
Привет, Хабр!
Сегодня мы, команда Sber AI, расскажем про бейзлайн генерации сказок с озвучкой и картинками, который мы предложили в рамках трека по Creative AI международного соревнования для школьников Artificial Intelligence International Junior Contest (AIIJC): рассмотрим аспекты обучения conditional ruGPT-3, генерацию музыки, генерацию изображения по текстовой строке, а также обсудим некоторые проблемы, с которыми пришлось столкнуться во время обучения и дообучения моделей.
В этом посте мы хотим разобрать (и разобраться сами), как можно использовать и объединять генеративные (и не только) модели для решения одной большой задачи — генерации контента. Мы подобрали большое количество материалов про каждую конкретную модель, чтобы ими ��ожно было пользоваться сразу.
Зачем генерировать видеосказки?
Если хочется чего-то интересного в жизни — надо устроить соревнование! В первую очередь мы решили устроить соревновательный трек для школьников: в прошлый раз такая затея уже принесла SOTA в общеизвестной задаче с большим отрывом. Выбрали задачу, которая смогла бы бросить вызов даже современным большим моделям-трансформерам, а именно генерацию полноценного видео по текстовому запросу. Команда Creative AI в Sber AI заинтересовалась этой проблемой. В разное время разными исследователями было предпринято множество попыток решить эту задачу, например:
генерация видео по названию (статья);
MoCoGan — генерация ведущих видео (по сути озвучивание сценария).
В целом все эти решения имели как свои плюсы, так и минусы, например, все они требовали вмешательства человека на определённых этапах, необходимо было что-то делать самому.
End-to-end baseline
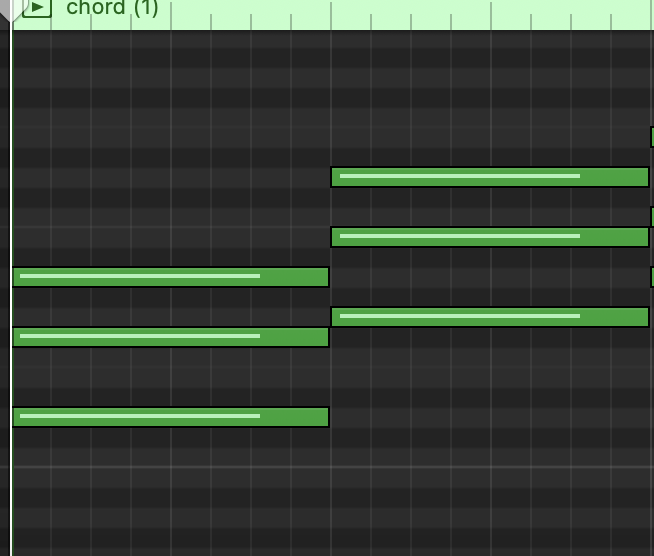
Мы сделали бейзлайн генерации, где на вход подаётся название сказки, а композиция из нескольких нейронных сетей на выходе даёт результат. Например такой:
Как мы подошли к решению задачи? Понятно, что написание любого рассказа начинается со сценария. Давайте подробнее рассмотрим, как мы его генерировали.
Генерация текста
Прошлой осенью Сбер выпустил ruGPT-3, что стало большим достижением в русском NLP (самая большая модель как по числу параметров, так и по размеру датасета). GPT-образные модели можно использовать для conditional generation, то есть для генерации текста с некими заданными заранее признаками. И мы с командой как раз хотели иметь возможность генерировать текст в нужном жанре и с правильным названием.
Нужно отметить, что в случае с ruGPT-3 речь идёт именно про ГИГАНТСКИЕ генеративные модели, дообучать и обучать с нуля которые крайне проблематично. А нам нужно было, чтобы у участников соревнования была возможность при желании файнтюнить модель самим. Поэтому было принято решение взять ruGPT-3 Small — в отличие от своих старших братьев, её можно файнтюнить даже на домашних видеокартах или Colab за адекватное время (несколько часов на K80), при этом она в состоянии выдавать неплохой результат.

Сначала мы поставили эксперимент на этом датасете русских сказок. Он содержит в себе 28 тысяч рассказов, размеченных на две категории — детские и взрослые. Но сказки не имеют названия, а следовательно нельзя будет обращаться к нейросети как к волшебному горшочку.
Протестировав модель для двух жанров, мы поняли, что это как минимум не очень интересно, и стали копать дальше. Так мы пришли к сайту фанатских рассказов Ficbook.ru. Его плюсы заключаются в обилии тегов, подробной разметке по жанрам, а также размерах текстов (средняя длина составила 1500 токенов). Результаты генерации получились такие (вместо двух весьма размытых жанров у нас появились вполне конкретные):
Наши результаты: |
Имя: Гарри Поттер. Жанр: ужасы. Текст: «Imagine, I know», — сказал себе Гарри перед тем как уснуть. Он был в комнате и думал о том, что ему нужно делать… Он не мог заснуть, потому то всё это казалось сном… Но нет! Все эти воспоминания были реальностью. Это была реальность его мечты… Но почему же тогда так больно? Может, из-за того, чего я здесь сижу на этой самой кровати? Почему мне хочется кричать от боли?! Что за чувство такое? Не могу понять... Наверное, просто страх потери… А может, боль осознания своей вины? Нет, нет, конечно!!! Я хочу плакать! Слёзы градом лились по моему лицу!
|
Имя: Гарри Поттер. Жанр: магический реализм. Текст: На поляне горел костёр. Пляшущие языки пламени то взвивались вверх, будто пытаясь лизнуть нависающие над ними ветви деревьев и поленьями пробираясь сквозь кустарники; то прижимались к стенам хижины отшельника — импровизированной крепости из колючих стеблей осоки или жёсткого камня с утолщёнными краёвстыми стенками — для защиты от непогоды. — Хагрид! Гарри! — закричал чародей в сторону источника огня (непонятно откуда взялась зелёная вспышка), но ожидаемой боли не последовало ни по одному боку поляны, либо горящей травы даже под порыв ветра... Выглядящий запуганным Северус Снейп застыл как громом поражённый. Колени затряслись ещё больше от того, что мощный импульс магической энергии ударил прямо через тело мальчика-подростка. В тот самый момент Дамблдор сделал шаг назад со снимающей заклинание палочкой у самого лица директора Шишкиной. — Ты можешь объяснить нормально? Это ненормально! *тихо рыдая* Тебе нужно отдохнуть! Ты должен вернуться обратно! |
Да, стоит отметить проблему того, что качество некоторых текстов было довольно низким, поэтому мы решили использовать только тексты, набравшие не менее 100 лайков, качество которых оказалось вполне удовлетворительным. Строго говоря, было не обязательно так делать, потому что длины окна не хватит в любом случае, и генерировать полноценный рассказ GPT-шкой в один заход — почти утопия, контекст теряют даже самые большие модели. В целом, есть разные способы для того, чтобы заставить модель генерировать более длинные и качественные последовательности, например sparse attention, который и был использован в самых больших версиях GPT-3. Подробнее про то, как генерировать тексты, можно почитать в этой статье от HuggingFace.
А теперь расскажем нашу сказку...
Каждая история должна быть рассказана, а так как сказку написал в некотором роде ИИ, то будет логично, что и расскажет её ИИ.
Генерация речи
Моделей для генерации речи из текста на русском довольно много, каждая крупная компания обязательно обучит свою на основе известной архитектуры или дообучить другую известную архитектуру. Но есть одна маленькая проблема: все существующие крутые решения или закрыты, или доступны в виде приватного API.
Это не подходило под нашу идею использовать открытые решения, которые при желании можно легко файнтюнить, в связи с чем выбор пал на SILERO models, которые делает команда SILERO (github, статьи про модельки)(находятся под лицензией GNU AGPL).
В целом качество синтеза речи было на достаточно хорошем уровне, но так как обучение модели генерации текста проводилось на открытых данных, то возникла одна существенная проблема: у модели были заметные трудности с грамматикой, она часто путалась в окончаниях и в целом говорила не очень грамотно. Это не слишком серьёзная проблема для чтения текста человеком, но большая проблема для вокодера (подробнее про то, как обучаются text2speech-модели, можно почитать тут).
Решение было простым — давайте исправим грамматику с помощью опечаточника JamSpell.
Так как Silero models имеют ограничение в 140 символов, то текст разбивается на батчи по 140 символов, игнорируя целостность слов. Возможность этого улучшения мы предлагаем участникам, как и возможность, например, добавить свои кастомные ударения.
Добавим музыки
Генерация музыки — одно из самых малоизученных и перспективных направлений Creative AI. В последнее время данное направление набирает всё большие обороты. Работа с музыкой предполагает вариативность формата входных данных, ведь музыку мы можем подавать как напрямую (музыка в формате .wav или .mp3) с последующим переходом к спектрограммам, так и в виде извлечённой информации о музыкальной композиции (высоты и длительности нот, тональности, громкости нот и т. п.). В рамках составления бейзлайна мы предоставили оба варианта, однако у каждого из них есть свои недостатки.
Первое, что приходит на ум, когда говорят про музыку, сгенерированную ИИ, — Jukebox от OpenAI. Гигантская модель для генерации (пропевания и продолжения) музыки, основанная на заданном тексте и/или некоторой затравке, созданная в 2020 году.
В её основе лежат модифицированные вариационные автоэнкодеры, которые сжимают огромное входное пространство в более адекватные и пригодные пространства для дальнейших вычислений. Генерация происходит именно в сжатом пространстве с последующим апсемплингом для повышения качества звука сгенерированного трека.

Jukebox может также разнообразно «пропевать» текст песни внутри трека, однако качество такого пропевания и соответствие заданному тексту далеко не всегда удовлетворительное.
На выходе получается уже готовый трек, не требующий серьёзной обработки.
Но с Jukebox есть одна существенная проблема: частота записанной музыки составляет не менее 44100 Гц, а значит, что в одной минуте трека будет более 2,5 млн наблюдений. В связи с чем генерация занимает огромное количество времени (на 30 секунд генерации уходит порядка 4,5 часов), а качество сгенерированной музыки резко падает после 15-20 секунд. Иногда генерация изначально получается плохая.
Также запуск Jukebox на Colab или на домашних мощностях представляется маловозможным, особенно в режиме генерации с нуля — она просто не запустится, ведь требуется карточка или кластер, сопоставимые с V100. И если запуск на мощностях Сбера будет простым, то у участников таких мощностей, скорее всего, нет.
Таким образом, напрашивается задачка по генерации треков на основе внутренней информации о составных «детальках» трека — нотах. Такую информацию предоставляют либо нотные листы (для них необходимы модели, извлекающие информацию), либо форматы, из которых такую информацию очень легко извлечь (.xml, .midi).
И тогда задачу генерации музыки можно свести к задаче, решаемой современными языковыми моделями, и «просто» предсказывать следующую ноту. Данный подход работает с одной дорожкой, сделать такое для нескольких очень сложно. Поэтому мы взяли самое оптимальное, на наш взгляд, решение — MusicTransformer от Magenta.
В его основе лежит архитектура GPT, с одной поправкой — вместо обычного Self-attention используется Relative Attention (относительное представление зависимостей токенов). Такой тип attention позволяет учитывать зависимости куплет-припев.

В целом качество музыки получается довольно высоким, однако это не готовый трек, а трек, требующий обработки в различных секвенсорах.
Для такого типа модели есть 2 проблемы:
1. Сложный энкодинг, учитывающий всю необходимую информацию, сильно раздувает размер входной последовательности.
В MusicTransformer используется event-based энкодинг, который описывает события включения и выключения нот, громкости нот и временных дельт. Таким образом, на 15 секунд генерации в среднем выходит около 1000 токенов, и генерировать более длительные композиции становится проблематично.
2. Датасет для такой модели собрать достаточно проблематично, т. к. в открытом доступе уж слишком мало данных.
Из возможных вариантов решения — парсить открытые источники и парсить музыку из YouTube с последующим транскрибированием wav-формата в midi (пример хорошей модели транскрибирования).
Существует несколько хороших имплементаций MusicTransformer, которые участники соревнования могут модифицировать для достижения лучших результатов: ссылка, ссылка.
Визуализируем то, что написал ИИ
А теперь давайте визуализируем то, что написала GPT-шка, и добавим к сказке сопутствующий видеоряд.
Задача визуализации по текстовому описанию безумно сложная. Первые попытки её решить были предприняты в 2015-2018 годах, выходило довольно много статей касательно того, что можно сделать. Практически все они либо не имели имплементации в коде, либо ничего не работало так, как было описано в статье.
Так было до января 2020 года, когда OpenAI выпустили статьи «DALL-E — creating images from text» и «CLIP — connecting text and images». И если первая модель всё ещё не в open source, то веса CLIP-а были опубликованы почти сразу после выхода статьи.
Казалось бы, у нас есть проекция картинки и текста в одно и то же пространство, как можно из этого сделать text2image? Ребята с reddit предложили очень простую и в то же время гениальную идею того, как это можно осуществить: давайте возьмём генератор от GAN и заставим его что-то генерировать, а потом будем двигать оптимизатором так, чтобы получать наиболее близкую к текстовому описанию картинку (для этого возьмём из CLIP-а перевод текста в латентное признаковое пространство и будем это векторное представление текста приближать к нужному изображению). Данный подход можно использовать для любого GAN, да и в принципе практически любой сетки для генерации картинок.
В апреле этого года была представлена архитектура Taming transformers, она основана на идее представления картинки в виде CodeBook — состоящего из набора квадратов изображения.

В этой архитектуре используется комбинация идей из GAN и трансформеров. Любопытно, что изначально эта архитектура пригодна для решения многих задач, связанных с генерацией изображений, таких как Depth2Image (воссоздание изображения из карты глубины), а также задаче, решаемой image GPT.
Рассмотрим примеры генерации на VQGAN + CLIP (обычный английский).
Text: картина с цветами в вазе.
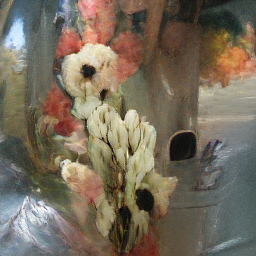
Интересный факт: при обучении скорее всего использовались открытые данные, в том числе с сайтов художников вроде ArtStation, где часто встречались ключевые слова типа UNREAL ENGINE| Hyperrealistic.
Что мы имеем в итоге, если добавить такие ключевые слова?
А вот что!
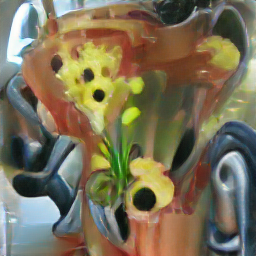
А вот, например, в стиле Сальвадора Дали:

В мае этого года в Индии исследователь опубликовал подход для MTCLIP (примечание автора — MT: multilanguage) на основе mtBERT.
Это позволило добавить русский язык, а вот пример генерации для текстового ввода:

Русские в Индии
Свежие подходы к генерации
Индустрия развивается динамично — за то время, что мы писали статью, вышел подход на основе Guided Diffusion, который ставит новую планку качества генерации.
Текстовый запрос: Логотип Sber AI.

Текстовый запрос: Цветы в вазе.

Ещё немного про генерацию картинок из текста
А ещё мы собрали ноутбук на VQGAN + Multilanguage CLIP (поддерживает 104 Mtbert языка). Плюс можно настраивать разрешение, но лучше запускать его с Collab pro, а ещё лучше — на отдельном кластере.
Участникам мы предлагаем самим попробовать добавить MT CLIP по примеру того, что написали мы :)
Кстати, регистрация на соревнование всё ещё доступна по ссылке, от участников требуется быть младше 18 лет.
Спасибо за прочтение!
Команда: Александр Николич, Денис Димитров, Иван Базанов, Андрей Черток
