Казалось бы простая задача - развернуть Kubernetes кластер и в нем запустить централизованный мониторинг TICK стек и логирование ELK стек. Но для меня она осложнилась тем, что с этим технологиями я столкнулся впервые. Чтобы понять, как все работает, хотел пройти простые Quick Start инструкции. К своему удивлению, не нашел детальных актуальных описаний - либо отдельные статьи со своей спецификой, либо многостраничные книги по Kubernetes. Пока собирал пазл из многочисленных материалов, решил написать статью, в которой рассмотреть общую концепцию развертывания TICK и ELK стеков в Kubernetes. Для чего, вообще, решать задачу централизованного мониторинга и логирования в Kubernetes?
Архитектура Kubernetes кластера
IT индустрия пришла к консенсусу, что cloud native приложения - это такие, которые могут эффективно работать в Kubernetes кластере (K8S). И одним из требований к cloud native приложением - это их построение в соответствии с принципами наблюдаемости (observability). В Kubernetes приложения работают в контейнерах и в любой момент контейнер может быть остановлен и его внутренние данные, включая логи, пропадут. Поэтому мониторинг работоспособности и логирование должны осуществляться внешними системами. В настоящее время наиболее популярны системы, построенные на TICK и ELK стеках. Поэтому задача установки и настройки этих систем в Kubernetes кластере является актуальной.
Но для начала надо обзавестись Kubernetes кластером. Самый простой способ - установить под Windows Docker Desktop и Minikube. Но как показала практика, Minikube предназначен только для изучения Kubernetes, а как среда для развертывания промышленных систем, не тянет. Эксперименты с увеличением вычислительных ресурсов для Minikube не помогли. Пришлось разворачивать кластер на Amason EKS (Elastic Kubernetes System), что, конечно, не бесплатно, но что ни сделаешь ради статьи!
Начнем с теории и посмотрим на архитектуру Kubernetes. Я нарисовал свой вариант архитектуры со всеми элементами и связями, т.к. в документации и книгах включены только упрощенные схемы:

Подробное описание элементов и связей можно найти в официальной документации Kubernetes и многочисленных статьях, поэтому здесь приведу только краткое описание. Kubernetes кластер содержит одну или несколько Master Node. В Master Node работают следующие элементы:
api-server - предоставляет REST API для взаимодействия с кластером Kubernetes.
Cluster Store (etcd) - хранит состояние и конфигурацию кластера.
Scheduler - получает от api-server новые задания по запуску Pods и назначает им рабочие ноды.
Controller - следит за состоянием кластера и приводит его в нужные состояния.
Kubernetes кластер содержит одну или несколько Worker Node. В Worker Node работают следующие элементы:
Kubelet - k8s agent регистрирует ноды в кластере, обрабатывает вызовы api-server, запускает Pods. При ошибках нотифицирует мастера, который решает, что делать дальше.
Container Engine - управляет контейнерами, обычно используется Docker.
kube-proxy - обеспечивает сетевую связность, выдает IP для Pods, распределяет вызовы (Load balances) между Pods в Service.
Pod
Pod - единица запуска и масштабирования в Kubernetes кластере.
Может содержать один или несколько Docker контейнеров.
Deployment
С помощью Deployment обеспечивается запуск, обновление и удаление Pods.
Services
Каждый Pod имеет свой IP. Pods объединяются в Service для распределения нагрузки и организации единой точки интеграции.
Service - стандартный способ доступа к Pods снаружи кластера.
Service обеспечивает для Pods доступ к внешним сетевым ресурсам.
Persistent Volume
Используются для организации постоянных хранилищ данных для Pods
На локальном компьютере обычно работают:
Kubectl - обеспечивает связь с Kubernetes кластером.
Helm - обеспечивает запуск Helm charts, которые загружаются из внешних репозиториев.
Запуск кластера в Amazon EKS
Создание Kubernetes кластера в Amazon не так очевидно, как с помощью Minikube, но на все шаги есть хорошие инструкции. Для того, чтобы развернуть Kubernetes кластер в Amazon необходимо создать:
Cluster для начала без Nodes.
Пользовательскую роль для управления кластером со стороны Amazon.
Node Group.
Пользовательскую роль для управления вычислительными ресурсами в Node Group.
В Node Group выделить вычислительные ресурсы (виртуальные машины).

Для того, чтобы управлять кластером и запускать Pods со своего локального компьютера необходимо получить доступ к кластеру с помощью kubectl. Для этого идем по очередной инструкции "Create a kubeconfig for Amazon EKS"
Устанавливаем aws консоль локально, проверяем, что установка успешна:
aws --version
Вводим API key и API secret которые получаем в онлайн консоли:
aws configure
Консоль aws пропишет в Kubernetes setup файл свои настройки, проверяем, что есть доступ к нашему кластеру:
kubectl cluster-info
Теперь для доступа к кластеру можно использовать как kubectl, так и графический интерфейс. В своей работе я использую open source приложение Lens (https://k8slens.dev/)
Helm
Устанавливать наши приложения будем с помощью Helm Charts https://helm.sh/. Они значительно упрощают процесс установки и конфигурирования, т.к. скрывают шаги по созданию многих сущностей, которые иначе пришлось бы делать в Kubernetes вручную:
Deploymet - конфигурации развертываний.
ConfigMap - конфигурации приложений.
Secrets - чувствительные к разглашению данные.
Persistent Volume - постоянные диски.
Service - сервисы для доступа к приложениям.
Пользователи и их роли.
Установка Helm
Инструкция по установке Helm. Под Windows Helm устанавливается одной командой:
choco install kubernetes-helm
Helm еще удобен тем, что после установки его можно использовать как для работы с локальным Kubernetes в Minikube, так и в облачном Amazon EKS.
Поиск Helm charts
Не нашел структурированного места для поиска Helm charts. Думал, что есть аналог Docker Hub, который используется для поиска docker контейнеров. Официальная команда поиска Helm charts:
helm search hub influxdb
выдает список из нескольких десятков чартов для InfluxDB непонятного происхождения. Поэтому лучше всего, если производитель сам сделал чарт для разворота приложения в Kubernetes. Для наших задач есть официальные чарты от производителей:
Для Fluentd чарты находятся на GitHub
Посмотреть список установленных локальных репозиториев можно командой:
helm repo list
Установка TICK стека
Классическая схема TICK стека находится на официальном сайте InfuxData и состоит из Telegraf, InfluxDB, Chronograf и Kapacitor:

Вместо Chronograf будем использовать Grafana, как более функциональное приложение, а Kapacitor вообще для наших целей не понадобится. Таким образом у нас получатся не TICK, а TIG стек.
Для установки TIG стека изучил несколько инструкций:
Здесь приведу краткий алгоритм, который работает, если установка идет без сбоев.
Установка InfluxDB
Создаем в кластере namespace для мониторинга:
kubectl create namespace monitoring
Добавляем репозиторий в Helm:
helm repo add influxdata https://helm.influxdata.com/
Обновляем список чартов репозитория:
helm repo update
Запускаем чарт на выполнение:
helm upgrade --namespace monitoring --install influxdb influxdata/influxdb
Если в чарте надо поменять параметры по умолчанию, есть два способа, первый:
Скачать чарт локально:
helm pull influxdata/influxdb -d c:/work/influxdb
Поменять параметры в файле values.yaml и запустить на выполнение из локального каталога:
helm upgrade --namespace monitoring --install influxdb .
Второй способ: при вызове helm использовать параметры "set". Например, для ограничения использования 1Gi оперативной памяти и 1 виртуального процессора в командную строку надо добавить два параметра "set":
helm upgrade --namespace monitoring --install influxdb influxdata/influxdb --set resources.requests.memory=1Gi --set resources.requests.cpu=1000m
Оба способа рабочие и используются в зависимости от решаемых задач.
Проверяем, что Pod InfluxDB установился в кластер. Для этого смотрим, что он есть в списке Pods:
kubectl get pods --namespace monitoring
Смотрим, что сервис для InfluxDB есть в списке сервисов:
kubectl get services --namespace monitoring
Теперь необходимо получить доступ к установленной базе InfluxDB и сделать первоначальные настройки. Для этого запускаем порт форвардинг с именем нашего сервиса:
kubectl port-forward --namespace monitoring svc/influxdb 8086:8086
Теперь можно запускать InfluxDB CLI и делать настройки. Для этого, опять же, есть два способа. Первый - заходим внутрь контейнера и запускаем CLI изнутри:
kubectl exec -i -t --namespace monitoring influxdb-0 /bin/sh
influx
Второй способ работает, если есть локально установленная база influxDB. В этом случае можно подключится сразу из под Windows, при условии, что работает порт форвардинг:
C:\Program Files\InfluxData\influxdb\influxdb>influx.exe
Настройки в базе делаем для последующего подключения к Telegraf и Grafana. Для этого выполняем последовательность команд:
Создаем базу telegraf:
CREATE DATABASE telegraf
Смотрим что она есть в списке:
SHOW DATABASES
Делаем ее активной:
USE telegraf
Для проверки работоспособности вставляем произвольное значение:
insert key1 value=1
Сморим, что данные отображаются:
SHOW MEASUREMENTS
SELECT * FROM telegraf
На этом с InfluxDB закончили, далее устанавливаем Telegraf.
Установка Telegraf
Устанавливаем Telegraf из того же репозитория, что и InfluxDB:
helm upgrade --namespace monitoring --install telegraf influxdata/telegraf
С первого раза чарт не установился, смотрим логи:
kubectl logs --namespace monitoring --tail=20 telegraf-64fdc74887-22ld9
Видим строку:
Error running agent: Error loading config file /etc/telegraf/telegraf.conf: error parsing statsd, line 40: (statsd.Statsd.Percentiles) cannot unmarshal TOML integer into float64
Что-то не то с конфигурацией в telegraf.conf. Подозреваю, что Telegraf ожидает в конфиге float числа, а в нем integer. Проверим гипотезу, для этого добавляем в конфигурацию точки с нулем:

Перестартовываем чарт:
kubectl rollout restart --namespace monitoring deployment/telegraf
Как ни странно, но это помогло... как же они тестировали свой конфиг?) Теперь надо добавить системные метрики, которые Telegraf будет передавать в InfluxDB. Для этого в конец того же конфига добавляем метрики, описанные в статье:
[[inputs.cpu]] percpu = true totalcpu = true collect_cpu_time = false report_active = false [[inputs.disk]] ignore_fs = ["tmpfs", "devtmpfs", "devfs"] [[inputs.diskio]] [[inputs.kernel]] [[inputs.mem]] [[inputs.processes]] [[inputs.swap]] [[inputs.system]] [[inputs.docker]] endpoint = "unix:///var/run/docker.sock"
Опять перестартовываем чарт:
kubectl rollout restart --namespace monitoring deployment/telegraf
Чтобы убедиться, что появились нужные нам метрики снова заходим в CLI IngluxDB и выполняем команды:
USE telegraf
SHOW MEASUREMENTS
Смотрим, что есть нужные нам метрики cpu, disk и mem:

Теперь устанавливаем графический интерфейс.
Установка Grafana
Добавляем репозиторий:
helm repo add grafana https://grafana.github.io/helm-charts
Обновляем список чартов:
helm repo update
Если надо, скачиваем чарт локально или устанавливаем сразу:
helm upgrade --namespace monitoring --install grafana grafana/grafana
Cмотрим имя Pod
kubectl get pods --namespace monitoring
Для доступа к интерфейсу делаем порт форвардинг. 3001 я сделал т.к 3000 порт у меня занят под локальную Grafana:
kubectl port-forward --namespace monitoring grafana-pod-name 3001:3000
Идем в Secrets, смотрим user / password:

Запускаем GUI в браузере: http://127.0.0.1:3001
Вводим полученные user / password
Добавляем DataSource, при этом в качестве IP указываем внутренний адрес InflixDB в кластере: http://10.100.35.97:8086
В качестве базы данных указываем ранее созданную telegraf:

Теперь можно создавать dashboard. Существуют уже готовые dashboards для разных метрик. Например, в нашем случае можно сделать импорт dashboard по ранее упомянутой инструкции. Для этого надо нажать на знак "+" слева и выбрать пункт меню Import, далее ввести номер нужной dashboard 928:

Теперь смотрим на красивые графики по потреблению системных ресурсов нашим кластером:

Создание Service для Grafana
В промышленном кластере удобно получать доступ к интерфейсу Grafana по внешнему IP адресу, а не делать форвард портов. Для этого в Kubernetes используются Services. Шаги для создания Service:
В Pod Grafana делаем метку, по которой Service будет находить необходимый Pod, например "app: my-grafana":
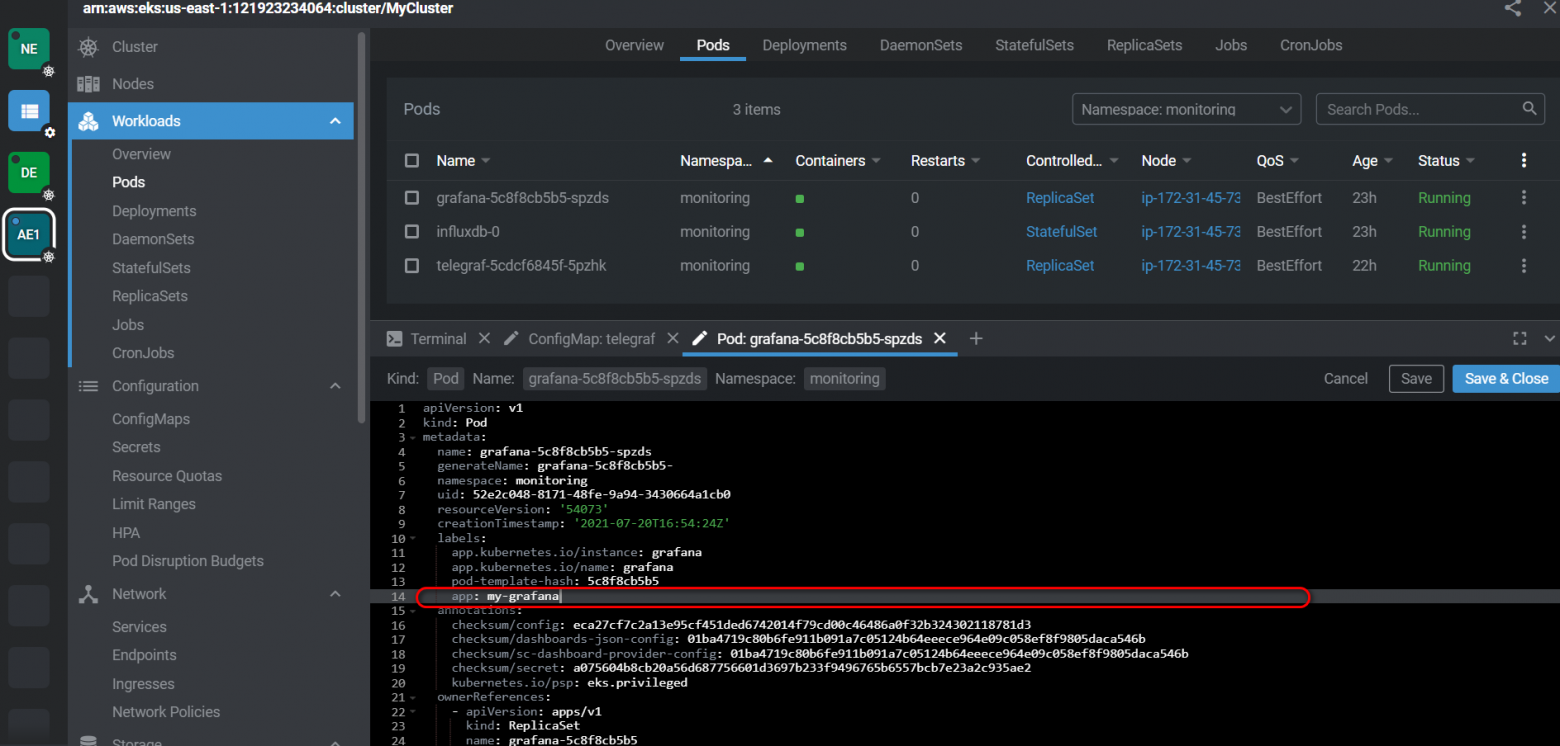
Делаем файл grafana-loadbalancer-svc.yaml для сервиса с типом LoadBalancer, чтобы он получил внешний IP адрес. В селектор записываем нашу метку. Внутренний и внешний порт указываем стандартный 3000:
apiVersion: v1 kind: Service metadata: name: my-grafana-loadbalancer spec: type: LoadBalancer ports: - port: 3000 targetPort: 3000 selector: app: my-grafana
Запускаем на выполнение
kubectl apply --namespace monitoring -f ./grafana-loadbalancer-svc.yaml
Смотрим список сервисов, убеждаемся, что присутствует наш my-grafana-loadbalancer, смотрим его внешний IP.
Смотрим, что в списке endpoints сервиса присутствует IP, который указывает на Pod с Grafana:

Вводим полученный адрес в браузере, убеждаемся что появилось GUI Grafana:
http://a26ddb02e81fd4956867aea4a0178679-256392.us-east-1.elb.amazonaws.com:3000
Если сервис больше не нужен, то удаляем:
kubectl delete svc --namespace monitoring my-grafana-loadbalancer
Схема Pods в Kubernetes
В результате получили полную цепочку для централизованного мониторинга в Kubernetes:

Установка ELK стека
Классическая цепочка логирования в ELK стеке.

Вместо Logstash будем использовать стандартного для Kubernetes агента Fluentd и поэтому у нас получится не ELK, а EFK стек. Также в Kubernetes есть несколько схем развертывания логирования. Они описаны в официальной документации "Kubernetes Logging Architecture". Мы будем реализовывать следующую стандартную схему:

Начнем установку EFK стека с базы данных Elastic Search.
Установка Elastic Search
Создаем namespace efk в Kubernetes:
kubectl create namespace efk
Добавляем репозиторий:
helm repo add elastic https://helm.elastic.co
Обновляем список чартов:
helm repo update
Для минимизации ресурсов делаем конфигурацию с одной Master Node, одной репликой и ограничиваем объём диска в 10Gb. При промышленном развёртывании, конечно, параметры должны быть рассчитаны из реальных требований к надежности Elastic Search кластера и предполагаемого объёма данных:
helm install elasticsearch elastic/elasticsearch --namespace efk --set volumeClaimTemplate.resources.requests.storage=10Gi --set replicas=1 --set minimumMasterNodes=1
Если с первого раза не получилось, смотрим логи, удаляем chart и persistent volume:
helm delete elasticsearch --namespace efk
kubectl delete -n efk persistentvolumeclaim elasticsearch-master-elasticsearch-master-0
Правим параметры, запускаем заново.
После успешной установки проверяем, для этого делаем форвард потов:
kubectl port-forward --namespace efk svc/elasticsearch-master 9200
Запускаем в браузере: http://127.0.0.1:9200/
В ответ должен вернуться JSON с версией Elastic Search.
Установка Fluentd
Чтобы разобраться с Fluentd я использовал несколько материалов:
Краткий алгоритм, который при удачном стечении обстоятельств должен привести к успеху:
Клонируем Helm чарты для fluentd из Git Hub:
git clone https://github.com/fluent/fluentd-kubernetes-daemonset
Создаем ServiceAccount в namespace kube-system с именем fluentd.
Создаем ClusterRole и записываем в него конфигурацию с правилами доступа:
apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: fluentd uid: 3458b789-e888-4473-9b48-04550404ea30 resourceVersion: '36487' creationTimestamp: '2021-07-20T14:02:13Z' selfLink: /apis/rbac.authorization.k8s.io/v1/clusterroles/fluentd namespace: kube-system rules: - apiGroups: - "" resources: - pods - namespaces verbs: - get - list - watch
Создаем ClusterRoleBinding, в которой связываем ServiceAccount и ClusterRole.
Далее в файле fluentd-daemonset-elasticsearch.yaml в параметре FLUENT_ELASTICSEARCH_HOST указываем внутренний IP сервиса elasticsearch-master.
Там же правим на настройки с путями.
После нескольких неудачных попыток у меня получился следующий работоспособный YAML:
apiVersion: apps/v1 kind: DaemonSet metadata: name: fluentd namespace: kube-system labels: k8s-app: fluentd-logging version: v1 spec: selector: matchLabels: k8s-app: fluentd-logging version: v1 template: metadata: labels: k8s-app: fluentd-logging version: v1 spec: serviceAccount: fluentd serviceAccountName: fluentd tolerations: - key: node-role.kubernetes.io/master effect: NoSchedule containers: - name: fluentd image: fluent/fluentd-kubernetes-daemonset:v1-debian-elasticsearch env: - name: FLUENT_ELASTICSEARCH_HOST value: "10.100.73.75" - name: FLUENT_ELASTICSEARCH_PORT value: "9200" - name: FLUENT_ELASTICSEARCH_SCHEME value: "http" - name: FLUENT_UID value: "0" resources: limits: memory: 200Mi requests: cpu: 100m memory: 200Mi volumeMounts: - name: varlog mountPath: /var/log - name: dockercontainerlogdirectory mountPath: /var/lib/docker/containers readOnly: true terminationGracePeriodSeconds: 30 volumes: - name: varlog hostPath: path: /var/log - name: dockercontainerlogdirectory hostPath: path: /var/lib/docker/containers
Устанавливаем Helm чарт:
kubectl apply --namespace kube-system -f fluentd-daemonset-elasticsearch.yaml
Если попытка не получилось, разбираемся, удалям:
kubectl delete --namespace efk -f fluentd-daemonset-elasticsearch.yaml
Правим, устанавливаем заново.
Установка Kibana
Установка оказалось на удивление проста. В параметрах сразу подрезаем требуемые системные ресурсы:
helm install kibana elastic/kibana --namespace efk --set resources.requests.cpu=500m --set resources.requests.memory=1Gi
При ошибках, как всегда, разбираемся, удаляем:
helm delete kibana --namespace efk
Запускаем заново. После успешной установки проверяем, делаем порт-форвардинг:
kubectl port-forward --namespace efk deployment/kibana-kibana 5601
Запускаем GUI в браузере: http://127.0.0.1:5601
А вот с конфигурированием Kibana все оказалось не очевидно. Чтобы разобраться, установил EFK стек локально под Windows, прошел там всю цепочку и потом вернулся в Kubernetes. Но для тех, кто до этого работал с Kibana, разумеется, все просто:
После захода в GUI Kibana делаем новую Index Pattern (Management -> Index Patterns -> Create New Index Pattern).
При создании индекса указываем Logstash index, который сгенерировал Fluentd.
Идем в Discover, выбираем созданный индекс.
Ставим фильтр на определенную дату / время .
Выбираем поля kubernetes.container_name и log и смотрим на логи от fluentd и самой Kibana:

Создание Service для Kibana
Для удобного доступа к GUI Kibana делаем сервис, как мы ранее сделали для GUI Grafana. Шаги те же, тут просто перечислю без подробностей:
В Pod Kibana делаем метку, по которой Service будет его находить.
Далаем и запускаем файл kibana-loadbalancer-svc.yaml для сервиса с типом LoadBalancer. В селектор записываем нашу метку. Внутренний и внешний порт указываем стандартный для Kibana 5601.
Смотрим выданный Kubernetes внешний IP адрес, с помощью него получаем доступ к GUI Kibana.
Полная схема Pods в Kubernetes
В результате получили классическую цепочку для централизованного логирования в Kubernetes. Полная схема, развернутых в Kubernetes стеков:

В результате получили в Kubernetes


Заключение
В статье мы рассмотрели, как развернуть в Kubernetes кластере классические цепочки для централизованного логирования и мониторинга.
Для себя сделал вывод, что в Kubernetes устанавливать программы сложнее, чем локально или на виртуалки, т.к. появляется новая прослойка абстракции и не всегда сразу понятно, почему что-то не работает.
Что дальше? Не просто же так мы поднимали эту инфраструктуру! Дальше рассмотрим все требования к cloud native приложениям, а не только требование observability, сделаем само приложение и запустим его в нашей инфраструктуре.
It's only the beginning!

