framework, так и для .NET Core.
Проект выложен на GitHub, в собранном виде присутствует в NuGet.

