
Начнем с точки входа в приложение. Чтобы инструмент удобно было использовать, напишем приложение с командным интерфейсом. Перед началом работы также стоит создать переменное окружение и активировать его.
Для обработки параметров командной строки в Python есть удобный модуль click (установка pip install click). Обработка аргументов командной строки происходит при помощи добавления к функции декораторов. Определим обязательные параметры: search_path — путь по которому будем искать, либо файл с путями и дополнительные: режим исполнения программы (многопоточный или без), имя файла с результатами, формат записи результата (excel, csv, sqlite) и другие параметры по вашему желанию.
@click.command() @click.argument('search_path', type=click.Path(resolve_path=True, dir_okay=True, file_okay=True), required=True) @click.option('--concurrent_mode', '-cm', type=click.STRING, required=False, default="None", help="Concurrent search execution(multi or single)." " Multi allows multiprocessing and threading") @click.option('--output_path', '-o', type=click.STRING, required=False, default='results', help="Output filename(without extension)") @click.option('--output_type', '-ot', '-out', type=click.STRING, required=False, default='sqlite', help="Format for output data((excel, csv, sqlite, mssql)") ... def main(search_path, output_path, concurrent_mode, output_type): """ Starts search info(cards numbers) in files in path search_path: path to search or json file with paths """ ... if __name__ == "__main__": main()
Функцию поиска содержимого будем вызывать из функции main(). В данном случае вызов выглядит следующим образом:
multi_mode = True if not concurrent_mode.lower() == "single" else False search_in_files(search_path, file_types, output_path, maxsize, buffer_size, clear_results, clear_log, continue_option, multi_mode, output_type, debug, include)
Совершим настройку логирования для сохранения информации о произошедших при исполнении скрипта ошибок. Для этого прекрасно подходит встроенный модуль logging. Информация будет записываться в файл лога.
LOGGING_FORMAT = ('%(asctime)s %(levelname)s %(filename)s - ' '%(funcName)s %(message)s') logging.basicConfig(filename="program_log.log", filemode='a', level=logging.INFO, format=LOGGING_FORMAT)
В качестве аргументов командной строки может поступать одиночный путь, либо файл с путями. Для проверки файл это или каталог прекрасно подходит класс Path модуля pathlib. Выбор одного из двух вариантов реализуем следующим образом.
searching_path_obj = Path(search_path) if searching_path_obj.is_dir(): search_type = 'one' else: search_type = searching_path_obj.suffix search_type = search_type[1:]
Варианты заполнения списка с путями для проверки опишем с помощью словаря с ключами, представляющими тип входного пути (отдельный путь, файл формата csv или json) и значениями – функции для обработки.
PATH_FILLER = { 'one': add_search_dict, 'json': add_search_from_json, 'csv': add_searches_from_csv }
Функции для обработки считывают данные из файлов и записывают в список словарей с ключами идентификатор, имя ресурса, путь. Словари очень хорошо подходят для написания красивого кода и возможности избавиться от множественных проверок условий.
Каждая функция принимает два параметра список для хранения результатов и путь к файлу с данными.
Также не стоит забывать обрабатывать параметры командной строки – пользователь может ввести их неправильно. Посмотрим обработку на примере аргумента search_type:
SEARCH_TYPES = ["one", "json", "csv"] if search_type not in SEARCH_TYPES: types = ",".join(SEARCH_TYPES) message = (f"Неправильный тип поиска!" f" Должен быть один из вариантов: {types}") print(message) logging.error(message) return
Теперь, когда имеется словарь с функциями для заполнения списка входных данных из файлов с разными форматами заполнение списка будет выглядеть довольно просто:
# Для хранения списка файлов search_paths = [] # Заполнение списка PATH_FILLER[search_type](search_paths, search_path)
Многопоточность и обработка частями
Чтобы наше приложение могло использовать как можно больше вычислительных ресурсов добавим многопоточность при помощи ThreadPoolExecutor из стандартной библиотеки. Для отображения прогресса работы программы используем tqdm (pip install tqdm).
futures = [] with ThreadPoolExecutor(max_workers=max_threads) as executor: for proc_id, search_dict in enumerate(paths_list): source = SearchSource(search_dict['name'], search_dict['id'], search_dict['path']) futures.append(executor.submit(find_in_path, source, allowed_types, max_filesize=max_filesize, max_buffer_size=max_buffer_size, continue_state=continue_state, debug_mode=debug_mode)) progress_bar = tqdm(as_completed(futures), total=len(paths_list), desc="Проверка ФИРов", bar_format='{desc:<15} ' '{percentage:3.0f}%|{bar:20}{r_bar}') for _ in progress_bar: pass
Результаты поиска будем записывать в датафрейм модуля pandas (pip install pandas). В процессе поиска будем сохранять промежуточные результаты, на случай если что-то пойдёт не так и скрипт завершит работу.
interim_result = [] common_uid = generate_uid() for result in files_gen: current_num += 1 result.save_to_dataframe(interim_result, source_search.path) total_fs_size += result.size if current_num % batch_size == 0: batch_num += 1 progress_state = batch_num * batch_size info_message = (f"Поток {process_thread_id}.{subprocess_postfix} " f"Обработано: {progress_state} файлов.") print(info_message) if current_num > 0 and current_num % FILES_IN_POOL == 0: stat = SearchStat(current_num, total_fs_size) search_result = pd.DataFrame(interim_result, columns=REPORT_COLUMNS) save_interim(search_result, source_search, stat, part_num, common_uid) interim_result = [] part_num += 1 if interim_result: stat = SearchStat(current_num, total_fs_size) search_result = pd.DataFrame(interim_result, columns=REPORT_COLUMNS) save_interim(search_result, source_search, stat, part_num, common_uid) else: uid = generate_uid() save_dir_progress(source_search, SearchStat(0, 0), uid, "Нет доступа")
Количество обрабатываемых файлов для записи промежуточных результатов определим в FILES_IN_POOL, а колонки для отчёта опишем в переменной REPORT_COLUMNS (список строк).
Обработка файлов и архивов
Для обработки результатов напишем функцию-генератор, возвращающий результаты обработки и использующую функцию os.walk для рекурсивного обхода по файлам:
for root, dirs, files in os.walk(path): for file in files: file_path = os.path.join(root, file) try: file_obj = File(file_path, thread_id, None, max_buffer_size) file_suffix = file_obj.extension except Exception as ex: error_message = (f"{str(ex)}. Не удалось получить " f"доступ к файлу {os.path.join(root, file)}") logging.error(error_message) file_suffix = '!NONE!' proc_res, res_info = file_obj.process(max_filesize) result = SearchResult(file_obj.path, proc_res, res_info, file_obj.size, file_suffix) yield result
Для работы с файлами и поиска по ним используется отдельный класс:
class File: """ File class with file info. Method file processing calling processing functions for each filetype (document, pdf, xlxs, image) """ # Максимальный объём файла для обработки по умолчанию PROCESSING_MAX_SIZE = 100 def __init__(self, file_path, process_thread_id=1, subprocess_id=None, buffer_size=314_572_800): path_obj = Path(file_path) self.name = path_obj.name self.extension = path_obj.suffix self.flat_name = path_obj.stem self.parent_directory = str(path_obj.parent) self.path = file_path self.process_thread_id = process_thread_id self.buffer_size = buffer_size self.subprocess_id = subprocess_id self.size = os.path.getsize(self.path)
Обработку файла реализуем при помощи метода process() класса File.
def process(self, limit_size: int = 100): """ Process file and starts search inside :param limit_size: max file size in MB :return: """ if limit_size is None: limit_size = File.PROCESSING_MAX_SIZE file_size_in_mb = self.size / (1024 * 1024) # размер в мегабайтах if self.extension in CRITICAL_FILE_EXT: return self.find_cards(critical=True) if file_size_in_mb > limit_size: return self.get_max_size_exceed() if self.extension in USUAL_SUFFIXES: return self.find_in_file() elif self.extension in ARCHIVES_SUFFIXES: result = self.find_in_zip() remove_dir(self.form_tempdir_name(TEMP_ARCHIVES_PATH)) return result elif self.extension in OLD_SUFFIXES: temp_dir = self.form_tempdir_name(TEMP_PATH) recreate_tempdir(temp_dir) result = self.find_in_olddoc() remove_dir(temp_dir) return result return self.get_unsupported_result()
Отдельно стоит упомянуть, что при обработке архивов разных форматов их прийдётся извлекать во временные папки и обрабатывать. Конечно, как вариант, можно использовать отдельные модули для обработки архивов разного формата (есть стандартные модули zip, tarfile остальные нужно устанавливать), но для задач, в каких целях применялся разработанный инструмент, требовалась обработка rar формата. В данном случае будет использоваться модуль patoolib (pip install patool).
Также при обработке архивов стоит учесть, что внутри могут находиться другие архивы. Поэтому извлекать архивы стоит рекурсивно. Класс для обработки архивов представлен ниже:
class Archive(File): def __init__(self, path, temp_dir=None): super().__init__(path, 1, subprocess_id=None, buffer_size=314_572_800) self.temp_dir = TEMP_ARCHIVES_PATH if temp_dir is None else temp_dir def extract(self, out_path: str = TEMP_PATH, recursive=True, changed_path=None, extract_level=1): """ Extracts all data from archive :param extract_level: current extraction depth :param recursive: True for recursive extract(by default) :param out_path: Path to extract archive :param changed_path: Path for second and more extract :return: """ source_path = self.path if changed_path is None else changed_path try: patoolib.extract_archive(source_path, verbosity=-1, outdir=out_path, interactive=False) if changed_path is not None: os.remove(source_path) except Exception as ex: logging.error(f"Ошибка при извлечении архива {self.path}: {ex}") return if recursive: for root, dirs, files in os.walk(out_path): for file in files: pth = Path(root) / file suffix = pth.suffix if suffix in ARCHIVES_SUFFIXES: try: extract_dir = str(pth.parent) if extract_level > 999: # В случае большого вложенного # архива останавливаем процесс return self.extract(extract_dir, recursive=True, changed_path=f"{pth}", extract_level=extract_level + 1) except Exception as ex: logging.error(f" Проход по архиву." f"Файл {pth} Ошибка - {ex}")
Для хранения результатов поиска удобно организовать отдельный класс.
class SearchResult: """ Represents search results Attributes: result(bool) : True if success, else False info(str): additional string description size(int): file size ext(str): file extension """ def __init__(self, file_path: str, result: bool = None, info: str = None, size=0, ext=None): """ :param result: result : True if success, else False :param info: additional string description :param size: file size :param ext: file extension """ self.__result = result self.__info = info self.__size = size self.__ext = ext self.__path = file_path
Для обработки файлов с различными расширениями напишем отдельные функции. Для их вызова также используем словарь.
process_functions = { '.docx': docx2txt.process, '.txt': process_txt, '.xls': extract_text_xls, '.xlsx': extract_text_xlsx, '.xlsm': extract_text_xlsx, '.xlsb': extract_text_xlsb, '.rtf': extract_text_rtf, '.csv': extract_csv, '.pdf': extract_text_from_pdf, } try: text = process_functions[self.extension](self.path) except Exception as ex: logging.error(f"Ошибка при обработке файла {self.path}: {ex}")
При обработке текстовых файлов нам помогут средства стандартной библиотеки Python, табличных – модули pandas, pyexcel, xlrd ; файлов Word – модули docx2txt, win32com/пакет LibreOffice; rtf –модуль striprtf; pdf файлов – модуль pdfminer.
Поиск по содержимому
Для поиска информации воспользуемся модулем re. Если нужно искать данные по каким-то конкретным шаблонам, как в случае с задачей для которых использовался инструмент, определим их отдельно в переменной SEARCH_REGEXPS.
def search_info(text): """ Search info :param text: text in str format :return: results count and info """ results = [] for pattern in SEARCH_REGEXPS: finds = re.findall(pattern, text) for res in finds: results.append(res) return len(results), ",".join(results)
Обработка результатов
Промежуточные результаты сохраняются в файлы на локальном компьютере. Для записи результатов Обработка полученных результатов выглядит следующим образом.
RESULT_SAVERS = { 'sqlite': sqlite_save, 'mssql': mssql_save, 'csv': save_csv, 'excel': save_excel, 'xlsx': save_excel, } def process_results(result_type, output_tablename='results'): """ Unite all results from RESULTS_PATH directory :param result_type: result format for save (sqlite, mssql, csv) :param output_tablename: out table postfix for name """ result_dirs = load_setting("RESULT_DIRS") for result_dir in result_dirs: print(f'Чтение результатов {result_dir}..') # Имя таблицы/файла для сохранения outname = f"{output_tablename}-{result_dir}" path_to_process = Path(result_dir) dataframes = [] result_paths = [] if path_to_process.exists(): result_paths = [p for p in path_to_process.iterdir()] for path in tqdm(result_paths, desc="Чтение файлов", bar_format='{desc:<15} {percentage:3.0f}%|' '{bar:20}{r_bar}'): try: if path.suffix == '.xlsx': dataframes.append(pd.read_excel(str(path), sheet_name=0)) elif path.suffix == '.csv': dataframes.append(pd.read_csv(str(path), encoding='cp1251', sep=';')) except Exception as ex: print(F"Ошибка при обработке файла {path}. Ошибка: {ex}") print('Объединение данных...') if dataframes: result_frame = pd.concat(dataframes) # Убираем лишний столбец со внутренними id remove_first = load_setting("REMOVE_FIRST") if remove_first: result_frame.drop(result_frame.columns[[0]], axis=1, inplace=True) print('Запись результатов..') if result_type not in RESULT_SAVERS: print(f"Неверный формат данных {result_type}!!!") try: RESULT_SAVERS[result_type](outname, result_frame) except Exception as ex: print(f"Ошибка сохранения в {result_type}: {ex}") print('Сохранение результов завершено!') else: print('Данные отсутствуют!')
Для записи в базу данных воспользуемся модулями sqlalchemy, pymssql, pandas. Настройки для подключения будем хранить в отдельном файле или переменных среды. Код для записи в БД выглядит следующим образом.
def get_connection_settings(): global DATABASE_NAME, DOMAIN, DB_SERVER DATABASE_NAME = load_setting('DATABASE') DOMAIN = load_setting('DOMAIN') DB_SERVER = load_setting('DB_SERVER') get_connection_settings() def sqlite_save(table_name: str, data: pd.DataFrame): """ Saves pd dataframe in sqlite db :param db_name: database name :param table_name: table name in database :param data: dataFrame to save """ engine = create_engine(f'sqlite:///{DATABASE_NAME}.db') data.to_sql(f'{table_name}', con=engine, if_exists='append', method='multi') def mssql_save(table_name: str, data: pd.DataFrame): """ Saves pd dataframe in sqlite db :param table_name: table name in database :param data: dataFrame to save """ with pymssql.connect(server=DB_SERVER, database=DATABASE_NAME) as con: engine = create_engine('mssql+pymssql://', creator=lambda: con) data.to_sql(f'SearchDpk_{table_name}', con=engine, if_exists='append', method='multi', chunksize=500)
Вот так будет выглядеть результат:
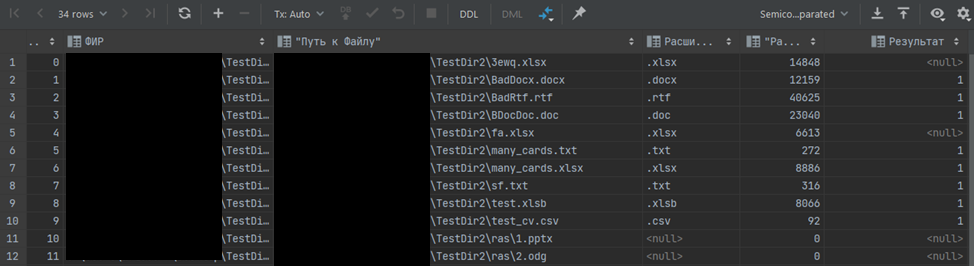
Таким образом, получим инструмент, позволяющий обрабатывать файлы в указанных каталогах.

