Иногда при анализе производительности запроса на предмет "куда ушло все время" возникает стойкое ощущение deja vu, что вот ровно этот же кусок плана ты уже где-то раньше видел...
Пролистываешь выше - и таки-да, вот он рядом - но почему он там оказался, и как выйти из Матрицы самому и помочь коллегам?

Одна запись - несколько полей
Возьмем простую и достаточно типовую бизнес-задачу - показать последний документ по каждому из некоторого набора покупателей:
CREATE TABLE doc( doc_id serial PRIMARY KEY , customer_id integer , dt date , sum numeric(32,2) ); CREATE INDEX ON doc(customer_id, dt DESC); INSERT INTO doc( customer_id , dt , sum ) SELECT (random() * 1e5)::integer , now() - random() * '1 year'::interval , random() * 1e6 FROM generate_series(1, 1e5) id;
Для каждого клиента мы хотим иметь в результате исполнения запроса все значимые поля этого "последнего" документа. Что ж, "как слышится, так и пишется":
SELECT id customer_id , (SELECT doc_id FROM doc WHERE customer_id = id ORDER BY dt DESC LIMIT 1) doc_id , (SELECT dt FROM doc WHERE customer_id = id ORDER BY dt DESC LIMIT 1) dt , (SELECT sum FROM doc WHERE customer_id = id ORDER BY dt DESC LIMIT 1) sum FROM unnest(ARRAY[1,2,4,8,16,32,64]) id;
И... мы героически вытаскиваем одну и ту же запись из таблицы трижды! [посмотреть на explain.tensor.ru]


Возврат целой записи таблицы
И вот зачем мы каждое поле отдельно ищем? Мало того, что это раздувает размер запроса, так еще и выполняется каждый раз заново!
Давайте вернем из вложенного запроса сразу всю запись (только id мы теперь не будем переименовывать, чтобы не получилось два customer_id в результате):
SELECT id , ( SELECT doc -- это запись всей таблицы FROM doc WHERE customer_id = id ORDER BY dt DESC LIMIT 1 ).* -- разворачиваем запись в отдельные поля FROM unnest(ARRAY[1,2,4,8,16,32,64]) id;
И... теперь вместо 3 циклов у нас стало 4 - по одному на каждое поле извлекаемой вложенным запросом записи, включая customer_id (причем Index Only Scan, когда dt можно было вернуть прямо из индекса, превратился в менее эффективный, зато полностью совпадающий с остальными, Index Scan):
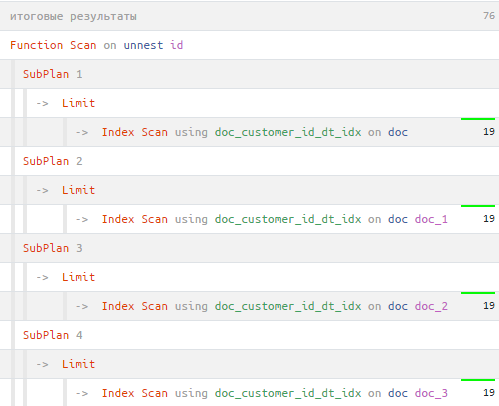

Экранируем запись с помощью CTE
WITH dc AS ( SELECT id , ( SELECT doc FROM doc WHERE customer_id = id ORDER BY dt DESC LIMIT 1 ) doc -- это одно поле-запись FROM unnest(ARRAY[1,2,4,8,16,32,64]) id ) SELECT id , (doc).* -- разворачиваем в отдельные поля FROM dc;
И, если вы используете версию PostgreSQL ниже 12-й, то все отлично - теперь индекс сканируется однократно (точнее, 7 раз вместо 28):
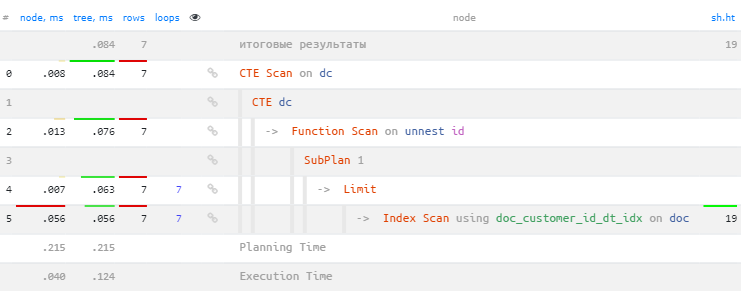
А вот начиная с PostgreSQL 12, планировщик "разворачивает" содержимое CTE, сводя все к тому же плану с 4 SubPlan. И чтобы он этого не делал, а наш "хак" продолжил работать, для CTE необходимо указать ключевое слово MATERIALIZED:
WITH dc AS MATERIALIZED ( ...
Незаслуженно забываемый LATERAL
Глядя на все больше обрастающий "хаками" и становящийся менее читабельным код, невольно возникает вопрос - неужели нельзя как-то попроще?
И такой способ есть - это LATERAL-подзапрос, выполняющийся отдельно для каждой записи выборки, собранной на предыдущих шагах (в нашем случае это набор из 7 строк id):
SELECT * FROM unnest(ARRAY[1,2,4,8,16,32,64]) id LEFT JOIN LATERAL( SELECT * FROM doc WHERE customer_id = id ORDER BY dt DESC LIMIT 1 ) doc ON TRUE; -- LEFT JOIN всегда должен иметь ON-condition
Обратите внимание на комбинацию LEFT JOIN LATERAL ... ON TRUE - это неизбежная плата, если мы хотим обязательно получить запись по каждому из 7 наших id, когда документов по конкретному покупателю нет совсем.

Такой запрос не только ищет запись однократно, но еще и в 1.5 раза быстрее из-за отсутствия необходимости формировать и читать CTE!

Один источник - разные условия
В предыдущем случае все SubPlan делали ровно одно и то же - искали одну и ту же запись по одинаковому условию. Но что если условия у нас окажутся разными?
Добавим к нашим документам пару полей - сотрудника-автора и сотрудника-исполнителя, которые указывают на таблицу с именами сотрудников:
ALTER TABLE doc ADD COLUMN emp_author integer , ADD COLUMN emp_executor integer; -- проставляем авторов/исполнителей UPDATE doc SET emp_author = (random() * 1e3)::integer , emp_executor = (random() * 1e3)::integer; CREATE TABLE employee( emp_id serial PRIMARY KEY , emp_name varchar ); -- генерируем "сотрудников" INSERT INTO employee( emp_name ) SELECT ( SELECT string_agg(chr(((random() * 94) + 32)::integer), '') FROM generate_series(1, (random() * 16 + i % 16)::integer) ) FROM generate_series(1, 1e3) i;
А теперь давайте попробуем получить имена автора/исполнителя для тех документов, которые мы искали на первом шаге - мы ведь уже знаем, что нам поможет LATERAL:
SELECT * FROM unnest(ARRAY[1,2,4,8,16,32,64]) id LEFT JOIN LATERAL( SELECT * FROM doc WHERE customer_id = id ORDER BY dt DESC LIMIT 1 ) doc ON TRUE LEFT JOIN LATERAL( -- извлекаем автора SELECT emp_name emp_a FROM employee WHERE emp_id = doc.emp_author LIMIT 1 ) emp_a ON TRUE LEFT JOIN LATERAL( -- извлекаем исполнителя SELECT emp_name emp_e FROM employee WHERE emp_id = doc.emp_executor LIMIT 1 ) emp_e ON TRUE;
Небольшое замечание: пожалуйста, не забывайте
LIMIT 1во вложенных запросах, когда вам необходима только одна запись, даже если уверены, что PostgreSQL "знает", что поиск идет по уникальному первичному ключу. Потому что иначе ничто не помешает ему выбрать вариант сSeq Scanпо таблице.
Все нормально, но пара узлов в плане оказывается подозрительно похожа друг на друга:
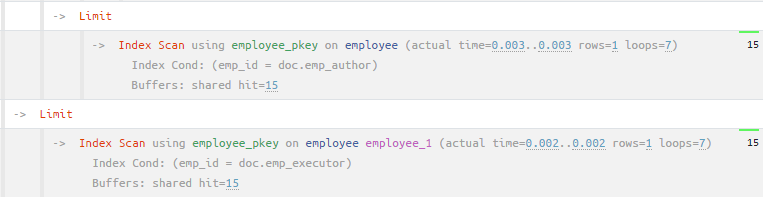
Можно ли свести эти два прохода по индексу в один? Вполне! Используем для этого PIVOT с помощью условных агрегатов:
SELECT * FROM unnest(ARRAY[1,2,4,8,16,32,64]) id LEFT JOIN LATERAL( SELECT * FROM doc WHERE customer_id = id ORDER BY dt DESC LIMIT 1 ) doc ON TRUE LEFT JOIN LATERAL( SELECT -- min + FILTER = PIVOT min(emp_name) FILTER(WHERE emp_id = doc.emp_author) emp_a , min(emp_name) FILTER(WHERE emp_id = doc.emp_executor) emp_e FROM employee WHERE emp_id IN (doc.emp_author, doc.emp_executor) -- отбор сразу по обоим ключам ) emp ON TRUE;
Более подробно про разные нетривиальные варианты использования агрегатов можно почитать в статьях "SQL HowTo: 1000 и один способ агрегации" и "PostgreSQL Antipatterns: ударим словарем по тяжелому JOIN".

Впрочем, этот способ стоит использовать с осторожностью, поскольку иногда сама агрегация может стоить дороже остальных вычислений.
Знаете еще другие случаи "клонированных" узлов в планах - поделитесь в комментариях, а у меня на сегодня все.


