
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
Давайте выбросим MS Excel (далее с вашего позволения просто - "эксель") и начнем работать на Python
Это же всегда так, сначала "дед мороза не существует", потом оказывается "на ноль делить можно", ну а дальше по накатанной "забудьте чему вас учили в школе" :D
Вот пока вы занимаетесь этим анализом один и никто к вам не лезет - вы можете хоть на чем угодно это делать. Отчеты выдаются, начальник доволен.
Но, предположим, вы увольняетесь. И вместо вас приходит другой человек, который должен быстро все после вас разгрести и делать то же самое. Сможет он это все понять на куче скриптов из VBA в куче Excel-файлов? Ну удачи ему.
Или, более оптимистичный сценарий - у вас работы по горло и вы просите помощника. Вам его дают и у вас встает вопрос об использовании этих файлов вдвоем - кто-то что-то поправил в расшаренном файлике, а другой это затер. Или не понял как это использовать.
Если не дают ничем пользоваться кроме Excel... Ну я бы не стал это терпеть, например..
// Кстати, я случайно поставил статье плюс, хотя хотел минус
Версионирование кода? Нет, зачем, пусть лежит в xls-файле на шаре. (sarcasm)
А уж какой простор для новых требований...
Поступило требование формировать отчет и отправлять письмом? Сделаем на Excel, конечно же. (sarcasm)
Надо отправлять этот отчет каждый день в 6 утра? Напишем еще велосипед! (sarcasm)
Надо хранить отчет в базе и выдавать сторонним клиентам через API с фильтрами? О-о! Вот это простор для Excel! (sarcasm)
(все кейсы выше взяты из реальной жизни, изначально заказчик не упоминал о них при заказе отчетов)
Версионирование кода? Нет, зачем, пусть лежит в xls-файле на шаре. (sarcasm)
Экселька прекрасно загружает модули/код из текстовых файлов которые вы можете версионизировать.
Ок, согласен. А вы так делаете?
Много из вышеперечисленного решается так или иначе велосипедом под названием VBA
Ну понятно, можно и мультики рисовать в Excel. Можно? Можно. Нужно? Эмм....
Вы просто не умеете это готовить
Ой, все (с).
Экселька прекрасно загружает модули/код из текстовых файлов которые вы можете версионизировать.
А что делать с процедурами загрузки? Выносим за скобки? В общем, когда я увижу вашу библиотеку на github.com, тогда и продолжим разговор.
А, кстати, что насчет unit и всяких прочих тестов? CI/CD? Linux environment?
Как говорится - главное не размер, а умение пользоваться)
Я себе на связке Excel+MS SQL сделал свой гитхаб с версиями и автообновлением файлов)
Так что это совсем не проблема.
При этом весь бэкенд на sql, а фронт - на Excel.
Так же совсем не проблема отправлять письма из Экселя и даже звонить)
То есть как инструмент для модифицирования данных пользователем Эксель очень даже ничего. И главный плюс - скорость разработки.
Конечно он не панацея и технологии не стоят на месте, в отличии от VBA, но у меня тоже подгорает, когда кто то необоснованно пренебрежительно говорит об этом мегакомбайне )
xls файлы — это просто XML. Он прекрасно хранится в git.
Сначала надо распаковать. После любого мелкого изменения в GUI в XLS будет столько правок, что фиг поймешь и найдешь (в GUI), что там на самом деле поменялось.
Для формирования отчетов ничего лучше excel не придумать — делаем шаблон с нужными графиками и таблицами,
LaTEX прозрачнее и мультиплатформеннее. Графики и диаграммы - ну перенесите визуальые стили из одного XLS-файла в другой... Если нужна защита от копирования, чтобы документ можно было посмотреть только на корпоративном ноутбуке (с опциональным запретом печати), находящемся в корпоративной сети, то для PDF решения есть. А для XLS?
макросом подставляем в него данные — и вот у вас красивый документ.
Документы с макросами не отрываю. Или в виртуальной машине.
Когда появился эксель, мне сказали: "выбрось свои awk и прочие юниксовые утилиты". Я их естественно не выбросил. Но зато подготовив данные можно загнать их в эксель и получить графики, с минимальными затратами времени. Всякому инструменту своё применение.
Однако на постоянной основе так делать отчёты, или что-либо другое, - это маразм. Чтобы не заниматься этим маразмом, нужно действительно либо кодить либо юзать BI, как это и практикуется.
Словом я бы речь вел за MS Office, а не за один только Excel.
За умение использовать.
Нас в универе прокачивали на "табличных процессорах" (так это тогда в курсе называли) заставляя на "зачёт" писать игры в них: тетрис, змейка, жизнь...
но, для реальной задачи в жизни я все таки выбрал для автоматизации финотчетов веб-приложение с импортом в mysql + sql + php
и всюду вижу, что весь набор от MS этакий супер комбайн с огромным потенциалом, но этот потенциал никто не хочет пользовать. Как калькулятор пользуют. То ли не разъясняют назначение, то ли привычка с ворованных/халявных копий. Как фотошоп для просмотра картинок. В этом отношении, у Apple их офисный пакет лучше спозиционирован
Мне довелось много поработать и с экселем и с аксессом. Хорошие инструменты, но полные детских болячек, которые уже десятилетиями никто не собирается лечить.
Достаточно серьезные баги, которые я встречал в экселе и в аксессе 15 лет назад живы и сейчас. В аксессе "портятся" запросы, если таблица, на которую ссылается запрос залинкована из эксельки или другой мдбшки на сетевой папке, которая в данный момент недоступна. Т.е. упала сеть а ты в это время открыл запрос, он сломался. Сеть появилась снова, а запрос так и остался сломанным - круто же!
Ну или откройте в аксессе таблицу с миллионом записей, поставьте фильтр, чтобы осталось только 10 записей, а теперь отсортируйте эти 10 записей по возрастанию. Пока он сортирует можете пойти чайку попить.
А в Экселе я видел файл в котором больше 20 вкладок, на каждой вкладке сотни формул, они все ссылаются друг на друга, при этом все корректно сделано, ссылки все правильные, формулы правильные, но эксельку просто глючит от того, что она слишком большая и с какого то количества формул там в результате расчета начинается дичь.
А так действительно инструменты удобные, починили бы детские болезни, вообще было бы круто.
Т.е. упала сеть а ты в это время открыл запрос, он сломался. Сеть появилась снова, а запрос так и остался сломанным - круто же!
Справедливости ради, я могу написать код на десятке языков программирования, который поведет себя так же.
больше 20 вкладок, на каждой вкладке сотни формул, они все ссылаются друг на друга
А вот это да, реальная жесть. Особенно когда есть ссылки на внешние файлы и именованные области, тебе прислали (только один) файл по почте, а у тебя оказался только LibreOffice. Разбирайся как хочешь.
Достаточно серьезные баги, которые я встречал в экселе и в аксессе 15 лет назад живы и сейчас.
Имхо, Access намеренно кастрировали, чтобы не конкурировал с младшими версиями SQL Server. Например, ограничение на размер файла ну совсем смешное. SQL редактор невозможно убогий - даже подсветки нет. И у меня там иногда Copy/Paste переставал работать...
В последнее время раздражало то, что для того, чтобы соединить несколько ячеек в одну строку, надо либо через "&" указывать ячейки, либо использовать СЦЕПИТЬ() где тоже нужно указывать каждую ячейку. Варианта функции, чтобы указать диапазон (как в СУММ()), нет. Пришлось писать самому.
А в Экселе я видел файл в котором больше 20 вкладок, на каждой вкладке сотни формул, они все ссылаются друг на друга, при этом все корректно сделано, ссылки все правильные, формулы правильные, но эксельку просто глючит от того, что она слишком большая и с какого то количества формул там в результате расчета начинается дичь.
Это у меня стандартная ситуация, excel действительно подглючивает на итеративных вычислениях. Но решается просто: отключается автоматический пересчет листов, хотя он у меня и так всегда отключен, и небольшой скрипт, который пересчитывает листы в нужной последовательности.
А то, что Excell на русском не понимает формулы на английском и наоборот — делает бесполезным использование формул в международных компаниях.
Особенно бесит, самопроизвольно упёртое преобразование в дату, того что датой не является.
Особенно бесит, самопроизвольно упёртое преобразование в дату, того что датой не является.
Больше всего бесит, что они знают, что это больно, но принципиально выступают за дальнейшее причинение боли:
Microsoft Excel предварительно программируется, чтобы упростить ввод дат. Например, 12/2 изменяется на 2-дек. Это очень неприятно, если вы вводите что-то, что не хотите менять на дату. К сожалению, отключить эту возможность не получится.
Чтобы акцессовские таблицы не глючили нужно выбирать данные через запрос, а уже в нем производить расчеты, сортировки, группировки...
Обрабатывая многомиллионные ежедневные транзакционные данные, нужно было посчитать Scheme Fee (микро платежи в пользу Visa/MasterCard начисляемые по различным параметрам как например — за каждые 1000 платежей по магнитной полоске.....
Имеет право на жизнь в небольших конторах, которые не особо хотят вкладываться в софт. Но когда у вас появляется куча филиалов, сделайте уже нормальную информационную систему, куда будут попадать все необходимые данные и откуда все необходимые отчёты можно будет получить через SQL запросы. Правда есть тут небольшой косяк... Некоторые люди будут сидеть без работы, а значит их ставки можно сократить.
Питон удобнее, чем убогий древний VBA. Одна строчка в Питоне может сделать больше, чем строчка на VBA. Ну, например, list compehension — в VBA такого нету. Следовательно, производительность и удобство работы программиста на Питоне выше.
Также, при редактировании кода на Питон вы можете использовать нормальный редактор, а не встроенный в офис. Код на Питон удобно коммитить в репозиторий.
Код на Питоне может обрабатывать большие объемы данных, чем может поместиться в Excel-таблицу. Документация к Питону лучше.
Следовательно, лучше использовать Питон.
Единственное, Питон медленный, но если ваши данные можно потоково обработать с помощью numpy, то будут задействованы SIMD инструкции и производительность будет высокой.
В тех страховых и финансовых компаниях которых я работал, не существовало возможности установить дополнительно программное обеспечение на компьютер или тонкий клиент.
Эта работа предполагала ручную обработку данных, а вы зачем-то лезете с автоматизацией. Вы устроились на работу, где не приветствуется автоматизация, и пытаетесь этим как-то оправдать использование VBA. Если уж на то пошло, то на такой работе и макросы могли бы запретить — так как через них распространяются вирусы.
Код на Питоне может обрабатывать большие объемы данных, чем может поместиться в Excel-таблицу. Документация к Питону лучше.
Эта работа предполагала ручную обработку данных, а вы зачем-то лезете с автоматизацией.
Одно время мучался с VBA, а потом открыл для себя Power Query, в котором много чего работает сразу из коробки - например собрать инфу из кучи файлов или подружить данные из разных источников. Excel решает)
Ну, VBA вообще возглавляет список самых нелюбимых (? dreadful) языков программирования. И, хотя отказаться от него в ближайшие лет 10 вряд ли получится из-за большого количества скриптов во всех отраслях, но новых фич в нем я бы не советовал ждать. Cobol тоже еще не умер как бы, но...
Работаю с продуктами от OsiSoft и Rockwell Automation, их объектные модели поддерживают автоматизацию VBA (тут питонисты должны слиться).
Иногда приходится иметь дело с их PI-серверами, так пакет win32api дает возможность работать с ними из питона в windows. А можно и из Linux'а через jdbc.
Мне хватило раз по 20 наступить на пару моих любимых граблей с экселем:
Берём вывод из MS SQL Management Studio, где есть даты и копи-пастим в эксель. Чу! Часть строчек выпадает из статистики потому что Студия добавила миллисекунды через точку и Эксель посчитал, что это теперь не дата, а строка. Не беда! Поменяем формат ячейки на строку... Ой - теперь у меня вместо дат какие-то красивые цифры, 4-с-чем-то-тысячи. Надо было сразу в Jupyter сделать pandas.read_clipboard() и не было бы проблем.
Возьмём логи и попробуем вытащить подстроку из сообщений. Ой, НАЙТИ() в случае ненахождения подстроки выдаёт исключение! Не беда, обернём его в местный try-catch и тогда, после пары таких комбинаций, в нашей формуле уже никто и никогда не разберётся. Надо было тоже сразу делать pandas.read_clipboard(), а потом уже можно было str.extract с поиском по регуляркам...
Да, можно всё это делать в VBA, но можно же с тем же успехом использовать и Python? Последний в этом сравнении мне нравится больше, а тут как ни крути, начинается уже вкусовщина.
Эксель до сих пор использую для быстрой фильтрации по заголовку таблицы. Или для рисования графиков. Но какие-то преобразования данных уже давно делаю в питоне - там я получу результат за предсказуемое время, не попадая на неожиданности вроде формата дат или непривычной работы find/charindex/и т.п.
Берём вывод из MS SQL Management Studio, где есть даты и копи-пастим в эксель. Чу! Часть строчек выпадает из статистики потому что Студия добавила миллисекунды через точку и Эксель посчитал, что это теперь не дата, а строка.
Я тут ещё подумал: что ж меня так триггерит каждый раз с этих «апологий эекселя»? И, кажется, я понял: это обманутые ожидания.
Эксель говорит «дружище, давай к нам, я помогу перемолоть эту кучу данных всего парой кликов!» И ты радостно обращаешься к нему, ожидая, что через минуту у тебя уже будет готовый результат. Но через минуту ты ударяешься мизинцем об одну дырявую транзакцию: даты – не то, чем кажутся. Ничего, результат уже на горизонте – но вот новая проблема: у твоей любимой функции из обычных языков программирования не нашлось нужного аналога. Ничего, и это можно перебороть – пишем 3-этажную формулу, вытираем пот со лба – опять что-то работает не так, как ожидал.
Да, понятно, надо знать ограничения инструмента (=уметь им пользоваться). Но у меня глубокое впечатление, что эксель обещает сильно больше, чем потом может исполнить. Оттого и такая обида на этот инструмент.
стандартная проблема, которая появляется через Copy/Paste.
Ну вот Pandas же как-то научился с ней справляться. Ни разу с ним таких проблем не было
Ну, хоть опять портрет Альфа вставляй )
Какой копи-паст? Гражданин программист, Вы о чем?
"Данные" - "Получить данные" - "Из базы данных" - "Из базы данных SQL Server"
Не хотите подключаться к БД?
Сделайте выгрузку и загрузите данные оттуда, с помощью ПоверКвери (есть такая начиная с Эксель 2013). Проверьте форматы.
Не всё в порядке? Зайдите в редактирование запроса и на М-коде поправьте нужный шаг/столбец. Можете даже не думать про М-код - просто пользуйтесь "шагами и кнопочками".
По времени - на 15 сек больше чем копи-паст.
Может быть удивлю, но для любителей загружать в Эксель миллионЫ строк, без ПоверКвери не обойтись. В нем данные можно почистить, отфильтровать, транспонировать в пару кликов, без ненавистного ВБА и без Питона.
Потом, если всё равно строк больше ляма, выгрузить результат в Сводную Таблицу.
Эксель заточен под анализ БД и дашборды. Следующий шаг - ПоверБиАй, который... работает с тем же М-кодом.
Так что, думаю, если про Эксель не только разницу между "А1" и "$А$1", правильный результат можно получить чуть позже, чем моментально.
Какой копи-паст? Гражданин программист, Вы о чем?
Ну надо тогда законодательно копи-паст в эксель запретить)
Я не спорю, если я делаю какую-то витрину, к которой буду возвращаться - тогда и запрос в БД, и PowerQuery. Я же тут говорю про случай, когда хочется ad-hoc, на коленке, что-то быстро подсчитать. И в этом случае (как я писал выше) Эксель обещает справиться быстро, но на практике со всех сторон вылезают ньюансы.
Почитав комментарии видно, что каждый кулик своё болото хватит.
Могу сказать одно, это просто счастье, когда вы можете делать проект на том что хотите вы.
Офис есть везде -и этот факт крайне сложно чем-то перешибить
Ну, на самом деле, и не везде и не Офис. Кто-то переходит на Office365 и Microsoft сама старается его продвигать взамен, поскольку ей так удобнее деньги собирать.
А где-то переходят на OpenSource и, например, LibreOffice, который, хотя и хорошо поддерживает xlsx файлы, но не отлично и очень часто многие вещи он слегка делает не так (примеров не будет, но факт).
А если мы говорим как программисты (мы на профессиональном ресурсе как бы), то есть такие вещи как расширяемость проекта и интеграция с другими инструментами. Вот сделали вы какую-то логику внутри в Excel, но, внезапно, через какое-то время, вам нужно ее использовать еще и в другом инструменте (написанном на Java/Python/PHP или даже в другом Excel-файле). Можно нагородить кучу костылей через COM или развернуть логику на вызов всего из Excel или копипастом в другой проект перенести код, но все это будет слегка не очень. А если ваш проект развивается, то рано или поздно такие задачи встанут.
И если они встанут перед вами - вы как-то сможете втихую это поправить, наверное. А если это будет делать кто-то еще, то ваша недальновидность в выборе инструмента будет очевидна.
Вкратце мое мнение еще раз: логика внутри Excel - плохо и не очень расширяемо. Использовать Excel (xlsx) для формирования отчетов, графиков и представления пользователю - норм.
Да, я понимаю о чем вы говорите. И, действительно, в условиях когда все зарегулировано и нет возможности даже файлик на флэшке принести - немного вариантов чтобы что-то сделать и на это повлиять не получится.
До сих пор у нас в стране, я уверен, есть места где файлами на дискетках обмениваются и на древнем FoxPro базы держат.
Иногда бывает из академического интереса можно попробовать реализовать какую-то идею в искуственных ограничениях и поведать об этом всему миру.
У автора же была возможность выбрать другой инструмент, но он этого не сделал и теперь учит других поступать так же. Я с этим не согласен и не хочу такое поощрять.
У автора же была возможность выбрать другой инструмент, но он этого не сделал и теперь учит других поступать так же. Я с этим не согласен и не хочу такое поощрять.
В тех страховых и финансовых компаниях которых я работал, не существовало возможности установить дополнительно программное обеспечение на компьютер или тонкий клиент. Вообще. Совсем. На последнем месте было невозможно запустить даже cmd. Но везде и всегда был установлен нелюбимый многими M$ Офис.
1) Как Вы думаете, в чем отличие Офис 365 от Офис 2019 или 2016? Подсказать? В обновлениях "на лету". Не факт, что это нужно 90% пользователей.
Для справки: "клеточки" не становятся "линиями в косую", но добавляются новые функции. В 2019 году, произошел очередной качественный скачек, который работает в 365, но не попал (и не попадет) в 2019. Вы в курсе, про тип ссылок "А1#"? Не "А1" и не "$А$1". Речь не о самой ссылке, а о новом... принципе работы, что-ли, в Эксель.
Сравнивать ОпенОфис и Эксель может только тот, кто дальше ВПР() не осилил и тем же Вордом пользуется, как Блокнотом. Ещё раз: таких 90% пользователей.
2) Эксель предназначен для обработки данных из БД, в меньшей степени, для создания и ведения "легкой БД".
Результат можно оформить прям в Экселе, а можно подготовить для ПоверПойнт, ПоверБиАй, выгрузить в Ворд, текст, ЦСВ, ПДФ, для связки Сервак-ГуглТаблица-ГуглДатаСтудио, т.е. для ПРЕЗЕНТАЦИИ (вариант - первичных документов) или для загрузки в БД.
Где ещё может понадобиться логика из Эксель? В файле на соседнем ПК? Сделайте надстройку.
Вам нужно обрабатывать данные в Эксель и удобнее это реализовать на Питоне? Правда?
СУБД начального уровня, предназначенную для работы с Эксель гораздо проще реализовать в самом Эксель, Аксесс, Вам не кажется?
ВБА не совместим с плюсами и шарпами? Серьезно? А все остальные совместимы?
В "говнокоде на ВБА" сложнее разобраться, чем в "трушном" на Питоне, т.к у него "ниже входной порог", как писали выше? Ниже чего? Чьего-то достоинства?
ЗЫ: "xlsx" - не панацея. Rar("xls") - годнота )
У меня есть разовая (вернее ежепятилетняя) работа по обработке приблизительно 50 листов с 30-100 тыс строк и 30-50 столбцов циферок. При этом правила обработки этих данных грубо говоря не оговорены, т.е. составляются и правятся на ходу, есть особые случаи и исключения.
Пользуюсь Excel, о какой наглядности или удобстве можно говорить в питоне, это вообще не про то.
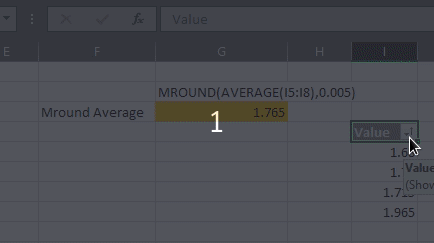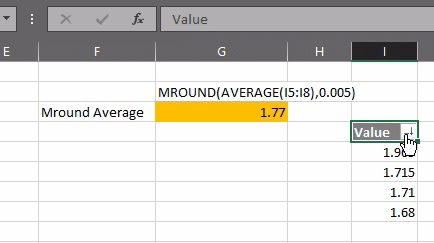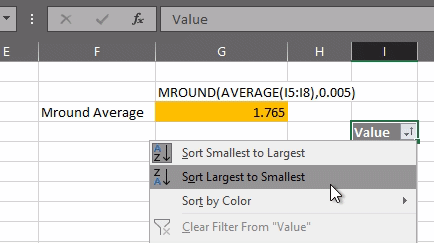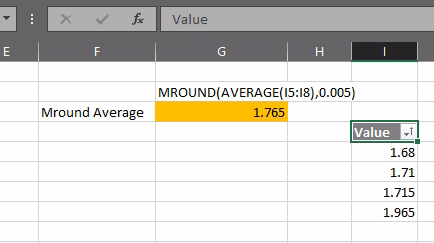

>>> 1.68+1.71+1.715+1.965
7.069999999999999
>>> 1.965+1.715+1.71+1.68
7.07
>>> (1.68+1.71+1.715+1.965)/4
1.7674999999999998
>>> (1.965+1.715+1.71+1.68)/4
1.7675
Ну если уж очень хочется python, то есть решения которые добавляют его в excel.
Для запросов к данным есть PowerQuery, который позволяет делать многие вещи просто, быстро и без кода.
после Delphi/C#/Java/JavaScript я скачусь до VBA
Не обязательно отказываться от любимого языка, так как с офисом можно взаимодействовать не только через макросы, но и через надстройки. VSTO поддерживает C# и VisualBasic.Net, а Office Add-ins — Javascript/Typescript. С остальных языков можно взаимодействовать через COM.
VSTO и COM работают только на Windows. Office Add-ins — на всех платформах (Windows, Mac, Mobile, Web).
На экселе всегда делаются первые рабочие POC и MVP прототипы, потом они получают путевку в жизнь и дальше переводятся в нормальный BI, с данными в базе, ELT инструментами с трансформациями на sql (ну иногда добавляется питон, если у нас airflow) , и визуализацией в чем-то аля PowerBI или Tableau.
И снова про MS Excel