
Фото Jack Hunter, Unsplash.com
После почти пятилетней разработки протокол HTTP/3 наконец приближается к окончательному выпуску. Здесь мы узнаем, как в HTTP/3 улучшилась производительность, включая контроль перегрузок, блокировки HoL и установку соединения 0-RTT.
Это вторая часть серии о новом протоколе HTTP/3. В первой мы говорили о том, зачем нам вообще нужен HTTP/3, о протоколе QUIC и новых возможностях.
Во второй части вы увидите, как QUIC и HTTP/3 повышают производительность при загрузке веб-страниц. Спойлер: не ждите слишком многого.
У QUIC и HTTP/3 отличный потенциал, но порадуют они, в основном, пользователей в медленных сетях. Если сеть и так быстрая, скорее всего, вы почти ничего не заметите. Но даже в странах и регионах с быстрой связью, 1% или даже 10% пользователей с самым медленным соединением (99-й и 90-й перцентили) могут приятно удивиться. Дело в том, что HTTP/3 и QUIC решают проблемы, которые встречаются не так часто, но могут сильно затруднять работу.
В этой части будет больше технических деталей, чем в первой, но в самые глубины мы лезть не будем — просто приведём список дополнительных ресурсов о том, что новый протокол даст среднестатистическому веб-разработчику.
- Часть 1: История и ключевые концепции HTTP/3
Эта часть для тех, кто в целом мало что знает об HTTP/3 и протоколах. Здесь мы говорим о самых основах.
- Часть 2: Характеристики производительности HTTP/3
Тут мы углубимся в технические детали. Если с основами вы уже знакомы, начинайте со второй части.
- Часть 3: развертывание HTTP/3 на практике
Здесь описываются трудности, связанные с самостоятельным развёртыванием и тестированием HTTP/3. Мы поговорим, как нужно изменить веб-страницы и ресурсы и нужно ли вообще (примечание переводчика: перевод третьей части тоже появится в нашем блоге в ближайшее время).
Скорость
Говорить о производительности и скорости сложно, потому что веб-страницы загружаются медленно по многим причинам. Раз речь о сетевых протоколах, мы рассмотрим сетевые аспекты. И самые важные из них — задержка и полоса пропускания.
Задержкой мы будем считать время, которое требуется для доставки пакета из точки А (допустим, клиента) в точку Б (сервер). В теории мы ограничены скоростью света, а на практике — скоростью прохождения сигналов по проводным или беспроводным сетям. В итоге задержка часто зависит от физического расстояния между точками А и Б.
На планете Земля это значит, что задержки небольшие, от 10 до 200 мс. Но это только в одну сторону — ведь нужно ещё дождаться ответа. Задержка при передаче туда и обратно называется временем кругового пути (round-trip time, RTT).
Из-за таких функций, как контроль перегрузок (см. ниже), круговых путей даже для загрузки одного-единственного файла будет немало, как правило. Поэтому даже если задержка меньше 50 мс, в сумме может получиться гораздо больше. И это одна из главных причин, по которым мы используем сети доставки контента (CDN): в них серверы находятся физически ближе к конечным пользователям, чтобы максимально сократить задержку.
Полоса пропускания — это число пакетов, которые можно отправить одновременно. Эту концепцию сложнее объяснить, потому что она зависит от физических свойств среды (например, частоты радиоволн), числа пользователей в сети и устройств, которые соединяют разные подсети (потому что они обычно могут обрабатывать ограниченное количество пакетов в секунду).
Представьте себе трубу, по которой течёт вода. Длина трубы определяет задержку, а диаметр — полосу пропускания. Интернет можно сравнить с целой системой разных труб, и в трубах с маленьким диаметром возникают узкие места. Поэтому полоса пропускания между точками А и Б обычно ограничена самым медленным отрезком.
Все тонкости мы рассматривать не будем, для понимания этой статьи достаточно общего представления. Если хотите узнать больше, читайте превосходную главу о задержках и полосе пропускания в книге Ильи Григорика (Ilya Grigorik) High Performance Browser Networking.
Контроль перегрузок
Один из аспектов производительности — насколько эффективно транспортный протокол может использовать полную (физическую) пропускную способность, т. е. сколько пакетов можно отправлять и получать в секунду. От этого зависит, как быстро загружаются ресурсы страницы. Некоторые считают, что в этом QUIC гораздо лучше TCP, но это не так.
А вы знали?
TCP-соединение, например, не начинает сразу отправлять данные на полную полосу пропускания, чтобы избежать перегрузки сети. Мы уже говорили, что каждый сетевой канал физически может обработать только определённый объём данных в секунду. Отправьте больше — и лишнее придётся отбросить, что приведет к потере пакетов.
В первой части мы уже говорили, что TCP может исправить потерю пакетов только одним способом — заново отправить данные. Для этого требуется ещё один проход туда-обратно. В сетях с большой задержкой (больше 50 мс RTT) потеря пакетов может серьезно снижать производительность.
Ещё одна проблема — мы не знаем заранее, какой будет максимальная полоса пропускания. Где-то по пути может возникнуть узкое место, но где это будет — угадать невозможно. В интернете пока нет механизмов, с помощью которых можно сообщать конечным точкам о ёмкости каналов.
И даже если бы мы знали о доступной физической полосе пропускания, это не означало бы, что вся она достанется нам. Обычно её делят между собой сразу много пользователей.
Соединение не знает, какую полосу пропускания получит, к тому же это значение меняется вместе с величиной активного потребления полосы у провайдеров. Чтобы решить эту проблему, TCP постоянно пытается выяснить доступную полосу пропускания с помощью механизма контроля перегрузки — congestion control.
В начале соединения протокол отправляет несколько пакетов (от 10 до 100, или от 14 до 140 КБ данных) и ждёт ответа о получении этих пакетов. Если получение подтверждено, значит сеть справляется с такой скоростью и можно попробовать отправить больше данных (обычно объём увеличивается вдвое при каждой итерации).
Скорость отправки растёт до тех пор, пока какие-то пакеты не останутся без подтверждения. Это значит, что сеть перегружена, и они потерялись. Такой алгоритм называется медленным стартом. Заметив пропажу, TCP уменьшает скорость, а через какое-то время пытается увеличить её снова, но с меньшим шагом приращения. Затем эта логика повторяется каждый раз при потере пакетов. По сути, это означает, что TCP всегда пытается получить свою максимально доступную долю полосы пропускания. Этот механизм показан на рисунке 1.
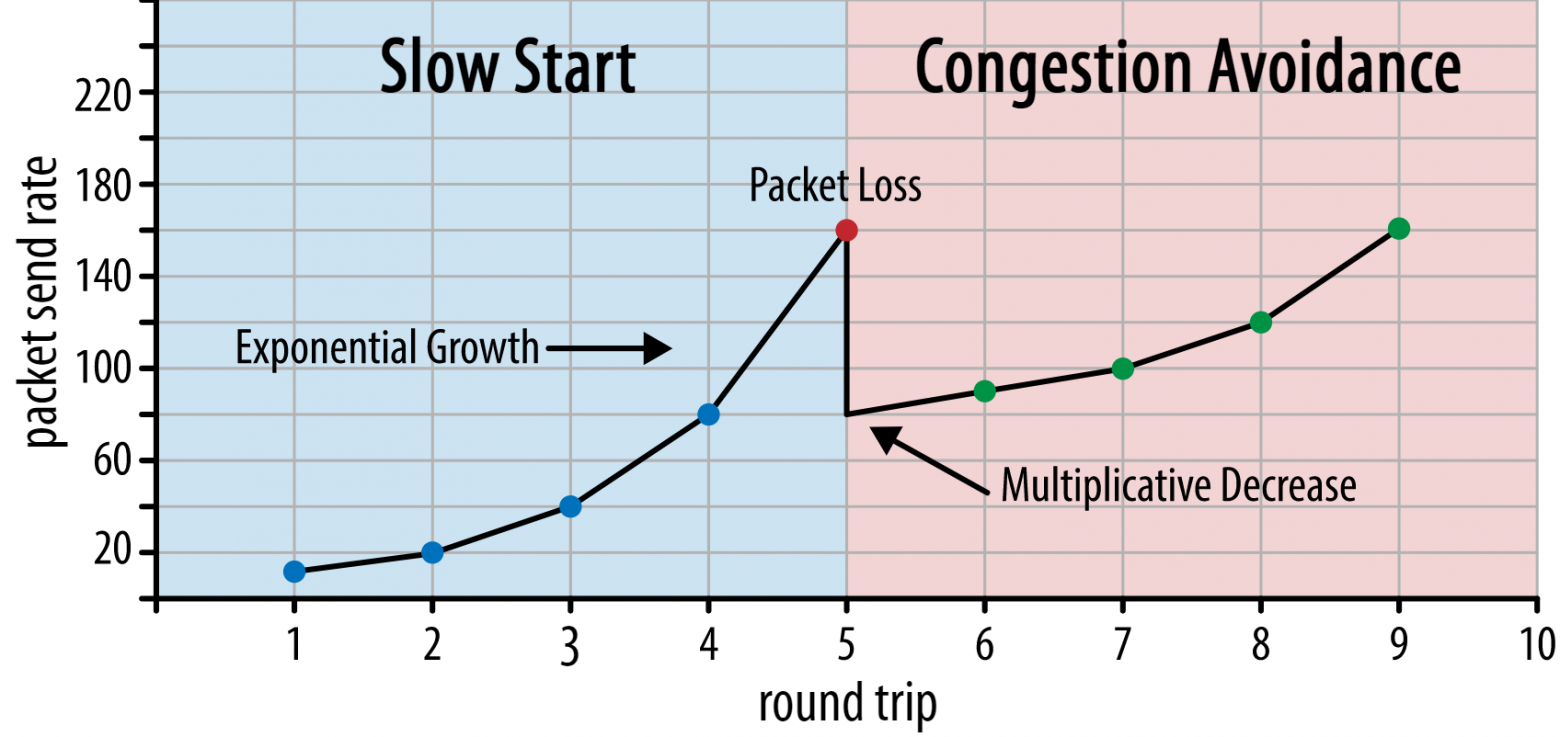 Рис. 1. Упрощённая схема контроля перегрузок: TCP начинает с 10 пакетов (адаптация с сайта hpbn.co) (исходное изображение).
Рис. 1. Упрощённая схема контроля перегрузок: TCP начинает с 10 пакетов (адаптация с сайта hpbn.co) (исходное изображение).Это очень упрощённое объяснение контроля перегрузок. На практике здесь участвует много факторов, например, bufferbloat (излишняя буферизация), колебания RTT из-за перегрузки и тот факт, что получить свою долю полосы пропускания стараются сразу несколько желающих. Существуют и продолжают появляться разные алгоритмы контроля перегрузок, но ни один из них не универсален.
Механизм контроля перегрузок TCP повышает надежность, но оптимальная скорость отправки достигается не сразу, в зависимости от RTT и фактически доступной полосы пропускания. При загрузке веб-страниц медленный старт влияет на метрики, например, время до первой полезной отрисовки контента (First Contentful Paint), потому что в первых нескольких проходах туда и обратно передаётся очень маленький объём данных (пара десятков или сотен килобайт). (Слышали, наверное, о рекомендации укладывать критически важные данные в 14 КБ.)
Если действовать агрессивнее, можно улучшить результаты в сетях с большой полосой пропускания и задержкой, особенно если потеря пакетов для вас не проблема. На эту тему бытует много заблуждений о принципах работы QUIC.
В первой части мы говорили, что в теории QUIC меньше страдает от потери пакетов (и связанной блокировки HoL), потому что обрабатывает каждый поток байтов независимо. Кроме того, QUIC использует протокол UDP, у которого, в отличие от TCP, нет встроенной функции контроля перегрузок. С ним можно попытаться отправить данные на любой скорости, но потерянные данные он не будет передавать заново.
В итоге появилось много статей, где говорится, что QUIC не контролирует перегрузки, а просто сразу отправляет данные на высокой скорости по UDP, решая проблему потери пакетов благодаря отсутствию блокировки HoL. Потому, мол, QUIC гораздо быстрее TCP.
В реальности это максимально далеко от истины: методы управления полосой пропускания у QUIC очень похожи на то, что делает TCP. QUIC тоже начинает с невысокой скорости и увеличивает её со временем, используя подтверждения, чтобы измерять пропускную способность сети. Отчасти это связано с тем, что QUIC должен обеспечивать надёжность, чтобы его можно было использовать с HTTP, потому что кроме него есть и другие QUIC (и TCP!) соединения и потому что удаление блокировки HoL не гарантирует полную защиту от потери пакетов (как мы увидим чуть позже).
Это не значит, что QUIC не может управлять полосой пропускания чуточку умнее, чем TCP. В основном, потому что QUIC дает больше гибкости и его проще развивать. Мы уже сказали, что алгоритмы контроля перегрузок по-прежнему активно развиваются, например, чтобы максимально эффективно использовать технологию 5G.
TCP обычно реализуется в ядре ОС, самой защищённой и самой ограниченной среде, к тому же проприетарной в большинстве ОС. Поэтому логика контроля перегрузок в ОС обычно реализуется ограниченным кругом разработчиков, что замедляет развитие технологии.
Большинство реализаций QUIC, наоборот, находятся в пользовательском пространстве, где мы обычно запускаем нативные приложения, и имеют открытый исходный код — как раз для того, чтобы как можно больше разработчиков экспериментировали с ним (и Facebook уже подает пример).
Ещё один пример — расширение для отложенной отправки подтверждений, предложенное для QUIC. По умолчанию QUIC отправляет подтверждения для каждых двух полученных пакетов. С помощью расширения можно настроить подтверждение, допустим, для каждых десяти пакетов. Такой подход показал значительное увеличение скорости в спутниковых сетях и сетях с большой полосой пропускания, потому что издержки на передачу подтверждений снизились. Внедрять такое расширение для TCP было бы очень долго, а с QUIC все гораздо проще.
Мы ожидаем, что благодаря гибкости QUIC будет больше экспериментов, и алгоритмы контроля перегрузок со временем улучшатся. Эти наработки потом можно будет перенести на TCP.
А вы знали?
В официальном QUIC Recovery RFC 9002 описано использование алгоритма контроля перегрузок NewReno. Это надежный, но немного устаревший подход, который уже не очень широко используется на практике. Тогда почему он включен в QUIC RFC? Во-первых, потому, что в начале разработки QUIC алгоритм NewReno был самым современным из стандартизированных. Более продвинутые алгоритмы, вроде BBR и CUBIC, до сих пор не стандартизированы или только недавно стали RFC.
Во-вторых, NewReno относительно просто настраивать. Поскольку любой алгоритм нужно адаптировать, чтобы учесть отличия QUIC от TCP, с простым алгоритмом будет приятнее иметь дело. Поэтому RFC 9002 можно считать скорее рекомендацией по тому, как настроить контроль перегрузок для QUIC, чем требованием использовать с QUIC именно этот алгоритм. По факту большинство реализаций QUIC на уровне продакшена используют кастомные варианты Cubic и BBR.
Повторю: алгоритмы контроля перегрузок не привязаны к TCP или QUIC. Их можно использовать для обоих протоколов, и мы надеемся, что усовершенствования в QUIC доберутся и до TCP.
А вы знали?
С концепцией контроля перегрузок связан механизм контроля потоков (flow-control). Их часто путают в TCP, потому что они оба используют TCP window (окно TCP), хотя окон по сути два: congestion window и receive window. Flow control, впрочем, не так важен для загрузки веб-страниц, поэтому здесь мы не будем о нём говорить. Если интересно, см. исследование, видео или статью.
Что всё это значит?
QUIC по-прежнему подчиняется законам физики и должен проявлять уважение к остальным отправителям в сети. Он не сможет волшебным образом загружать ресурсы на сайте гораздо быстрее, чем TCP. Но QUIC очень гибкий, а значит экспериментировать с алгоритмами контроля перегрузок будет проще. TCP от этого в итоге тоже выиграет.
Установка соединения 0-RTT
Второй аспект производительности — сколько раз нужно совершить круговой путь, прежде чем можно будет отправить полезные данные HTTP (ресурсы страницы, например) в новом соединении. Кто-то говорит, что QUIC на два-три цикла быстрее, чем TCP + TLS, но на самом деле мы экономим всего один цикл.
А вы знали?
В первой части мы уже говорили, что обычно соединению требуется одно (TCP) или два (TCP + TLS) рукопожатия, прежде чем можно будет обмениваться HTTP-запросами и ответами. При этих рукопожатиях клиент и сервер обмениваются начальными параметрами, которые нужны им, например, для шифрования данных.
Как видно на рисунке 2, каждому отдельному рукопожатию нужен как минимум один круговой путь (TCP + TLS 1.3, (b)), а иногда и все два (TLS 1.2 и ниже (a)). Это неэффективно, потому что нам приходится ждать как минимум два прохода туда и обратно, прежде чем можно будет отправить первый HTTP-запрос, то есть первые данные ответа HTTP (красная стрелка обратно) поступят минимум через три круга. В медленных сетях это может приводить к дополнительной задержке в 100–200 мс.
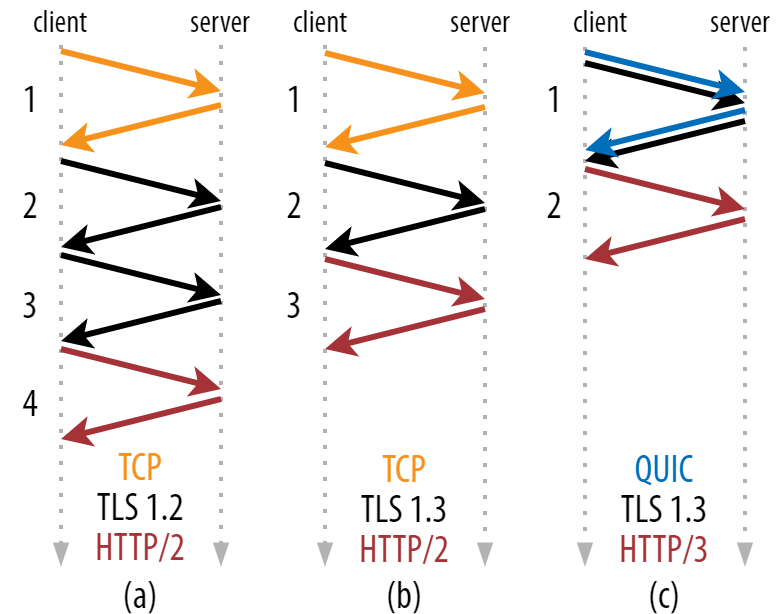
Рис. 2: Установка соединения TCP + TLS и QUIC (исходное изображение).
Странно же, что нельзя объединить рукопожатия TCP + TLS в одном проходе? Теоретически это возможно, и QUIC так и делает, но изначально было задумано, что TCP можно использовать как с TLS, так и без него. Другими словами, TCP просто не поддерживает отправку того, что к нему не относится, во время рукопожатия. Были попытки добавить эту возможность в расширение TCP Fast Open, но, как мы уже сказали в первой части, оказалось, что в большом масштабе всё это трудно развернуть.
QUIC с самого начался создавался под TLS, поэтому объединяет транспортные и криптографические рукопожатия. Получается, что QUIC нужно совершить один круговой путь, а это ровно на один меньше, чем TCP + TLS 1.3 (см. рис. 2c).
Вы наверняка слышали, что QUIC быстрее на два или даже три круга, но в большинстве статей рассматривают худший сценарий (TCP + TLS 1.2 (2a)) и почему-то забывают, что TCP + TLS 1.3 укладывается в два прохода (2b). Сэкономить один проход, конечно, приятно, но вряд ли вызывает восторг. Если сеть быстрая (допустим, с RTT < 50 мс), этого никто и не заметит, хотя для медленных соединений с отдалённым сервером преимущества будут.
А почему мы вообще должны ждать, пока рукопожатия закончатся? Давайте сразу отправим HTTP-запрос да и всё. Но в этом случае первый запрос будет не зашифрован. Кто угодно сможет перехватить его в нарушение всех требований безопасности и конфиденциальности. Поэтому и приходится ждать, прежде чем отправить первый HTTP-запрос. Или всё-таки это необязательно?
Тут есть одна хитрость. Мы знаем, что пользователи часто возвращаются на веб-страницы вскоре после первого посещения, а значит можно использовать изначальное зашифрованное соединение, чтобы запустить следующее соединение в будущем. Проще говоря, во время первого соединения клиент и сервер безопасно обмениваются новыми криптографическими параметрами. С помощью этих параметров можно с самого начала зашифровать второе соединение, не дожидаясь завершения рукопожатия TLS. Такой подход называется возобновлением сеанса.
С его помощью можно серьёзно оптимизировать процесс: можно отправить первый HTTP-запрос вместе с рукопожатием QUIC/TLS, сэкономив еще один проход туда-обратно! Если использовать TLS 1.3, то ждать рукопожатия TLS вообще не придётся. Такой метод часто называется 0-RTT (хотя, по сути, HTTP-ответ всё-таки приходит после одного кругового пути).
Многие ошибочно считают, что возобновление сеанса и 0-RTT относятся исключительно к QUIC. На самом деле это функции TLS, которые уже в каком-то виде присутствуют в TLS 1.2, а теперь полноценно реализованы в TLS 1.3.
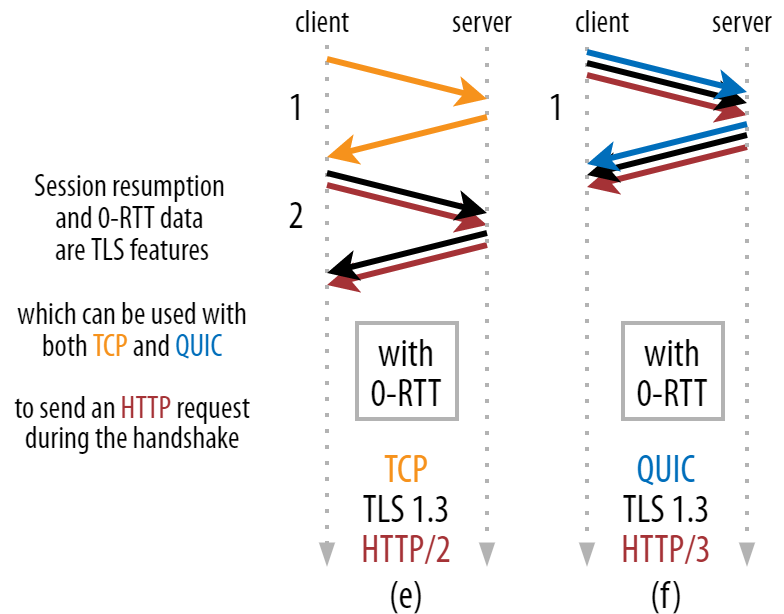
Если посмотреть на рисунок 3, будет очевидно, что производительность можно увеличить и для TCP (а значит и для HTTP/2 и даже HTTP/1.1)! Как видите, даже с 0-RTT протокол QUIC по-прежнему всего на один круговой путь опережает стек TCP + TLS 1.3. Разговоры про три круга основаны на сравнении рисунка 2a с рисунком 3f, что, как мы видели, не совсем справедливо.
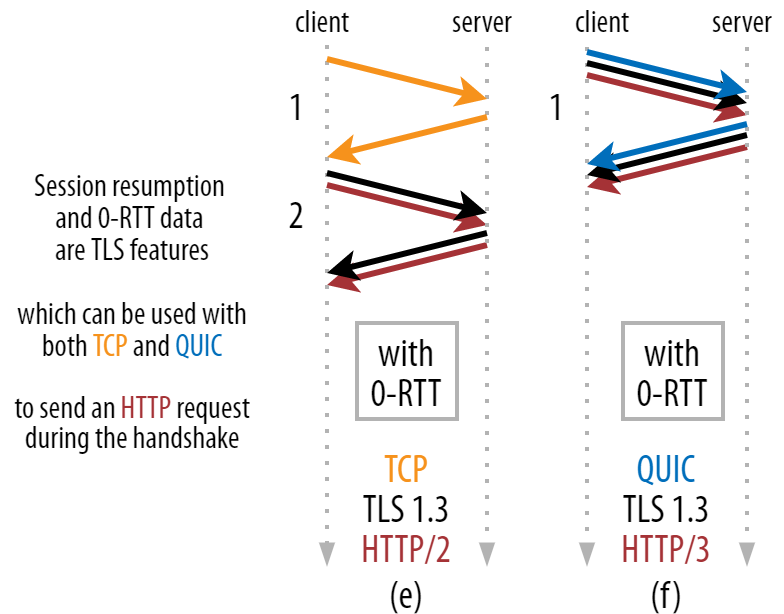 Рис. 3: Установка соединения TCP + TLS и QUIC 0-RTT (исходное изображение).
Рис. 3: Установка соединения TCP + TLS и QUIC 0-RTT (исходное изображение).Проблема в том, что при использовании 0-RTT, QUIC не может полноценно реализовать эту экономию из соображений безопасности. Чтобы понять это, нужно разобраться, зачем рукопожатие TCP вообще существует. Во-первых, оно позволяет клиенту убедиться, что сервер доступен по указанному IP-адресу, прежде чем отправлять на него данные.
Во-вторых, и это самое главное, сервер должен проверить, что клиент действительно то, за что себя выдает, прежде чем посылать ему данные в ответ. Если помните, в первой части мы говорили о четырёх параметрах соединения. Так вот, клиент, в основном, идентифицируется по своему IP-адресу. В этом и проблема: IP-адреса можно подделывать!
Допустим, злоумышленник запрашивает очень большой файл по HTTP через QUIC 0-RTT. При этом он подменяет IP-адрес, чтобы всё выглядело так, будто запрос 0-RTT поступил с компьютера жертвы. См. рисунок 4 ниже. Сервер QUIC никак не может определить подлинность IP-адреса, потому что это первый пакет от клиента.
 Рис. 4: Злоумышленники могут подменять IP-адрес при отправке запроса 0-RTT на сервер QUIC, запуская атаку с усилением (amplification) (исходное изображение).
Рис. 4: Злоумышленники могут подменять IP-адрес при отправке запроса 0-RTT на сервер QUIC, запуская атаку с усилением (amplification) (исходное изображение).Если сервер просто начнёт отправлять большой файл на этот IP, это приведёт к перегрузке полосы пропускания в сети жертвы (особенно если параллельно отправлено много фейковых запросов). Компьютер жертвы отклонит этот ответ, потому что не запрашивал его, но это уже не важно. Сеть всё равно должна будет обработать эти пакеты!
Также это называется reflection attack (amplification attack), и это один из самых распространённых методов DDoS-атак. Такого не случится, если использовать 0-RTT с TCP + TLS, как раз благодаря рукопожатию TCP, которое происходит ещё до первого запроса 0-RTT + TLS.
Поэтому QUIC должен использовать консервативный подход, отвечая на запросы 0-RTT, и ограничить объём отправляемых данных, пока сервер не убедится, что это настоящий клиент, а не жертва. Для QUIC установлен лимит: в три раза больше данных, чем получено от клиента.
Другими словами, коэффициент усиления у QUIC равен трём. Это компромисс между производительностью и безопасностью (случались инциденты, где коэффициент усиления был больше 51 000). Обычно клиент сначала отправляет один или два пакета, так что ответ 0-RTT от сервера QUIC не превысит 4–6 КБ (включая остальные издержки QUIC и TLS). Не впечатляет?
Другие проблемы безопасности могут привести, например, к атакам повторного воспроизведения (replay attack), что ограничивает доступные типы HTTP-запросов. Например, Cloudflare разрешает только запросы HTTP GET без параметров запроса в 0-RTT. Очевидно, что это ещё больше снижает потенциальную пользу 0-RTT.
К счастью, у QUIC есть возможность немного улучшить ситуацию. Например, сервер может проверить, поступает ли запрос 0-RTT с IP-адреса, с которым у него уже было соединение. Но это работает, только если клиент остаётся в той же сети (частично это ограничивает возможность миграции соединения в QUIC). Даже если всё получится, ответ QUIC будет ограничен из-за логики медленного старта для контроля перегрузок, которую мы обсуждали выше. Как видите, никакого невероятного увеличения скорости мы не получим, разве что сэкономим один круговой путь.
А вы знали?
Интересно отметить, что в QUIC коэффициент усиления, равный трём, действует и без 0-RTT (рис. 2c). Это может стать проблемой, если, например, TLS-сертифкат сервера слишком большой и не поместится в эти 4–6 КБ. В этом случае его придется разделить, и второй фрагмент попадет во второй проход (после подтверждения первых пакетов, чтобы убедиться в подлинности IP-адреса клиента). И тогда для рукопожатий QUIC понадобится два прохода — прямо как у TCP + TLS! Поэтому для QUIC очень важно будет использовать такие методы, как сжатие сертификатов.
А вы знали?
В некоторых продвинутых системах эти проблемы можно будет хотя бы отчасти решить, чтобы получить больше пользы от 0-RTT. Например, сервер может помнить, какая полоса пропускания была у клиента в последний раз, и применять менее строгие алгоритмы медленного старта для контроля перегрузок для подлинных клиентов. Исследователи уже занимаются этим вопросом и даже предложили подходящее расширение для QUIC. Некоторые компании используют что-то подобное для ускорения TCP.
Ещё один вариант — отправлять с клиентов больше пакетов (например, еще 7 пакетов без полезных данных), чтобы трёхкратное усиление давало хотя бы 12–14 КБ даже после миграции соединения. Я писал об этом в одном из своих исследований.
Кроме того, неправильно настроенные серверы QUIC могут специально превышать трёхкратный лимит, если им кажется, что это безопасно, или проблемы с безопасностью их не волнуют (в конце концов, никакие политики протокола этому не препятствуют).
Что всё это значит?
Если с 0-RTT соединение QUIC устанавливается быстрее, это скорее небольшая оптимизация, но уж никак не революция. По сравнению со стеком TCP + TLS 1.3 в лучшем виде, мы экономим максимум один круговой путь, да и то можем отправить только небольшой объём данных из соображений безопасности.
По сути, вы получите большое преимущество только для пользователей в сетях с очень высокой задержкой (допустим, спутниковые сети с RTT > 200 мс) или если отправляете много данных. Пример последнего сценария — сайты с большим объёмом кэшированных данных, а еще одностраничные приложения, которые периодически получают небольшие обновления через API и другие протоколы, например, DNS-over-QUIC. Если Google получил очень хорошие результаты с 0-RTT для QUIC, так это потому, что они тестировали его на уже хорошо оптимизированной странице поиска с маленькими ответами на запросы.
В остальных случаях вы сэкономите не больше пары десятков миллисекунд. Даже меньше, если используете сеть CDN (кстати, используйте CDN, если вам важна производительность!).
Миграция соединения
Третья особенность ускоряет QUIC при переходе между сетями, поддерживая существующее соединение. Это полезная функция, но смена сетей происходит не так уж часто, и соединению все равно приходится сбрасывать скорость.
В первой части мы говорили, что идентификаторы соединения (CID) в QUIC позволяют переносить соединение при смене сети. В качестве примера мы привели переход с Wi-Fi на 4G во время загрузки большого файла. В TCP пришлось бы прервать загрузку, а в QUIC она может продолжаться.
Но давайте подумаем, как часто такое вообще происходит. Может показаться, что так бывает, когда мы переходим от одной точки доступа Wi-Fi в здании к другой или между сотовыми вышками в дороге. Но если в такой системе все настроить правильно, устройство сохраняет IP-адрес, потому что переход между беспроводными базовыми станциями выполняется на более низком уровне протокола. В итоге миграция нужна только при переходе между разными сетями, а это не самый частый случай.
Во-вторых: полезна ли эта функция для других сценариев, кроме отправки больших файлов или онлайн-конференции? Если вы загружаете веб-страницу и в этот самый момент переходите между сетями, придется повторно запросить некоторые последние ресурсы.
Но загрузка страницы занимает секунды, маловероятно, что этот период совпадёт со сменой сети. Более того, в сценариях, где это действительно проблема, уже настроены другие механизмы миграции. Например, серверы, с которых загружают большие файлы, могут поддерживать HTTP-запросы с диапазоном, чтобы загрузку можно было возобновлять.
Поскольку есть переходный период, пока первая сеть отключается, а вторая подключается, видеоприложения могут открывать несколько соединений (по одному на сеть), синхронизируя их после полного отключения первой сети. Пользователь заметит переключение, но перерывов в воспроизведении видео быть не должно.
В-третьих, нет никаких гарантий, что в новой сети будет такая же полоса пропускания, как в старой. Поэтому даже если по сути соединение не прерывается, сервер QUIC не может отправлять данные на прежней высокой скорости. Чтобы избежать перегрузки в новой сети, он должен сбросить (или хотя бы снизить) скорость отправки и снова начать с медленного старта.
Начальная скорость обычно слишком маленькая, чтобы поддержать видеостриминг, так что вы заметите потерю качества или короткие сбои даже с QUIC. В каком-то смысле миграция соединения нужна скорее не для повышения производительности, а для того, чтобы сохранить контекст соединения и не потреблять лишние ресурсы сервера.
А вы знали?
Если очень постараться, можно оптимизировать миграцию соединения. Например, можно попытаться запомнить, какая полоса пропускания была доступна в конкретной сети в прошлый раз, и быстрее увеличить скорость до этого уровня при миграции. Ещё можно представить, что мы не просто переключаемся между сетями, а используем их обе одновременно. Эта концепция называется multipath, и мы поговорим о ней чуть позже.
Пока мы, в основном, говорили об активной миграции соединения, когда пользователи перемещаются между сетями. Но бывает еще и пассивная миграция, когда сама сеть меняет параметры. Хороший пример — повторная привязка NAT (преобразование сетевых адресов). Здесь мы не будем подробно говорить о NAT, но суть в том, что номера портов могут меняться в любое время без предупреждения. На большинстве роутеров это чаще происходит для UDP, чем для TCP.
В таких случаях QUIC CID не меняется, и большинство реализаций протокола предполагают, что пользователь находится в той же физической сети, а значит не сбрасывают окно перегрузки и другие параметры. QUIC также использует PING и индикаторы таймаута, чтобы предотвратить подобное, потому что обычно это происходит с соединениями, которые долго неактивны.
В первой части мы говорили, что для безопасности QUIC использует несколько CID. При миграции CID меняется. На практике всё сложнее, потому что у клиента и сервера есть отдельные списки CID (в QUIC RFC они называются CID источника и назначения). См. рисунок 5.
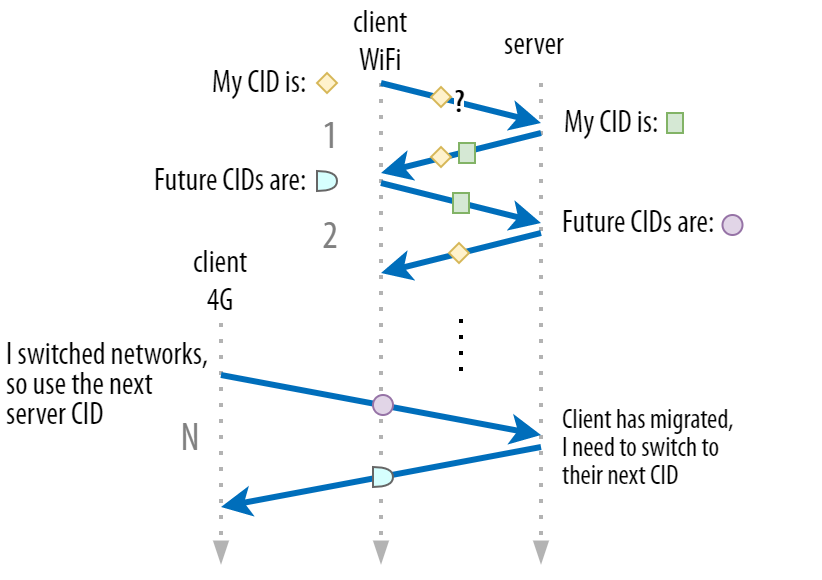 Рис. 5: QUIC использует отдельные CID для клиента и сервера(исходное изображение).
Рис. 5: QUIC использует отдельные CID для клиента и сервера(исходное изображение).Это позволяет каждой конечной точке выбирать собственный формат CID и содержимое. Это важно для расширенной логики маршрутизации и балансировки нагрузки. При миграции соединения балансировщики нагрузки не могут просто идентифицировать соединение по четырем параметрам и направить его на нужный бэкенд-сервер. Если бы все QUIC-соединения использовали случайные CID, это потребовало бы много памяти на стороне балансировщика нагрузки, потому что пришлось бы хранить соответствия CID с бэкенд-серверами. Миграции бы не получалось, потому что CID менялись бы на новые случайные значения.
Поэтому важно, чтобы у бэкенд-серверов QUIC, развернутых за балансировщиком нагрузки, был предсказуемый формат CID. Тогда балансировщик сможет определить по CID нужный сервер даже после миграции. Способы добиться этого описаны в документе, предложенном IETF. Для этого у серверов должна быть возможность выбирать собственный CID, но это было бы невозможно, если бы инициатор соединения (для QUIC это всегда клиент) выбирал CID сам. Поэтому CID клиента и сервера в QUIC разделены.
Что всё это значит?
Миграция соединения зависит от ситуации. Начальные тесты Google, например, показывают небольшой процент улучшений для их сценариев. Во многих реализациях QUIC эта функция ещё не поддерживается. А даже если поддерживается, используется для мобильных клиентов и приложений, а не их десктопных эквивалентов. Некоторые даже считают, что эта функция не нужна вовсе, потому что в большинстве случаев установка нового соединения с 0-RTT дает аналогичную производительность.
Всё же для некоторых вариантов применения и пользовательских профилей она может быть очень полезной. Если ваш сайт или приложение обычно используются во время движения (например, Uber или Google Maps), преимущества будут более очевидными, чем в случаях, когда ваши пользователи просто сидят за столом. Если речь о непрерывном взаимодействии (видеочат, совместное редактирование или игры), наихудшие варианты улучшатся заметнее, чем при использовании новостных сайтов.
Удаление блокировки HoL
Четвертая функция производительности должна ускорить QUIC в сетях с большими потерями пакетов, решая проблему блокировки HoL. В теории звучит хорошо, но на практике мы, скорее всего, увидим, что производительность при загрузке веб-страниц вырастет незначительно.
Для начала поговорим о приоритизации потоков и мультиплексировании.
Приоритизация потоков
В первой части мы говорили, что потеря одного пакета в TCP может привести к задержке данных для нескольких ресурсов, потому что абстракция потока байтов считает все данные частью одного файла. QUIC видит параллельные, но разные потоки байтов и обрабатывает потерю пакетов для каждого потока отдельно. На самом деле потоки передают данные не совсем параллельно. По сути, данные потока мультиплексируются в одном соединении. Мультиплексирование происходит по-разному.
Например, для потоков A, B и C последовательность отправки пакетов может быть
ABCABCABCABCABCABCABCABC, то есть пакеты чередуются по кругу, по принципу round-robin. Порядок может быть и другим, например AAAAAAAABBBBBBBBCCCCCCCC, то есть следующий поток отправляется только после полной отправки предыдущего (назовем это последовательной передачей). Комбинации могут быть разными: AAAABBCAAAAABBC…, AABBCCAABBCC…, ABABABCCCC… и т. д. Схема мультиплексирования очень динамичная и управляется функцией приоритизации потоков на уровне HTTP (подробнее об этом чуть позже).Оказывается, выбор схемы мультиплексирования заметно влияет на производительность загрузки сайта. Это видно на видео внизу (спасибо Cloudflare), поскольку у каждого браузера свой мультиплексор. У этого явления множество причин, и я не раз писал об этом (например, здесь и здесь) и рассказывал на конференции. Патрик Минан (Patrick Meenan), создатель Webpagetest, записал целое трехчасовое руководство исключительно на эту тему.
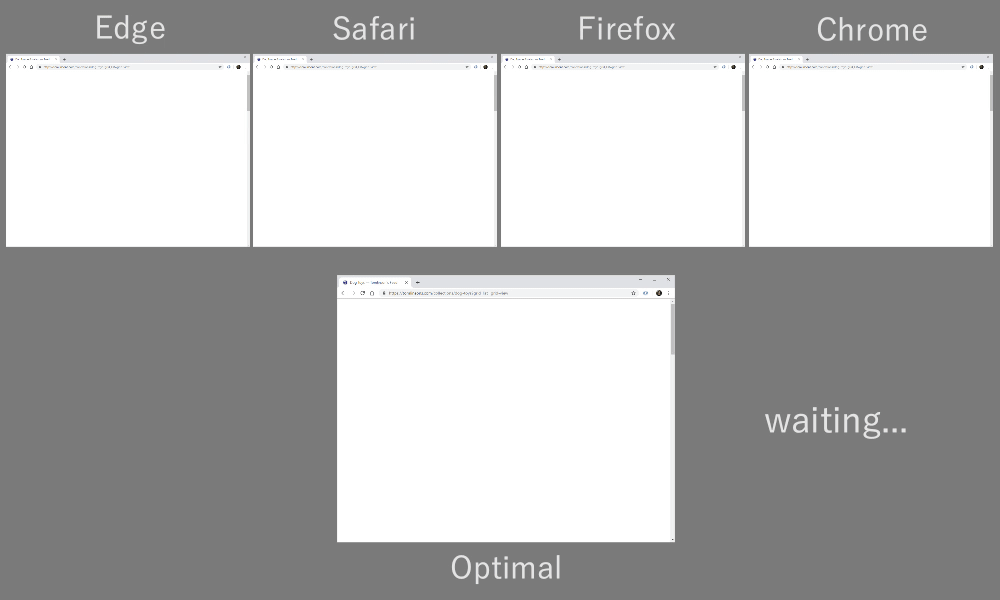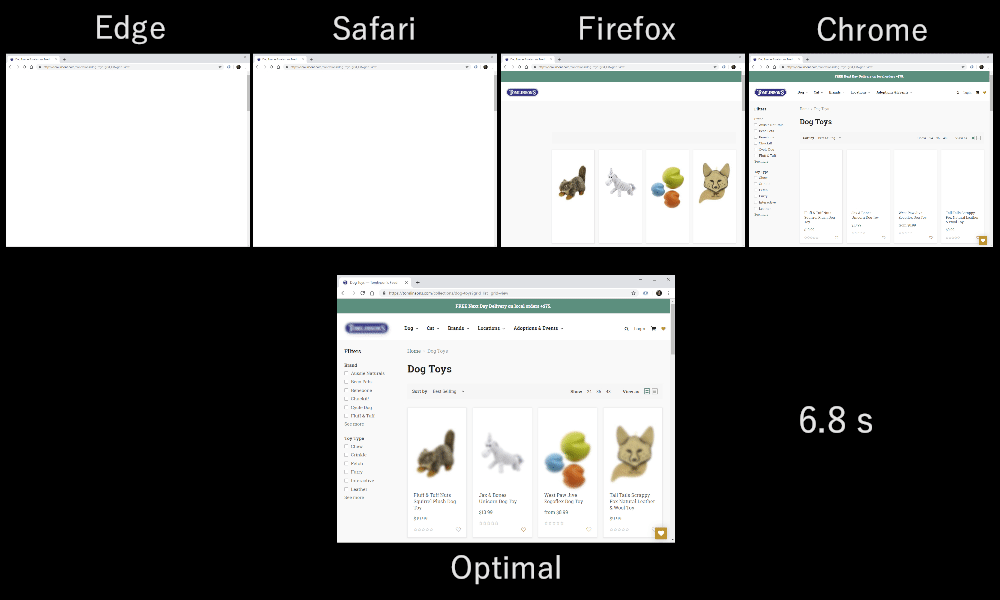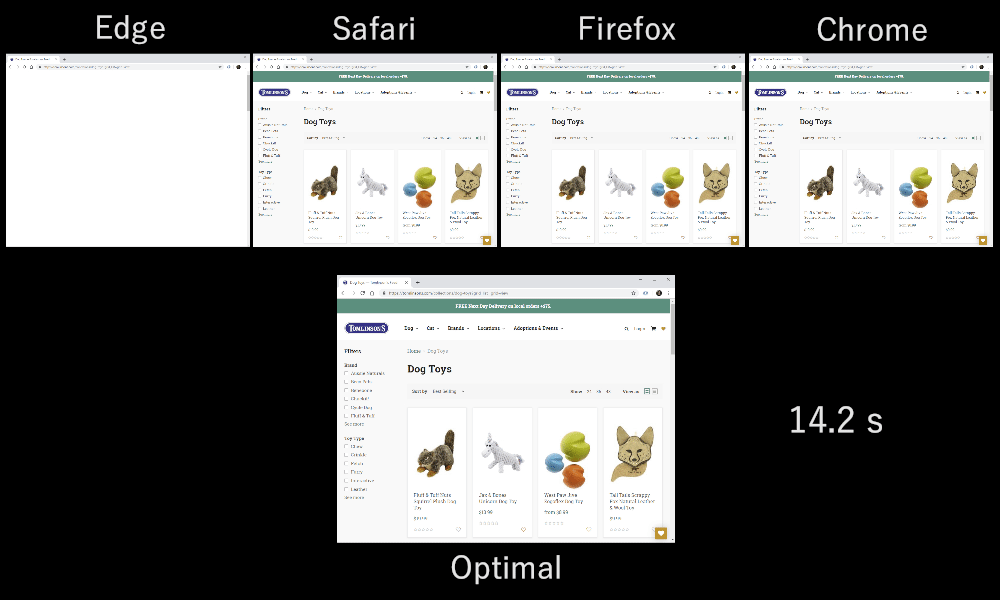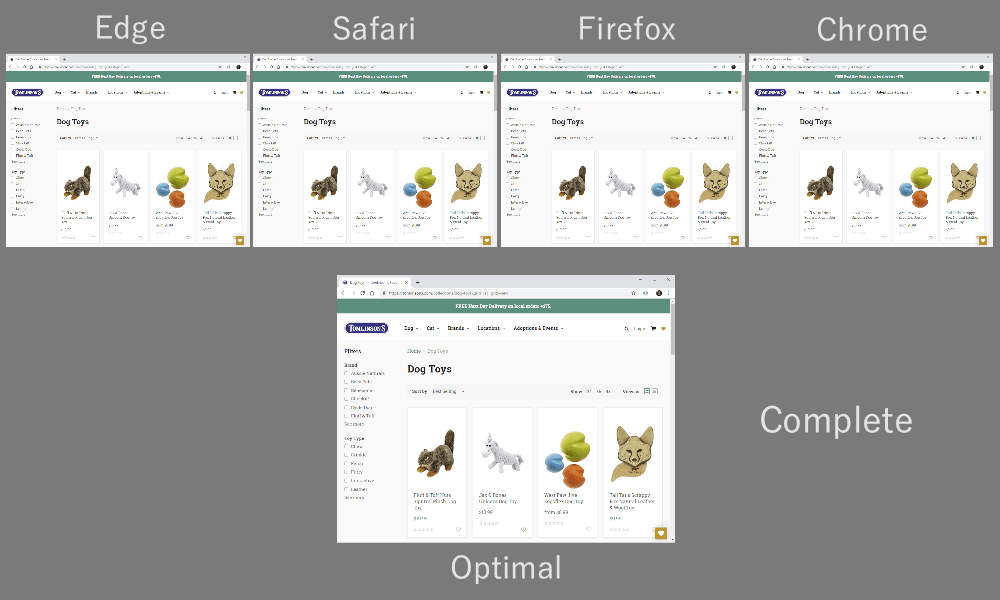 Как различия в мультиплексировании влияют на загрузку сайтов в разных браузерах (исходник).
Как различия в мультиплексировании влияют на загрузку сайтов в разных браузерах (исходник).К счастью, основы можно объяснить относительно просто. Возможно, вы знаете, что некоторые ресурсы блокируют рендеринг. Так бывает с файлами CSS и иногда с JavaScript в элементе HTML
head. Эти файлы загружаются, но браузер не может отрисовать страницу (или, например, выполнить новые JavaScript).Более того, файлы CSS и JavaScript нужно загрузить полностью, чтобы использовать (хотя их часто можно парсить и компилировать постепенно). Такие ресурсы нужно загружать как можно быстрее, у них наивысший приоритет. Что будет, если ресурсы A, B и C будут блокировать рендеринг?
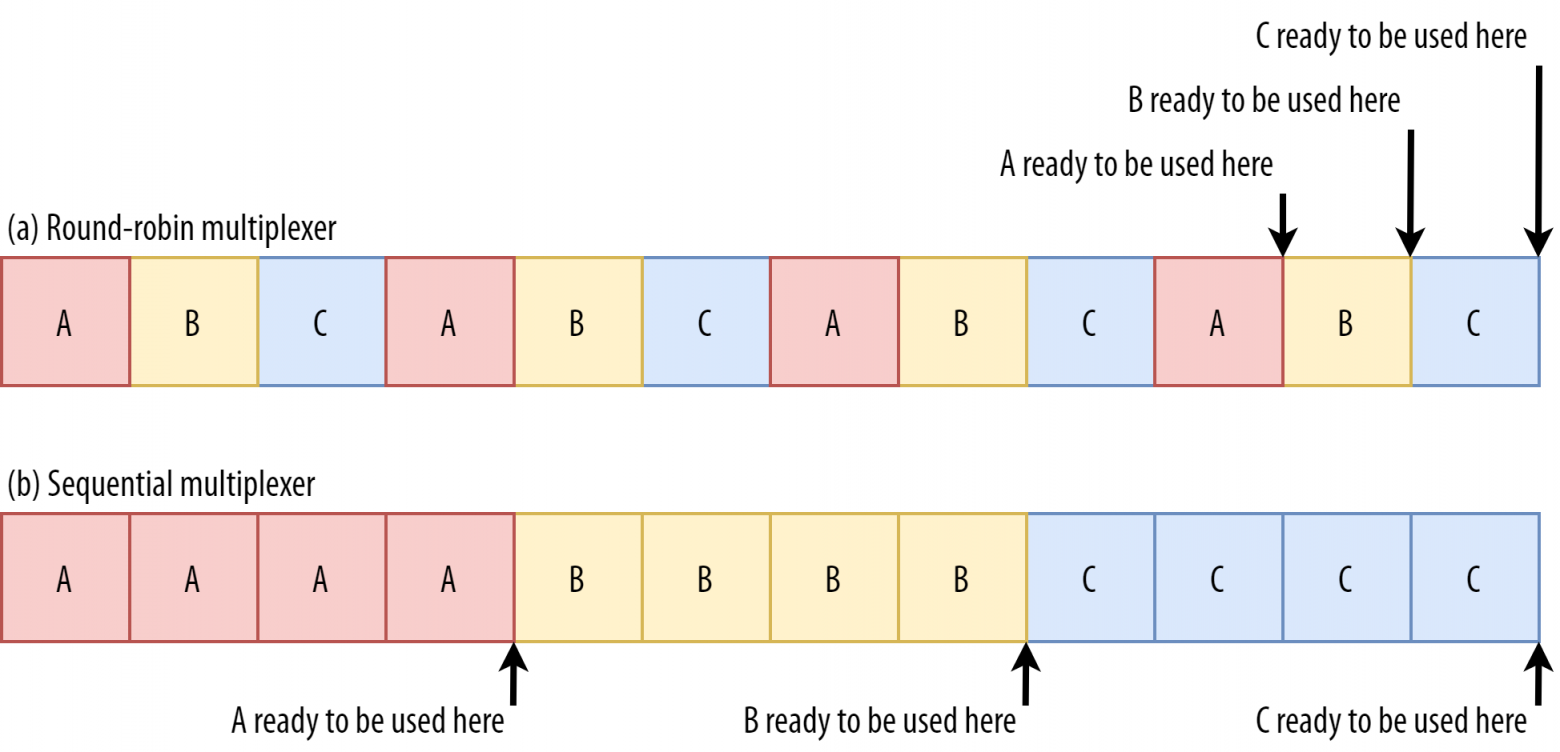 Рис. 6: Подход к мультиплексированию потока влияет на время загрузки ресурсов, блокирующих рендеринг (исходное изображение).
Рис. 6: Подход к мультиплексированию потока влияет на время загрузки ресурсов, блокирующих рендеринг (исходное изображение).Если использовать принцип round-robin (верхний ряд на рис. 6), мы задержим загрузку каждого ресурса, потому что им придется делить полосу пропускания с остальными. Раз их можно использовать только после полной загрузки, задержка будет значительной. Если мультиплексировать их последовательно (нижний ряд на рис. 6), A и B загрузятся гораздо раньше и будут доступны для браузера, при этом они не повлияют на время загрузки C.
Это не значит, что последовательный подход всегда лучше, потому что ресурсы без блокировки рендеринга (например, HTML и прогрессивный JPEG) можно обрабатывать и использовать постепенно. В этих и некоторых других случаях лучше использовать первый вариант или что-то среднее.
Но для большинства ресурсов веб-страниц последовательное мультиплексирование работает лучше. Так, например, поступает Google Chrome на видео выше, а Internet Explorer использует самый неподходящий мультиплексор с round-robin.
Устойчивость к потере пакетов
Итак, мы знаем, что потоки не всегда активны одновременно и могут мультиплексироваться по-разному. Давайте посмотрим, что происходит при потере пакетов. В первой части мы видели, что если в одном потоке QUIC теряется пакет, остальные активные потоки все равно можно использовать (в TCP они будут приостановлены).
Как мы только что узнали, несколько параллельных активных потоков — это обычно не лучший вариант в плане производительности, потому что важные ресурсы с блокировкой рендеринга загружаются медленно даже без потери пакетов. Лучше, чтобы активным был только один или два потока, как в последовательном подходе. Но при такой схеме мы не реализуем весь потенциал удаления блокировок HoL в QUIC.
Допустим, отправитель может передать 12 пакетов за раз (см. рис. 7) — помните, что это число ограничено механизмом контроля перегрузки). Если все эти 12 пакетов будут относиться к потоку A (потому что он блокирует рендеринг и имеет высший приоритет — допустим, это
main.js), у нас будет всего один активный поток.Если один из пакетов потеряется, придется применить блокировку HoL — у QUIC просто не будет других потоков для обработки, кроме A. Все данные здесь относятся только к A (у нас нет данных B или C) и остальным ресурсам придется ждать, как в TCP.
 Рис. 7: Последствия потери пакетов зависят от мультиплексора. Мы предполагаем, что у каждого потока больше для данных для отправки, чем на предыдущих изображениях (исходное изображение).
Рис. 7: Последствия потери пакетов зависят от мультиплексора. Мы предполагаем, что у каждого потока больше для данных для отправки, чем на предыдущих изображениях (исходное изображение).Возникает противоречие: последовательное мультиплексирование (
AAAABBBBCCCC) обычно лучше для производительности веб-страниц, но оно мешает нам использовать все преимущества удаления блокировки HoL в QUIC. Мультиплексирование по принципу round-robin (ABCABCABCABC) лучше сочетается с отсутствием блокировки HoL, но снижает производительность. В итоге получается, что один метод оптимизации нивелирует другой.И даже это еще не всё. Пока мы говорили только о потере пакетов по одному за раз. На самом деле пакеты в интернете теряются пачками, по несколько штук одновременно.
Выше мы говорили, что пакеты часто теряются, когда сеть уже перегружена данными и отбрасывает лишнее. Затем и нужен медленный старт, после которого скорость увеличивается вплоть до… потери пакетов!
То есть механизм, который должен предотвращать перегрузку сети, по факту перегружает сеть (пусть и контролируемо). В большинстве сетей это происходит через некоторое время, когда пакеты отправляются по несколько сотен за раз. Когда лимит достигнут, можно потерять сразу много пакетов.
А вы знали?
Отчасти поэтому мы и хотели перейти на использование одного (TCP) соединения с HTTP/2 вместо 6–30 соединений с HTTP/1.1. Каждое отдельное соединение ускоряется примерно одинаково, поэтому у HTTP/1.1 была бы хорошая скорость в начале, но потом началась бы массовая потеря пакетов, потому что соединения перегрузили бы сеть и мешали друг другу.
В то время разработчики Chromium высказывали предположения, что это поведение отвечает за потерю большинства пакетов в интернете. И это одна из причин, по которым BBR часто используется как алгоритм контроля перегрузок, — он оценивает доступную полосу пропускания по колебаниям в RTT, а не потере пакетов.
А вы знали?
Другие причины могут привести к потере небольшого количества пакетов, особенно в беспроводных сетях. Но там потери обычно обнаруживаются на нижних уровнях протокола и решаются между двумя объектами (скажем, смартфоном и вышкой 4G), а не между клиентом и сервером. Обычно это не приводит к настоящей потере пакетов, а выражается, скорее, как отклонения в задержках (jitter) и поступление пакетов в другом порядке.
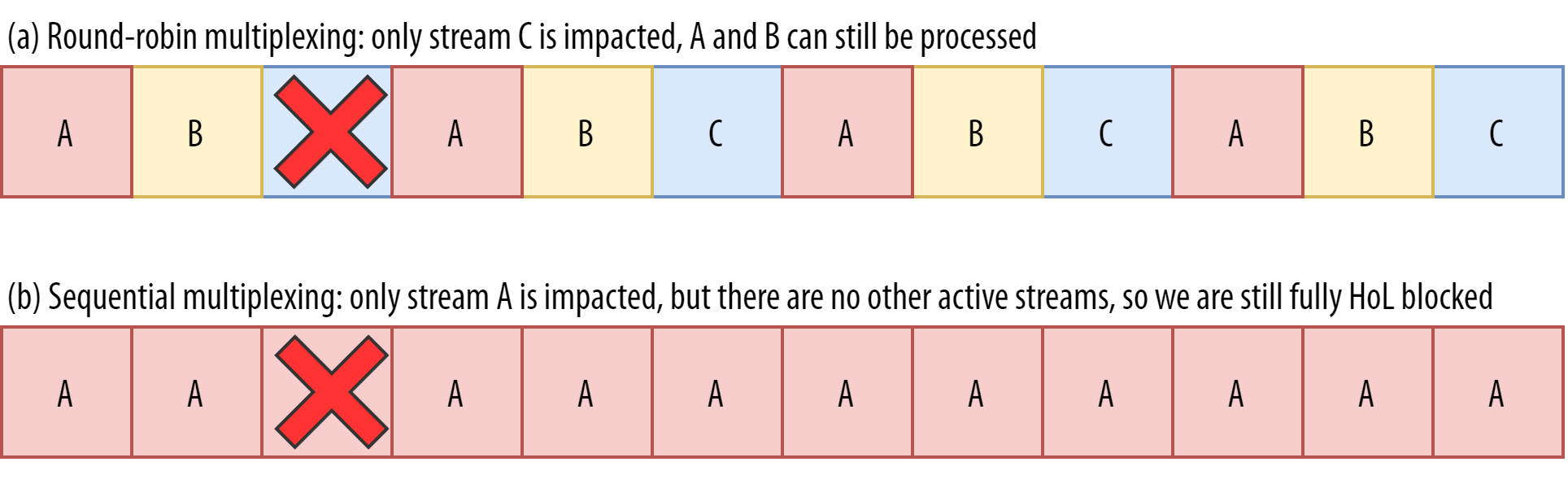
Допустим, мы используем подход round-robin (ABCABCABCABCABCABCABCABC…), чтобы получить максимум преимуществ от удаления блокировки HoL, и у нас теряется группа из четырёх пакетов. Такая потеря всегда будет затрагивать все три потока (см. средний ряд на рис. 8). В этом случае удаление блокировки HoL в QUIC не даёт никаких преимуществ, потому что всем потокам придётся ждать повторной передачи.
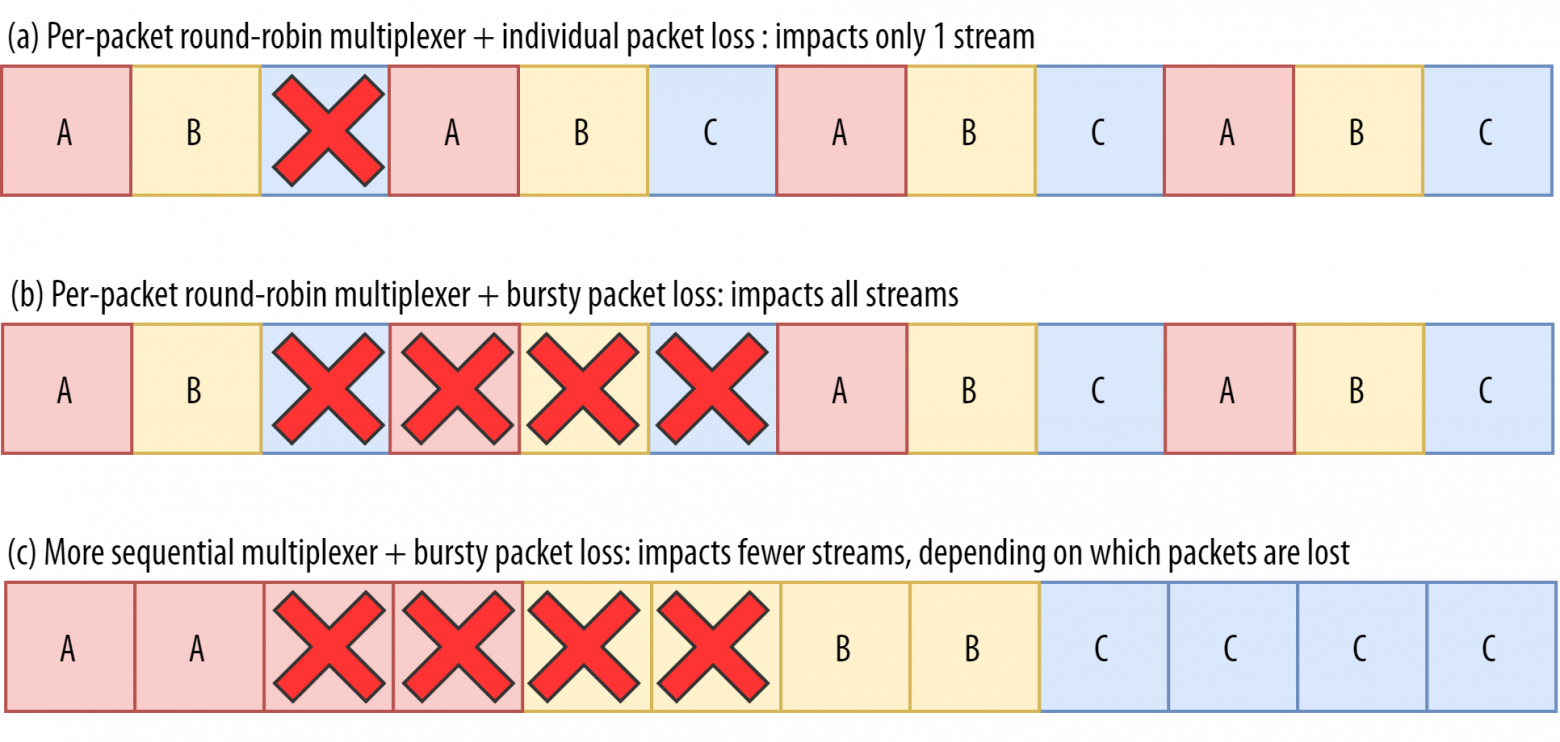 Рис. 8: В зависимости от мультиплексора и количества потерянных пакетов будет затронут один или несколько потоков(исходное изображение).
Рис. 8: В зависимости от мультиплексора и количества потерянных пакетов будет затронут один или несколько потоков(исходное изображение).Чтобы потеря группы пакетов не влияла сразу на несколько потоков, нужно передавать подряд больше пакетов из одного потока. Например, схема
AABBCCAABBCCAABBCCAABBCC… сработает чуть лучше, а AAAABBBBCCCCAAAABBBBCCCC… — ещё лучше (см. нижний ряд на рис. 8). Более последовательный подход будет эффективнее, хотя с ним у нас будет меньше параллельности.В целом сложно предсказать, какую пользу мы получим от удаления блокировки HoL в QUIC. Все зависит от числа потоков, размера и частоты потери групп пакетов, фактического использования данных потока и т. д. Однако пока большинство результатов показывают, что преимущество не так уж заметно при загрузке веб-страниц, потому что в этом сценарии у нас обычно меньше параллельных потоков.
Если хотите больше узнать об этой теме или изучить конкретные примеры, читайте мою статью с подробным описанием блокировки HoL в HTTP.
А вы знали?
Здесь тоже можно использовать разные хитрости. Например, современные механизмы контроля перегрузки используют packet pacing. Это значит, что они не отправляют, допустим, 100 пакетов одной группой, а распределяют их по всему RTT. Это снижает вероятность перегрузки сети, и в QUIC Recovery RFC рекомендуется использовать такой подход. Кроме того, некоторые алгоритмы контроля перегрузок, например BBR, не повышают скорость отправки до потери пакетов, а останавливаются заранее, учитывая, например, колебания RTT, поскольку RTT возрастает при приближении к перегрузке).
Такие подходы снижают вероятность потери пакетов, но не всегда снижают частоту возникновения такого явления, как потеря пакетов.
Что всё это значит?
В теории удаление блокировки HoL означает, что QUIC (и HTTP/3) будут работать лучше в сетях с большими потерями, но на практике всё зависит от многих факторов. Поскольку для загрузки веб-страниц лучше подходит более последовательное мультиплексирование, а потеря пакетов непредсказуема, скорее всего, эта функция будет по-настоящему полезна только для 1% самых медленных пользователей. Но исследования продолжаются и, может быть, что-то изменится.
В некоторых ситуациях улучшения будут более заметны. В основном, не для первой полноценной загрузки страницы (самого распространённого сценария), а в случаях, когда ресурсы не блокируют рендеринг, и они могут обрабатываться постепенно, тогда как потоки полностью независимы друг от друга или за один раз отправляется меньше данных.
Например, при повторном посещении хорошо кэшированных страниц, фоновых загрузках и вызовах API в одностраничных приложениях. Facebook, скажем, реализует преимущества удаления блокировки HoL, когда загружает данные в их собственное приложение приложение через HTTP/3.
Производительность UDP и TLS
Пятый аспект производительности QUIC и HTTP/3 связан с тем, насколько эффективно и продуктивно эти протоколы могут создавать и отправлять пакеты в сети. Мы увидим, что из-за UDP и массового шифрования QUIC может работать медленнее, чем TCP (но постепенно прогрессирует).
Мы уже говорили, что QUIC использует UDP для гибкости и простоты развёртывания, а не для производительности. Это подтверждает и тот факт, что до последнего времени через QUIC с UDP пакеты отправлялись гораздо медленнее, чем у TCP. Во многом это связано с тем, где и как обычно реализуются эти протоколы (см. рис. 9).
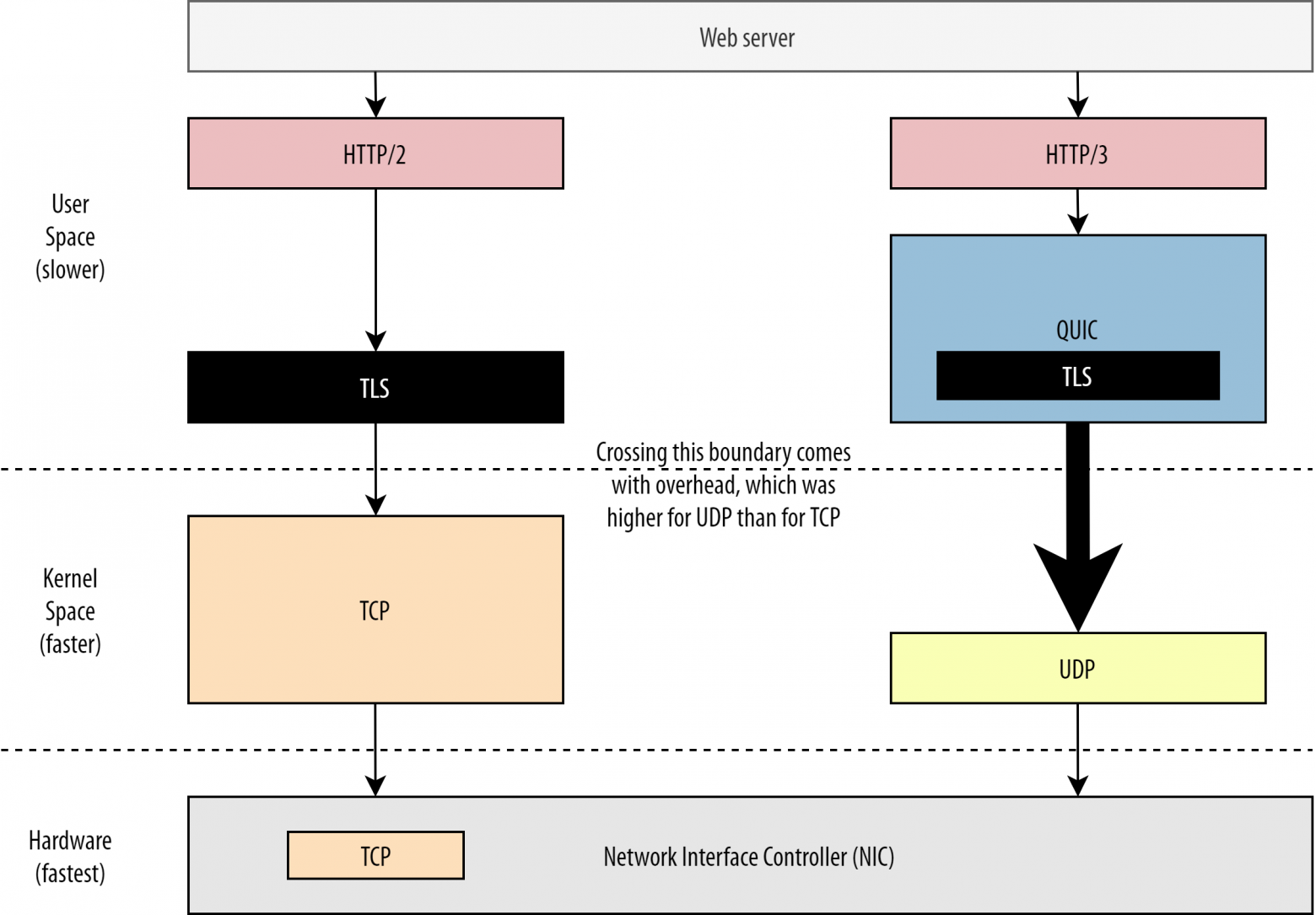 Рис. 9: Различия в реализации между TCP и QUIC (исходное изображение) .
Рис. 9: Различия в реализации между TCP и QUIC (исходное изображение) .Как мы говорили выше, TCP и UDP обычно реализуются на быстром уровне, прямо в ядре ОС. TLS и QUIC, в основном, реализуются в более медленном пользовательском пространстве (в QUIC это сделано, в основном, для гибкости). Хотя бы из-за этого QUIC работает чуть медленнее, чем TCP.
Кроме того, если данные отправляются из софта в пользовательском пространстве (допустим, браузеров или веб-серверов), мы должны передать эти данные в ядро ОС, которое затем использует TCP или UDP для их передачи в сеть. Данные передаются через API ядра (системные вызовы), что приводит к некоторым издержкам. Для TCP эти издержки были гораздо меньше, чем для UDP.
В основном, потому что традиционно TCP использовался гораздо больше, чем UDP. Со временем в реализации TCP и API ядра добавили много оптимизаций, чтобы свести к минимуму издержки при отправке и получении пакетов. Во многих сетевых платах (NIC) даже есть встроенная аппаратная обработка (hardware-offload) для TCP. UDP не так повезло, потому что он используется ограниченно и вроде как не стоит затраченных усилий. К счастью, в последние пять лет большинство ОС добавили варианты оптимизации и для UDP.
QUIC связан с большими издержками, потому что шифрует каждый пакет отдельно. Стек TLS + TCP делает это быстрее и эффективнее, потому что пакеты шифруются группами (до 16 КБ или 11 пакетов за раз). В QUIC от этого отказались намеренно, потому что шифрование нескольких пакетов может привести к блокировке HoL.
Здесь уже нельзя добавить API, чтобы ускорить UDP (и QUIC), а значит по этому показателю QUIC всегда будет отставать от TCP + TLS. Но на практике можно, например, использовать оптимизированные библиотеки шифрования и продуманные методы, чтобы шифровать заголовки пакетов QUIC по несколько штук.
Первые версии QUIC от Google работали в два раза медленнее, чем TCP + TLS, но с тех пор всё стало гораздо лучше. Например, в недавних тестах Microsoft удалось достичь для тщательно оптимизированного стека QUIC скорости в 7,85 Гбит/с, тогда как TCP + TLS показал 11,85 Гбит/с в той же системе (здесь QUIC примерно на треть медленнее TCP + TLS).
Всё благодаря последним апдейтам Windows, которые ускорили UDP (для полноты сравнения — пропускная способность UDP в этой системе была 19,5 Гбит/с). Самая оптимизированная версия стека QUIC у Google сейчас на 20% медленнее, чем TCP + TLS. Ранние тесты, проведённые Fastly на менее продвинутых системах и с некоторыми доработками даже показывают одинаковые цифры (примерно 450 Мбит/с), то есть в определённых условиях QUIC вполне может составить конкуренцию TCP.
Но даже если QUIC будет в два раза медленнее TCP + TLS, это не так уж и страшно. Начнем с того, что обработка QUIC и TCP + TLS — не самая ресурсоёмкая задача на сервере, потому что есть и другие процессы (допустим, HTTP, кэширование, прокси и т. д.). Поэтому вам не понадобится в два раза больше серверов для QUIC (пока не совсем ясно, как всё-таки это отразится на реальном дата-центре, потому что никто из крупных компаний ещё не рассказывал об этом).
Во-вторых, есть много возможностей оптимизировать реализации QUIC в будущем. Например, со временем некоторые реализации QUIC будут частично перенесены в ядро ОС (как TCP) или будут обходить его (некоторые уже это делают, например MsQuic и Quant). Можно ожидать появления оборудования под QUIC.
Скорее всего, в некоторых сценариях TCP + TLS останется предпочтительным вариантом. Например, в Netflix в обозримом будущем не собираются переходить на QUIC, потому что серьёзно вложились в специфичные решения на базе FreeBSD для стриминга по TCP + TLS.
В Facebook тоже говорят, что из-за больших издержек QUIC пока будет использоваться между конечными пользователями и границей CDN, но не между дата-центрами или граничными узлами и исходными серверами. В целом, если полоса пропускания большая, лучше использовать TCP + TLS. Во всяком случае в следующие пару-тройку лет.
А вы знали?
Оптимизация сетевых стеков — это огромное непаханое поле, которое мы пока ковыряем лопаткой. Если вам хватит смелости или очень хочется узнать, что такоеGRO/GSO,SO_TXTIME, kernel bypass,sendmmsg()иrecvmmsg(), почитайте интересные статьи об оптимизации QUIC от Cloudflare и Fastly или посмотрите подробные обзоры от Microsoft и Cisco. Один инженер из Google интересно рассказал, как они планируют оптимизировать свою реализацию QUIC.
Что всё это значит?
Из-за подхода к применению протоколов UDP и TLS изначально QUIC был гораздо медленнее, чем TCP + TLS. Сейчас благодаря разным улучшениям он потихоньку догоняет. В обычных условиях при загрузке веб-страниц вы вряд ли что-то заметите, но на больших серверных фермах эти расхождения будут бросаться в глаза.
Возможности HTTP/3
До сих пор мы сравнивали QUIC и TCP. А как насчёт HTTP/3 и HTTP/2? В первой части мы говорили, что HTTP/3 — это, по сути, HTTP/2-over-QUIC, так что ничего особо нового ждать не приходится. HTTP/1.1 и HTTP/2 гораздо сильнее отличаются друг от друга, например, сжатием заголовков, приоритизацией потоков и server push. Всё это есть и в HTTP/3. Разница в том, как эти возможности реализованы.
В основном, это связано с тем, как работает в QUIC удаление блокировки HoL. Мы уже говорили, что потеря пакетов из потока B больше не означает, что потокам A и C придётся ждать, пока B догонит, как это было в TCP. Так что если пакеты A, B и C были отправлены через QUIC в этом порядке, в итоге браузер может получить и обработать их в порядке A, C, B! Другими словами, в отличие от TCP, QUIC не соблюдает строгий порядок потоков.
HTTP/2 ждал от TCP пакеты в определённом порядке для многих функций, которые используют специальные управляющие сообщения и фрагменты данных. В QUIC управляющие сообщения могут поступать и применяться в любом порядке, так что потенциально результат выполнения функций может быть противоположен ожидаемому. В технические дебри углубляться не будем, но по первой половине этой статьи видно, насколько это неразумно сложная схема.
В итоге внутренняя механика и реализация функций должна была измениться в HTTP/3. Конкретный пример — сжатие заголовков HTTP, которое позволяет сэкономить на повторяющихся больших заголовках HTTP (например, cookie и строки user-agent). В HTTP/2 для этого использовался HPACK, который для HTTP/3 переделали в более сложный QPACK. Обе системы выполняют одну задачу (сжимают заголовки), но по-разному. Подробные технические описания и схемы читайте в блоге Litespeed.
Примерно то же самое можно сказать и о функции приоритизации, которая управляет логикой мультиплексирования потоков, как мы недавно увидели. В HTTP/2 она реализована с помощью сложного дерева зависимостей, которое пыталось описать все ресурсы страницы и их взаимосвязи (есть интересное видео о приоритизации ресурсов в HTTP). Если просто перенести эту систему на QUIC, дерево может получиться очень странное, потому что добавление в него каждого ресурса потребовало бы отдельного управляющего сообщения.
Такой подход оказался слишком сложным, так что в реализациях возникали баги и недостатки, а производительность на многих серверах оставляла желать лучшего. В итоге система приоритизации в HTTP/3 была переработана и упрощена. С упрощённой структурой затруднительно или даже невозможно реализовать некоторые сложные сценарии (например, проксирование трафика с нескольких клиентов в одно соединение), но для оптимизации загрузки веб-страниц возможностей достаточно.
Здесь тоже оба подхода решают одну задачу (мультиплексирование), но мы надеемся, что благодаря простоте настройки HTTP/3 в реализации будет меньше багов.
Наконец, server push. позволяет серверу отправлять HTTP-ответы без явного запроса. В теории это должно серьезно повысить производительность. На практике оказалось, что правильно использовать эту функцию сложно, и реализуется она несогласованно. Скорее всего, из Google Chrome эту функцию удалят.
Пока она всё ещё числится как функция HTTP/3 (хотя ее поддерживают мало реализаций). Она изменилась не так сильно, как предыдущие две функции, но её адаптировали к недетерминированному порядку в QUIC. К сожалению, это мало поможет решить её давние проблемы.
Что всё это значит?
Мы уже говорили, что большинство потенциальных преимуществ HTTP/3 связаны с QUIC. Внутренняя реализация протокола очень отличается от HTTP/2, но высокоуровневые возможности производительности и варианты их применения не изменились.
Чего нужно ждать в будущем
В этой серии я не раз подчёркивал главные преимущества QUIC (а значит и HTTP/3) — быстрое развитие и хорошая гибкость. Это значит, что новые расширения протокола и варианты его применения уже разрабатываются. Вот за чем нужно следить особенно внимательно:
- Forward error correction
Цель этой техники — повысить устойчивость QUIC к потере пакетов. Суть заключается в отправке избыточных копий данных (они по-умному закодированы и сжаты, так что занимают не очень много места). Если пакет потерялся, но у нас есть его копия, снова передавать его не нужно.
Изначально такая возможность была в Google QUIC (откуда и пошли разговоры об устойчивости к потере пакетов), но в стандартизированный QUIC version 1 она не входит, потому что её влияние на производительность пока не проверено. Эксперименты уже ведутся, и вы можете поучаствовать в них через приложение PQUIC-FEC Download Experiments.
- Multipath QUIC
Вы уже знаете о миграции соединения и о том, что она даёт, скажем, при переходе с Wi-Fi на сотовую сеть. А почему бы тогда не использовать Wi-Fi и сотовую сеть одновременно, чтобы увеличить полосу пропускания и повысить надёжность. Это главная концепция, на которой основан подход multipath.
В Google экспериментировали с этим, но в QUIC version 1 эта возможность не входит из-за своей сложности. Исследователи видят здесь большой потенциал, так что ждём QUIC version 2. Кстати, TCP multipath тоже существует, но ему понадобилось почти десять лет, чтобы стать применимым на практике.
- Передача ненадёжных данных по QUIC и HTTP/3
QUIC очень надёжный протокол, но работает поверх ненадёжного UDP, так что QUIC можно приспособить и для передачи ненадёжных данных. Механизм описан в предложенном расширении для датаграмм. Он, конечно, не подходит для отправки ресурсов веб-страницы, но может пригодиться для игр или видеостриминга. Так пользователи получат все преимущества UDP, но с шифрованием и, по желанию, контролем перегрузок от QUIC.
- WebTransport
Браузеры не открывают TCP или UDP для JavaScript напрямую, в основном, из соображений безопасности. Приходится использовать API на уровне HTTP, например Fetch, и более гибкие протоколы WebSocket и WebRTC. Самый новый вариант — WebTransport, с которым можно использовать HTTP/3 (а значит и QUIC) на более низком уровне (хотя его можно приспособить и для TCP и HTTP/2, если нужно).
Самое главное, он позволит использовать ненадёжные данные по HTTP/3 (см. выше), чтобы упростить реализацию в браузере, например, для игр. Для обычных (JSON) вызовов API мы всё равно будем использовать Fetch, который автоматически будет применять HTTP/3 по возможности. Вокруг WebTransport пока много дискуссий, так что неясно, как он в итоге будет выглядеть. Из браузеров только Chromium пока работает над открытой proof-on-concept реализацией.
- DASH и HLS для стриминга
Для видео по запросу (например, YouTube или Netflix) браузеры обычно используют протоколы Dynamic Adaptive Streaming over HTTP (DASH) и HTTP Live Streaming (HLS). Оба подразумевают кодирование видео маленькими фрагментами (2–10 секунд) и разные уровни качества (720p, 1080p, 4K).
При запуске браузер оценивает максимальное качество, которое потянет сеть (или оптимальный уровень для конкретного сценария), и запрашивает соответствующие файлы у сервера по HTTP. У браузера нет прямого доступа к стеку TCP (потому что он обычно реализуется в ядре), так что иногда он ошибается в своих оценках или медленно реагирует на изменение условий (и видео зависает).
QUIC реализуется как часть браузера, поэтому его можно заметно улучшить, если дать механизмам оценки доступ к информации на нижнем уровне протоколов (процент потерь, полоса пропускания и т. д.). Другие исследователи тоже экспериментировали со смешиванием надёжных и ненадёжных данных для видеостриминга и получили неплохие результаты.
- Другие протоколы (кроме HTTP/3)
QUIC — это транспортный протокол общего назначения, и, скорее всего, многие протоколы на прикладном уровне, которые сейчас используют TCP, будут работать и на QUIC. Сейчас уже разрабатывают DNS-over-QUIC, SMB-over-QUIC и даже SSH-over-QUIC. У этих протоколов другие требования, не связанные с HTTP и загрузкой веб-страниц, так что в них улучшения производительности QUIC могут проявляться заметнее.
Что всё это значит?
QUIC version 1 — это всего лишь начало. Многие улучшения производительности, над которыми экспериментировал Google, не вошли в первую версию. Но протокол очень быстро развивается, появляются всё новые расширения и функции. Со временем QUIC (и HTTP/3 вместе с ним) станут заметно более быстрыми и гибкими по сравнению с TCP (и HTTP/2).
Заключение
Во второй части серии мы рассмотрели разные функции и аспекты производительности HTTP/3 и особенно QUIC. Мы увидели, что большинство этих функций кажутся интересными, но на практике не приносят ожидаемой пользы среднему пользователю при загрузке веб-страниц.
Например, хоть QUIC и использует UDP, это не значит, что ему доступна более широкая полоса пропускания, чем TCP, или что он будет загружать ресурсы быстрее. Хвалёный 0-RTT позволяет сэкономить всего один круговой путь, и то мы успеем передать примерно пять килобайт (в худшем сценарии).
Удаление блокировки HoL не спасает, если мы теряем много пакетов сразу или загружаем ресурсы с блокировкой рендеринга. Миграция соединения зависит от ситуации, и HTTP/3 здесь особо не обгоняет HTTP/2.
Всё это звучит так, будто игра не стоит свеч. И что теперь? Забыть об HTTP/3 и QUIC? Ни в коем случае! Новые протоколы вряд ли впечатлят пользователей в быстрых (городских) сетях, но определённо принесут пользу мобильным пользователям и тем, кто вынужден использовать медленные сети.
Даже, например, в Европе, где мы используем быстрые устройства и высокоскоростные сотовые сети, улучшения заметят от 1 до 10% пользователей в зависимости от продукта. Например, пассажиру поезда срочно нужно найти важную информацию на вашем сайте, но приходится ждать 45 секунд, пока всё загрузится. Я не раз бывал в таких ситуациях, и QUIC пришёлся бы очень кстати.
А ведь есть страны и регионы, где условия гораздо хуже. Там среднему пользователю приходится хуже, чем 10% самых медленных пользователей в европейской стране, а для одного худшего процента страница вообще может так и не загрузиться. Во многих частях мира веб-производительность — это вопрос доступности и инклюзивности.
Поэтому тестировать страницы нужно не только на нашем хорошем оборудовании (а ещё и использовать сервисы вроде Webpagetest), и поэтому же обязательно нужно развернуть QUIC и HTTP/3. Если ваши пользователи часто находятся в дороге или не имеют доступа к быстрым сотовым сетям, новые протоколы принесут огромную пользу, даже если на своём MacBook Pro с кабельным интернетом вы ничего особенного не заметите. Обязательно почитайте пост Fastly на эту тему.
Если и это вас не убедит, просто знайте, что QUIC и HTTP/3 будут активно развиваться и ускоряться в следующие несколько лет. Опыт с протоколом на ранних этапах обязательно окупится в будущем, где вы сможете использовать преимущества новых функций сразу после их появления. Наконец, QUIC использует лучшие методы безопасности и конфиденциальности, которые будут полезны абсолютно всем пользователям.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}