В мае 2021 года меня похитили инопланетяне и приказали разработать сервис аналитики данных, в простонародье именуемый “self-service BI (business intelligence)”. И не просто какой-то аналог Redash или Superset в масштабе 1:43, а с нормальной поддержкой загрузки данных из файлов (локальных и через веб), ну и, конечно, с коннекторами к популярным базам данным. Например, чтобы можно было импортировать содержимое файлов json, xml или логов, а потом сджойнить их с выгрузкой из clickhouse. И ещё чтобы графики рисовались. Дашборды тоже было бы неплохо, но можно и без них.
Вот что они мне нарисовали в качестве ТЗ:

Ума не приложу, зачем им это, но как человек неконфликтный и легко внушаемый, я в итоге подчинился.
Первую неделю я, конечно, пытался сопротивляться, показывал им куски ранее написанного кода, пытаясь доказать, что я не настоящий программист. Также пробовал апеллировать к разуму, дескать, в одно лицо такое написать нереально (особенно, если ты — не настоящий программист).
Но переубедить их не удалось: меня просто ударили током и вернули домой.
Хотя, может, ничего этого и не было.

На следующее утро уже вовсю кипела работа: я собрал docker с nginx, php 7.4 и всякими тулзами и библиотеками, набросал спеку, нашёл неплохую js библиотеку apexcharts.js для визуализации (потому что красивая, бесплатная и хорошо умеет рендерить графики в svg).
Также вспомнил, что есть jquery datatables, перечитал по ней мануал и начал кодить сервис, не забывая, конечно, про пуши в гит. А примерно через два месяца у меня получился TABLUM.IO, который я потом ещё два раза переделывал и, как мне кажется, улучшал.

Снаружи — аскетичный, внутри — практичный. Этакий “швейцарский нож” для IT-человека.
Особенности сервиса
Если бы меня вдруг спросили, что в сервисе такого особенного, то я бы обратил внимание на три вещи.

Первая — это автодетект типов данных при импортировании данных из нетипизированных источников. Сервису не важно, это файл json, csv, Гугл-таблица или данные из clipboard. Каждая колонка таблицы получает свой тип на основе анализа данных в момент их загрузки во внутреннее хранилище, в результате чего у колонок в интерфейсе появляются свои функции агрегации, форматирования и сортировки.

Даже для данных из БД я не стал использовать типы, определённые в схемах таблиц, поэтому при выгрузке из clickhouse или postgres типы колонок тоже определяются динамически. Кстати, финансовые данные вида “12000 руб”, “$10,000.5”, “30,000,000 €” парсятся и сохраняются внутри в унифицированном формате с учётом валюты и разделителей разрядов.

Ожидая закономерный вопрос про перфоманс загрузки 1M+ записей в таблицу — всё ОК, работает быстро, тип данных определяется по первым 100 записям (в большинстве случаев этого достаточно, а для нестандартных случаев тип колонки можно будет назначить вручную).
Вторая особенность сервиса — генератор SQL-запросов для функций агрегации и оконных функций (это те, которые считают скользящее среднее, сумму с накопительным итогом и подобные штуки). Я постоянно забываю их синтаксис, поэтому, чтобы не лазить в Гугл, сделал автоматическую генерацию SQL-запроса в интерфейсе таблицы. Когда требуется что-то посчитать, я тыкаю мышкой по нужным столбцам, а оно само строит “трёхэтажный” SQL.
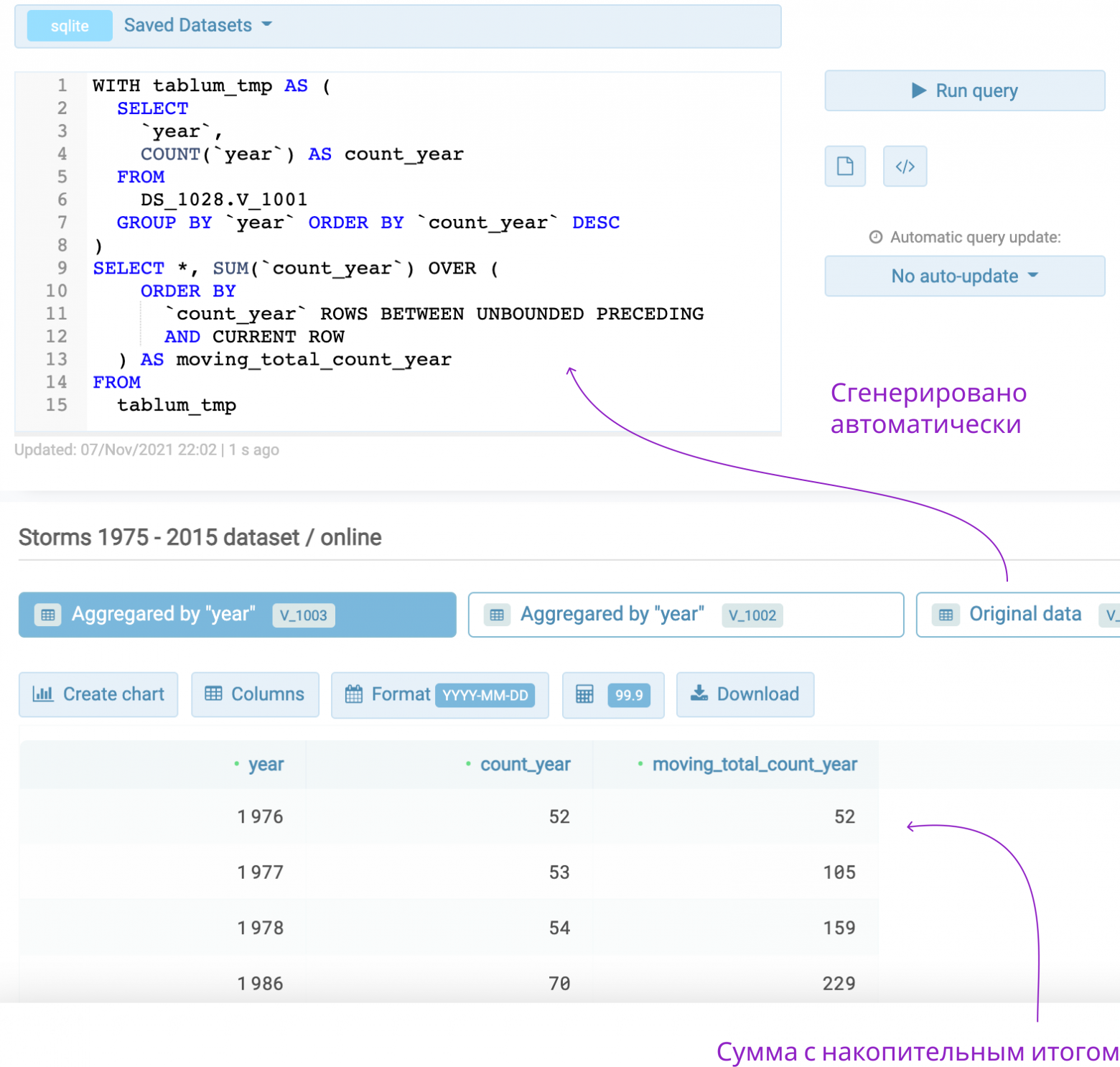
Аналогично с функциями агрегации: сервис сам группирует значения по столбцу с данными, причём это можно делать с различными временными интервалами (недели, месяцы, годы). Для этого ему нужно только указать, какие столбцы добавить в группировку и по какому столбцу выполнить агрегацию.
C оконными функциями можно вытворять разное, но мне чаще всего от них нужно сравнение значений с предыдущими в определённом временном интервале: можно сравнивать, например, посещаемость сайта в этом и прошлом году по месяцам, или активность аудитории сервиса текущей недели относительно предыдущей недели на протяжении года. Всё, естественно, одним SQL-запросом, который даже не нужно писать.

В TABLUM.IO такие штуки строятся примерно за 5 кликов мышью и 0 нажатий клавиш.

Третья особенность - это типографика таблиц. Наверняка большинство пользователей даже не обратят внимание на выравнивание данных в столбцах, всякие полупробельные разделители для разрядов и индикаторы типов данных. Главное — что им будет удобно считывать данные в таблице, где разряды под разрядами, соблюдён ink/data ratio, учитываются всякие правила близости и т. П. Но, как известно, нет предела совершенству, поэтому если у вас есть предложения, что можно улучшить - напишите.

Основные возможности
Кроме этого, конечно, в TABLUM.IO присутствует и классический для аналитических/BI-сервисов набор возможностей:
Загрузка данных из файлов в различных форматах: json, xml, odt, xlsx, csv, tsv, log и т. п. Формат файла определяется по внутренностям, расширению или mime-типу, в зависимости от того, как файл загружается. Файлы json и xml будут автоматически преобразованы из древовидного в табличный вид. Вроде как тоже интересная фича, которую я в других BI не встречал.
Загрузка данных из популярных БД: clickhouse, mysql, postgres. На самом деле их будет больше, как минимум все то, что поддерживается в ADOdb-библиотеке, но чуть позже.
Загрузка данных из GoogleSheet. Причём, в отличие от Redash, где можно вспотеть, пока для каждого файла выгрузишь авторизационный json, TABLUM прошёл верификацию у Гугла и GoogleSheet-коннектор требуется создать один раз для всех своих документов, а дальше просто указывать в запросе URL конкретного документа.
Отображение данных в табличном формате и в виде графиков.
Экспортирование данных в различных форматах: csv, html, sql, xml, json и др. Сервис можно использовать для конвертации данных, например, из json в дамп SQL для последующего импорта в БД.
Я решил пока не делать дашборды. Их нужно делать или хорошо, или не делать вообще, а то получится как у Redash (а хочется как у Tableau). Но в качестве некой компромиссной альтернативы сделал график с отправкой в Telegram или Slack. То есть можно настроить регулярную (раз в сутки, раз в неделю, и даже раз в 15 минут) выгрузку данных из БД, и последующий репортинг данных в виде графика в Telegram.

Приглашение потестировать
Статья была бы неполной, если бы не этот раздел ;)

С уверенностью могу сказать, что получаю нематериальный профит от работы в TABLUM.IO — он экономит мне время, ускоряя обработку данных. Можно с минимальными телодвижениями выбрать данные из clickhouse или postgres и построить по ним графики, вывести на графике статистику событий от датчиков с Raspberry PI, распарсить результат вызова REST API, сконвертировать xml в json, скоррелировать данные БД и GoogleSheet и выгрузить результат в json, нормализовать данные для нейронки, распарсить логи веб-сервера и посмотреть аномалии и т. п.
Всё это в некотором роде вдохновляет и обнадёживает. Поэтому, спустя несколько месяцев индивидуальной работы с данным инструментом, я решил, что “инопланетные технологии” должны стать достоянием общественности и сегодня робко представляю этот проект на всеобщее обозрение (в надежде, конечно, избежать участи Прометея и сохранить свою единственную печень в целости).
Входить можно с парадного входа (нужен аккаунт Google или Facebook). Про Хабраэффект я знаю и жду его с нетерпением. Хотя вроде как упасть не должно, но на всякий случай, если не будет открываться, просто зайдите попозже.
Инструкции по работе и всякие поясняющие диаграммы я разместил на одностраничнике.
Будет здорово, если вы найдёте время, чтобы поработать в TABLUM.IO некоторое время и дадите обратную связь по тому, что непонятно или неудобно, чего не хватает. Или, наоборот, что удобно и для каких задач вы его используете. Ну а следить за дальнейшей судьбой проекта можно в соответствующем канале.


