
Диспозиция
Зимой мы с коллегами решили поучаствовать в хакатоне Power BI, который проводил один крупный российский портал, посвященный этой BI-системе. Задачей было создание аналитического отчёта о посещении сайта портала. На тот момент мы активно использовали в работе shape maps или карты фигур и нам, естественно, захотелось сделать красивую визуализацию метрик в разрезе географии. Карта была собрана и загружена в отчёт, таблица атрибутов подключена в модели, мера, рассчитывающая интересующий нас показатель (посещения сайта), добавлена на карту и тут нас ждал неприятный сюрприз.

Карта получилась бледной и неинформативной. Выделялись лишь пара ярких пятен: Москва и Санкт-Петербург. Проблема была очевидна: две столицы "оттянули" на себя большую часть посещений сайта, оставив регионы далеко позади. В результате различия внутри основной массы наблюдений оказались настолько слабыми, что условное форматирование при помощи цвета, оказалось абсолютно ненаглядным. Говоря языком статистики, мы столкнулись с выбросами, которые сильно отстояли от основной кривой распределения признака по выборке. Воспользуемся возможностями R, чтобы посмотреть, что из себя представляет наша выборка.

На графике мы видим три выброса, которые и мешают нам раскрасить нашу карту. Кстати, подобная ситуация часто встречается и при заливке таблиц, когда одно значение на порядок отличается от всего массива и полыхает красным (или зеленым), а остальные ячейки окрашиваются в диаметрально противоположный цвет. Посмотрим, как будет выглядеть кривая распределения без них.
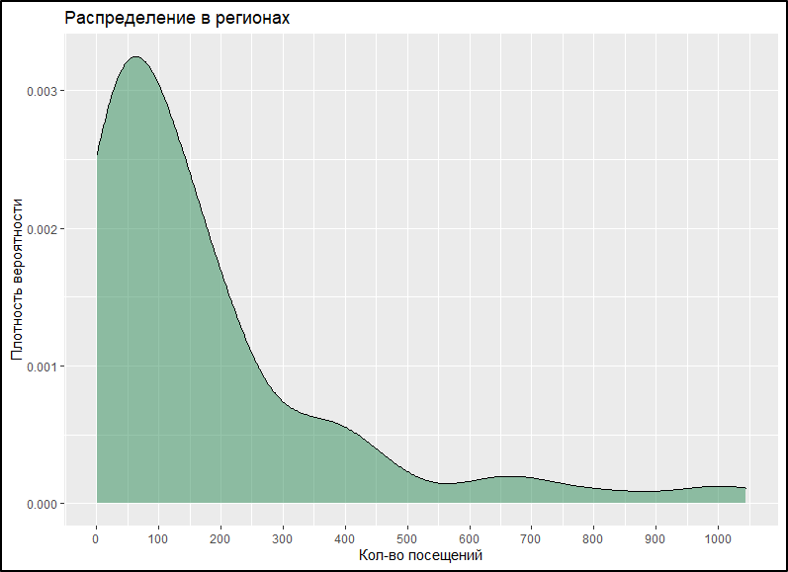
Кажется, что в таком виде все должно работать нормально. Как же устранить эту проблему? Первое, что приходит в голову - удалить выбросы. Но тогда мы потеряем часть данных, и картина будет неполной. Второй вариант - искусственно занизить значения выбросов так, чтобы визуально они все равно остались в топе. Но на сколько занижать? И как? Об этом и расскажу дальше.
Основной ход сражения
Вариант с "подменой" выбросов на другие, подходящие для целей условного форматирования значения, нам понравился. Оставалось только понять, что использовать в качестве "муляжа". В процессе обсуждения звучали разные версии, но все они были нежизнеспособны и отметались практически сразу. Тут-то и вспомнились мне такие далекие, но знакомые слова - "границы доверительного интервала". Как мы знаем, доверительный интервал, в самом простом изложении - это та часть выборки, которая с заданной вероятностью репрезентативна генеральной совокупности.
Может показаться, что в нашем случае никакой выборки нет, ведь мы располагаем всеми существующими данными о посещениях нашего сайта, то есть, фактически имеем в своем распоряжении всю генеральную совокупность. Однако, такая логика будет оправдана лишь в том случае, когда пользователь отчета будет работать со всеми данными без применения каких-либо фильтров. Но, в реальности, такое встречается редко и пользователи рассматривают лишь часть данных, применяя самую разнообразную фильтрацию. Следовательно, использовать понятие "выборка", применительно к данным отчетов, абсолютно справедливо.
Что если заменить наши выбросы на значение верхней границы доверительного интервала? В теории, если мы выберем 99% доверительный интервал, то получим 99,5% значений нашей выборки в нетронутом виде и лишь 0,5% в искаженном. Что ж, попробуем это реализовать.
Мы имеем следующую модель данных:

Таблица фактов, где хранятся данные о посещениях сайта, справочник местоположений, связанный с предыдущей таблицей по ID и таблица атрибутов для нашей карты. В последней хранится служебное поле с наименованием полигона в JSON (GID_1), поле с наименованиями регионов, записанными транслитом как в справочнике (Relationship) и поле с наименованиями регионов для отображения на карте (Регион). Расчеты будем производить в мере. Чтобы определить верхнюю границу доверительного интервала, нам нужно прибавить значение интервала к среднему. Что ж, приступим.
Количество_сессий = var Table_sessions = /* в первой переменной рассчитаем количество посещений в разрезе регионов */ FILTER( SUMMARIZE( /* создаем временную таблицу */ FILTER('GA Посещения сайта'; /* оставляем только данные из России */ RELATED('SHD Параметры местоположений'[Страна]) = "Russia"); 'SHD Параметры местоположений'[Регион]; /* группируем данные по регионам */ "Sessions"; /* создаем новое поле */ SUM('GA Посещения сайта'[Сессии])); /* агрегируем нужный показатель */ NOT('SHD Параметры местоположений'[Регион] in {""; BLANK()})) /* убираем строки с пустым регионом */ var All_table_sessions = /* во второй переменной убираем контекст карты, чтобы рассчитать доверительный интервал для всей выборки */ CALCULATETABLE( FILTER( SUMMARIZE( FILTER('GA Посещения сайта'; RELATED('SHD Параметры местоположений'[Страна]) = "Russia"); 'SHD Параметры местоположений'[Регион]; "Sessions"; SUM('GA Посещения сайта'[Сессии])); NOT('SHD Параметры местоположений'[Регион] in {""; BLANK()})); ALL('Карта_РФ_таблица')) var ci_Ses = /* в третьей переменной рассчитываем верхнюю границу доверительного интервала*/ AVERAGEX(All_table_sessions; [Sessions]) + /* выводим среднее и прибавляем к нему значение доверительного интервала*/ CONFIDENCE.T( 0,01; /* задаем значение альфа, для 99% доверительного интервала оно равно 0,01 */ STDEVX.S(All_table_sessions; [Sessions]); /* считаем стандартное отклонение */ COUNTAX(All_table_sessions; 'SHD Параметры местоположений'[Регион]) /* указываем размер выборки */) return /* наконец, когда все нужные показатели рассчитаны, производим "подмену" */ IF( MAXX(Table_sessions;[Sessions]) > ci_Ses; ci_Ses; MAXX(Table_sessions;[Sessions])) /* для каждого региона выполняем проверку и если количество посещений больше, чем верхняя граница доверительного интервала, то выводим верхнюю границу, иначе оставляем реальное значение */
Наша мера готова. Добавим ее на карту и посмотрим, что получилось.


Добавим во всплывающую подсказку название региона, реальное количество посещений и значение нашей меры, которое назовем "Максимум / 99%".

Выбрав Самарскую область, мы видим, что реальное количество посещений совпадает со значением нашей меры, а значит, оно не превышает верхнюю границу доверительного интервала.

Но если мы выберем Московскую область, то увидим, что значения отличаются, что и является следствием нашей "подмены".
Результат нас устроил, однако, он мог бы быть немного другим. Дело в том, что существует еще один метод определения границ статистически значимой выборки. Он используется при построении диаграммы размаха, или "ящика с усами". Для определения верхней границы, при использовании этого метода, к медиане прибавляется значение межквартильного размаха, умноженное на определенный коэффициент. Чтобы использовать этот расчет в нашей мере, нужно вместо переменной ci_Ses вставить следующий код:
var top_limit = MEDIANX( All_table_sessions; [Sessions]) + /* рассчитаем медиану */ ((PERCENTILEX.EXC( All_table_sessions; [Sessions]; 0,75) - /* рассчитаем межквартильный интервал, для этого из третьего квартиля вычтем первый */ PERCENTILEX.EXC( All_table_sessions; [Sessions]; 0,25)) * 3) /* и умножим его на нужный коэффициент */
В нашем случае подошел коэффициент 3, хотя чаще используется 1,5. По сути, мы сами решаем, какой размах значений будет наилучшим образом описывать нашу выборку. Это удобно при тонкой настройке отображения визуализации, но может привести к непредсказуемому результату со временем, когда выборка будет меняться. Поэтому, мы сделали выбор в пользу автоматизации и оставили первый вариант.
UPD
В комментариях @Ananiev_Genrih предложил, не мудрствуя лукаво, перевести значения нашего показателя в логарифмический масштаб. Это оказалось, действительно, куда проще, чем наши предыдущие экзерциции.
MAXX( FILTER( SUMMARIZE( /* создаем временную таблицу */ FILTER('GA Посещения сайта'; RELATED('SHD Параметры местоположений'[Страна]) = "Russia"); /* оставляем только данные из России */ 'SHD Параметры местоположений'[Регион]; /* группируем данные по регионам */ "Sessions"; /* создаем новое поле */ LOG10(SUM('GA Посещения сайта'[Сессии]))); /* агрегируем нужный показатель и вычисляем логарифм*/ NOT('SHD Параметры местоположений'[Регион] in {""; BLANK()})); /* убираем строки с пустым регионом */ [Sessions]) /*выводим значения*/
Достаточно было использовать функцию LOG10, которая возвращает логарифм числа по основанию 10. Сразу оговорюсь, что я пробовал использовать разные основания, но визуально разница была неразличима. Посмотрим, что же получилось.

Мы видим, что проблему "выбросов" нам удалось обойти, но теперь все регионы стали уж слишком похожего оттенка. А произошло это потому, что предельные значения всего диапазона (2 и 11 880) превратились в 0,3 и 4,07, то есть максимальное значение всего в 14 раз превзошло минимальное. Фактически, произошел обратный эффект: различия "сгладились", что и отразилось на карте.
Картинка будет выглядеть лучше, если мы возведем наш логарифм в квадрат.

И даже в этом случае, на мой взгляд, провести быстрый визуальный анализ ситуации будет достаточно трудно, если вы с детства не тренировались различать оттенки желтого.
Логарифмическая шкала традиционно используется на графиках. Ее даже можно выбрать в стандартных настройках оси визуализации. И именно на графиках она показывает себя наилучшим образом. Ниже, исключительно для примера, приведу две визуализации. И упаси вас Всевышний делать подобное в реальных отчетах :)


Подводя итог, можно сказать, что использование логарифмического масштаба, хоть и помогло устранить нам одну проблему, но не приблизило нас к основной цели - созданию удобного инструмента для быстрого визуального анализа данных.
UPD 2
Недавно в telegram-чате "Power BI Group RU" завязалась дискуссия, касательно предмета статьи, в ходе которой Ilya Koshi предложил интересный способ решения проблемы. Он, как и предыдущий, основан на приведении значений к логарифмической шкале, но задействует еще одну манипуляцию. При расчете, нам надо сравнить каздое значение со средним по выборке и заменить все значения, которые больше среднего на новые. Новые же значения будут представлять собой сумму среднего и логарифма реального значения. Чтобы произвести расчет, вставим в нашу меру, вместо переменной ci_Ses, следующий код:
IF( MAXX(Table_sessions,[Sessions]) > AVERAGEX(All_table_sessions,[Sessions]), /* проверяем условие */ AVERAGEX(All_table_sessions, [Sessions]) + LOG10(MAXX(Table_sessions,[Sessions])), /* если значение больше среднего, то выводим сумму среднего и логарифма значения */ MAXX(Table_sessions,[Sessions])) /* иначе выводим реальное значение
Проверим, как этот способ отработает на наших данных.
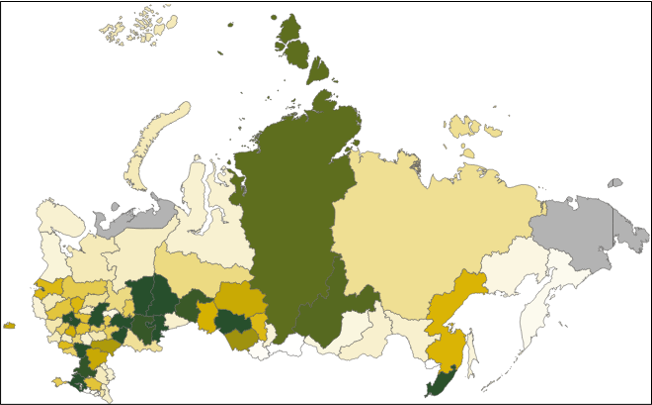
Карта выглядит симпатичной, но на ней появилось очень много "зеленых" регионов. Этим мы обязаны применению логарифма. По сути, произошло то же самое, что и в предыдущем примере. Различия сгладились, но не для всей выборки, а только для тех наблюдений, которые оказались выше среднего. Итак, внешне наша карта стала вполне привлекательной, однако, для задач визуального анализа, она вряд ли подойдет. Ведь, по сути, мы записываем в топ все значения выше среднего, а это может натолкнуть нас на ошибочные выводы. При этом, нельзя не отметить изящество предложенного способа. Думаю, что для определенных специфических задач, он может стать наилучшим решением.
Исход битвы
Итак, путем несложных манипуляций, нам удалось добиться красивой и информативной визуализации данных. Это особенно важно при использовании shape map, так как сам принцип отображения информации на такой карте, основывается на механизме условного форматирования. Естественно, я ни в коем случае не призываю фальсифицировать данные в угоду эстетической составляющей. Все описанные выше манипуляции возможны только при условии информирования пользователей и наличии доступа к реальным, неизмененным данным. Надеюсь, что статья будет полезна всем data-аналитикам, использующим в своей работе Power BI. Кстати, предложенное решение можно легко перенести в Эксель, где тоже встречается описанная проблема. Если вам известны другие методы решения подобного кейса, не описанные в статье, пишите о них в комментариях. Я обязательно опробую их и дополню статью. Буду рад вашим замечаниям и конструктивной критике.
P.S. Целью статьи не был разбор методов математической статистики, поэтому статистические термины в ней истолкованы достаточно вольно. Для их изучения рекомендую воспользоваться специальной литературой ;)

