Чтобы разработать свой распределенный SQL-движок, можно написать свой SQL-оптимизатор для построения движков. Вам придется сделать парсер, семантический анализатор и придумать правила трансформации и оптимизации. Всё протестировать, а потом как-то интегрировать в свою систему. Но можно пойти более быстрым путем — внедрить для этого готовый инструмент.
Владимир Озеров, бывший инженер Hazelcast, а сейчас руководитель Querify Labs, на конференции HighLoad++ 2021 поделился опытом разработки и проектирования с нуля распределенного SQL-движка для продукта Hazelcast IMDG. Видео его выступления можно посмотреть здесь.
Сегодня статья о том, для чего в Hazelcast IMDG понадобилась эта разработка, и в чем преимущества и недостатки фреймворка Apache Calсite. Как на нем были реализованы встроенные оптимизации, выбор вторичных индексов и планирование перемещения данных в кластере. И как справились с описанием запросов произвольной сложности, кооперативной многозадачностью и оптимизированием сетевого протокола.

Что такое Hazelcast IMDG
Hazelcast IMDG — это распределенное key-value-хранилище, в котором пара «ключ-значение» организованы в шарды и распределены по узлам, чтобы обеспечивать горизонтальное масштабирование:
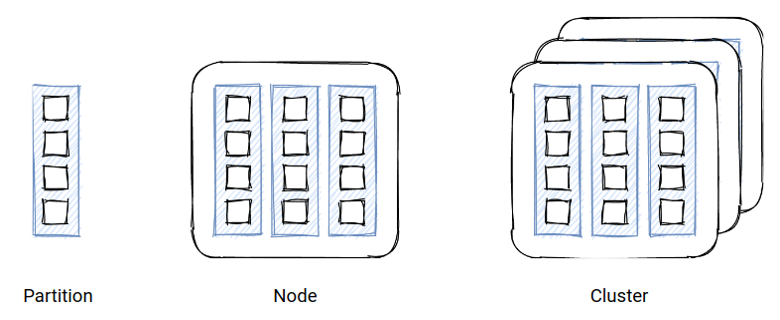
Hazelcast предоставляет доступ к данным по ключу. Для выполнения более сложных запросов существует Predicate API, который позволяет получить записи, удовлетворяющие условию. Predicate API может задействовать вторичные индексы, которые хранят данные либо в хипе Java-процесса (ConcurrentHashMap), либо в offheap (однопоточное красно-чёрное дерево).
У этого API было несколько проблем. Его изначально спроектировали для выдачи полного сета данных, без курсоров. Он исполнял предикаты и делал простые агрегации, но у него не было сложных операторов, типа join и сортировки:
IMap<Long, Person> map = …
…
map.put (1L, new Person (“John”));
…
Predicate predicate = Predicates.equals(“name”,”John”);
Collection<Person> persons = map.values(predicate);
Например, если вы работаете с большим сетом данных и отправили предикат с низкой селективностью, то получите миллионы записей, из-за чего ваш узел упадет с «Out of Memory». Predicate API не был декларативным и помимо всего прочего пользователю приходилось изучать его с нуля. Чтобы решить эти проблемы, в Hazelcast IMDG решили сделать SQL-движок.
Что было сделано
Оптимизация с Apache Calcite
После анализа решений на рынке для ускорения создания этого компонента, был выбран Apache Calcite — фреймворк для построения SQL-движков. У него есть все необходимые компоненты: парсер из коробки, семантический анализатор, транслятор и оптимизатор для применения правил оптимизации к запросам для поиска оптимального плана исполнения:
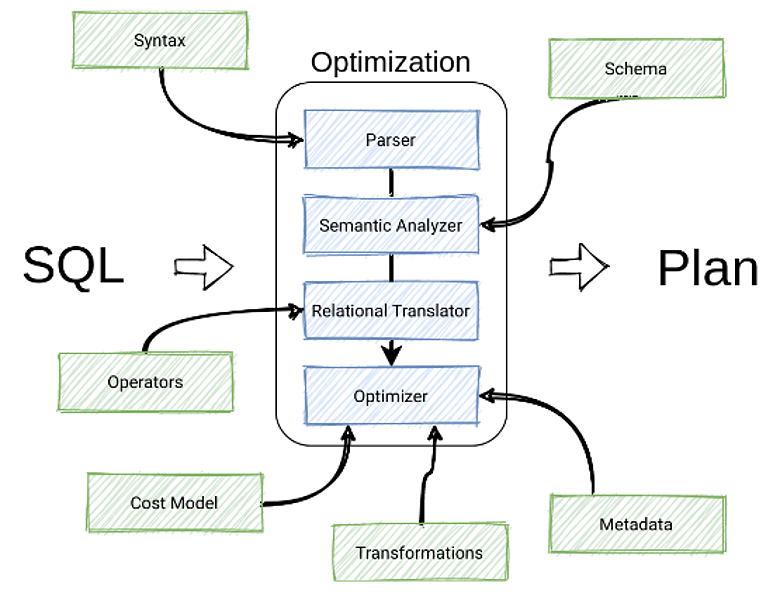
В Calcite вы можете добавить свои дополнительные фичи или определения практически в любой компонент. Например, собственную схему для парсера, собственный синтаксис для правил оптимизации, создав свои правила или операторы.
Парсинг
Берем оригинальную строку, скармливаем ее в парсер Calcite и получаем синтаксическое дерево запроса:
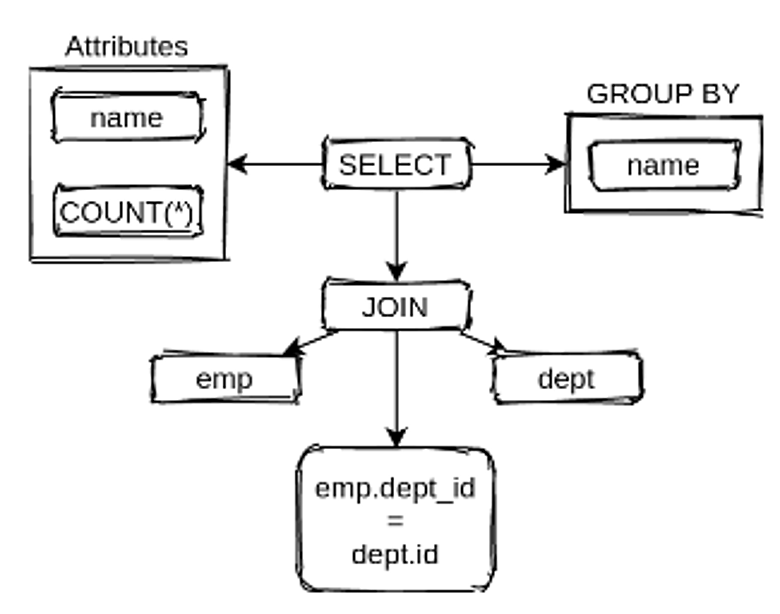
У парсера Calcite есть поддержка SQL-синтаксиса 2003 года, которая дает возможности изменения его поведения.
Семантический анализ
Для проверки семантической корректности синтаксического дерева в Calcite есть компонент SQL-валидатор. Он проверяет реляционную семантику, разрешает имена объектов СУБД функций и осуществляет вывод типов:
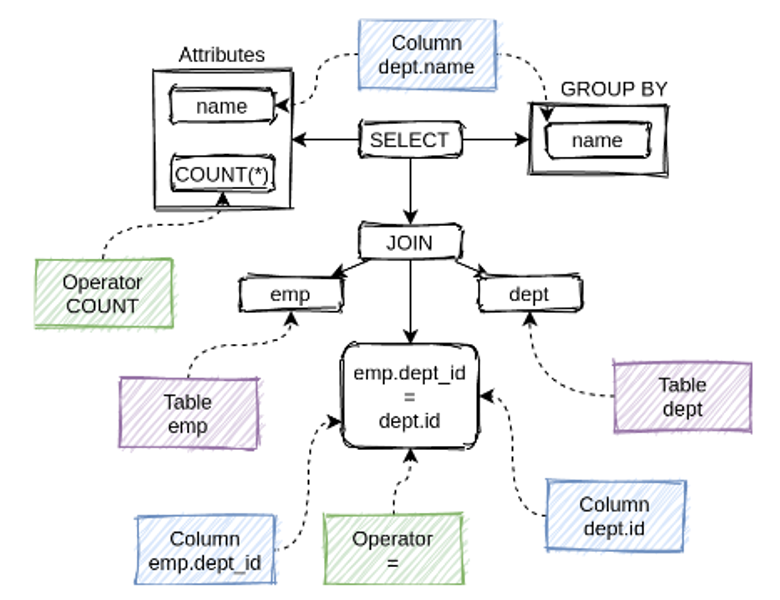
Calcite является расширяемым продуктом. Поэтому, если в процессе разработки потребуется изменить вывод типов функций в SQL, вы легко это сделаете. Семантика Calcite близка к MySQL, но можно сделать и более строгую семантику, как в Postgres.
Схема в Hazelcast
В Hazelcast IMDG базовая структура данных — IМар (распределенная HashMap), которая хранит произвольные пары «ключ-значение». Чтобы из этой неструктурированной информации получить схему, которую можно использовать в SQL, было сделано допущение, что все данные, ключи и значения имеют одни и те же типы.
Для каждой пары «ключ-значение» из распределенной HashMap взяли информацию о полях Java объектов (Hazelcast написан на Java), извлекли атрибуты и предоставили в Calсite:
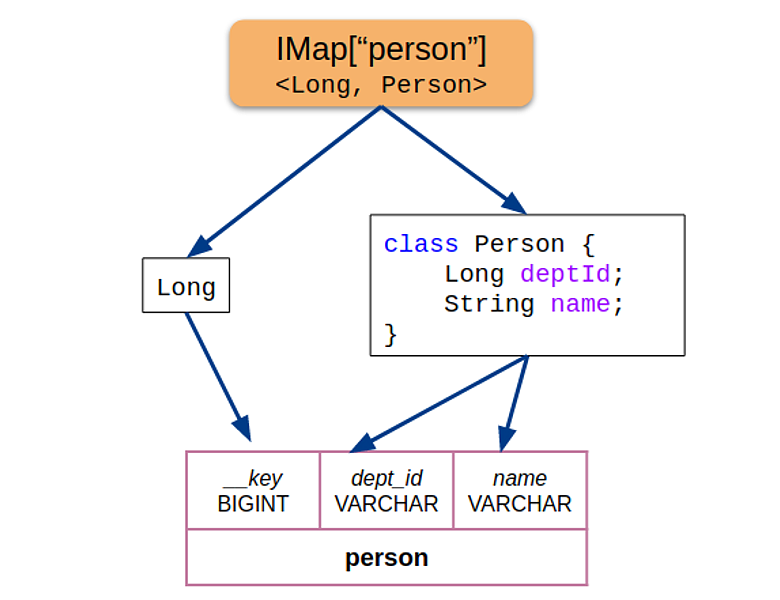
Если объекты из IМар оказывались других типов, движок возвращал ошибку. Такой подход позволил зафиксировать схему на начало оптимизации запроса и избежать конфигурации — всё работало из коробки.
Трансляция в реляционное дерево
Многие БД используют синтаксические деревья для оптимизации, но из-за особенностей синтаксиса SQL у них получается сложная структура со сложными правилами. Например, у оператора SELECT много child-узлов: WHERE, HAVING, GROUP BY и т.д.
Поэтому Calсite для оптимизации использует промежуточное представление (IR) в виде дерева реляционных операторов: scan, project, filter, join, aggregate и т.п. Операторы имеют строго ограниченную семантику, поэтому их удобно использовать для оптимизации запроса:

Реляционные операторы:
Scan — сканировать абстрактный источник данных;
Project — трансформировать кортеж (напр., а+Ь), оператор берет набор входных атрибутов и может изменить их порядок или применить к ними функции;
Filter — отфильтровать кортежи (WHERE, HAVING), оператор фильтрует (обрабатывает) tuple, которые не прошли предикат;
Sort — ORDER BY / LIMIT / OFFSET;
Aggregate — агрегация, оператор описывает агрегацию и больше ничего;
Window — оконная агрегация;
Join — классический join двух операторов;
Union/Minus/Intersect — set-операторы.
Для такого набора простых операторов легко писать правила оптимизации. Например, если вы пишете запрос с GROUP BY и HAVING, для Calсite — это два отдельных оператора. Информация из GROUP BY и его агрегатные функции в SELECT станут оператором Aggregate. HAVING превратится в Filter над оператором агрегации.
В Calсite операторы абстрактные. Например, у join нет спецификации, которая описывает — это hash-join, merge-join или nested loops-join. Для агрегатов и сканирования тоже нет описания, например, какое это сканирование — по индексу или по таблице. Поэтому если вы хотите интегрировать Calсite, сначала определите физические операторы, специфичные для вашего бэкенда, а также правила, которые будут транслировать логические операторы Calсite в физические операторы вашей системы.
В Hazelcast операторы определили так:
Логический оператор — Физические оператор
Scan — Table Scan, Index Scan
Aggregate — Hash Aggregate, Streaming Aggregate
Join — Hash Join, Merge Join, Nested Loop Join
Правила трансформации
После этого Calсite трансформирует оригинальное дерево логических операторов в дерево физических операторов, специфичных для вашей системы. Дерево описывает шаги, которые вы должны сделать в вашем бэкенде.
Большая часть всех трансформаций в Calсite имплементирована с помощью правил, состоящих из паттерна и самой трансформации. Трансформация описывает паттерн, который вы ищете в дереве. Например, паттерн агрегат, который находится поверх join:

Правило делает push down агрегата под join. Так оптимизация уменьшает количество данных, которые доходят до оператора join.
В Calсite трансформации применяются двумя путями. Либо итеративно — мы увидели паттерн, применили и получили новое дерево, после чего перешли к следующему дереву, и так, пока не придем в финальную точку. Либо с помощью Cost-based-оптимизатора, который вместо перехода от дерева к дереву кодирует все потенциальные деревья в одну структуру данных (MEMO) — последовательность реальных операторов и групп эквивалентности. На схеме группы показаны кружками:
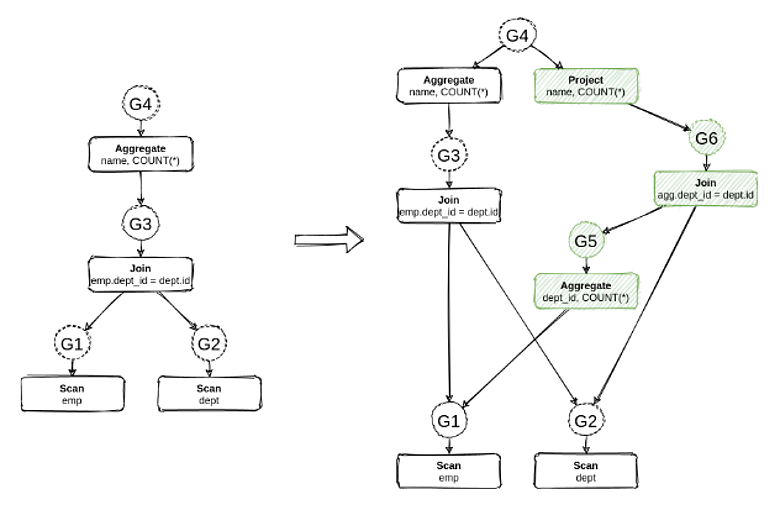
У группы G4 два эквивалентных оператора. Aggregate — то, что было до применения правила и Project, который появился после применения правила. Эквивалентность означает, что операторы вернут всегда один и тот же сет данных для любого входного набора данных. Calсite присваивает закодированным в одну структуру данным значение на основе кос-функции вашего оператора.
Например, в Spark или Presto трансформации чаще всего происходят эвристически, cost best оптимизации присутствуют на уровне определенных правил, но сделать их между рулами для всех альтернатив нельзя. В Calсite можно выбрать подходящий план исполнения.
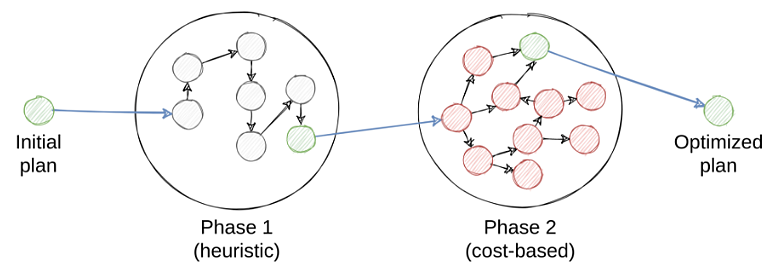
Многофазная оптимизация
В Calсite можно сделать композицию фаз оптимизации для облегчения ее процесса. Чтобы найти оптимальный план, вам нужно перебрать все планы. Поэтому в практических оптимизаторах процесс поиска плана разбивается на отдельные фазы. Так уменьшается общая сложность планирования, но существует вероятность пропуска оптимального плана.
В Hazelcast это сделано по такому же принципу: набор итеративных и cost-based фаз следует одна за другой, пока не приводит к финальному физическому плану:
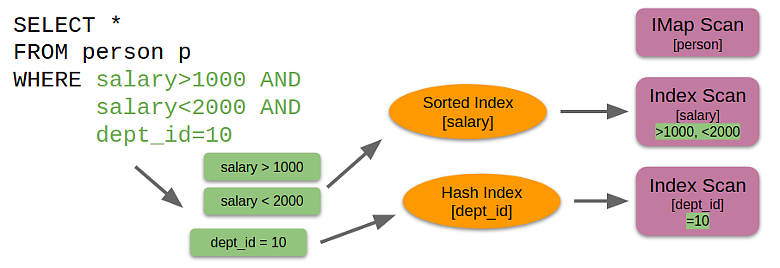
Физическая оптимизация: выбор индекса
В зависимости от того, какие предикаты есть в фильтре поверх оператора Scan, определяются индексы, которые удовлетворяют и ускоряют эти предикаты. Так можно не только сканировать базовую структуру данных (самого распределенного HashMap), но и добавлять в пространство поиска дополнительные альтернативные планы, которые задействуют те или иные индексы:
Физическая оптимизация: distribution
Одна из самых больших проблем распределенного SQL в том, что распределение данных в кластере может не подойти для исполнения конкретных операторов — таких как join, aggregate или sort. Поэтому надо планировать не только классические реляционные операторы, но и перераспределение данных в кластере. В Hazelcast определили три типа распределений для каждого оператора:
PARTITIONED — результат работы оператора распределен по узлам кластера;
REPLICATED — полная копия данных присутствует на всех узлах;
SINGLETON — результат работы оператора находится на одном узле, используется для моделирования доставки данных в конечный курсор, который отдает их пользователю.
Все распределения в Calсite можно закодировать через интерфейс RelTrait, в котором parent-оператор запрашивает конкретное распределение у child-оператора:
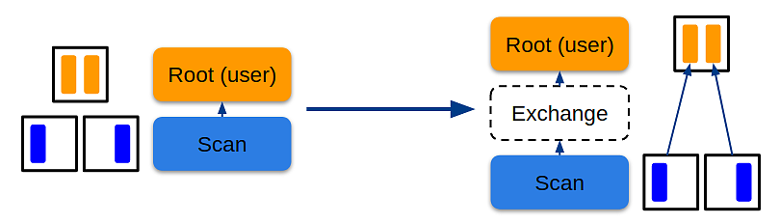
Представьте, что оператор Root моделирует доставку данных пользователю. Их надо свести в одну точку, чтобы отдать из курсора. Если у оператора Scan partitioned распределения, то всех данных на текущем узле нет. Тогда с помощью Calсite можно смоделировать свойство distribution, и один узел запросит у другого узла свойство — допустим, singleton. Если child-узел не удовлетворяет этому свойству, Calсite вставит оператор Exchange, чтобы сделать переход от partition-распределения к singleton-распределению, то есть смоделирует передачу данных со всех узлов на один узел в кластере. В Hazelcast интегрировали данную физическую оптимизацию с нуля.
С оптимизациями разобрались. Теперь перейдем к тому, как были сделаны SQL-запросы.
Фрагменты
Вместе с финальным планом от Calсite был получен и набор операторов, в том числе Exchange. После чего был имплементированспециальный визитор, который идет по дереву снизу вверх и, встречая оператор Exchange, создает отдельные фрагменты операторов, которые могут быть исполнены независимо друг от друга. Sender отправляет данные, а Receiver, соответственно, принимает. Так можно смоделировать любой запрос, потому что Exchange позволяет перемещать данные в кластере:
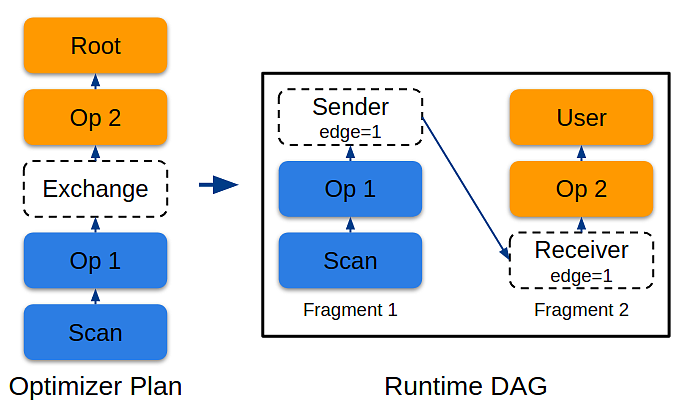
В итоге получили список фрагментов и определили, на каких узлах нужно их исполнить. Зная связи между парами sender-receiver, можно создавать батчи данных и отправлять из sender в receiver, чтобы доставить финальный результат в курсор пользователя:
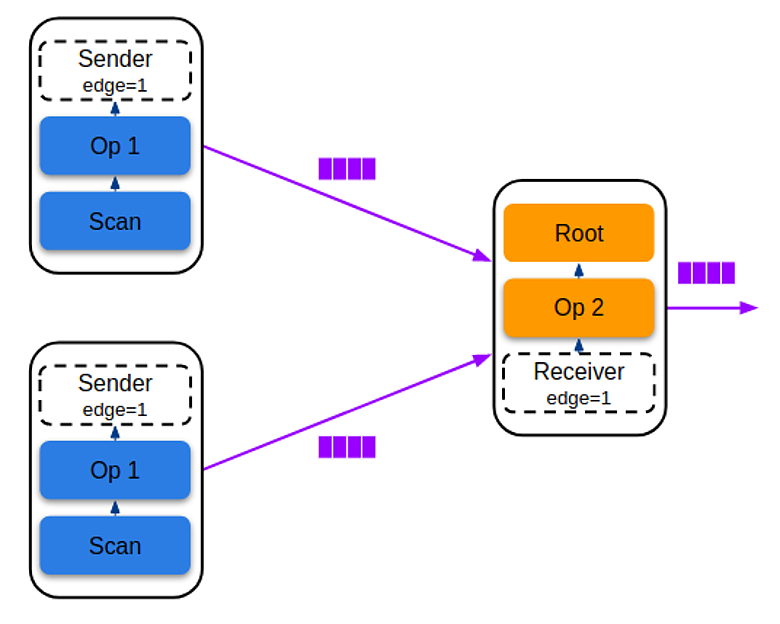
Фрагмент — это произвольное количество промежуточных операторов, которые берут данные из одного или более input'oв: индексов, IMap или receiverов. Фрагмент всегда имеет один output — ender или пользовательский курсор.
Представьте, что нужно исполнить запрос TPC-DS Q3, в котором есть join трех таблиц, агрегация и сортировка:
Запрос TPC-DS Q3
select dt.d year,
item.i_brand_id brand_id,
item.i_brand brand,
sum(ss_ext_sales price) sum_agg
from date_dim dt,
store_sales,
Where dt.d_date_sk = store_sales.ss_sold_date_sk
and store_sales.ss_item sk = item.i_item_sk
and item.i manufact_id = 128
and dt.d_moy=11
group by dt.d_year,
item.i brand,
item.i_brand_id
order by dt.d_year,
sum_agg desc,
brand_id
limit 100С помощью операторов Exchange можно разбить запрос на три отдельных фрагмента:
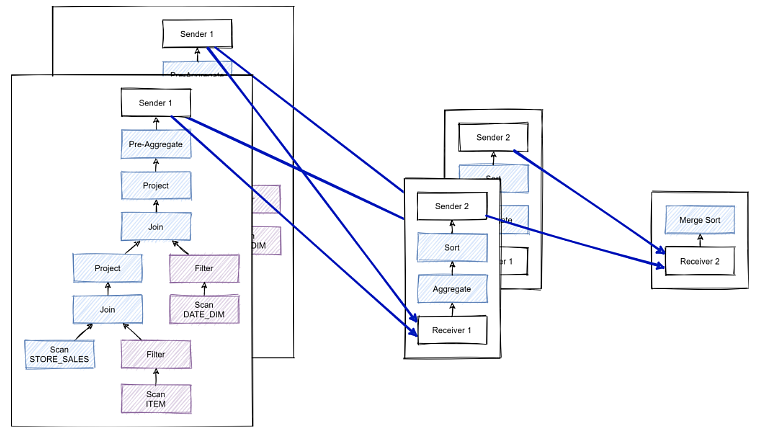
В первом фрагменте определяем две таблицы как replicated, чтобы сделать сколлоцированный join на узлах независимо друг от друга, то есть каждый узел join’ит часть своих данных. Потом на этих же узлах можно сделать агрегацию, поставив операторы Exchange и отправив в следующие фрагменты. Следующий фрагмент сделает финальную агрегацию и предварительную сортировку, после чего перешлет данные на один финальный узел, где и произойдет окончательный merge sort.
Volcano Model
За основу была взята модель классического Volcano-итератора, где у всех операторов есть общий интерфейс. Представьте, что вы хотите сделать оператор filter, который берет данные из другого оператора:

Вы говорите, что одно из полей этого оператора является другим оператором. Тогда при вызове операции next на фильтре вызывается next на child-операторе и проверяет, удовлетворяет ли он предикату. Если да, то мы его отдаем. Если нет, то продолжаем в цикле брать данные из child-оператора.
У классической модели Volcano итераторы отдают по одному кортежу, что не всегда эффективно. Например, если у вас тысяча записей в таблице, вам придется вызывать операцию next на операторы сканирования тысячу раз. Поэтому был сделан batching, чтобы операторы отдавали множество кортежей:

Под batching пришлось распределять ресурсы памяти, но с точки зрения производительности это достаточно хороший шаг.
Volcano Model: неблокирующее выполнение
Так как система распределенная, то может оказаться, что для текущего фрагмента нет данных. Например, данные выполняются на удаленном узле, который еще не завершил обработку. Чтобы операция next не блокировала поток, который исполняет фрагмент, был переделан классический интерфейс в неблокирующий режим.
Для этого операция next сигнализировала, есть ли в наличии картежи, которые можно получить из оператора, или нет. Если их нет, то исполнение текущего фрагмента приостанавливается и ставится на исполнение через compared set.
Фрагмент всегда исполняется строго в одном потоке. Если не хватает данных, он отдает исполнение другому фрагменту в этом же потоке. Было реализовано исполнение фрагментов в кооперативном пуле. Так как продукт написан на Java, то использовали ForkJoinPool и то, что операторы никогда не блокируют потоки, повышает производительность:

Протокол: запуск запроса
Для запуска и исполнения запросов был реализован сетевой протокол. При исполнении каждого запроса выбирается узел Initiator, который координирует выполнение запроса, выбирает узлы-участники (Participant) и отсылает им execute-запрос. Когда узел получает команду execute, он мгновенно исполняет те фрагменты, за которые отвечает, и участники обмениваются batch-сообщениями с данными:

Так как в Hazelcast не было синхронизации старта исполнения запросов на отдельных узлах, то случалось, что один узел отправлял батч, а другой узел не получал сообщение от координатора и не знал, что должен что-то принять. Это приводило либо к потере батчей, либо к утечкам памяти. Поэтому был реализован мгновенный старт узла после получения execute, чем сэкономили время на сообщениях.
Протокол: flow control
Чтобы исключить разную скорость работы операторов, когда sender генерирует пакеты быстрее, чем receiver может их принять и обработать, было реализовано подобие алгоритма flow control:
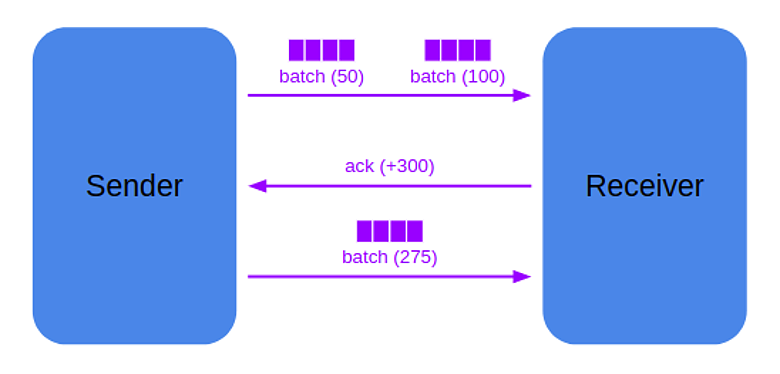
Sender и receiver договариваются, сколько данных («кредитов») sender может отправить на receiver. Receiver отслеживает оставшиеся «кредиты», и если видит, что их осталось мало, а receiver готов продолжать исполнение запроса, то отправляет ack-сообщение, которое увеличивает количество «кредитов» на sender. Это позволяет избегать перегрузки receiver.
Протокол: отмена запроса
Иногда нужно остановить выполнение запросов на всех узлах, например, из-за того, что пользователь отменил запрос или на узле возникла ошибка. Любой узел, который участвует в исполнении запроса, может инициировать его отмену. Для отмены запроса participant отправляет cancel сообщение на узел координатора (initiator), после чего координатор рассылает broadcast-сообщения на отмену всем остальным узлам.
Двухфазная отмена была сделана, чтобы избежать шквала запросов на отмену. Например, все участники столкнулись с ошибкой сериализации в Java и напрямую отправили запросы каждый каждому. В двухфазном протоколе это невозможно.
Протокол: отказоустойчивость
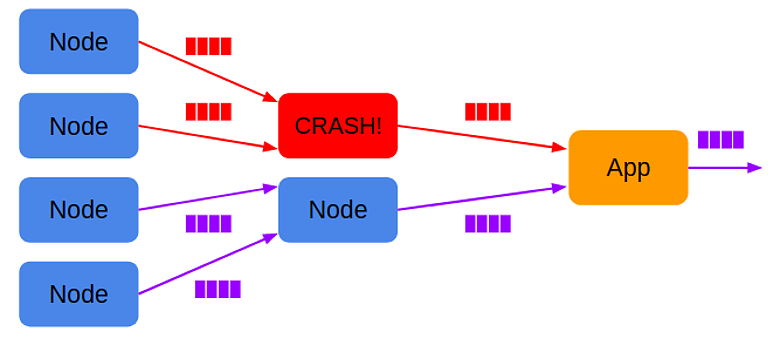
На момент проектирования движка проблемы fault-tolerance не стали решать, потому что обеспечение корректности данных пользователя более актуальным. Поэтому, если один из узлов падает из-за проблем с сетью или других причин, то запрос можно только отменить. Пользовательские запросы достаточно быстрые и вероятность отказа невелика. Для OLTP-нагрузок восстановление с произвольного падения избыточно. Проще перезапустить короткий запрос и получить финальный результат, чем тратить время на создание промежуточных материализаций.
Заключение
За полтора года с нуля было сделано:
SQL-движок на основе Apache Calcite со встроенными оптимизациями, выбором вторичных индексов и планированием перемещения данных в кластере («exchange»);
Runtime: DAG из фрагментов, которым можно описать запросы произвольной сложности, неблокирующие Volcano-style-итераторы с буферизацией и кооперативную многозадачность;
Сетевой протокол был оптимизирован под минимизацию latency и сделан Flow control для избежания перегрузки узлов.
В первой версии, которая вышла осенью 2020 года, поддерживались только простые операторы (сканирование, фильтрация, проекция), но инфраструктуру можно было расширить до поддержки join, агрегации и сортировки. В новых версиях агрегации и сортировки уже появились. Дальше появятся джойны, так как в движке была предусмотрена поддержка более сложных SQL-запросов.
HighLoad++ 2021 пройдет 17 и 18 марта 2022 года в Крокус-Экспо в Москве. Программа конференции не меняется, текущие билеты будут перенесены на новые даты! Расписание и билеты.

