
Введение
Привет! Я хочу рассказать вам о рекомендательных алгоритмах. Мы в Prequel создаем фильтры и эффекты для редактирования фото и видео. Создаем давно, и постепенно этих эффектов стало очень много. А с ними и пользовательского контента. Мы захотели помочь с выбором из этого многообразия, для чего нам и понадобилась система рекомендаций. Если масштабы вашей системы такие, что пользователям сложно в ней ориентироваться, возможно, что рекомендации могут помочь и вам.
Задуманный обзор систем оказался слишком объемным для одной статьи, поэтому мы разбили его на две части. Перед вами первая, она посвящена постановке задачи и базовым методам решения. В этой части мы разберем коллаборативные модели от матричного разложения (на примере ALS) до neural collaborative filtering. Кроме того, будет небольшой обзор метрик и техник борьбы с проблемой холодного старта.
В самом общем смысле рекомендации — это предложение пользователю релевантных объектов, персонализация в противовес унификации, которая не учитывает интересы конкретного пользователя. Исторически рекомендательные системы родились как ответвление задач поиска. В поиске есть запрос, есть контекст (предпочтения пользователя и его характеристики) и есть элементы, которые нужно ранжировать. В рекомендациях всё аналогично, но запросом выступает сам пользователь, его предпочтения.
Вызовы (проблемы) рекомендательных систем
Сложности, с которыми приходится сталкиваться при построении рекомендательных систем только отчасти похожи на проблемы смежных ML-областей. Такие системы многосоставны, к тому же требуют постоянного обновления и улучшения. Из этого возникают три категории проблем: модельные, инфраструктурные и проблемы выбора метрик. Я уделю некоторое время разбору, поскольку именно специфика проблем определяет подходы к построению рекомендаций.
Проблемы моделей
Сложность построения моделей в необходимости одновременно удовлетворять разным критериям качества, а также в сложности подготовки/интерпретации имеющихся данных. Для ясности вот неполный список конкретных проблем:
Разнообразие типов фидбэка (длительность, лайки, клики, добавление в избранное) и его неоднозначность. Клик, но не лайк и не покупка — это что? Нравится результат пользователю или нет?
Разнообразие типов контента (видео и картинки, для них, например, длительности взаимодействия принципиально не сравнимая)
Холодный старт пользователя
Холодный старт контента
Краткосрочность трендов и устаревание контента
Глобальная популярность
Обновление рекомендаций (для юзеров со 100500 действий, 100500+1 мало меняет выдачу)
Учет последовательности взаимодействия (вкусы меняются)
Учет сезонности (на Новый год и на 14 февраля в тренде будут разные фильтры)
Включение разных типов информации (чтобы учитывать не только взаимодействия, но и сам контент: картинки и текст, а также метаданные юзера: геолокацию, платежеспособность и прочее)
Инфраструктурные проблемы
Инфраструктурные проблемы большей частью произрастают из необходимости постоянного апдейта моделей. Это, например, в CV можно обучить очень сложную модель ретуши или сегментации один раз и дальше беспокоиться лишь о времени предсказания. Для рекомендаций это неприемлемо.
На практике распространенными проблемами становятся:
Масштабируемость, скорость выдачи рекомендаций, кэширование, нагрузка на сервера
Обновление рекомендаций (быстрое реагирование на недавние действия, новый контент)
Регулярный апдейт моделей
Правильное проведение аб-тестов
Но главная, пожалуй, проблема, состоит в том, что, несмотря на всю схожесть задач в этой области, у каждого сервиса остается своя специфика. У музыкальных сервисов композиции могут слушать многократно, а фильм даже самый интересный редко станут смотреть дважды. В Tiktok миллионы роликов и они устаревают с чудовищной скоростью. Рекламные рекомендации в ВК нужно оптимизировать с учетом геотаргетинга (даже если ты очень любишь суши, и это действительно крутой ресторан, то ты все равно не закажешь доставку из Новосибирска в Москву). А в Airbnb необходимо оптимизировать не только удовлетворенность туристов от хостов, но и хостов от туристов (то есть, оптимизировать в обе стороны).
Важно точно определять критичные для сервиса особенности рекомендательной системы.
Проблемы метрик
Одной из таких критичных для определения вещей являются метрики качества системы. В идеале мы хотели бы напрямую измерить, насколько пользователя устраивает сервис, но это невозможно. Приходится довольствоваться косвенными метриками, некоторые из которых могут конфликтовать. К примеру, довольно просто повысить количество просмотров (фильмов, роликов) за счет уменьшения среднего времени просмотра. Но будет ли это хорошо? У многих даже простых метрик есть свои подводные камни. Так, ориентирование на количество кликов повышает в выдаче мусорный, кликбейтовый контент — и не работает для лент, которые просто читают, листая без кликов.
Если необходимо оценить работу рекомендательного алгоритма на тестовой выборке, обычно используется одна или несколько метрик из списка ниже. Нюанс в том, что ранжирование (оно же сортировка) касается всех доступных для рекомендации объектов. То есть, если в каталоге доступно 100к фильмов для просмотра, то рекомендательная система теоретически может составить отсортированный список размером 100к. На практике же обычно важно, насколько хороши рекомендации верхних N элементов списка, где N в зависимости от задачи варьируется обычно в пределах от 5 до 20. Оттого в метриках ранжирования появляется постфикс @k.
Precision@k
Precision — это отношение полученных релевантных элементов к общему количеству, где количество мы задаем параметром k. Релевантными считаем те, с которыми пользователь взаимодействовал за тестовый период времени. Целевое взаимодействие может быть разным: просмотр, оценка, покупка — в зависимости от целей системы.

Average Precision@k
Чтобы учесть не только удачные попадания в top-k, но и то, насколько эти релевантные элементы близки к началу списка, используется метрика AP@k.
В этой метрике суммируются разные Precision@k, но если на позиции k оказался релевантный элемент. Сумма делится на m, которое равно общему количеству релевантных элементов.
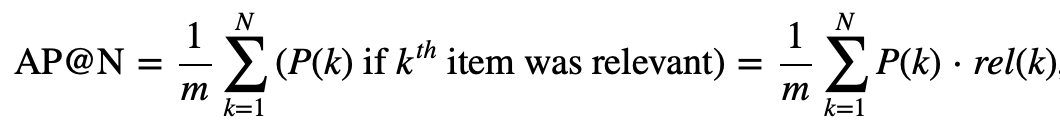
Mean Average Precision@k
MAP@k это совсем простой шаг — усреднение метрики AP@k по набору тестовых пользователей.
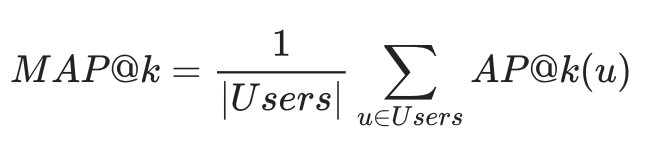
Normalized Discounted Cumulative Gain
Еще одна метрика, учитывающая позиции релевантных элементов в выдаче — это Normalized Discounted Cumulative Gain.
Ее тоже представим по порядку. Есть простая метрика Cumulative Gain (CG): для позиции p это количество релевантного контента на позициях с 1 по p. Cumulative Gain не учитывает порядок элементов в наборе, просто суммирует. Discounted Cumulative Gain уменьшает релевантность документов, которые находятся ниже, в зависимости от их позиции. Normalized Discounted Cumulative Gain — это возможность оценить близость нашего ранжирования к некому идеальному (за которое мы, например, можем взять реальный порядок взаимодействий пользователя с объектами).

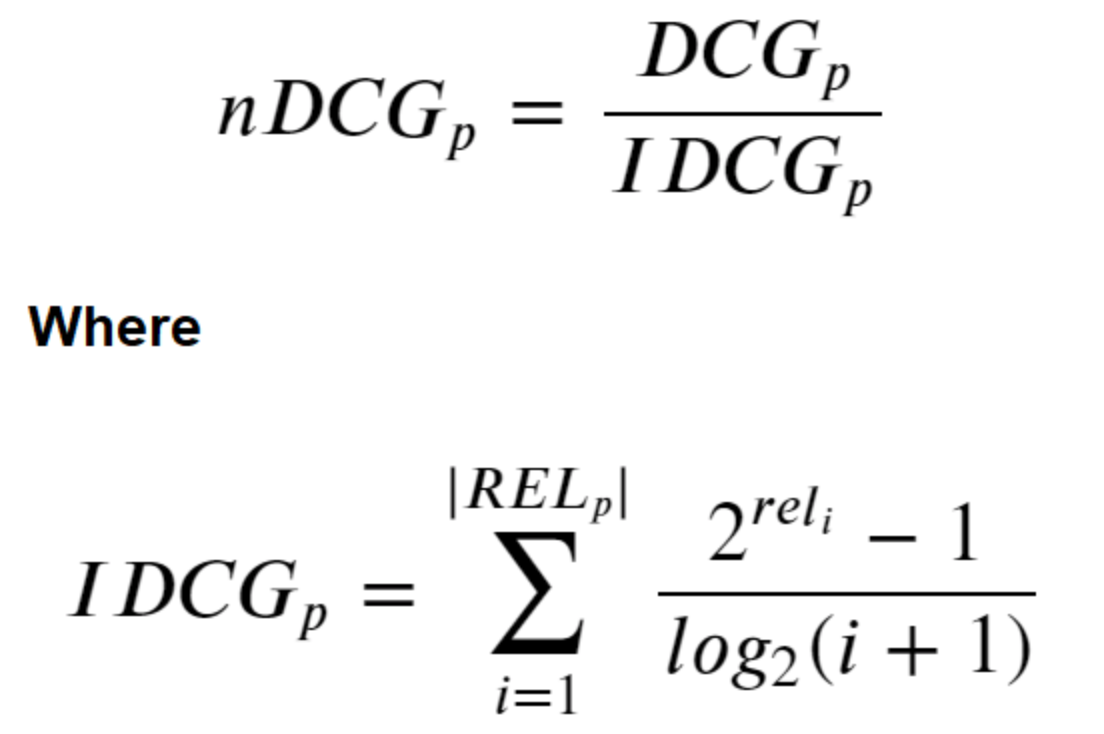
У всех метрик вроде NDCG или Mean Average Precision @ k общие проблемы: недостаток интерпретируемости и неочевидная (иногда отсутствующая) корреляция с бизнес-метриками. Если говорить непосредственно про бизнес-метрики (ретеншен, время на сессию, количество действий за сессию, средняя активность за период времени), то с ними тоже нет однозначности. Одна метрика, возрастая, может тянуть на дно другую. К тому же, использовать их в моделях непосредственно практически невозможно. По этой причине в области рекомендаций острее, чем где-либо, стоит проблема применимости в продакшене моделей из статей или recsys-челленджей: датасеты и метрики часто совершенно оторваны от реальности.
Еще одна важная проблема рекомендаций. Мы получаем фидбэк только по тем единицам контента, которые пользователь видел (никто не в состоянии оценить ВСЕ ролики на YouTube).
Таким образом, рекомендации — это что-то вроде самосбывающегося пророчества. Мы рекомендуем что-то, пользователь смотрит что-то из рекомендованного, мы пытаемся еще лучше предсказывать, что именно он посмотрит. Таким образом, пользователь очень редко выходит из пузыря рекомендаций.
Типы данных
Два основных вида входных данных для рекомендаций — это коллаборативные фичи и метаданные.
Первое — это любые данные о взаимодействии пользователей и объектов. Как правило, выглядят как очень разреженная матрица большого размера.

Второе — метаданные объектов или сам контент непосредственно (видео, фото, звук).
Бывают модели построенные на первом, бывают на втором, а бывают комбинированные.
Все ищут путь к комбинированным по простой причине: больше данных — точнее модель. Коллаборативные фичи становятся мощной основой для рекомендаций, а метаданные позволяют сделать рекомендации точнее (к тому же помогают при холодном старте).
Коллаборативные модели
Матричное разложение
Как бы то ни было, фидбэк пользователей — самый важный вид информации, который можно учитывать в рекомендациях. Базовые методы рекомендаций построены на методе k-ближайших соседей. Для построения рекомендации мы находим пользователю близких по предпочтению “соседей” и усредняем их оценки. Или же находим объекты похожие на те, которые уже понравились пользователю. Проблема в том, что матрица коллаборативных данных, как уже упоминалось, большая и разреженная, искать соседей неудобно.
Потому появилась задача отобразить в единое векторное пространство и юзеров, и объекты, чтобы иметь возможность непосредственно сравнивать их схожесть. Векторное пространство, о котором идет речь, обычно называют «скрытыми факторами» (latent factors) или эмбеддингами. Ищется разложение матрицы взаимодействий такое, чтобы произведение двух матриц (пользователи-эмбеддинги и объекты-эмбеддинги) было близко к исходной матрице взаимодействий в тех позициях, которые были заполнены (процент заполнения матрицы низкий). Соответственно, скалярное произведение вектора пользователя на вектор контента дает предсказание степени интереса пользователя к этому контенту.
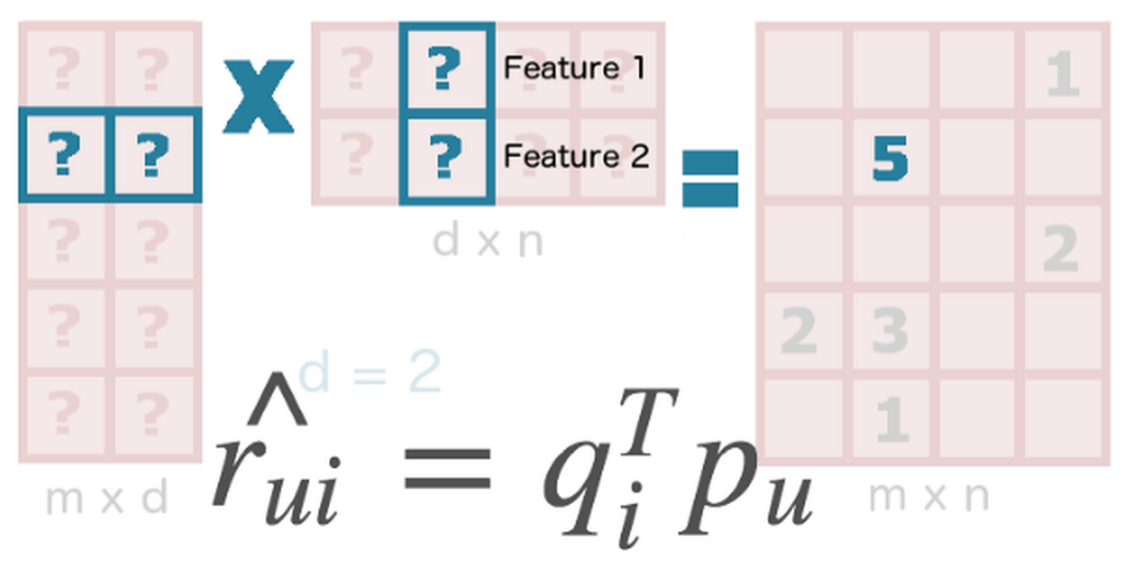
Сформулировать задачу можно как оптимизацию квадратичной ошибки с регуляризацией.
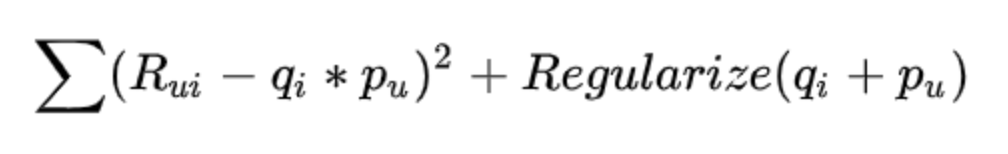
Но можно немного уточнить задачу. Этому фильму чаще ставят оценку 10, а этот юзер, предположим, очень добрый и вообще почти всем фильмам ставит 10-ки. Нужно отделить предвзятость пользователя и контента от именно персонального предпочтения. Потому формулу часто уточняют.

Здесь присутствуют три новых элемента: глобальная средняя оценка и смещение относительно нее для конкретного пользователя и объекта.
Alternating least squares (ALS)
Alternating least squares (ALS) — метод получения интересующих нас матриц. Сложность в том, что нужно оптимизировать сразу два набора параметров.
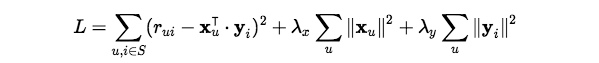
Алгоритм устроен так. Фиксируется один из наборов скрытых факторов, например объектов (y_i). Вычисляется производная функции потерь по другому набору векторов (пользователей). Затем процедура повторяется для векторов объектов. И так чередование продолжается.

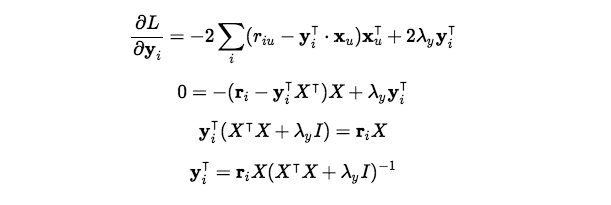
Здесь: n × m — размер исходной матрицы, Y — вектора эмбеддингов контента. Кроме того, вектор-строка r_u просто представляет строку пользователя u из матрицы рейтингов со всеми рейтингами для всех элементов (поэтому он имеет размерность 1 × m). Наконец, I - это просто единичная матрица, размерность которой здесь k × k.
Implicit ALS
Явный фидбэк (оценки) пользователей доступен нам не всегда — и не всегда ему можно верить. Неявный фидбэк (количества просмотров/прослушиваний, покупок, добавлений в закладки) есть всегда и в гораздо большем количестве, а количество для машинного обучения критично.
Рассмотрим сразу на примере ленты а-ля Tiktok. Человек не видел видео. Значит ли это, что оно ему не нравится? Или ему просто среди миллионов единиц контента еще не попался этот конкретный ролик? Если человек посмотрел кусок конкретного ролика, значит ли это, что он ему не понравился? Может быть, самую интересную/смешную часть он все же посмотрел? Значит ли это, что он ему обязательно понравился? С автоплеем в ленте судить еще сложнее.
Таким образом, рассуждения переходят от «этот контент понравился, а этот – нет» в пространство степени уверенности: «мы не уверены, что полсекунды просмотра означают, что ему понравилось, но гораздо сильнее уверены, что пять минут просмотра означают, что ему понравилось».
Привычная нам формула преобразуется таким образом. Вместо одной оценки вводится два значения: r — числовое выражение нашей уверенности, p — бинаризация r. C — для минимального порога уверенности.
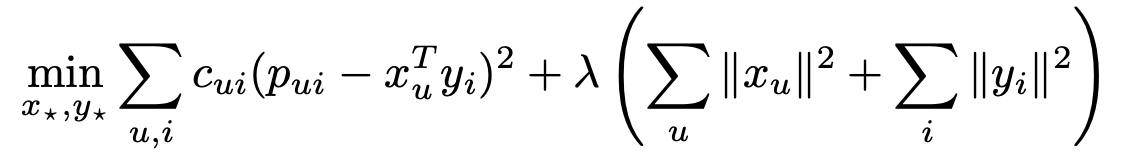
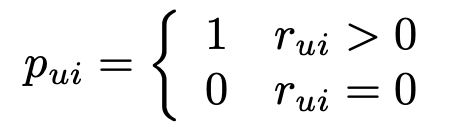

Получаем новую функцию для оптимизации, с которой можно работать уже описанным образом с помощью ALS алгоритма. Вместо непосредственно длительностей можно брать процент просмотра или логарифмировать длительности для сглаживания выбросов.
Холодный старт
Fold-in
Так называемый «холодный старт» — проблема рекомендаций для нового контента или пользователя. Предположим, мы обновляем рекомендации раз в три часа. За эти три часа может прийти новый пользователь. Или уже присутствующие пользователи могут совершить новые действия, на которые мы хотим реагировать быстрее (за три часа активный юзер может посмотреть много роликов, а рекомендации останутся прежними)
Этот простой трюк обычно называют «fold-in». По сути мы делаем один шаг оптимизации ALS только для одного нового вектора пользователя, фиксируя матрицу скрытых факторов контента.
Предсказание эмбеддингов
Холодный старт может касаться и объектов, если к нему не было еще достаточного интереса пользователей, чтобы сделать предсказание. Такое возможно, если объект только появился, или может быть виновата закольцованная проблема непопулярности: пока контент не популярен, его не рекомендуют, а значит, ему неоткуда взять популярность для рекомендаций.
Значит, нужно получить вектор эмбеддингов контента, по каким-то другим данным. Можно использовать любую дополнительную информацию. Например, существует прием, когда строят модель, предсказывающую эмбеддинги по метаданным контента. Разумеется, ее придется переучивать при каждом обновлении основной модели. Или если у нас есть эмбеддинги полученные другим образом (например из самого контента непосредственно), их тоже можно использовать для такого предсказания.
Maximal-volume algorithm
Холодный старт — многосоставная проблема. Самый крайний ее вариант: совершенно новые пользователи, о которых практически нет никаких данных.
Базовое решение: показывать популярный контент. Можно разбить популярность на глобальную популярность и недавние тренды. Можно отдельно считать популярность по странам/площадкам.
Что не так с таким подходом?
Допустим, мы рекомендуем видео-ролики, и самые популярные в последнее время — ролики со смешными котиками. Они забивают всю ленту для новых пользователей, так что человек, только пришедший на сервис, может подумать, что кроме котиков тут вообще ничего нет. Часть пользователей хотела бы увидеть другой контент, а для тех, кому популярное по вкусу, хватило бы нескольких роликов, чтобы после просмотра у них могли появиться уже персональные рекомендации. Видно, что много однотипного контента плохо решает эту задачу.
Критично важно показать пользователю все разнообразие интересного контента. Максимально разнообразно, но при этом максимально популярное. Это нетривиальная проблема, даже если ее будут решать в ручном режиме эксперты.Если формализовать задачу, то нужен такой набор контента (фиксированного размера), чтобы как можно больше пользователей нашли себе среди него хотя бы один интересный элемент.
Идея решения довольно проста: вектора эмбеддингов пользователей и объектов после матричного разложения находятся в одном пространстве. Что и позволяет нам говорить о схожести пользователя с контентом. В этом пространстве объекты представлены векторами. Если мы возьмем N таких векторов и посмотрим на область, которую они очерчивают, то мы хотим, чтобы эта область была максимальна (чтобы туда попало как можно больше пользователей). Если говорить интуитивно и упрощенно, то каждое число в векторе обозначает некий значимый признак объекта или набор признаков. А величина этого признака — его выраженность.
Требования могут быть выполнены путем поиска подмножества столбцов (объектов), которое максимизирует объем параллелепипеда, охваченного ими.
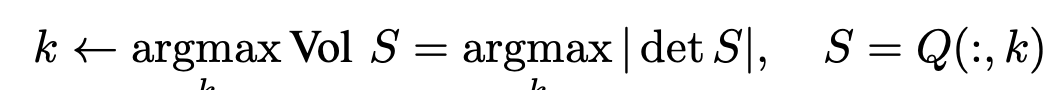
На рисунке у нас три набора по два вектора в двумерном пространстве. Легко видеть, какая пара покрывает большую площадь.

В общем случае задача NP-полная, но можно найти субоптимальное решение жадным алгоритмом, с названием maximal-volume algorithm. Суть в поиске dominant submatrix, квадратной матрицы.
Доминирующее свойство S означает, что все столбцы qi ∈ RL0 поля Q могут быть представлены через линейную комбинацию столбцов из S с коэффициентами, не превышающими 1 по модулю. Хотя это свойство не означает, что S имеет максимальный объем, оно гарантирует, что S является локально оптимальным, что означает, что замена любого столбца S столбцом Q не увеличивает объем.

Это алгоритм для получения квадратной матрицы. Для прямоугольного случая используется похожий принцип. На этом остановимся в рассмотрении классических методов матричного разложения и вспомогательных к ним.
Factorization machine
Factorization machine переформатирует рекомендательную задачу в терминах привычной регрессии. Для каждой пары пользователь-объект создается строчка в обучающем датасете, где сам пользователь и объект кодируются с помощью one-hot encoding.
Кроме самих признаков, в модель добавляется информация об их попарном взаимодействии. Для того, чтобы их учесть, формула FM выглядит таким образом.

Где v — это вектор размерности k, ассоциированный с каждым пользователем и каждым объектом, а скобки означают скалярное произведение. Если считать, что x принимает ненулевое значение только в позиции i и u (конкретной пары пользователь-объект), то получаем упрощенную модель.

Интересно, что FM позволяют добавлять дополнительные признаки кроме коллаборативных, но основной входной информацией все еще остается матрица взаимодействий.
Neural collaborative filtering (NCF)
NCF как и matrix factorization опирается на коллаборативный данные неявного фидбэка. Но пытается в отличии от него уйти от скалярного произведения в качестве меры схожести, поскольку NCF может изучить более сложные зависимости. Основная идея NCF в том, чтобы сделать эту меру более сложной и обучаемой.
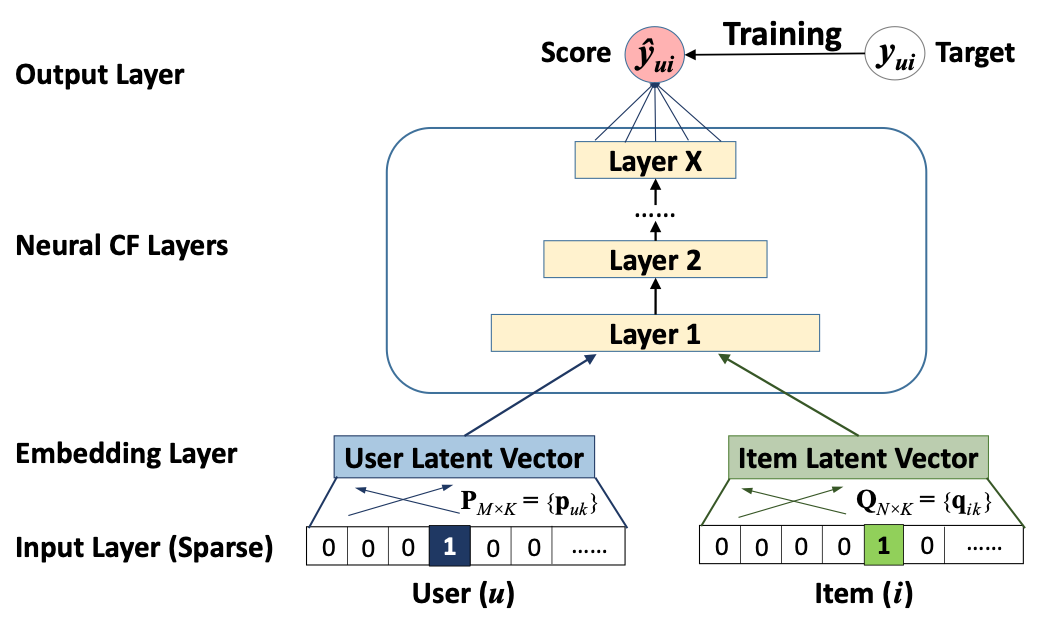
Входные данные могут быть разными, но изначально используются чистые коллаборативные данные, закодированные one-hot encoding. В ситуации холодного старта входными данными могут послужить метаданные контента и пользователей. За входным слоем находится полносвязный, который отвечает за преобразование разреженного one-hot представления в плотные эмбеддинги. После получения эмбеддинги конкатинируются, а дальнейшая архитектура носит имя neural collaborative filtering и отвечает за преобразование эмбеддингов пары пользователь-объект непосредственно в предсказание.
В данном случае стандартная среднеквадратичная ошибка может не отвечать виду реальных данных неявного фидбэка, которые представлены значениями 0 и 1. Потому используется вероятностный подход к обучению NCF. Если предсказанное число рассматривать как вероятность значения 1 (то есть релевантности объекта пользователю) и ограничить выход сети диапазоном [0,1], то можно использовать log loss.
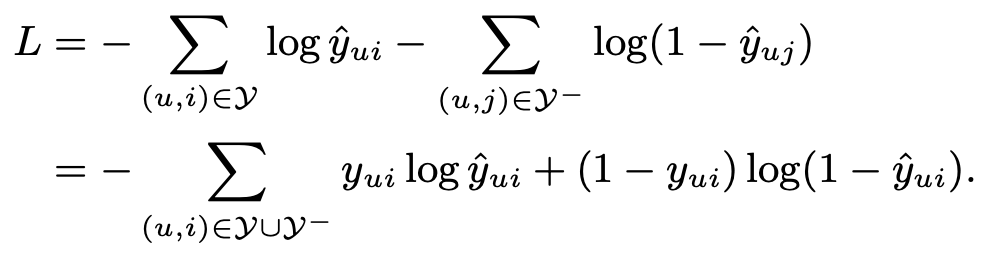
В формуле Y- означает множество негативных примеров, в качестве которых берется некоторое подмножество ненаблюдаемых взаимодействий (пар пользователь-объект, по которым нет данных). Негативные примеры отбираются равномерно, но можно использовать, например подходы, учитывающие популярность, что может еще улучшить производительность.
NCF получается более общим вариантом классического матричного разложения, которое можно в точности воспроизвести, если упростить слои идущие за слоем эмбеддингов.
В оригинальной статье приводятся результаты теста NCF в сравнении с классическими методами такими как KNN, рекомендация популярного и ALS матричное разложение на двух датасетах: MovieLens и Pinterest. Согласно тесту NCF демонстрирует лучшую стабильно более высокие результаты на обоих наборах данных.
Word2Vec
Есть и другие подходы к получению эмбеддингов из разреженной матрицы взаимодействий пользователей с объектами. Один из них заимствован из языковых NLP-моделей и носит название word2vec. Довольно просто представить, что объекты — это слова, а последовательности взаимодействия с ними в рамках одной сессии (или пользователя) — это предложения. По сравнению с предыдущими методами, NLP-модели используют скользящее окно небольшого размера, а значит, позволяют учитывать еще не последовательность действий, но уже близость одного к другому в последовательности.
Есть два метода формирования train-набора данных. Один называется skip-gram — это угадывание окружения вокруг слова. Другая схема — это CBOW (continuous bag of words), угадывание слова по его окружению (словам вокруг).

Суть одна — выделить паттерны слов, которые часто встречаются вместе в одном контексте.
Получается модель, которая берёт входное и выходное слова и вычисляет вероятность их соседства. Но нужно ввести в набор данных отрицательные образцы — слова, которые точно не являются соседями. Это называется Skip-gram с отрицательной выборкой (SGNS).
Цель на этапе обучения — подобрать таки эмбеддинги для всех слов словаря, чтобы скалярное произведение их было бы мерой вероятности для этих слов встретиться пососедству.
Ключевые гиперпараметры word2vec: размер окна, количество отрицательных образцов и размерность эмбеддингов. В Gensim (известной библиотеке для обработки естественного языка, где реализован word2vec алгоритм) размер окна по умолчанию равен 5, и 5 отрицательных образцов берется на каждый положительный.
Общая архитектура CBOW-сети представлена на рисунке. Входной слой может быть расширен в зависимости от количества слов в рассматриваемом контексте. Используется разреженное one-hot encoding представление слов.

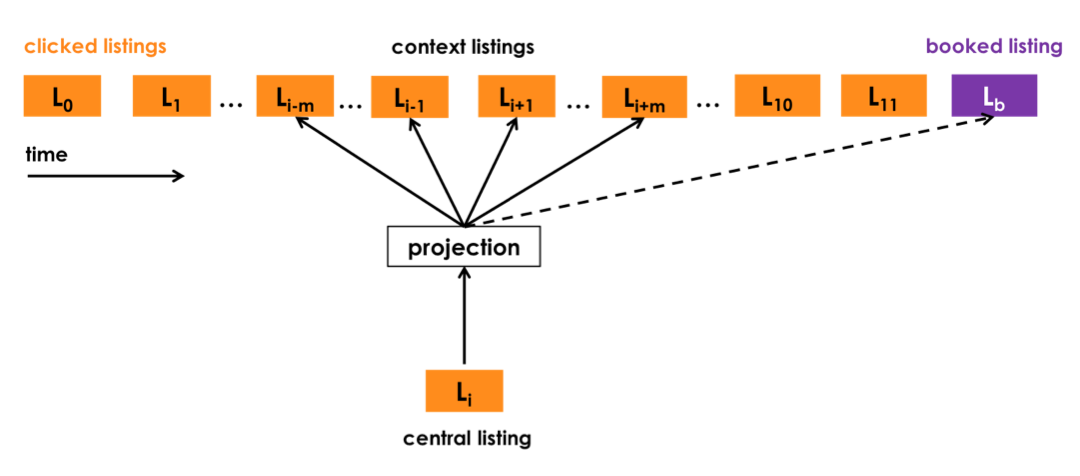
Рассмотрим конкретное применение в рекомендациях на примере Airbnb. В Airbnb используется skip-gram model. Если более формально, то функция L, которую максимизируют, выглядит так.

S — это сессии, каждая из которых состоит из последовательности кликов по l листингам (объектам размещения), v — обучаемые эмбеддинги.

Вероятность P — это вероятность увидеть листинг l_i+j на расстоянии, которое мы считаем контекстом от листинга l_i. Где m — это параметр отражающий размер контекста. v_l и v_l со штрихом — это входной и выходной вектор эмбеддингов листинга l. При таком подходе листинги, встречающиеся в схожих контекстах, получат похожие эмбеддинги (как и со словами). Чтобы не считать градиент по всему «словарю» листингов используется подход позитивного и негативного семплинга пар таргет-контекст.
Из интересных решений: чтобы сделать дополнительный акцент на сессиях, закончившихся бронированием, бронирование добавляется как глобальный (дополнительный) контекст ко всем тренировочным примерам из сессий с бронированием независимо от размера окна.
Есть еще одна интересная модификация, которую используют для торговых площадок Alibaba.
Вместо word2vec здесь используется DeepWalk, который использует ту же идею Skip-gram, но для составления эмбеддингов графовых структур. Его ключевая особенность — это случайные блуждания, которые используются вместо обычного фиксированного контекста в word2vec.

Заключение
На этом заканчивается первая часть обзора. Надеюсь, что она помогла вам составить картину происходящего в мире рекомендаций.
Замечу, что многие из этих проверенных временем алгоритмов до сих пор в строю, и, возможно, будут удачными решениями для вашей задачи. А следующей статье речь пойдет уже о более сложных и современных моделях рекомендаций: подходе Learn to rank, алгоритмах Wide & Deep, использовании авто-энкодеров для рекомендаций и sequential моделей с механизмами attention.
Спасибо за внимание!

