 Думаю, ни для кого не секрет, какой именно праздник собирается отмечать вся прогрессивная часть общественности 13 сентября сего года. Вот и мы решили отметить. Мы — это компания ТЕНЕТ г.Казань. Отмечать будем путём проведения хакатона (с 11 по 12 сентября) и последующего турнира. Будем писать бота для настольной игры. Все желающие могут поучаствовать в режиме online. Призы будут (мы просто пока не решили какие именно). Подробности под катом.
Думаю, ни для кого не секрет, какой именно праздник собирается отмечать вся прогрессивная часть общественности 13 сентября сего года. Вот и мы решили отметить. Мы — это компания ТЕНЕТ г.Казань. Отмечать будем путём проведения хакатона (с 11 по 12 сентября) и последующего турнира. Будем писать бота для настольной игры. Все желающие могут поучаствовать в режиме online. Призы будут (мы просто пока не решили какие именно). Подробности под катом.Правила игры
Игра "Alapo" была придумана Йоханессом Транелисом в 1982 году. Её описание включено в знаменитую энциклопедию шахматных игр, составленную Дэвидом Притчардом. Игра проводится на квадратной доске 6x6 полей. В игре участвуют три типа геометрических фигур: треугольник, квадрат и круг, большого и маленького размеров.
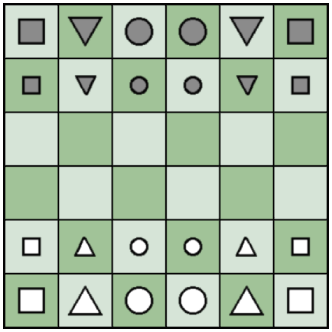
Игроки по очереди перемещают по одной фигуре своего цвета. Правила перемещения фигур похожи на шахматные. Большие квадраты перемещаются как ладьи – на произвольное количество полей по вертикали или горизонтали. Большие треугольники двигаются как слоны – на произвольное количество полей по диагонали. Большие круги совмещают в себе два этих типа хода, перемещаясь по доске как шахматные ферзи. Малые фигуры перемещаются в тех же направлениях, но только на одну соседнюю клетку. Бой фигур шахматный – если ход завершается на поле занятом вражеской фигурой, она убирается с доски до конца игры.
Фигуры не превращаются. Цель игры – достижение противоположной стороны доски любой из своих фигур. Фигура на последней линии – своего рода шах противнику, он обязан побить эту фигуру следующим ходом, если имеет такую возможность. В противном случае, он проигрывает. Также, игрок будет считаться проигравшим, если все его фигуры будут побиты. Можно потренироваться в игре, перейдя по следующей ссылке.
Проведение турнира
Для проведения турнира будет использована платформа DagazServer. Всем участникам необходимо зарегистрировать учётную запись на сервере, перейдя по следующей ссылке. В целях отладки, рекомендуется зарегистрировать по две учётных записи на каждого участника.

После регистрации учётной записи, можно войти в систему, указав логин и пароль. Впоследствии, параметры учётной записи могут быть изменены, на странице профиля. Участники турнира могут указать в профиле свой EMail, с целью облегчения обратной связи. Указанный адрес электронной почты не будет использоваться в рекламных целях, и не будет передаваться третьим лицам.
После регистрации учётной записи, участникам потребуется зарегистрироваться для участия в турнире. Для этого, потребуется зайти в систему под учётной записью, от имени которой будет играть бот, и перейти по следующей ссылке.
При переходе по ссылке «Alapo», система предложит присоединить учётную запись к турниру. Турнир будет проводиться по круговой системе. Право первого хода, в каждой партии, будет определяться случайным образом. В процессе проведения турнира, будет фиксироваться количество сыгранных игр, побед и поражений, а также вестись Elo-рейтинг игроков. Игрок набравший максимальное количество побед, при минимальном количестве поражений, будет считаться победителем турнира. При наличии более чем одного игрока, с одинаковым количеством побед и поражений, будет проведён дополнительный турнир среди претендентов, до выявления единственного победителя.
С целью ограничения продолжительности турнира, будет вестись контроль времени. Каждому игроку, в игре, будет выделено по 30 минут основного времени и по 20 секунд дополнительного времени на каждый ход, по истечении основного лимита времени. Игрок нарушивший регламент контроля времени будет автоматически считаться проигравшим. Попытка выполнения игроком хода нарушающего правила игры также будет приводить к немедленному поражению.
Взаимодействие с сервером
Взаимодействие с игровой платформой осуществляется по REST API. С целью упрощения процесса разработки и отладки ботов, на время проведения турнира и хакатона, будет открыт HTTP доступ к серверу. Поскольку сервер использует JWT, первое, что должен сделать бот при подключении к серверу – это авторизация.
axios.post(SERVICE + '/api/auth/login', {
username: USERNAME,
password: PASSWORD
})
.then(function (response) {
TOKEN = response.data.access_token;
app.state = STATE.TURN;
});
Полученный access_token должен использоваться в каждом последующем запросе. Авторизовавшись в системе, бот должен получить игровую сессию, в рамках которой ожидается его ход:
axios.get(SERVICE + '/api/session/current/134', {
headers: { Authorization: `Bearer ${TOKEN}` }
})
.then(function (response) {
if (response.data.length > 0) {
sid = response.data[0].id;
setup = response.data[0].last_setup;
}
});
Магическое число в URL-е — идентификатор игры (их на сервере много и будет лучше если бот будет интересоваться только теми играми, в которые умеет играть). Бот не должен предпринимать никаких действий при получении пустого набора строк. Каждая полученная строка будет соответствовать сессии на сервере, в которой от бота ожидается очередной ход. Бот может выбрать любую из полученных строк, сохранив её идентификатор (sid) и описание расстановки фигур в текущей позиции (setup). Если это поле пусто, бот должен игнорировать игровую сессию до тех пор, пока поле setup не будет заполнено.
Далее, бот должен получить идентификатор игрока (uid), который должен использоваться для передачи ходов в эту игру. С момента выполнения этого запроса и вплоть до момента передачи на сервер очередного хода лимит времени игрока на сервере будет расходоваться. Если лимит основного и дополнительного времени будет израсходован до получения хода, партия будет прервана, в связи с нарушением регламента контроля времени.
axios.post(SERVICE + '/api/session/recovery', {
id: sid,
setup_required: true,
ai: true
}, {
headers: { Authorization: `Bearer ${TOKEN}` }
})
.then(function (response) {
uid = response.data.uid;
});
Рассчитав очередной ход, бот должен передать его на сервер. В этом запросе, описание расстановки фигур, полученное после выполнения хода не должно передаваться, поскольку ход будет проверяться арбитром. Арбитр, в любом случае, будет вычислять очередную расстановку фигур и разработчику бота не имеет смысла тратить на это своё время.
axios.post(SERVICE + '/api/move', {
uid: uid,
move_str: move
}, {
headers: { Authorization: `Bearer ${TOKEN}` }
});
После этого, бот может вернуться к получению списка сессий, в которых ожидается его очередной ход.
В рамках проведения турнира, участники могут использовать любой язык программирования для разработки ботов. В случае использования JavaScript, в качестве языка разработки, участникам будет предоставлен скелетный проект бота, для запуска его в среде Node.js.
Используемые нотации
Для передачи боту текущей расстановки фигур используется облегчённая нотация Форсайта-Эдвардса, в соответствии с которой позиция кодируется построчно, с использованием символа ‘/’, в качестве разделителя. Цифры, от 1 до 6 обозначают последовательности пустых полей, латинские буквы нижнего регистра – чёрные фигуры, а верхнего – белые. Поскольку в игре нет рокировок и взятия на проходе, соответствующие разделы FEN-нотации опускаются. Таким образом, начальная позиция игры кодируется следующим образом:
rbqqbr/wfkkfw/6/6/WFKKFW/RBQQBR wФигуры, соответствующие шахматному слону (B), ладье (R) и ферзю (Q), обозначаются в соответствии с соглашениями принятыми в шахматном сообществе. Для обозначения фигур перемещающихся на одно поле использованы обозначения нотации Betza: фигура перемещающаяся ортогонально – Wazir (W), по диагонали перемещается Ferz (F), а движение во всех 8 направлениях соответствует ходу короля (K). Следует отметить, что хотя маленькие круги в Alapo перемещаются как шахматный король, в игре они не имеют никакого специального значения – защита этих фигур от возможных угроз не является обязательной.
Для кодирования ответных ходов бота используется алгебраическая шахматная нотация. Столбцы доски обозначаются буквами латинского алфавита от 'a' до 'f', горизонтали, снизу-вверх, пронумерованы от 1 до 6. Обозначение каждого поля состоит из буквы и цифры. Таким образом, любой ход кодируется обозначениями начальной и конечной позиций, разделёнными символом '-', без пробелов. Например, одним из возможных ходов, из начальной позиции, является 'a2-a3'. Обратите внимание на то, что соблюдение этих нотаций очень важно для разработчика бота. Все ходы, передаваемые ботами на сервер, контролируются арбитром. Ход, который не удастся корректно декодировать будет расценен как некорректный, что приведёт к немедленному поражению сформировавшего его бота.
Рекомендации по разработке бота
Разработка ботов для шахматных игр имеет давнюю историю. Уже в 1769 году, для развлечения королевы Марии-Терезии, был создан “Механический турок”, предназначенный для игры в шахматы. Разумеется, это было жульничество. Внутри машины сидел живой гроссмейстер. С появлением компьютеров идея обрела второе дыхание. Знаменитые математики Алан Тьюринг и Клод Шеннон стояли у истоков этого движения. Первая компьютерная программа была создана в 1952 году и была предназначена для упрощённого варианта шахмат, на доске 6x6, без шахматных слонов. В настоящее время, существуют три основных подхода к разработке ботов для абстрактных настольных игр с полной информацией:
- Минимаксные алгоритмы
- Метод Монте-Карло
- Использование нейросетей и глубокого обучения
Начнём с нейросетей. Это самое молодое и, в настоящий момент, наиболее перспективное направление в разработке игровых ботов. Хотя исследования в этой области ведутся ещё с 40-ых годов прошлого века, подлинный триумф нейросетей произошёл в марте 2016 года, когда AlphaGo – программа разработанная компанией Google DeepMind победила обладателя 9-го профессионального дана в игре Го, Ли Седоля со счётом 4:1. В последующем, этот подход был усовершенствован и обобщён на другие игры, в рамках проекта AlphaZero. В настоящее время существуют и другие, распространяемые под открытой лицензией проекты, по использованию глубокого обучения в настольных играх, такие как BetaGo и Leela Chess Zero. К сожалению, использование нейросетей крайне ресурсоёмко. Разработка и особенно обучение нейросети для новой игры с нуля – это не та работа, которую можно выполнить за два дня. Тем, кто интересуется этой темой, могу порекомендовать книгу Макса Памперла и Кевина Фергюсона "Глубокое обучение и игра Го", подробно разбирающую особенности и механизмы работы проектов Alpha Go и Alpha Go Zero.
Минимаксные алгоритмы – исторически самое раннее и наиболее развитое направление в разработке игровых ботов для абстрактных игр. Первоначально, критерий минимакса был сформулирован Джеймсом Уолдгрейвом в 1713 году. Впоследствии, Джоном фон Нейманом, в 1928, была доказана теорема Неймана-Моргенштерна о минимаксе, что послужило отправной точкой в становлении теории игр в качестве самостоятельного раздела математики. На практике, применение минимакса связано с различными оптимизациями, наиболее известной из которых является Альфа-бета-отсечение.
Применение минимаксного алгоритма с альфа-бета отсечением является наиболее очевидным решением, в приложении к нашей задаче. В качестве отправной точки, можно использовать исходный код шахматного бота GarboChess-JS. Это не самый сильный, на настоящий момент, шахматный движок, но важным его достоинством является наличие открытого и понятного исходного кода.
Прокомментирую основные моменты, на которые стоит обратить внимание. Прежде всего, обратите внимание на то, как кодируется внутреннее представление доски [1321]. Такое представление оставляет часть полей массива неиспользуемыми, но облегчает доступ к номеру строки и столбца, сводя его к битовым операциям. Кроме того, заполнение «бордюра» вокруг доски зарезервированным значением [1497] позволяет легко обнаруживать ситуацию выхода за пределы доски, при выполнении очередного хода. Также, обратите внимание на то, как кодируются фигуры [1136] и выполняется переключение очерёдности хода [1651].
Генерация ходов [2008] отделена от их выполнения [1649]. Для выполнения отката хода [1855], используется стек, сохраняющий основные параметры позиции [2266], такие как: начальная оценка позиции, фигура взятая ходом, признаки шаха, взятия на проходе и возможности рокировок.
Сам алгоритм поиска лучшего хода [194] построен в соответствии с концепцией "итеративного углубления". Дело в том, что алгоритм альфа-бета отсечения [1019] наиболее эффективно работает при выполнении поиска на фиксированную, наперёд заданную глубину. Однако, при наличии ограничений по времени на поиск лучшего хода, мы не можем предсказать заранее, на какую глубину удастся просмотреть дерево игровых состояний полностью. По этой причине, поиск начинается со значения maxPly=1 и далее углубляется до тех пор, пока остаётся неиспользованное время.
Конечно, это означает, что позиции в корне дерева будут рассматриваться многократно. По этой причине, записи об этих узлах хэшируются [615] в оперативной памяти, с использованием механизма "таблицы транспозиций". Разумеется, это означает, что необходим какой-то ключ, для того, чтобы отличать одну позицию от другой. В качестве такого ключа используется Zobrist-хэш. Для каждого расположения каждого типа и цвета фигуры на доске генерируется псевдослучайное число [1354], после чего, эти значения суммируются, с использованием «исключающего или» [1473]. Бонусом в использовании такого подхода является то, что движок запоминает результаты расчётов предыдущих ходов и сможет за отведённое время углубляться дальше, при условии того, что хэш «таблицы транспозиций» не будет очищаться в промежутке между расчётом ходов.
Ещё одним важным моментом является то, что мы не можем оценивать произвольную позицию, возникшую на доске в середине партии. Для корректной оценки, необходимо “доиграть” позицию до «спокойного» состояния [478], в котором нет непосредственных угроз фигурам и королю. Кроме того, любые отсечения, используемые помимо альфа-бета отсечения, способны значительно улучшить производительность алгоритма [817]. Обратите внимание на то, каким образом AllCutNode вызывается из функции AlphaBeta [1069].
Предварительная сортировка ходов также очень важна для обеспечения высокой производительности. Дело в том, что алгоритм альфа-бета отсечения работает наиболее эффективно в том случае, если лучшие ходы рассматриваются в первую очередь. Проблема заключается в том, что в середине партии, определить, какой ход является лучшим, довольно трудно. Обычно, используется следующий порядок просмотра ходов:
- Лучший ход из предыдущей итерации
- Атакующие ходы, ведущие к выгодному размену
- Ходы Killer Heuristic
- Тихие ходы
- Невыгодные размены
Очевидно, что в разных итерациях maxPly, порядок ходов, для одного и того же узла, может изменяться. В GarboChess, задачу сортировки ходов решает вспомогательный объект MovePicker [692]. Выгодные размены определяются функцией See [2280], с использованием алгоритма "Static Exchange Evaluation".
Осталось поговорить об оценке позиций [431]. До завершения игры, оценить позицию на доске можно только приближённо, основываясь на различных эвристиках. Основу оценки составляет g_baseEval – значение, модифицируемое при выполнении каждого хода. Эта оценка включает в себя как стоимость материала, так и бонусы, за расположение фигуры на той или иной позиции [250]. Обратите внимание на использование flipTable, для “переворачивания” доски, при расчёте хода чёрных [1367]. Помимо базовой оценки, в оценку включаются бонусы, добавляемые различными эвристиками (например, наличие на доске двух разнопольных слонов даёт бонус к оценке [443]) и мобильность. Фактически, мобильность – это количество полей, находящихся под боем фигур, но угроза фигурам противника или защита своих фигур могут оцениваться дополнительно [330]. От качества работы функции оценки во многом зависит сила игры всего бота, но нельзя делать эту функцию слишком медленной. То, насколько быстро она работает, напрямую влияет на количество позиций, оцениваемых за выделенное время, а значит и на качество работы всего алгоритма.
Что касается метода Монте-Карло – он проще. Не требуется оценочная функция, какие-то эвристики для выбора лучшего хода и т.п. Из списка возможных ходов просто выбирается ход и доигрывается до завершения игры, с учётом того, что оба игрока выбирает ходы случайным образом (из списка допустимых правилами ходов, конечно). Количество побед и сыгранных игр подсчитывается, после чего, выбирается ход, ведущий к выигрышу в наибольшем количестве сыгранных игр. Достаточно интересна задача частоты выбора первого хода, получившая название "задачи многорукого бандита". Одним из возможных решений является применение алгоритма "Upper Confidence bounds applied to Trees". В отличии от детерминированных минимаксных алгоритмов, метод Монте-Карло изначально является стохастическим и в одной и той же позиции может несколько возможных вариантов ответного хода. Метод Монте-Карло требователен к вычислительным ресурсам. Может потребоваться доиграть до конца тысячи партий, чтобы получить адекватную оценку позиции. С другой стороны, в отличии от минимаксных алгоритмов, метод Монте-Карло может быть эффективно распараллелен и линейно горизонтально масштабируется при добавлении вычислительных ресурсов.
Итак
Вроде бы всё что надо сказал. 4-го числа — турнир, 2-го и 3-го — подготовка к нему, в форме хакатона. Возможно командное участие. Я буду на связи и с удовольствием помогу как с разработкой бота, так и в плане интеграции с игровой платформой.

