
Спасибо большое, что все пришли послушать. У нас сейчас будет с вами чуть-чуть другая тема выступления. Мы поговорим про работу с географическими данными уже не с точки зрения такси, а с точки зрения работы с данными про недвижимость, что будет не менее интересно. Меня зовут Андрей Критилин. Я руководитель центра моделирования компании ЦИАН. О чем мы с вами сегодня конкретно поговорим.
Первый вопрос. Что такое вообще AVM модели? Или же говоря по-простому, модель оценки стоимости недвижимости. И как их строить при отсутствии нормальной целевой переменной. Сначала мы сразу хотели перейти в разговоре про географическую неоднородность данных при создании модели оценки недвижимости, как с ней бороться, как можно стэкать модели. Есть пару лайфхаков, как это можно преодолевать. Но перед этим стало понятно, что нужно рассказать, что такое непосредственно модель оценки недвижимости, на западе их называют AVM модели, Automated Valuation Models. И какие конкретно на нашем рынке есть проблемы с их построением. Как их можно на самом деле выбирать, здесь тоже пару советов дам.
Поэтому поехали. Н��ша первая часть. Модель оценки стоимости и проблемы с их целевой переменной. Первый вопрос. Давайте дадим определение, что такое оценка стоимости недвижимости. Это некоторый алгоритм или набор алгоритмов, который позволяет получить стоимость жилья при каком-то среднем сроке экспозиции, потому что у нас стоимость в том числе изменяется во времени, а не только в пространстве при этом по заданным параметрам с какой-то определенной точностью. Зачем вообще нужны модели оценки недвижимости?
Куча причин применения. С точки зрения классических классифайдов, сколько стоит недвижимость – это вопрос, с которым человек попадает на сайт по поиску недвижимости, которую желает как купить, так и продать. Если нужно продать, за сколько продать эту недвижимость. Если нужно купить, как купить так, чтобы купить по адекватной цене в адекватный срок.
Второе применение моделей оценки недвижимости – желание создать их самому, получив данные из ЦИАН, спарсив данные из ЦИАН. Кстати, не делайте так, у нас их можно получить культурным способом. У нас для этого есть раздел на сайте. Для того чтобы использовать в наших ML моделях, потому что недвижимость и сколько она стоит кругом, является для большого количества моделей, банковских, тех или иных, очень неплохим предиктором.
Какая первая проблема, которая будет с моделью недвижимости? Классно. У нас есть много информации о том, какая цена в объявлении. У нас есть информация о том, какая цена происходит в сделке. При этом есть еще какая-то рыночная цена объявления, бывает ли так. Что такое цена в объявлении. Это цена, которую выставляет собственник, дальше он какое-то время по этой цене падает, снижает цену. В какой-то момент цена попадает в рынок, и он уходит с экспозиции. В общем случае.
Что такое цена в сделке? Казалось бы, более близкая переменная как таковая. Это цена, за которую произошла купля-продажа. Конечно, в цене купли-продажи есть и свой минус, потому что то, что написали в договоре купли-продажи, не всегда будет являться отображением действительности, выбросы нужно будет чистить. В ипотечных кейсах ее люди могут завышать.
В инвестиционных кейсах ее часто могут занижать. Но в целом это более правильная цена. А есть еще такая Платоновская, как идеальный объект, рыночная цена, потому что цена в сделке – это результат некого торга как такового тоже сама по себе. При этом сделок у нас будет значительно меньше, чем объявлений. У нас есть хорошая база объявлений. У нас есть огромное количество данных по объявлению, так как меньшее количество данных по сделкам.
Вопрос, как считать и что считать, является открытым. Мы его еще коснемся. При этом стоит понимать, что с точки зрения влияния на целевую переменную, есть еще несколько факторов, которые шуметь будут всегда. Это фактор ремонта, потому что пользователи по-разному оценивают то, как ремонт влияет на их квартиру. И вообще, переменная как таковая, что такое евроремонт, дизайнерский рем��нт, все оценивают по-разному.
Поэтому один и тот же объект с одной и той же стоимостью квадратного метра, с точки зрения цены в объявлении, может абсолютно по-разному шуметь относительно цены сделки. Если я поставил итальянский смеситель в квартиру, поставил его за 50 тыс. рублей, классно, цена моей квартиры, предположим, она стоит 2 млн, 2 млн 50 тыс. рублей. 2 млн за квартиру, 50 тыс. – смеситель. В сделке, скорее всего, покупатель и продавца объяснит, что это не так, мы выровняемся. А в цене в объявлении эта переменная будет шуметь.
Конкурентное окружение вообще классная история, потому что с одной стороны, объект может быть ликвидным. Есть пять однушек на «Бабушкинской», каждая стоит по 5 млн рублей. Но для того, чтобы стать более ликвидной, нужно сбросить цену, потому что пока с рынка не уйдут другие объекты, твой объект не продастся. Они одинаковые, они конкурируют друг с другом.
Чем эта история шумит, с точки зрения цены в объявлении, понятно, что цена в сделке будет примерно та же самая, потому что это вопрос мгновенной ликвидности. Этот фактор нужно ловить в моменте. Срок экспозиции – это отдельная история. Большое количество всяких ноу-хау. Если мы хотим считать цену в оценке, на каком сроке экспозиции ее считать. В сделке понятно, но сделок у нас меньше. Объявление когда брать? Когда ее только поставили в экспозицию, когда ее сняли с экспозиции. Как пользователь менял цену.
И переменная, которая будет шуметь всегда примерно во всех наших видах, кроме Платоновской оценки рыночной цены, которую мы не посчитаем никогда, это навыки продавца. Итого у нас есть большое количество шумящих переменных, про пользователей сейчас еще подробнее расскажу. Что же нам делать, на что нам калиброваться. На самом деле ответ, который придет к нам всегда, это прокси-переменные спешат на помощь.
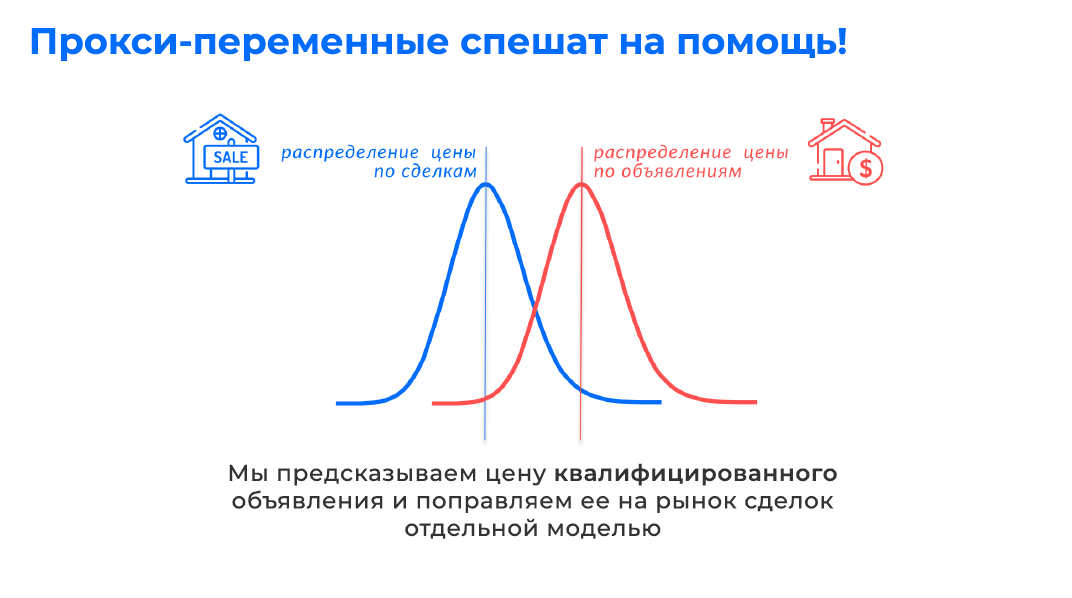
Конечно, лучше всего считать оценку по цене объявления, потому что там лучше всего понять динамику. Если где-то начали падать цены, мы быстрее это видим по цене объявления, чем по цене сделки. Объявлений у нас достаточно много. Но при этом есть сделки, которые все-таки учитывая те шумовые факторы, о которых я только что рассказал, более явно отражают нам рынок недвижимости, потому что это все-таки фактическая цена. Она, с точки зрения ш��ма как-то плюс-минус более близка к идеальной рыночной, несмотря на все свои шумовые факторы собственные, которые мы можем предсказать.
Что делать? Прокси-переменная. Мы предсказываем цену в объявлении. Конечно, большим количеством ноу-хау. Это цена в объявлении, которая у нас проходит поправку на экспозицию, всевозможные чистки данных этого объявления, что это не замануха. Огромное количество разных ноу-хау, в целом наша тема про геоаналитику, поэтому я сейчас буду потихоньку завершаться, потому что это достойно отдельного доклада, как правильно построить оценку именно с точки зрения работы с данными в ней.
Так или иначе, мы считаем цену на объявлении. Дальше мы берем некие наши сделки, которые у нас есть, и просто проводим калибровку наших моделей, которые были построены по объявлениям, мы их калибруем на сделки. То есть мы квалифицируем объявление, предсказываем цену квадратного метра, с точки зрения объявлений по недвижимости и поправляем ее на рынок, но уже отдельной моделью, которая у нас посчитана на сделках. В сделках меньше.
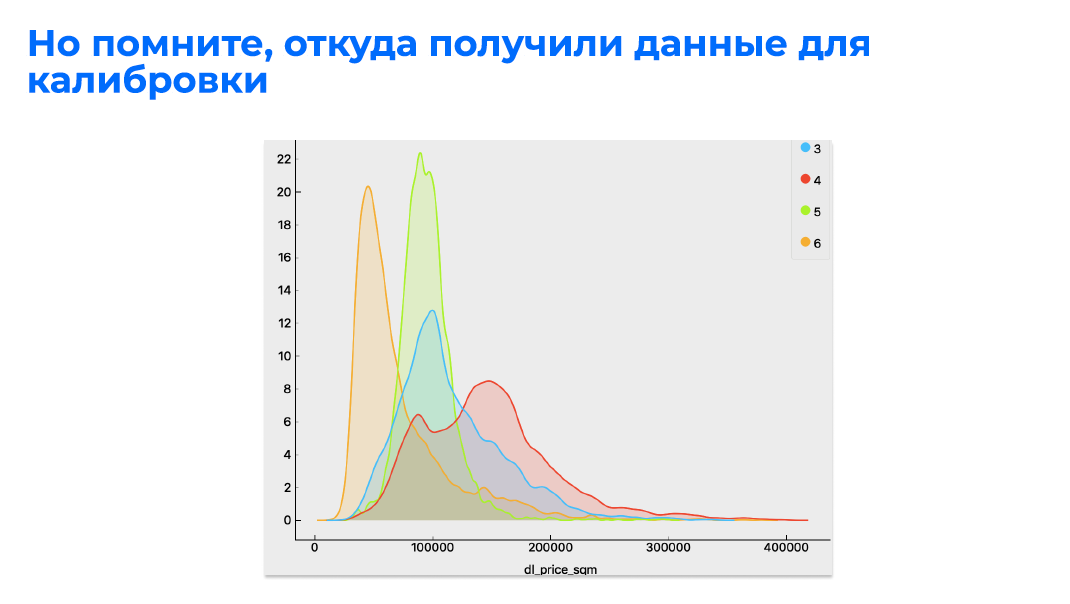
Важно понимать, откуда мы получили данные для калибровки, если используем прокси-переменную. Здесь я интереса ради вывел наши 6 каналов получения информации о сделках с недвижимостью, которые мы получаем от наших партнеров, понятно, это агентства недвижимости в большом количестве, застройщики и у кого есть сделки.
Важно видеть, что на самом деле у всех абсолютно разный как таковой внутренний структурный сдвиг сделок, на которые можно откалиброваться. К примеру, какой-то банк, согласно своей лимитной политике, не кредитует или ограничивает кредитование объектов определенной цены или определенного типа. Не кредитуют трешки, не кредитуют двушки в четырехэтажных домах с деревянными перекрытиями. Таким образом, если мы просто применим нерасширенную калибровку, начнем калибровать именно факт каждого сегмента и кластера домов, у нас, скорее всего, все съедет и получится некая такая странная оценка, которая уже и не оценка по объявлению, но при этом оценка, откалиброванная на какой-то странный внешний фактор.

Потихоньку завершаемся по оценке. Как этот алгоритм работает? У нас на ЦИАН достаточно просто. На ЦИАН он открыт, можно посмотреть. Вводим адрес, комнатность и площадь в наш калькулятор. Получается оценка, диапазон и точность. Под капотом там целый мир, с точки зрения используемых данных. Используются данные на основе объявлений. Про эту сложность я уже рассказал. Используются всевозможные данные о доме из внешних и внутренних источников, как он устроен.
Геоданные, о которых как раз сейчас с вами и поговорим отдельно. Данные об инфраструктуре кругом. Банковские данные о реальных сделках, на которых калибруемся. Все это замешиваем в разные ансамбли методов машинного обучения. Получаем классную ЦИАН оценку, о точности которой я расскажу в самом конце. Уже сейчас мы ее называем в открытую. Цифры у меня записаны в конце. 4,62 медианной ошибки у нас по Москве. Точность нашей оценки. Чуть-чуть еще расскажу про пользователей.
Мы сейчас с вами решали математическую задачу. У нас есть какая-то ошибка, какие-то калибровки. А как пользователь воспринимает нашу оценку. На самом деле пользователь воспринимает оценку абсолютно по-третьему. Это отдельная история как с этим работать. Сейчас расскажу только один пример. Первое – ремонт, о котором я рассказывал. Люди считают, что мы не учли наличие или отсутствие классного ремонта в их квартире. Покупатели считают, что цена завышена и продавцы, что цена занижена, потому что любой продавец считает, что его квартира стоит дороже. Фактор конкурентного окружения может влиять вообще классно и абсолютно наоборот. Тетя Маша продала такую же квартиру, только в другом районе, в другом типе дома и другую за 22 млн. Почему моя стоит 10 млн?
Там есть еще соль того, что оценки бывают разные. Я-то сейчас рассказал по поводу рыночной оценки, которую тоже можно строить на объявлениях, на сделках. Еще есть кадастровая оценка, которую дают оценщики. Люди с ней будут путать. Это отдельный вопрос, как работать с людьми. Самый основной и простой здесь совет – давать не точечную оценку, а давать оценку как таковую в некотором диапазоне. Все равно есть диапазон рыночной цены, которая минует сильное занижение, сильное завышение. Это диапазон объявлений, который с заданным сроком экспозиции. Точно из него уйдут. Поэтому в этом случае, работая с ожиданиями клиентов, стоимость оценки лучше давать в диапазоне.
Выводы по нашему первому разделу. Если строите оценку, и у вас не хватает данных центральной переменной, старый совет: используйте прокси-переменные для калибровки. Второй. Если на что-то калибруете, всегда следите за структурными сдвигами в данных, на которых калибруетесь, откуда вы их взяли. Третий. Интерпретация результатов оценки для пользователей может вообще не сойтись с вашим впечатлениями и тем, что вы предполагали, несмотря на то, какие калибровки вы там применили, как вы точно математически хотели сделать алгоритм.
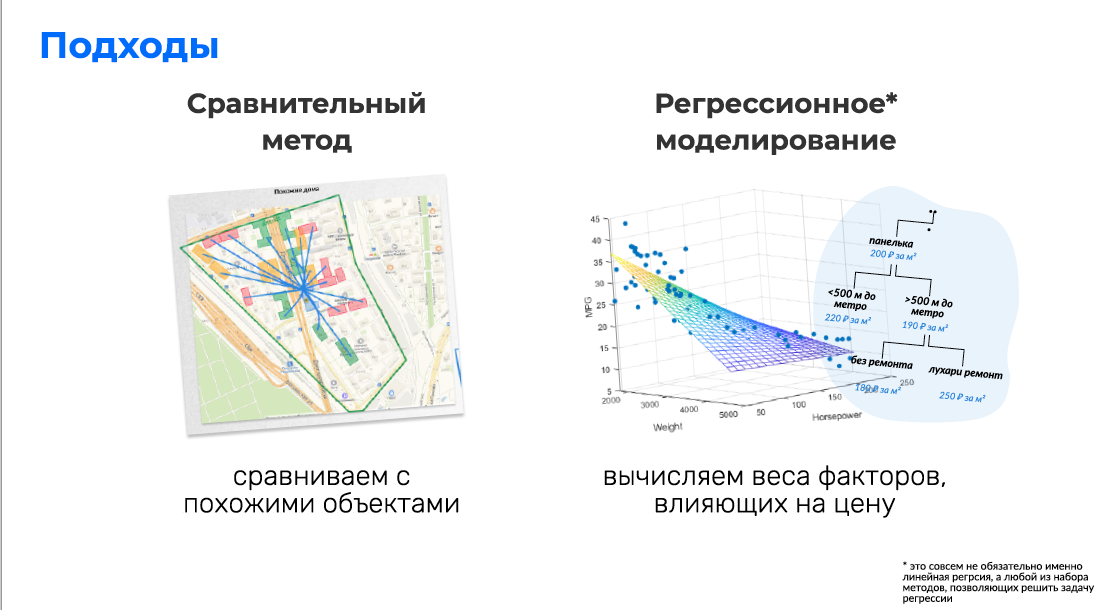
Разобрались с оценкой, что это такое, какие там есть сложности. Ближе к теме нашего доклада, геонеоднородности. Чуть-чуть поближе к ML, какие у нас вообще есть способы, какие два основны�� кластера – построить модель оценки. Первый метод – это классический и в жизни метод оценки. Это сравнительный метод. Возьми похожие объекты, посмотри, сколько они стоят, усредни их.
Плюсы. Выражаясь терминами машинного обучения, мы этого еще коснемся, очень похоже на алгоритм KNN, который всегда устойчивый, классный. Какое-то количество соседей. Кластеризуем объекты, похожие друг на друга. И прямо по соседям с затуханием по эвклидову расстоянию усредняем по ним цены. Классно, хорошо, легко.
Какой минус? Минус тоже был простым. Если с нашей точкой, каким-то домом, стоимость квадратного метра в котором мы оцениваем, нет похожих домов или же есть описанные каким-то внешним географическим фактором искажения, то оценка будет неточной.
Второй способ. Назовем его регрессионное моделирование. Хотя по факту это абсолютно необязательно, как правило, нет линейной регрессии, вообще любой набор методов, позволяющих решить набор регрессии, random forest, все что угодно на самом деле, который вычисляет веса факторов, влияющих на цену. Классический пример. У нас рядом с этим домом нет соседей. Сравнительный метод, который наиболее точный, как правило, в этих моделях работает плохо. Но при этом мы знаем, что мы можем проксимировать, как расстояние до центра города и до ближайшего метро влияет на цену. В Москве, кстати, влияет очень неплохо. Только на этих двух факторах коэффициента детерминации 0,6 можно добиться. Так себе, но какая-то модель уже построится. Итак, у нас есть эти два подхода. Зная эти два подхода, рассмотрим теперь проблему геонеоднородности.
И вот у нас с вами случилась, я это называю проблемой кладбища. У нас есть наши дома. Мы хотим построить по ним модель оценки. На их стоимость влияют какие-то известные нам факторы, расстояние до центра города, тип дома, тип постройки, близость к коммуникациям. Но есть какой-то зашумляющий фактор. У нас здесь где-то посреди домов стоит кладбище.
Мы решили начать строить нашу модель оценки. Что мы первое попробовали. Конечно, давайте попробуем сравнительный метод. Пускай это будет KNN. Классный метод, точно работает, реально по факту описывает задачу сравнительного анализа, потому что смотрим ближайшие точки, усредняем их через Эвклидово расстояние.
Классно, хорошо. Классный способ для начала. Но что произойдет. Для простого метода оценки это самое то. Но предположим, что когда у нас этот домик будет сравнивать себя с другими, увидит похожий на себя дом и будет пытаться среднее посчитать. Домик, который стоит рядом, в целом нормальный, так и дом, который находится рядом с нашим географически аномальным кладбищем. Таким образом, хоть сам дом рядом с кладбищем не находится, но оценка в этом доме будет занижена. Поэтому классный метод, но черт побери, кладбище, что делать, как его ввести в модель, как дать понять его модели.
Понятно было, что в KNN вряд ли получится что-то сделать. Но возьмем и попытаемся использовать random forest. Уже веселее будет, если мы введем в модель такую переменную как логарифм расстояния до ближайшего кладбища в метрах. Модель это поймет. Главное, чтобы у нас само по себе кладбище, что возможность посчитать на расстоянии данных было (01:07:11). Про это уже будет попозже. Модель у нас это поймет. Но в целом кладбище у меня игрушечный пример.

На самом деле таких геообъектов, школ, больниц, кладбищ, работающих, неработающих, работающих в минус, не только с точки зрения цены, но и плюс, красивый парк под окном. Географически неоднородных, с точки зрения своего размера. Может быть, не точка, а вытянутый лесопарк, кругом которого находятся дома. Дорожает не только первая линия. Их может быть огромная куча. Если все их попытаться внести в модель, все проклятие размерностей будет наше. Но с этим в целом можно справиться. Я не про то. Что делать, если мы ввели понятие расстояние до кладбища в нашу модель в forest. У нас вот эти вот географически неоднородные кластеры исправились по цене, модель это поняла. Мы научились тем или иным образом это ловить. И вот уже дома, которые не подчиняются общей логике, рядом с кладбищем у нас дешевле.
Что делать, если бы KNN нам более люб, в целом давал неплохую точность как таковую до этого. В нашем случае есть шанс, что в других местах у нас KNN будет работать лучше, сравнивая более близкие дома, чем forest в ряде случаев. Что делать? Часто можно услышать ответ: давайте все забустим, не будем думать, мы у мамы дата-сайентисты.
Нет, важное понимание. Я думаю, все мы это отлично знаем, что применяя любые методы машинного обучения, мы должны понимать, что у них находится под капотом, какую конкретную задачу в каждый конкретный момент мы решаем, потому что иначе можно напороться на стоимость абсолютно неожиданно, работая с не интерпретируемыми моделями, в которые не интерпретируемые данные, не понимать, почему ты там лажаешь. Как было на примере до этого даже с простым, примитивным KNN, не понимая, как работает KNN, проблему кладбища мы там не решим никогда.
Поэтому все забустить и не думать – способ так себе. Вы можете попробовать. Честно скажу, пробовали. Способ так себе как таковой.
Что же делать? Здесь на самом деле приходит простой ответ, который мы сначала сделали у себя, а потом выяснили, что во многих западных AVM моделях, поговорим с западными коллегами, многие так делают, ансамблируй это. Есть такая компания Open Doors. Это достаточно знаменитая американская компания, которая занимается айбаингом. Они занимаются мгновенным выкупом квартир. Большая капитализация. Недавно вышли на IPO. У них бизнес как раз построен кругом модели онлайн-оценки, где они дают оценку, тут же дают моментальный офер, говорят, что они по этой оценки готовы в течение месяца купить объект. Они дают достаточно простой совет. Есть геонеоднородность. Одни модели что-то ловят хорошо, другие модели что-то ловят плохо. Построй максимальное количество моделей, которые умеешь, в которые веришь. Они, кстати, в разных случаях будут давать еще разные полезные эффекты сами по себе. И стэкни их. В данном случае, с точки зрения стэкинга имеется все, что угодно. Это хоть усредни. Отличной идеей будет построить регрессию, стэкнуть через нее.
Так или иначе, первый ответ на проблему кладбища – это не сильно заморачиваться на нее, а построить модели, которые могут ловить абсолютно разную географию в силу специфики и модели. И просто стэкать эти модели. При этом мы должны понимать, как устроена модель. Если мы замешаем все это во что-нибудь интерпретируемое, то скорее всего, какого-то результата мы не найдем. А так какие-то модели можно расстакнуть, посмотреть, какой был результат, стэкнуть их обратно. И в целом мы идем, временами теряя интерпретацию, но понятной истории, хотя бы чего мы хотели добиться, какая модель что умела через стэки, какие плюсы, мы их объединили. Стэкинг модели, с точки зрения оценки географии – классная история.
Усложним нашу задачу. В нашей первой задаче у нас было кладбище, отмеченное на картах. Какой-нибудь USM объект. Мы знали, что оно там есть. Мы ничего не знаем про кладбище. Просто есть какой-то кластер, в котором почему-то падает цена. Мы даже не знаем, что этот кластер существует. Что делать?
Мы предполагаем, что какие-то географические неоднородности существуют. Нам нужно каким-то образом их найти, ошибку поправить. Здесь есть огромное количество способов. Я сейчас остановился только на двух для нашего примера, как можно поправить. Но наиболее тривиальные, при этом при своей тривиальности классно работающие.
Строим любую модель, которую хотим. Здесь может быть даже интерпретируемая, хоть регрессия. Предположим в нашем примере что-нибудь совсем примитивное, учебное. Это расстояние до центра города или до метро. Понятно, модель дает нам какую-то ошибку. Смотрим ошибку этой модели, ищем внутри нашей ошибки равнонаправленные кластера с меньшей, чем обычно, дисперсией ошибки. Понятно было, что выбор самого по себе способа кластеризации, количества точек, трешхолда, это как мы любим, уже на совести исследования.

Какая наша задача? Наша задача – найти какую-то гомогенную область, в которой ошибка отклоняется одинаково, в которой ошибку можно признать гомогенной. Таким образом, что мы нашли. Мы, скорее всего, нашли какой-то фактор, который как раз у нас концентрируется кругом этого самого кладбища, красивого лесопарка или еще чего-то такого.

Конечно, здесь не худо посмотреть его устойчивость, данные историчности, был ли там этот кластер всегда, повыкидывать значения, посмотреть, насколько кластер устойчивый. Но так или иначе, скорее всего, мы его нашли. Дальше в целом уже понятно, что будет. Мы смотрим, какая у нас ошибка кругом кластера. Точнее, почти везде, считаем разницу между нашим кластером и обыкновенной ошибкой. Просто внутри этих кластеров поправляем уже фактическую цену нашей модели, чтобы ошибка соответствовала стандартной ошибке кругом.
Мы увидели, что у нас в этом месте модель ошибается везде одинаково на 30 рублей. признали, что эта ошибка именно в этом моменте является гомогенной, потому что во всех домах в этой локации мы ошибаемся на 30 рублей. Поправили. Мы понимаем, что любую точку, которая оказывается в этом кластере, нужно поправлять на 30 рублей относительно стандартной ошибки модели, которые у нас выдают. Внезапно это решение является достаточно классным, простым даже для интерпретируемых моделей, простых моделей, той же самой линейки и прочего будет давать нам неплохую поправку на то, что классическая линейка у нас не будет иметь в принципе.
Сначала мы говорили про не интерпретируемые модели, ансамбли, про интерпретируемые модели. Как лучше использовать модели оценки. Не интерпретируемые ансамбли дают большую точность. Интерпретируемые модели дают большее понимание. Что кому давать? Не интерпретируемые ансамбли лучше давать пользователю. Ему, как правило, несильно интересно, почему так. Ему дать диапазон цены и не нужно с покупателем торговаться.
Интерпретируемые модели хорошо использовать для поиска инсайта. Они будут менее точными с точки зрения цены. Но при этом можно будет понять, какие факторы повлияли на цену в том или ином месте, что там изменяется, как будет работать большая модель, если послезавтра в этом районе вылупится метро, как начнут изменяться цены вокруг него, на каком расстоянии начнут изменяться цены. А с точки зрения коммуникации, а с точки зрения привязки к основным магистралям, к резервным магистралям. И много еще чего можно как раз будет понять на интерпретируемых моделях. Совет: используйте и то, и то. А еще все это можно отлично стэкнуть и получить uber-модель.
Здесь хочется подтвердить мои слова, что это неплохая истина, а не просто мои размышления. Мы всегда открыто делимся, какая точность нашей модели оценки, которая торчит у нас для Москвы, откалиброванная на сделке. Это точность по максимально близкой прокси-переменной к несуществующей переменной сделка. 4,12 – медианная ошибка для вторички Москвы по нашим моделям. При этом мы ее не прекращая улучшаем. Понятно было, что там есть некоторый предел, после которого ошибку снизить уже нельзя, потому что помним, поправка на торг, на ремонт, еще какие-то вещи. Такую ошибку мы держим. В целом много ноу-хау применили и продумали.

