
В прошлом посте я рассказал, как доставить логи из systemd. Теперь давайте разберёмся, как доставлять логи контейнеризированного приложения.
Шаг 1. Пишем логи
Ну что ж, опять начнём с того, что набросаем демоприложение на питоне, которое будет для нас генерировать записи логов: logs.py.
import logging import random import sys import time # Писать логи контейнера будем в STDOUT. Разбивать по severity будем при помощи парсера в Fluent-bit import uuid logger = logging.getLogger(__name__) # Зададим форматер чтобы позже по этому же шаблону парсить логи. formatter = logging.Formatter( '[req_id=%(req_id)s] [%(levelname)s] %(code)d %(message)s' ) handler = logging.StreamHandler(stream=sys.stdout) handler.setFormatter(formatter) logger.addHandler(handler) # Опционально можно настроить уровень логирования по умолчанию logger.setLevel(logging.DEBUG) # Мы могли бы обойтись и простым логированием случайных чисел, но я решил генерировать URL-подобные значения. PATHS = [ '/', '/admin', '/hello', '/docs', ] PARAMS = [ 'foo', 'bar', 'query', 'search', None ] def fake_url(): path = random.choice(PATHS) param = random.choice(PARAMS) if param: val = random.randint(0, 100) param += '=%s' % val code = random.choices([200, 400, 404, 500], weights=[10, 2, 2, 1])[0] return '?'.join(filter(None, [path, param])), code if __name__ == '__main__': while True: req_id = uuid.uuid4() # создаем пару код и значение URL path, code = fake_url() extra = {"code": code, "req_id": req_id} # Если код 200, то пишем в лог с уровнем Info if code == 200: logger.info( 'Path: %s', path, extra=extra, ) # Иначе с уровнем Error else: logger.error( 'Error: %s', path, extra=extra, ) # Чтобы можно было погрепать несколько сообщение по одному request id в 30% случаев будем писать вторую запись # в лог с уровнем Debug. if random.random() > 0.7: logger.debug("some additional debug log record %f", random.random(), extra=extra) # Ждем 1 секунду, чтобы излишне не засорять журнал time.sleep(1)
В принципе, всё просто и я постарался оставить комментарии, но я пройдусь ещё раз по основным пунктам.
Логи Docker-контейнера — это просто вывод STDOUT и STDERR. В приложении я решил не делить вывод по двум этим потокам, так как далее в парсере Fluent Bit у нас будет возможность распарсить строчку лога и вычленить оттуда уровень, с которым была сделана запись.
Формат строчки лога я постарался не перегружать, вывел лишь базовые параметры типа кода ответа и id запроса.
Шаг 2. Настраиваем развёртывание COI VM
Так как нам нужно развернуть как минимум два контейнера (контейнер с нашим приложением и логер-агент Fluent Bit), воспользуемся возможностью COI работать со спецификацией Docker Compose. Опишем в файле наши контейнеры. Репозиторий с моим образом не публичный — используйте свой. Например, так как в spec.yml.
version: '3.7' services: logs: container_name: logs-app image: cr.yandex/crpk28lsfu91rns28316/dockerlogtest:2021.10.17-6166ecb restart: always depends_on: - fluentbit logging: # Fluent-bit понимает логи в этом формате driver: fluentd options: # куда посылать лог-сообщения, необходимо что бы адрес # совпадал с настройками плагина forward fluentd-address: localhost:24224 # теги используются для маршрутизации лог-сообщений, тема # маршрутизации будет рассмотрена ниже tag: app.logs fluentbit: container_name: fluentbit image: cr.yandex/yc/fluent-bit-plugin-yandex:v1.0.3-fluent-bit-1.8.6 ports: - 24224:24224 - 24224:24224/udp restart: always environment: YC_GROUP_ID: e23j5q1nhth94apeduuh volumes: - /etc/fluentbit/fluentbit.conf:/fluent-bit/etc/fluent-bit.conf - /etc/fluentbit/parsers.conf:/fluent-bit/etc/parsers.conf
В контейнер Fluent Bit дополнительно передаём переменную окружения YC_GROUP_ID. Она понадобится нам для настройки плагина yc-logging, скажет ему, куда писать наши логи, и содержит id группы логирования.
Далее нам понадобится принести на ВМ конфиги. Сделаем это по инструкции, только сейчас всё проще и KMS нам не понадобится.
Шаг 3. Настраиваем чтение логов из контейнера
#cloud-config write_files: - content: | [SERVICE] Flush 1 Log_File /var/log/fluentbit.log Log_Level error Daemon off Parsers_File /fluent-bit/etc/parsers.conf [FILTER] Name parser Match app.logs Key_Name log Parser app_log_parser Reserve_Data On [INPUT] Name forward Listen 0.0.0.0 Port 24224 Buffer_Chunk_Size 1M Buffer_Max_Size 6M [OUTPUT] Name yc-logging Match * group_id ${YC_GROUP_ID} message_key text level_key severity default_level WARN authorization instance-service-account path: /etc/fluentbit/fluentbit.conf - content: | [PARSER] Name app_log_parser Format regex Regex ^\[req_id=(?<req_id>[0-9a-fA-F\-]+)\] \[(?<severity>.*)\] (?<code>\d+) (?<text>.*)$ Types code:integer path: /etc/fluentbit/parsers.conf users: - name: username groups: sudo shell: /bin/bash sudo: [ 'ALL=(ALL) NOPASSWD:ALL' ] ssh-authorized-keys: - ssh-rsa AAAA
Теперь подробнее о том, зачем нам нужна каждая часть конфига user-data.yaml, представленного выше. В секции SERVICE указаны настройки самого приложения Fluent Bit (например, период, с которым оно отправляет логи). Подробнее можно прочитать в документации.
[SERVICE] Flush 1 Log_File /var/log/fluentbit.log Log_Level error Daemon off Parsers_File /fluent-bit/etc/parsers.conf
В секции INPUT описано, откуда и как забирать логи.
[INPUT] Name forward Listen 0.0.0.0 Port 24224 Buffer_Chunk_Size 1M Buffer_Max_Size 6M
Для работы с логами в формате Fluentd и Fluent Bit нужно использовать инпут с типом forward. О других типах инпутов читайте в документации. А также у меня есть инструкция, как работать с systemd инпутом Fluent Bit.
Тут вроде всё понятно: Fluent Bit слушает логи на порту 24224. Именно туда мы велели Docker Compose отправлять логи нашего приложения в соответствующем конфиге выше.
Также в том конфиге мы сказали драйверу помечать все записи тегом app.logs. Именно на него мы можем ориентироваться, настраивая процессинг логов.
Для этого в файле parsers.conf мы опишем парсер.
[PARSER] Name app_log_parser Format regex Regex ^\[req_id=(?<req_id>[0-9a-fA-F\-]+)\] \[(?<severity>.*)\] (?<code>\d+) (?<text>.*)$ Types code:integer
Мы воспользуемся парсером regex. Для его конфигурирования зададим регулярное выражение, при помощи которого разберём строчки лога. Из каждой строки мы извлечём поля: req_id, в которое клали уникальный id запроса, severity — уровень логирования, code — HTTP-код ответа, text — весь остальной текст.
Теперь с помощью парсера преобразуем логи. Для этого в основном конфиге добавим секцию FILTER.
[FILTER] Name parser Match app.logs Key_Name log Parser app_log_parser Reserve_Data On
Тут мы говорим, что ищем только логи, тег которых совпадает с app.logs, берём из записи поле log, применяем к нему наш парсер app_log_parser, а все остальные поля лога сохраняем (Reserve_Data On).
Шаг 4. Отгружаем в Cloud Logging
Ну вот мы и подошли к отправке логов в облако. Так как мы разворачивали контейнер Fluent Bit из образа, куда уже добавлен плагин Yandex Cloud Logging, нужно лишь сконфигурировать секцию OUTPUT.
[OUTPUT] Name yc-logging Match * group_id ${YC_GROUP_ID} message_key text level_key severity default_level WARN authorization instance-service-account
Для отправки логов нужна авторизация. Мы воспользуемся самым простым способом: привяжем к ВМ сервисный аккаунт, которому выдадим роль, необходимую для записи логов logging.writer, или выше.
Отлично, теперь создадим ВМ с этими конфигами.
Нам понадобится id image, из которого мы будем разворачивать ВМ:
IMAGE_ID=$(yc compute image get-latest-from-family container-optimized-image --folder-id standard-images --format=json | jq -r .id)
Дальше подставим его в команду создания ВМ:
yc compute instance create \ --name coi-vm \ --zone=ru-central1-a \ --network-interface subnet-name=default-ru-central1-a,nat-ip-version=ipv4 \ --metadata-from-file user-data=user-data.yaml,docker-compose=spec.yaml \ --create-boot-disk image-id=$IMAGE_ID \ --service-account-name service-account
Когда ВМ развернётся и контейнеры на ней запустятся, можно перейти в Cloud Logging и посмотреть логи:

Если кликнуть на иконку глаза, можно увидеть дополнительные залогированные параметры:

По ним можно пофильтровать. Например, запрос json_payload.code >= 400 найдёт все строчки логов, связанные с ответами, содержавшими ошибки.
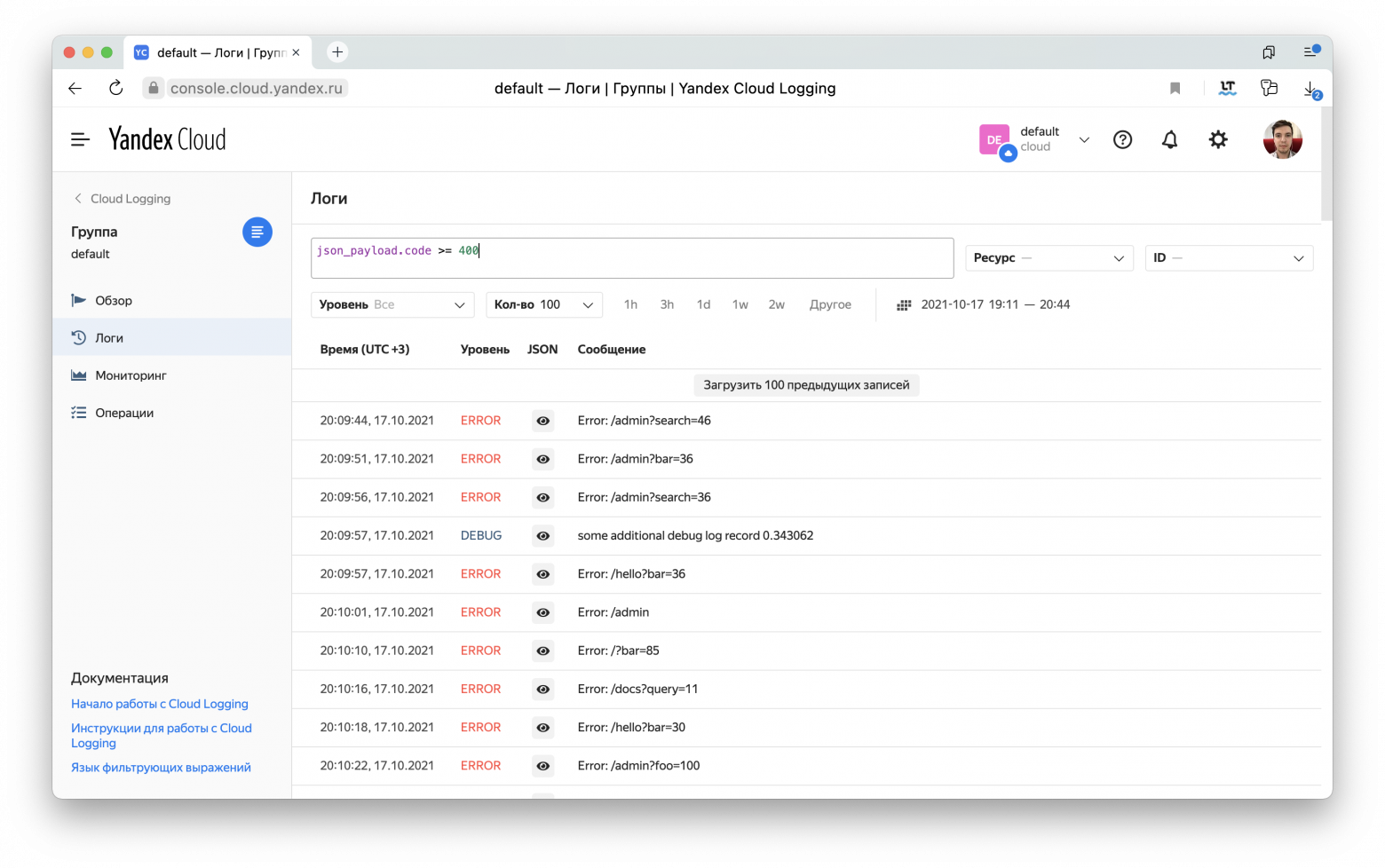
Также можно найти все сообщения, относившиеся к обработке одного запроса, если пофильтровать по json_payload.req_id.
Подробнее о языке запросов можно прочитать в документации. Весь код из этой статьи на GitHub.
P. S. Yandex Cloud Logging — это serverless-сервис в Yandex.Cloud. Если вам интересна экосистема Serverless-сервисов и все, что с этим связано, заходите в сообщество в Telegram, где можно обсудить serverless в целом.

