

Привет! Меня зовут Сергей, я занимаюсь фронтендом спецпроектов в KTS.
В апреле 2020 года перед нами встала непростая задача: разработать игру-раннер с управлением голосом в браузере. Проект задуман, как часть рекламной кампании тарифов «Билайн» на площадках «Яндекса».
В этой статье я расскажу, как мы делали этот проект, какие технические решения принимали, какие технологии использовали и с какими проблемами сталкивались. Возможно, некоторые вещи можно сделать лучше и использовать другие методы и подходы, но все равно надеюсь, что будет интересно.
При разработке использовался наш стандартный стек TS + React + MobX.
Что будет в статье:
Кратко о проекте
Суть геймплея: игровой персонаж двигается по платформам, прыгает между ними и по пути собирает буквы из промокода. Персонаж двигается, только когда пользователь разговаривает, и прыгает, когда пользователь повышает голос или кричит. Если игрок долгое время стоит на месте, сначала приложение выдает на экран подсказку, а еще через некоторое время завершает игру. На главном экране приложения можно поговорить с персонажем: например, узнать о тарифах.
Так выглядит итоговый проект:

Голосовой бот

На главном экране пользователь может пообщаться с главным персонажем Робертом на тему рекламируемых тарифов. Ключевым требованием было голосовое общение с ботом, чтобы пользователь не вводил ничего в чат, а разговаривал с ботом «вживую», ведь проект — это реклама тарифов для мобильной связи.
Из-за этого требования живого разговора в приложении не было кнопок для записи голосового сообщения, как в мессенджерах. Достаточно начать говорить, чтобы голос распознался и начал транслироваться в чате текстом. Персонаж-Роберт должен был отвечать согласно скрипту, в зависимости от сообщения пользователя. Потом пользователь задает следующий вопрос и т.д.
Поэтому мы реализовали следующую схему взаимодействия компонентов:
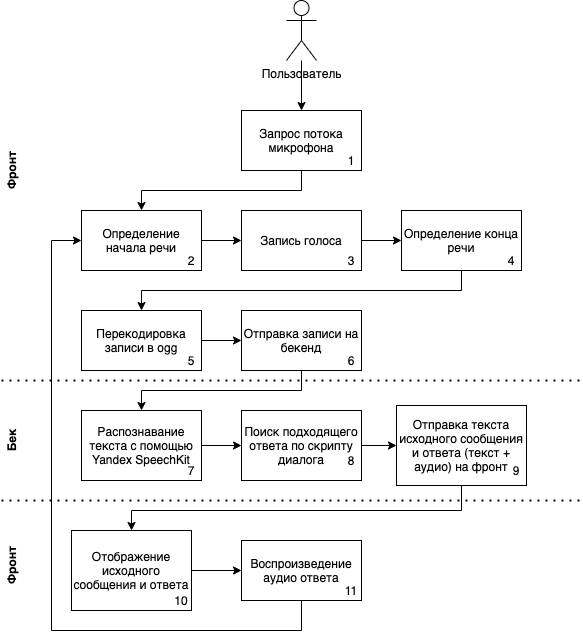
Запрос микрофона
В начале перед открытием чата приложение запрашивает у пользователя разрешение на доступ к микрофону. Для этого создается глобальный AudioContext, и с помощью mediaDevices.getUserMedia получается текущий аудиопоток. В опциях передаем echoCancellation: true, чтобы максимально исключить влияние звукового выхода на входной поток микрофона. Глобальный аудиоконтекст будем использовать в будущем для построения графа операций со звуком, а также гасить его (suspend), когда вкладка не в фокусе, и затем восстанавливать для экономии батареи, cpu и прочих оптимизаций.
Определение речи
Следующая задача — определить, когда пользователь начинает и заканчивает говорить. Мы нашли очень простую, а главное, удобную, библиотеку hark. Пришлось немного адаптировать ее, чтобы использовать заранее созданный контекст и аудиопоток.
Суть библиотеки простая: создается аудиограф, где к исходному потоку (audioContext.createMediaElementSource) подключается AnalyserNode. Это позволяет в реальном времени анализировать массив частот аудиопотока. Дальше с заданной периодичностью можно определять максимальное значение в децибелах для набора частот, например, с помощью getFloatFrequencyData. Если это значение громкости превосходит заданный порог, то в массив «истории» записывается 1, иначе 0.
Изначально массив истории заполнен нулями, что означает, что сейчас пользователь молчит. Длина массива небольшая: она отображает, превышала ли громкость заданный порог в течение последних N проверок. На основании изменения этой истории с 0 на 1 и наоборот в нескольких проверках подряд делается вывод о том, говорит сейчас пользователь или нет, и генерируются соответствующие события, на которые можно подписаться.
Мы делали проверки громкости чаще, если пользователь не разговаривает, и реже, если уже определили начало речи. Это позволило быстро реагировать на старт фразы, чтобы начать записывать голос, и при этом снизить затраты на проверки в течение самой речи.
Запись голоса
Когда происходит событие начала речи, мы запускаем запись. Для этого мы сделали небольшую обертку над библиотекой WebAudioRecorder. В ней создается граф обработки, в котором копия нашего аудиопотока подается на вход ScriptProcessorNode. Несмотря на пометку deprecated, ScriptProcessorNode поддерживается большинством браузеров, в отличие от своей замены — AudioWorkletProcessor.
Ключевая особенность WebAudioRecorder — реализации разных энкодеров, включая нужный нам для последующей обработки ogg. При записи стартует веб-воркер, который кодирует нашу запись в ogg. На выходе получается blob в нужном формате.
Есть множество других библиотек, например, OpusMediaRecorder, и даже браузерных API, например, MediaRecorder. Однако нашей задачей была поддержка как можно бОльшего числа браузеров, и WebAudioRecorder отлично с ней справился.
Мы попробовали разные варианты подключения и сборки всех компонентов в единую систему и столкнулись с разными проблемами при создании аудиографов, в том числе в мобильных браузерах. Но в итоге нам удалось собрать стабильную версию, которая поддерживала iOS 11+.
Распознавание речи и формирование ответа
После получения blob'а записи мы отправляем ее на бэкенд, который отправляет файл в yandex speechkit и получает транскрипцию записи. Использование speechkit было обязательным требованием на проекте. Мы экспериментировали с записью в wav и перекодировкой в ogg, который ожидает speechkit на бэкенде, но в итоге выбрали вариант выше. Он хорошо работает и реализуется на стороне клиента, не нагружая бэкенд.
Speechkit работает качественно, почти без проблем с транскрипцией записи в текст. После получения текста бэкенд ищет подходящий ответ в заданных скриптах.
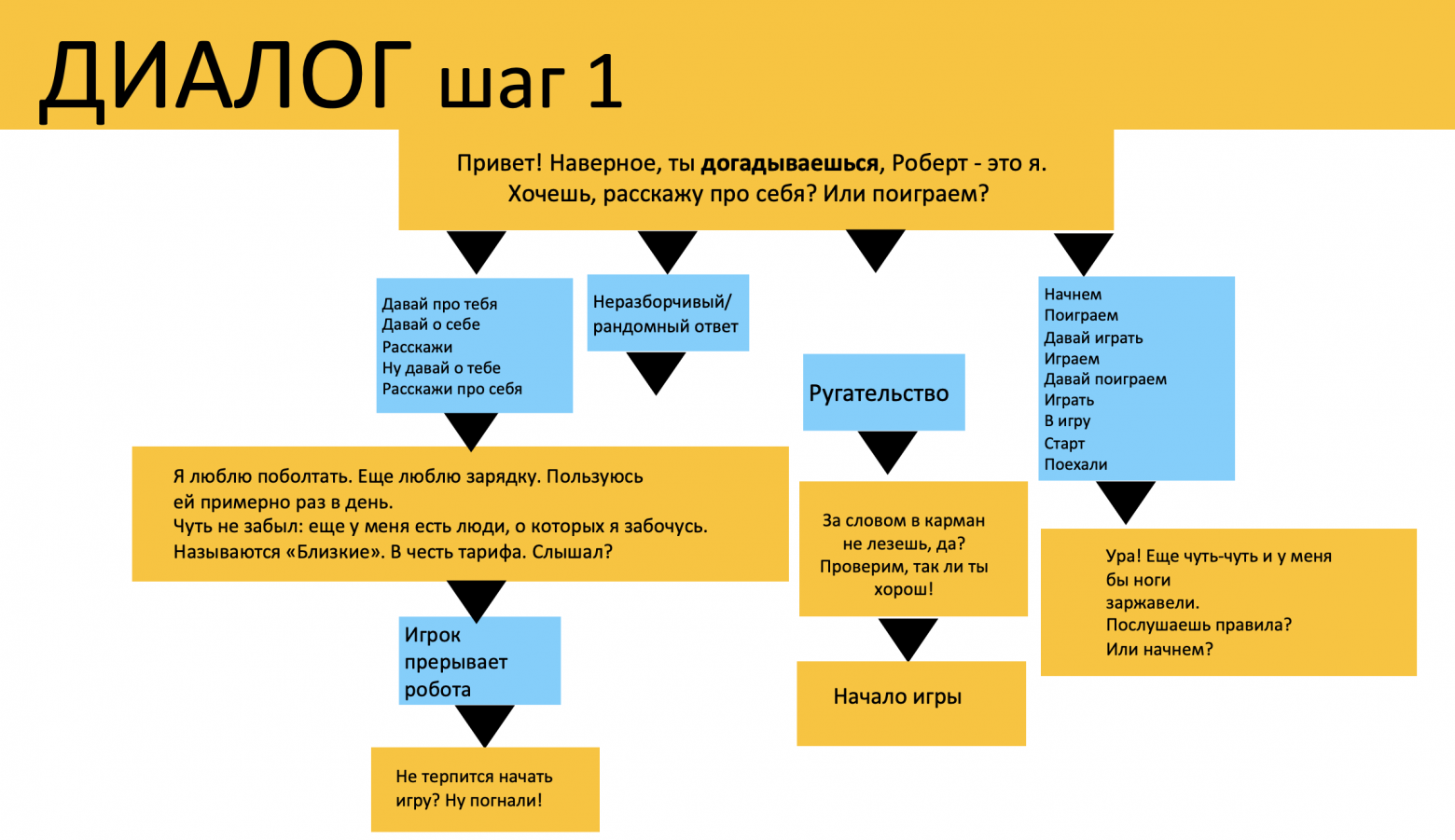
У каждого текста ответа есть соответствующая аудиозапись. Выбранный ответ отправляется на фронт, который отображает транскрипцию сообщения пользователя и текст ответа в чате и воспроизводит аудио.
При разработке мы прослушали записи столько раз, что научились пародировать персонажа и воспроизводить его реплики. А еще приходилось придумывать разные ругательства, чтобы проверять реакцию персонажа, поэтому родилось много локальных шуток и мемов :)
Механика игры
После диалога с ботом пользователь попадает на игровой экран. Механика игры тоже связана с голосом: нужно говорить, чтобы персонаж двигался вперед, и кричать, чтобы он прыгал. Также игроку нужно собирать буквы, которые появляются в течение игры, для получения промокода. Если игрок долгое время стоит на месте, то сначала пишется подсказка, что нужно делать, а потом игра заканчивается.
Для реализации механики мы использовали Phaser. Это движок 2d-игр с удобным API для работы с физикой. Основу игры составляют сцены, которые реализуются классами с некоторыми методами жизненного цикла. Подробно останавливаться на описании возможностей движка не буду, только скажу, что основных методов в сценах 3: preload, create и update. В preload загружаются нужные ресурсы, в create мы создаем все нужные объекты, update вызывается на каждый тик игры.
У нас используется 2 сцены — preload и game. Сцена preload отвечает за загрузку ресурсов и созданию из них объектов спрайтов с анимациями. Так выглядит файл со спрайтами для персонажа:

Внутри спрайтов есть разделение на этап движения, прыжка, приземления и падения. Под каждый из них создается собственная анимация, которую потом можно использовать по ключу:
this.anims.create({ key: animations.playerJump, frames: this.anims.generateFrameNumbers(assets.player, { start: 19, end: 28 }), frameRate: 22, repeat: 0 });
Сцена Game содержит объекты персонажа, пулы платформ и букв (о них позже), методы создания игровых объектов, обновления сцены и вспомогательные методы. Сигнатура класса выглядит так:
export class PlayGame extends Phaser.Scene { skyGroup: SkyGroup; // Пулл облаков platformsPool: PlatformsPool; // Пул платформ lettersPool: LettersPool; // Пул букв player: Player; // Объект игрока // Вспомогательные поля для подсказок startTime = new Date().getTime(); elapsedTime = 0; hintShowed = false; pausedBySilence = false; get passedTime() get audioMeter() // Объект класса измерения громкости create() // Создание всех объектов, физики и установка обработчиков событий async sendGameStart() shutdown() // Обработчик удаления сцены // Методы паузы pause() resume() // Проверка тишины и показ подсказок checkSilence() toggleHint(state: boolean) manageSilence() // Игровой тик, обновление всех игровых объектов update() }
Сама механика игры довольно простая. Для создания подобных игр на Phaser есть много туториалов, поэтому поясню только основные моменты.
В игре генерируются платформы, по которым персонаж должен прыгать, и буквы, которые он должен собирать. Эти объекты хранятся в отдельных классах — PlatformsPool и LettersPool. Классы работают по схожему принципу. Рассмотрим на примере пула платформ.
Изначально генерируется несколько первичных платформ. Платформы бывают разные и отличаются шириной. Со временем мы усложняем игру, генерируя более короткие платформы на бОльшем расстоянии друг от друга.
Каждая платформа имеет некоторую скорость движения. Таким образом, при каждом тике (обновлении) игры платформы двигаются влево. В то же время пул проверяет все объекты внутри себя. Если эти объекты еще находятся на экране, то делать ничего не нужно. Но если они уже «уехали» за левую границу — нужно их уничтожить, чтобы не было утечек памяти. Если расстояние от самой правой платформы до границы игровой области (условно, экрана) достигает некоторого предела, то можно сгенерировать следующую платформу. Этот принцип демонстрируется на картинке:
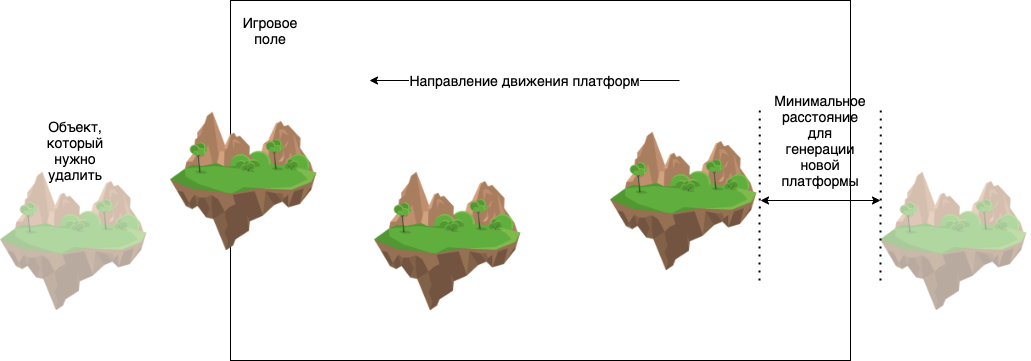
Задача пула — контролировать объекты на поле, удалять и создавать новые.
Внутри класс пула использует GameObjects.Group. Это позволяет добавить обработку столкновений между игроком и сразу всеми объектами пула, например, платформами:
this.platformsPool = new PlatformsPool(this); this.physics.add.collider( this.player, this.platformsPool.platformGroup, this.player.collidePlatform, null, this );
При столкновении вызывается колбек, в котором происходит обработка коллизии. Например, при столкновении персонажа с платформой воспроизводится анимация движения персонажа и устанавливается его скорость, которая должна быть обратной скорости движения платформы. Если этого не сделать, то персонаж «уедет» вместе с платформой за экран:
collidePlatform = () => { this.jumps = 0; this.setVelocityX(this.game.gameOptions.platformSpeed); if (!this.anims.isPlaying && this.runAnimation) { this.runAnimation = false; this.anims.stop(); this.anims.play(animations.playerRun, true); } };
Механику можно реализовать по-другому: добавить скорость персонажу, а все объекты сделать статичными. Тогда камера должна следить за персонажем. При такой реализации все равно нужно удалять объекты за экраном и генерировать их заново, но, вероятно, сложнее добавлять элементы, движущиеся с разной скоростью относительно персонажа — например, облака. Впрочем, в других играх с похожей механикой мы делали именно так, но об этом расскажем в других статьях :)
Если появляется сигнал к прыжку, скорость персонажа по оси X обнуляется, так как платформа перестает «тащить» его за собой влево, а скорость по Y меняется на отрицательное значение: персонаж поднимается вверх. Однако под действием силы гравитации, заданной для игрового мира, эта скорость постепенно увеличивается, становится положительной, и персонаж начинает падать. Таким образом получается дуга: персонаж прыгает.

jump = () => { if ( this.body.touching.down || (this.jumps > 0 && this.jumps < this.game.gameOptions.jumps) ) { this.setVelocityY(this.game.gameOptions.jumpForce * -1); this.jumps += 1; this.anims.setProgress(0); this.jumpAnimation = true; } };
Помимо этого у нас есть генератор платформ, который отвечает за постепенное усложнение игры путем изменения типа платформ, расстояния между ними, их позиции по вертикали и создания букв на них.
Изначально в генераторе заданы 4 типа платформ и вероятность создания каждой из них. С появлением каждой новой платформы вероятность создания наиболее частой платформы уменьшается, а следующей по частоте — увеличивается. Таким образом, все платформы по очереди становятся самыми частыми. В итоге вероятность создания самой маленькой платформы становится больше вероятности остальных:
updateChances(): void { if (this.mostFrequent + 1 === this.platforms.length) { return; } const mostFrequentPlatform = this.platforms[this.mostFrequent]; mostFrequentPlatform.chance -= CHANCE_DELTA; this.platforms[this.mostFrequent + 1].chance += CHANCE_DELTA; if (mostFrequentPlatform.chance <= MIN_CHANCE) { this.updateMostFrequent(); } }
Также сдвигается диапазон расстояния до создаваемой платформы, а вероятность создания буквы на платформе снижается.
Так мы получаем постепенное усложнение игры. В самом сложном режиме в большинстве случаев создаются короткие платформы на большом расстоянии друг от друга, а буквы из промокода попадаются игроку все реже.
Управление голосом
Когда механика игры готова, добавить управление голосом не составляет труда. Мы написали небольшой класс AudioMeter, который работает схожим образом с описанным выше принципом определения начала речи. В этом случае при определении громкости мы берем среднее квадратическое уровня громкости по значениям для всех частот с некоторым усреднением по истории изменения.
Скорость движения платформ, персонажа и других объектов — букв, облаков — линейно зависит от текущего уровня громкости. Если уровень громкости превышает заданный «порог крика», то поступает сигнал к прыжку. Если громкость, наоборот, снижается и пробивает некоторый «уровень тишины», то персонаж останавливается. Если игрок слишком долго молчит, появляется подсказка. Если он продолжает молчать, игра останавливается.

Это важно, потому что цель игры состоит в том, чтобы как можно дольше продержаться и собрать все буквы промокода, то есть «переговорить» всех. Нельзя давать пользователю возможность собрать много баллов просто за счет молчания.
Начальные пороги крика и тишины мы определили по общедоступным данным о громкости речи человека, скорректировав их после тестирования на разных устройствах. Стало ясно, что под все устройства и голоса подстроиться сложно. У кого-то микрофон более чувствительный, кто-то будет держать телефон ближе к лицу. Поэтому мы решили добавить калибровку.

На экране паузы пользователь может откалибровать микрофон, чтобы было проще управлять персонажем. Процедура простая: нужно прочитать рекламную фразу. Пока пользователь читает, мы сохраняем все значения громкости. Затем из этого ряда берем медианное значение и считаем это значение уровнем громкости его голоса при обычной речи. Уровень тишины и крика мы определили как 30% и 130% от средней громкости речи соответственно.
Так мы стараемся подстроить систему под пользователя для комфортной игры на его конкретном устройстве вне зависимости от положения.
Заключение
В проекте мы сделали еще много возможностей, а при разработке столкнулись с рядом проблем: например, нужна была поддержка различных браузеров в различных условиях и адаптация игрового поля под разные разрешения.
В статье я постарался описать ключевые моменты реализации с точки зрения механики и работы с голосом. Возможно, что-то можно было сделать лучше или проще, но для команды проекта работа с аудио на таком уровне была в новинку, пришлось изучить много документации, туториалов и примеров. Поэтому мы довольны тем, что получилось. Это был интересный опыт.
А главное, получился крутой проект, который выполнил поставленные KPI рекламной кампании. Поиграть можно на нашем тестовом стенде.
Другие статьи про frontend для начинающих:
Как работают браузеры: навигация и получение данных, парсинг и выполнение JS, деревья спец возможностей и рендеринга
Другие статьи про frontend для продвинутых:
