
Orchest содержит Jupyter Notebook, не требует ациклических ориентированных графов, а работать можно на Python, R и Julia. Также можно запустить сервис VSCode, метрики TensorBoard — и это далеко не всё. Руководством о создании конвейера ML при помощи Orchest делимся к старту флагманского курса по Data Science.
Чтобы обучить и оценить модель, воспользуемся данными двоичной классификации Kaggle В-клеточной антигенной детерминанты COVID-19/SARS. Разбирать код и рассматривать работу модели мы не станем: детальное объяснение смотрите в этом проекте.
Для классификации пептидов на две категории (антитела с индуцирующими свойствами обозначаются как положительные (1), антитела без индуцирующих свойств — как отрицательные (0) будем использовать наборы данных SARS-CoV и B-клетки. Всем, кому интересно узнать, как читается этот набор данных, рекомендуем ознакомиться с соответствующей научной статьей.
Orchest
Конвейер на Orchest состоит из этапов, то есть исполняемых файлов, которые выполняются в изолированной среде. Соединения определяют способ передачи данных. Возможно визуализировать прогресс, отслеживая каждый шаг. Также возможно запланировать запуск конвейера на информационной панели получить полный отчёт.

Дополнительные сервисы
В Orchest есть и другие сервисы: визуализация метрик производительности на TensorBoard или возможность писать код в VSCode. Эти сервисы без проблем интегрируются в одну и ту же среду.

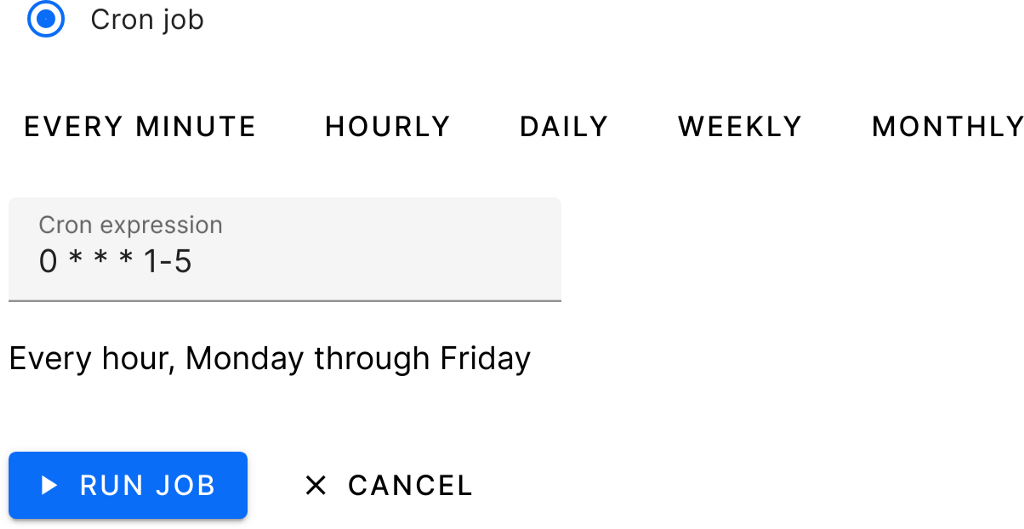
Запуск по расписанию
Запуск конвейера можно запланировать, вплоть до часа и минуты. Это делается так же, как в Airflow. Писать код или отслеживать конвейер при этом не нужно.
Установка
Windows
Обязательные требования:
Последняя версия Docker Engine.
Docker должен работать с WSL 2.
Ubuntu 20.04 LTS для Windows.
Запустите приведённый ниже скрипт в среде Ubuntu.
Linux
Для Linux нужна последняя версия Docker Engine и этот скрипт установки зависимостей:
git clone https://github.com/orchest/orchest.git && cd orchest ./orchest install # Verify the installation. ./orchest version --ext # Start Orchest. ./orchest start
Первый проект
Запустим локальный сервер. Вводим скрипт в среде Ubuntu: виртуальная среда Linux будет запускаться на Windows. Docker Engine должен работать корректно. Запустив скрипт, получим локальный адрес и перейдём по нему в браузере:
cd orchest ./orchest start

Создаём проект, нажав на Create Project:

Проект содержит много конвейеров, перейдём к их созданию. При создании конвейера в каталог с метаданными о каждом этапе автоматически добавляется файл vaccine.orchest.

Возьмём код из предыдущего проекта и сфокусируемся на построении эффективного конвейера:
Прогноз по антигенной детерминанте для разработки вакцины
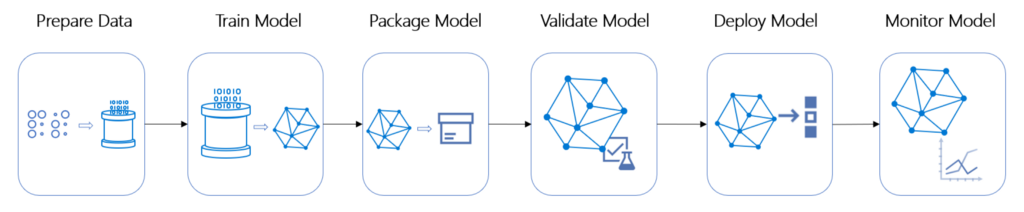
Конвейер ML
Конвейеры машинного обучения — это независимо исполняемый код запуска нескольких задач, связанных с подготовкой и обучением моделей на обработанных данных Azure Machine Learning. На следующем рисунке показана общая для всех проектов модель машинного обучения. Стрелки — это поток данных от одной изолированной задачи к другой, все задачи вместе составляют жизненный цикл ML.
Приступим
По кнопке New Step создаём новый этап. Нам нужно создать шаг. Если файла Python или .ipynb нет, создать его можно так:

Вот и всё. Создадим ещё несколько этапов и попробуем соединить узлы.

Мы добавили EDA (разведочный анализ данных) и этап предварительной обработки. Затем объединили их с этапом загрузки данных так, чтобы у каждого этапа был доступ к извлекаемым данным. Посмотрим, как пишется код.

Создание дополнительных этапов
Чтобы написать новый этап, нажмём на Edit in JupyterLab, — так мы оказываемся в Jupyter Notebook, где и напишем код.

Чтобы запустить все этапы, выделим их, а затем нажмём в левом нижнем углу синюю кнопку Run Selected Steps («Запустить выбранные этапы»). Нажав на любой этап, вы можете просмотреть логи или перейти в блокнот Jupyter и увидеть ход выполнения:
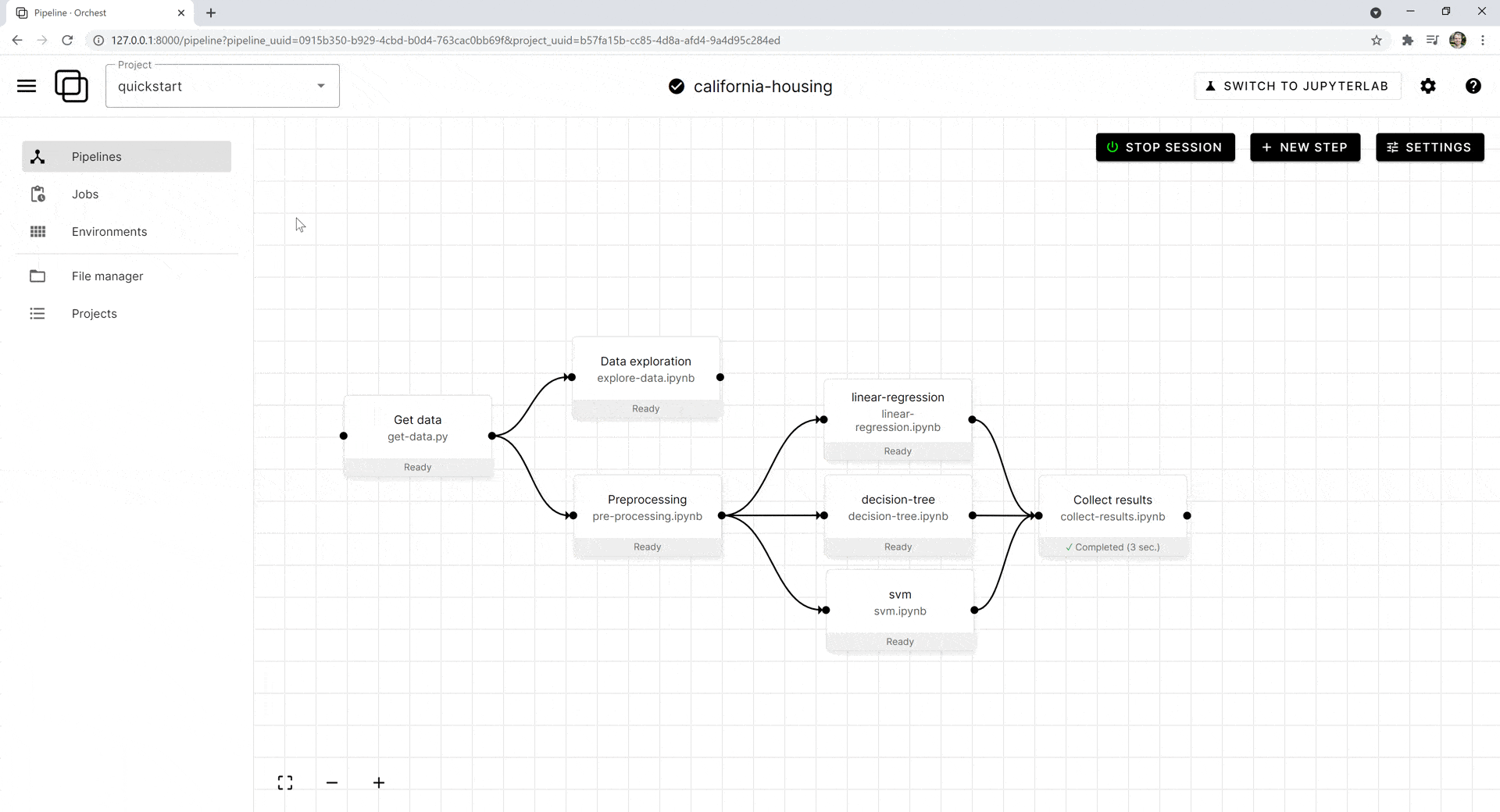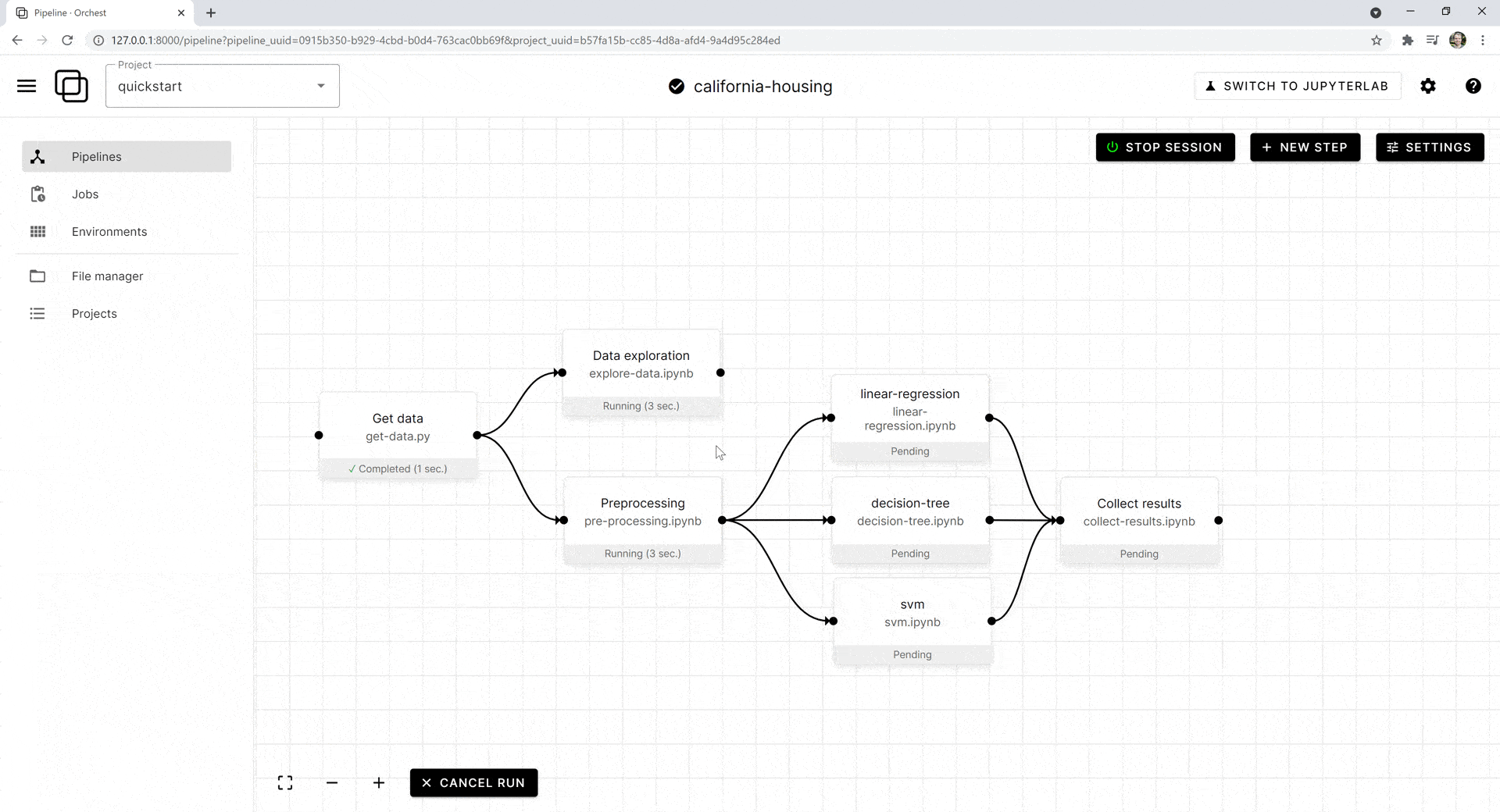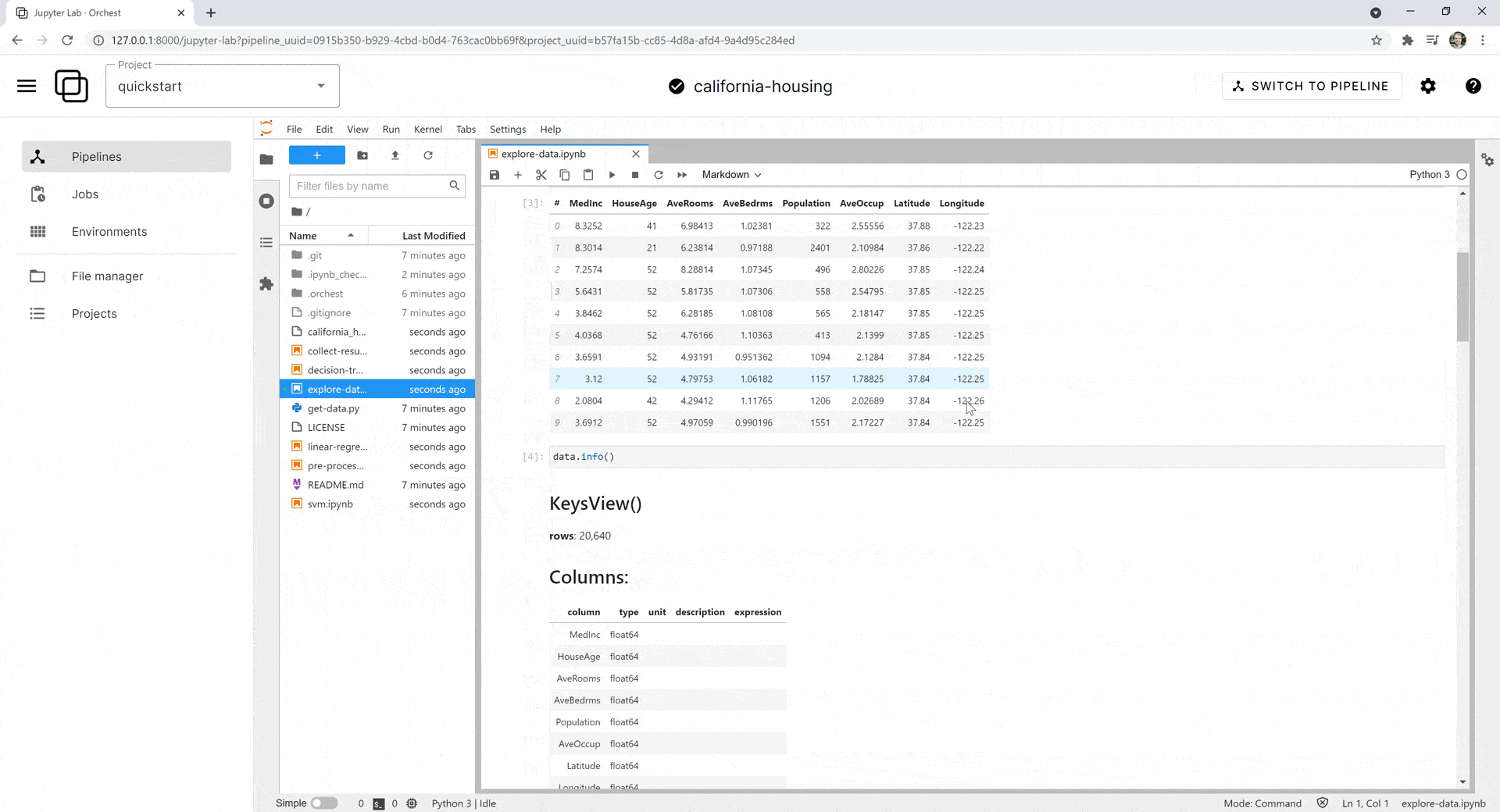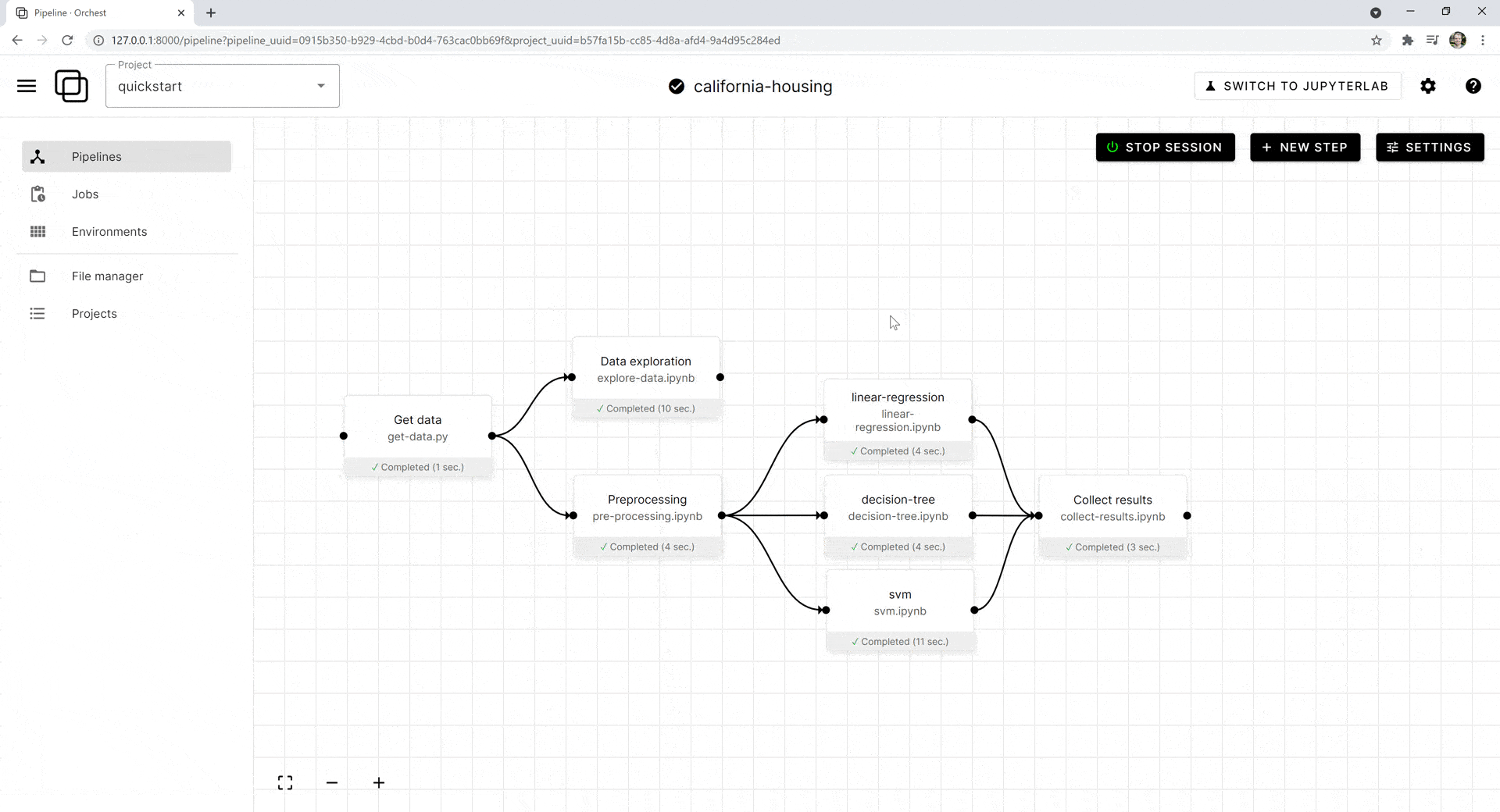
Вывод
Соединив узлы, перепишем код:
импортируем orchest;
загрузим данные с помощью pandas read_csv;
конкатенируем кадр данных bcell и sars;
задействуем orchest.output и через него выведем данные к следующему этапу.
Вывод Orchest принимает одну или несколько переменных и создаёт поток данных, применяемых на следующих этапах. В нашем случае bcell, covid, sars, bcell_sars хранятся в переменной потока данных, которая называется data:
import orchest import pandas as pd # Convert the data into a DataFrame. INPUT_DIR = “Data” bcell = pd.read_csv(f"{INPUT_DIR}/input_bcell.csv") covid = pd.read_csv(f"{INPUT_DIR}/input_covid.csv") sars = pd.read_csv(f"{INPUT_DIR}/input_sars.csv") bcell_sars = pd.concat([bcell, sars], axis=0, ignore_index=True) # Output the Vaccine data. print("Outputting converted Vaccine data…") orchest.output((bcell, covid, sars, bcell_sars), name=”data”) print(bcell_sars.shape) print("Success!") Outputting converted Vaccine data… (14907, 14) Success!
Входные данные
Теперь обратимся к этапу ввода данных. Здесь принимаются все четыре переменные. Чтобы показать поток данных между узлами, добавлено несколько ячеек Jupyter Notebook. Полный анализ смотрите здесь.
Импортируем необходимые библиотеки:
from matplotlib import pyplot as plt from sklearn.decomposition import PCA import orchest import seaborn as sns import pandas as pd import numpy as np
Функцию orchest.get_inputs используем для создания объекта, а затем для получения переменных из предыдущего этапа добавляем имя переменной конвейера данных (data).
data = orchest.get_inputs() bcell, covid, sars, bcell_sars = data["data"]
Загрузка данных из предыдущей задачи прошла успешно.
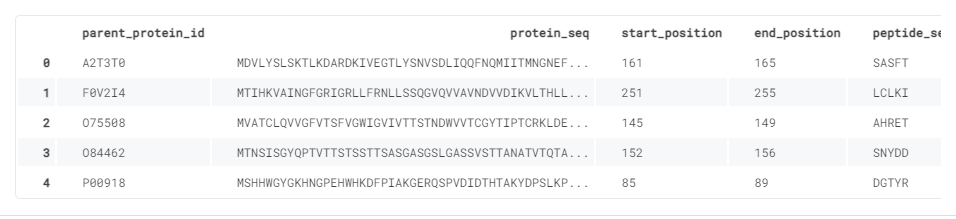
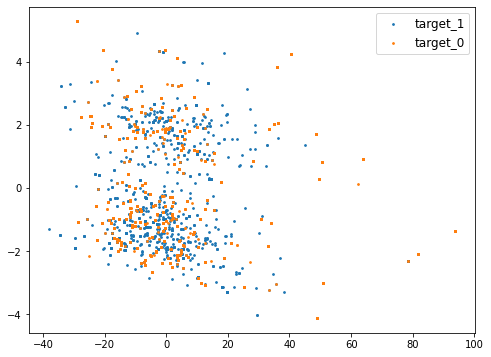
Используем PCA из библиотеки sklearn для уменьшения размерности до 2, а также точечные диаграммы для визуализации целевого распределения.
clf = PCA(n_components=2) z = clf.fit_transform( bcell_sars[["isoelectric_point", "aromaticity", "hydrophobicity", "stability"]] ) plt.figure(figsize=(8, 6)) plt.scatter(*z[idx_train].T, s=3) plt.scatter(*z[~idx_train].T, s=3) plt.legend(labels=["target_1", "target_0"], fontsize=12) plt.show()
Входные и выходные данные
Задействуем теперь функции ввода и вывода для извлечения обучающих данных, которые затем применим для обучения классификатора на основе ансамбля случайного леса. После обучения данные экспортируются для оценки.
import orchest from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import roc_auc_score
На тренировочный и тестовый наборы данные разделяются после шага Preprocessed, именем потока данных служит training_data.
data = orchest.get_inputs() X_train, y_train, X_test, y_test = data["training_data"]
Используем 400 объектов класса estimator и обучим модель на тренировочном наборе. Показатель AUC (площади под кривой ROC) довольно хорош для модели без настройки гиперпараметров.
rf = RandomForestClassifier(n_estimators=400, random_state=1) rf.fit(X_train, y_train) rf_pred = rf.predict(X_test) print("AUC score :", roc_auc_score(rf_pred, y_test)) AUC score : 0.9328534350603439
Выведем модель и прогноз для оценки.
orchest.output((rf,rf_pred), name="rf")
Итоговый конвейер

Загрузка данных.
Разведочный анализ данных.
Использование библиотек EvalML от Alteryx и FLAML от Microsoft для предварительной обработки, обучения нескольких моделей и последующей оценки результатов.
Обработка данных для обучения.
Обучение на наивном байесовском классификаторе, классификаторе случайного леса, CatBoost и LightGBM.
Оценка результатов.
Ансамблирование моделей.
Сравнение точности.
Результат
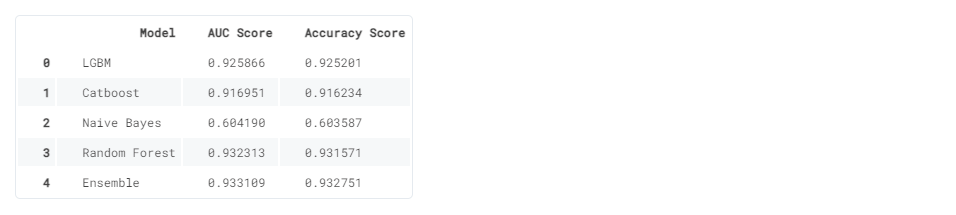
Результаты AutoML:

Результат каждой модели и ансамбля с показателями AUC (площади под кривой ROC) и показателями точности.
Проект
Хотите изучить каждый этап? Тогда смотрите проект на GitHub. Воспользуйтесь также репозиторием на GitHub и загрузите его на локальный сервер Orchest: он запустится с самого начала и с аналогичными результатами.
Облако Orchest
Облако Orchest Cloud работает в закрытом бета-тестировании, но есть возможность запросить доступ и в течение нескольких недель получить его. Загрузка проекта GitHub напрямую прошла легко и гладко.

Заключение
Возникли проблемы с установкой и загрузкой библиотек, но они решились сообществом Orchest в Slack. Впечатления от Orchest просто потрясающие. Думаю, что за ним — будущее науки о данных.
Так наука о данных становится проще и понятнее. Это означает, что умение работать с большими данными на базовом уровне вскоре может потребоваться очень широкому кругу специалистов. Если не хочется отставать от прогресса, на страницах наших курсов вы можете узнать, как мы готовим специалистов в Data Science, в машинном обучении и других направлениях:

Data Science и Machine Learning
Python, веб-разработка
Мобильная разработка
Java и C#
От основ — в глубину
А также:

