
Продакт-менеджерам посвящается...
Заступая на территорию proccess mining, каждый участник рано или поздно будет нуждаться в наборе логов событий, отражающих те или иные специфические моменты в процессах. Эти логи нужны как на этапе демонстрации решения, подсвечивания определенных вопросов, так и для отработки алгоритмов или же тестов на производительность. Оба рекомендуемых сценария «взять с продуктивных систем» или «взять из интернета» терпят фиаско. Как правило, это очень
малые датасеты, слабо удовлетворяющие потребностям как по наполнению, так и по объему.
Остается вариант — написать генератор правдоподобных логов самостоятельно. Тут тоже есть два варианта.
- Вариант первый — превратить эту задачу в универсальный монстроподобный продукт, содержащий визуальный конструктор в нотации BPMN 2.0, всевозможные визуальные конструкторы формул и атрибутов, полноценную имитационную машину под капотом. Годы работы, миллионы на ветер, на выходе — файл с логами. КПД близок к нулю.
- Вариант второй — отнестись к этой задаче как к вспомогательной и создать инструментами data science стека упрощенный генератор в 100 строк кода.
Остановимся далее на втором варианте.
Является продолжением серии предыдущих публикаций.
Постановка задачи
Сформулируем первичный набор требований:
- описание процессов должно быть в конфигурационном файле, ориентированном на редактирование человеком;
- генератор должен поддерживать элементы последовательно-параллельных локальных цепочек описываемых процессов;
- генератор должен создавать файлы логов объемом не менее нескольких гигабайт в сыром виде;
- генератор должен работать быстро (характерный масштаб времени — десятки секунд);
- генератор должен быть простым и компактным.
На этом пока остановимся, этих требований более чем достаточно, чтобы сформировать путь решения и отмести заведомо трудозатратные варианты.
Генератор событий
Первая мысль, которая может прийти в голову — давайте напишем имитационный симулятор и будем по нему гонять цифровых человечков. Это хороший вариант, в R есть отличный пакет для DES — simmer. Можно даже AnyLogic прикупить. Но нам это все не годится по двум причинам:
- процесс надо описывать кодом — какой уж тут конфигурационный файл и BPMN;
- для наших максимальных объемов это будет чрезвычайно медленно.
Воспользуемся такой идеей. Пойдем от обратного — будем не события генерировать, а трейсы. И создавать мы будем их простым Монте-Карло. Потом эти трейсы расщепим и набьем атрибутикой. Договоримся сразу, что трейс у нас будет простой текстовой строкой в которой последовательности активностей разделены заданным символом, остановимся на -. При подобном подходе нам даже не о чем беспокоиться. Большая выборка даст все возможные комбинации для относительно несложных процессов, а после генерации можно сделать однократную отбраковку по критериям. Пакетная обработка на несколько порядков быстрее штучной возни с каждым событием.
Конфигурация процессов
Раз уж мы определились генерацию вести по трейсам, то и конфигуратор процесса нам тоже стоит сделать в пространстве трейсов. Как договорились выше, нотация BPMN нам не подходит в силу ее тяжеловесности. Все же, нам нужны различные вариативности в компактном виде, поэтому можем воспользоваться двумя трюками, заимствованных из семантики регулярных выражений:
- для описания ветвлений будем оперировать подпроцессами;
- для описания циклов воспользуемся квантификаторами.
Естественно, что это ограничивает модели, которые мы можем описать, но простота и компактность и большая гибкость в описании это вполне нивелируют. В силу того, что мы оперируем трейсами, то подпроцессы можно описывать как куски трейсов.
В итоге, остановимся на таком формате:
activity;quantifier ENTER;1 FLOOR_1|FLOOR_2|FLOOR_3;1 (LOOK-DROP)|(LOOK-TAKE);{1,4} (COFFEE-CAKE)|(CAKE-COFFEE);{0,1} (OPEN-CLOSE);{0,2} PAY|CANCEL;1
()— определяют подпроцесс,
|— определяет ветвление (ИЛИ),
{min, max}— определяет квантификатор этого этапа.
В конце мы убедимся, что даже такой тривиальный формат вполне позволяет описывать сложность процессов, необходимую для задач, описанных в постановке.
Код генератора
В первой версии работать будем в однопотоке. Естественно, что для очень больших объемов надо работать в многопоточном режиме и работать по ссылкам.
library(tidyverse) library(datapasta) library(tictoc) library(data.table) library(stringi) library(anytime) library(rTRNG) library(dqrng) library(furrr) library(tsibble) data.table::setDTthreads(0) # отдаем все ядра в распоряжение data.table data.table::getDTthreads() # проверим доступное количество потоков
bo_df <- here::here("data", "process_01.txt") %>% read_delim(delim = ";") %>% # первичный депарсинг mutate(across(activity, ~stri_extract_all_regex(., "([A-Z0-9_\\-]+)"))) %>% tidyr::extract(quantifier, into = c("q_min", "q_max"), "(\\d+),*(\\d+)?") %>% mutate(across(c(q_min, q_max), as.integer)) %>% # у одиночных операций нет верхнего квантификатора mutate(q_max = if_else(is.na(q_max), q_min, q_max)) %>% # для последующей расстановки операций mutate(bo_idx = row_number())
ff <- function(activity, q_min, q_max, bo_idx){ nums <- q_min:q_max # class nums = 'integer' n_cases <- 100000 dt <- data.table(case_id = 1:n_cases, # на каждый кейс сгенерируем квантификатор quantif = dqsample(nums, n_cases, replace = TRUE)) %>% # для одинаковых квантификаторов можем сделать матрицу .[, events := { m <- matrix(dqsample(activity, .BY[[1]] * .N, replace = TRUE), nrow = .N, byrow = TRUE); # делаем свертку по строкам (MARGIN = 1), получаем вектор apply(m, MARGIN = 1, stri_c, collapse = "-")}, by = quantif] %>% # сбросим активности, которые оказались с нулевым квантификатором .[events != ""] %>% .[, bo_idx := bo_idx] dt } tic() # раскрываем квантификаторы для всех трейсов сразу t_dt <- purrr::transpose(bo_df) %>% map(~ff(.$activity, .$q_min, .$q_max, .$bo_idx)) %>% rbindlist() %>% # соберем паттерны по событиям в исходном порядке .[order(bo_idx), .(pattern = stri_c(events, collapse = "-")), by = case_id] toc()
unique(t_dt[, .(pattern)]) %>% write_csv(here::here("data", "model_traces.csv"))
Разворачиваем в событийный лог. Важный момент — чтобы лог был правдоподобным, расчет событий должен вестись сверху вниз, от транзакции к событию. Перекосы случайных распределений исправляем гильотиной в конце. Создаем записи с запасом, все кривые потом просто отбрасываем.
# Важное допущение -- нет параллельных операций, все выполняется строго последовательно tic("Generate events") # транзакции идут одна за другой, в параллель ничего не исполняется # для упрощения задачи мы сгенерируем количество записей с запасом, а потом отсечем по временнЫм границам df2 <- t_dt %>% # для каждой транзакции случайным образом сгенерируем общую попугайную длительность .[, norm_duration := rnorm_trng(.N, mean = 1, sd = .5, parallelGrain = 1000L)] %>% # отбрасываем все транзакции, которые имеют слишком малую длительность или > таймаута # таймаут устанавливаем равным 1.2 условных попугая .[norm_duration %between% c(0.4, 1.2)] %>% # назначим среднюю длительность транзакций (~ 5 секунд на действие) пропорционально числу шагов .[, cnt := stri_count_fixed(.BY[[1]], "-"), by = pattern] %>% .[, duration := norm_duration * 5 * cnt] %>% as_tibble() %>% select(-norm_duration, -cnt) %>% # расщепляем транзакции на отдельные состояния, при этом порядок следования состояний сохраняется separate_rows(pattern, sep = "-") %>% rename(event = pattern) toc()
set.seed(46572) RcppParallel::setThreadOptions(numThreads = parallel::detectCores() - 1) tic("Generate time markers, data.table way") # так примерно в 8-10 раз быстрее samples_tbl <- data.table::as.data.table(df2) %>% # делаем в два захода # сначала просто генерируем случайные числа от 0 до 1 для каждой записи отдельно # и масштабируем одним вектором # в таком раскладе trng быстрее в несколько раз (может даже на порядок получиться) # фактически, здесь мы считаем случайные соотношения времен между операциями внутри транзакции .[, trand := runif_trng(.N, 0, 1, parallelGrain = 10000L) * duration] %>% # делаем сортировку вектора внутри каждой сессии, простая сортировка будет ОЧЕНЬ долгой # делаем трюк, формируем составной индекс из case_id, который является монотонным, и смещением по времени # поскольку случайные числа генерятся в диапазоне [0, 1], мы их утаскиваем в дробную часть (за запятую) .[, t_idx := case_id + trand / max(trand)/10] %>% # подтягиваем в колонку сортированное значение вектора с реконструкцией # session_id в целой части гарантирует сортировку пропорций в рамках каждой транзакции без доп. группировок .[, tshift := (sort(t_idx) - case_id) * 10 * max(trand)] %>% # добавим дополнительной реалистичности, между транзакциями могут быть сдвижки (-60+30 сек) .[event == "ENTER", tshift := tshift + runif_trng(.N, -60, 30, parallelGrain = 10000L)] %>% # удаляем весь промежуточный мусор .[, `:=`(duration = NULL, trand = NULL, t_idx = NULL, timestamp = as.numeric(anytime("2020-06-01 08:00:00 MSK")))] %>% # переводим все в физическое время, начиная от 01.06.2020 (потенциально для каждого объекта отдельно) .[, timestamp := timestamp + cumsum(tshift)] %>% # добавим метку окончания события и длительность .[, duration := round((shift(timestamp, type = "lead") - timestamp) * runif_trng(.N, .2, .6, parallelGrain = 10000L), 2)] %>% .[is.na(duration) | duration < 0, duration := 5] %>% .[, timestamp_finish := timestamp + duration] %>% as_tibble() %>% mutate_at(c("timestamp", "timestamp_finish"), anytime, tz = "Europe/Moscow") %>% select(case_id, event, timestamp, timestamp_finish, duration) toc() gc(full = TRUE) plot(density(samples_tbl$duration))
sample_tsbl <- as_tsibble(samples_tbl, key = case_id, index = timestamp, regular = FALSE) sample_tsbl %>% index_by(year_week = ~ yearweek(.)) %>% # monthly aggregates summarise(n = n()) %T>% print(n = 100) %>% feasts::gg_tsdisplay()
saveProcessMap <- function(df, type){ tic(glue::glue("{type} process map")) # https://github.com/gertjanssenswillen/processmapR/blob/master/R/process_map.R dfg <- df %>% mutate(activity_instance_id = dplyr::row_number()) %>% bupaR::simple_eventlog(case_id = "case_id", activity_id = "event", timestamp = "timestamp", validate = FALSE) %>% # processmapR::process_map(type = processmapR::frequency("relative_case")) processmapR::process_map(render = FALSE) # прежде чем так сохранять, надо проверить наличие директории images checkmate::assertDirectoryExists(here::here("images")) title <- paste("Эмулированный процесс с", ifelse(type == 'complete', 'полным', 'урезанным'), "перечнем событий") DiagrammeR::export_graph( dfg, file_name = here::here("images", glue::glue("{type}_pmap.png")), file_type = "png", title, width = 2560, height = NULL ) toc() } # -------------------- # Переходим к реальной жизни # Окончательно перемешиваем данные и добавим доп. атрибуты actors_vec <- c("Петров", "Иванов", "Петровская", "Иванова", "Сидоров", "Сидоркина", "Ивановская") log_tbl <- samples_tbl %>% select(case_id, timestamp, event) %>% # здесь мы можем сэмулировать частичную потерю элементов транзакций sample_frac(1 - .02) %>% mutate(actor = sample(!!actors_vec, n(), replace = TRUE)) # ------- Сохраняем сгенерированный лог событий fst::write_fst(log_tbl, here::here("data", "fuzzy_manual_log.fst")) # ------- Сохраним полную карту процесса saveProcessMap(samples_tbl, "complete") # ------- Сохраним редуцированную карту процесса saveProcessMap(log_tbl, "reduced")
При формировании выходных представлений не забываем, что
- нам нужны еще атрибуты какие-никакие,
- в реальной жизни иногда могут теряться части событий.
Заключение
Для приведенного кода совокупным объемом ~100 строк весь цикл генерация на «офисном» ноутбуке осуществляется в пределах 30-40 секунд. Картинки процессов даже для такого тривиального конфигурационного файла выглядят очень насыщенными и информативными.
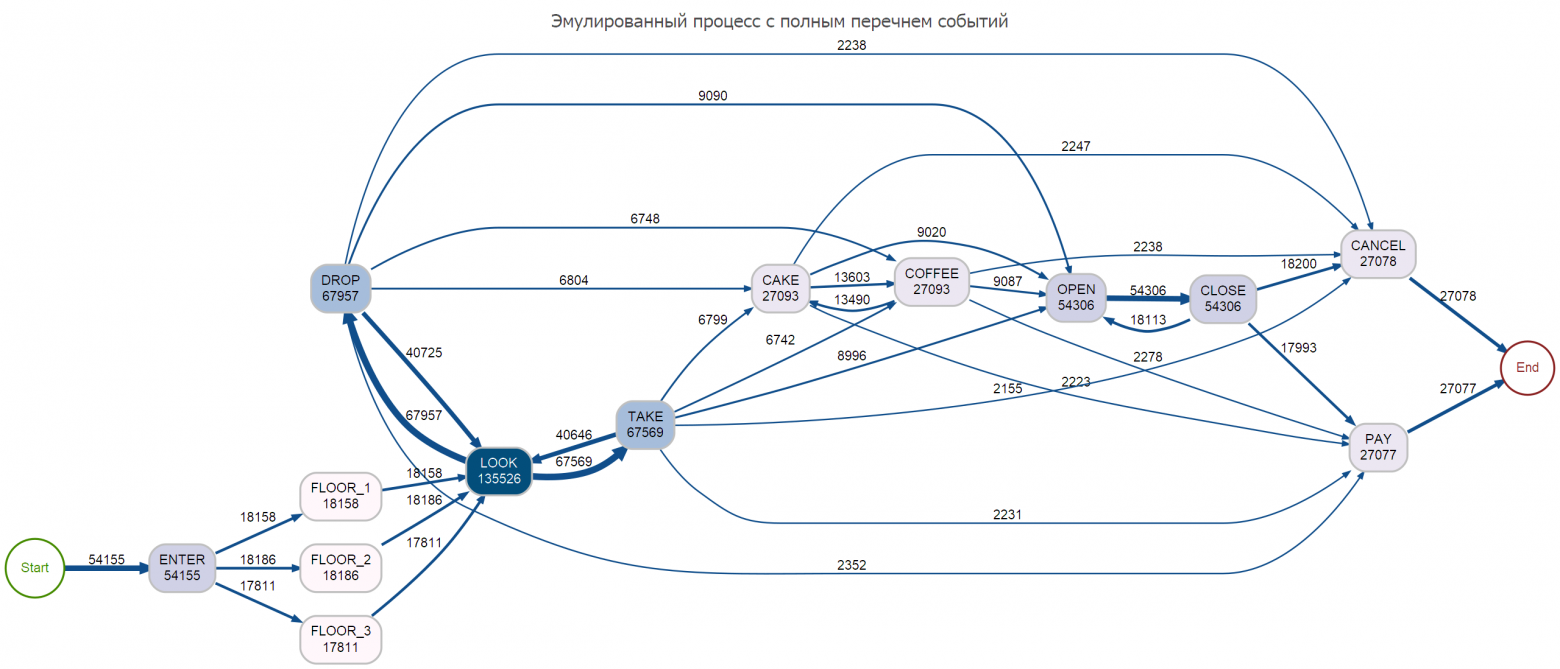
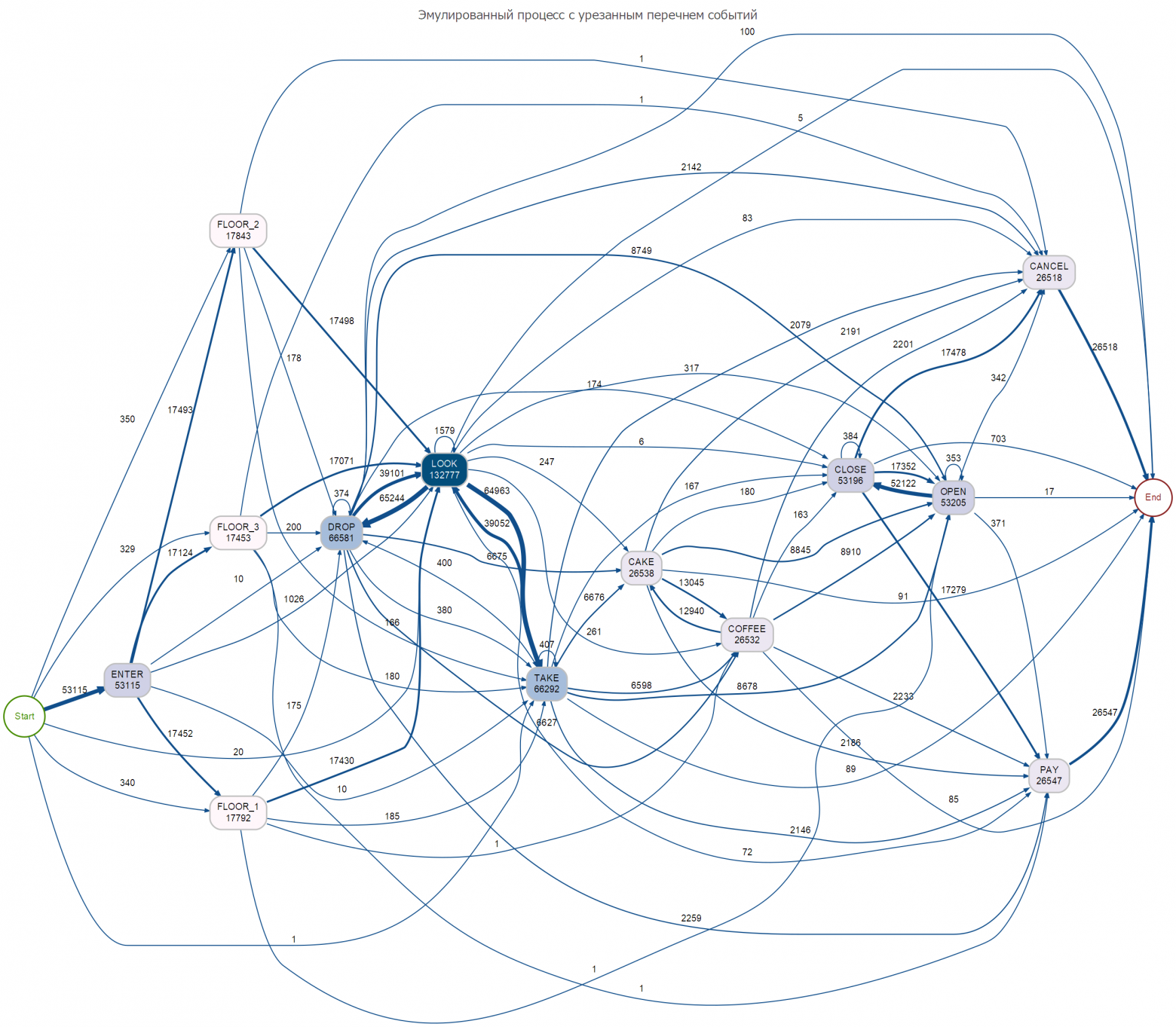
Естественно, что это быстрый прототип. Для более серьезных задач и генератор должен быть
чуть посложнее. В частности, требуется:
- поддержка параллельных процессов;
- поддержка быстрой генерации десятков гигабайт логов;
- расширенное атрибутарное наполнение по типам данных (целые числа, плавающие числа,
дата, дата-время, строка); - расширенное атрибутарное наполнение по точкам привязки (кейс, активность, исполнитель);
- управление статистическими характеристиками генерируемых логов (число типов трейсов,
число транзакций, распределения времен и пр.); - поддержка NA в атрибутах,
- еще что-либо...
Это будет несколько сложнее, но при определенных упрощениях можно поддержать почти все без значимой потери в функционале и без существенного усложнения.
Для поддержки параллельных процессов можно ввести понятие основного пути и параллельных веток в конфигурационном файле. Например, так:
path;activity;quantifier *;ENTER;1 *;FLOOR_1|FLOOR_2|FLOOR_3;1 *;(LOOK-DROP)|(LOOK-TAKE);{1,4} *;(COFFEE-CAKE)|(CAKE-COFFEE);{0,1} 0;(OPEN-CLOSE);{0,2} 0;(UNCOVER-COVER);{0,1} 1<<;THINK|READ;{1,2} 1;WAIT;{0,1} 2<<;THINK|READ;{1,2} *;FLOOR_1|FLOOR_2|FLOOR_3;1 0;(OPEN-CLOSE);{0,2} 0;(UNCOVER-COVER);{0,1} 1<<;THINK|READ;{1,2} 1;WAIT;{0,1} *;PAY|CANCEL;1
где * — основной путь, n — ветка n в идеологии split/join.
И чуть усложнить параметризацию конфиг файл самого скрипта, например, подобным образом:
parallel_1: # имя входного файла с моделью бизнес-процесса model_filename: 'process_01p.txt' # ограничитель по количеству уникальных цепочек, отправляемых на разыменование max_unique_traces: 100 # ограничение сверху по числу генерируемых кейсов max_case_id: 50000 # имя выходного выходного csv лога событий eventlog_filename: 'process_01p' # максимальный размер выходного csv лога событий, в мегабайтах max_log_size_Mb: 7 # средняя длительность одной активности в цепочке, в минутах # 1440 минут = 1 сутки average_activity_duration: 2880 # исключать в финальном логе SPLIT/JOIN remove_split_point: TRUE # имя файла с параметрами атрибутивного наполнения (если есть), либо пустота attr_sample_config: 'attr_samples_default.xlsx' # следует ли генерировать перемешанную подвыборку generate_fuzzy_log: TRUE # следует ли генерировать графические карты процессов generate_process_maps: TRUE
Есть задел, вполне можно двигаться дальше.
И, кстати, при создании программных продуктов подобные задачки встречаются десятками. Опытный продакт не будет распылять дорогие ресурсы сеньоров на создание "продуктов-сателлитов", а воспользуется инструментами DS.
Предыдущая публикация — «ETL в анализе данных без перерывов на кофе и курилку».

