Статья написана по мотивам работы "Forecasting SQL Query Cost at Twitter", 2021 («Прогнозирование стоимости SQL-запросов в Twitter»), представленной на IX Международной конференции IEEE по облачной инженерии (IC2E). Подробностями делимся, пока у нас начинается курс по Machine Learning и Deep Learning.
Обзор
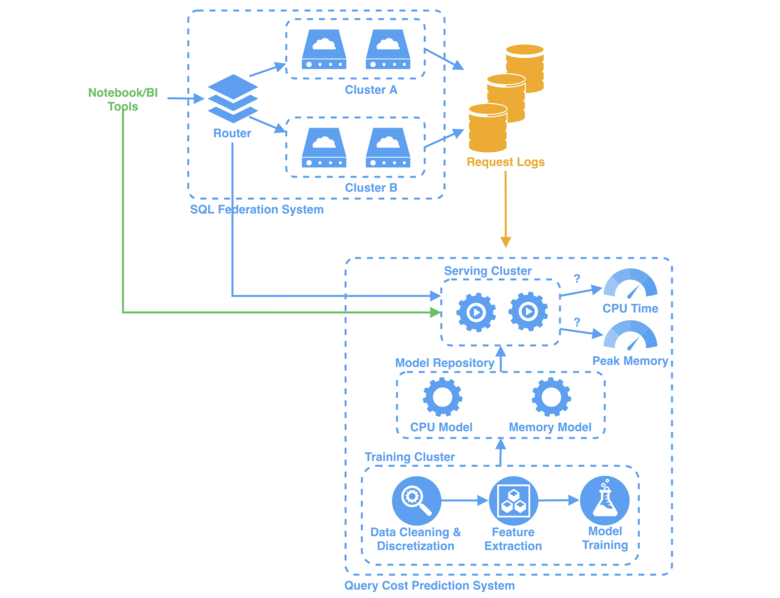
Команда Interactive Query в Twitter, откликаясь на растущую потребность в анализе данных петабайтного (Пб) масштаба, стремится достигнуть высокой масштабируемости и доступности. Чтобы решить проблемы с производительностью при разработке и обслуживании систем SQL с увеличивающимися объёмами данных, мы разработали крупномасштабную систему объединению SQL в необлачных и облачных кластерах Hadoop и Google Cloud Storage (GCS).
Сделано это с использованием Presto как центра кластеров SQL-движка. Система объединения SQL вместе с другими проектами под общим названием Partly Cloudy («Переменная облачность») идёт по пути демократизации анализа данных и повышения производительности в Twitter.
Во время работы этой SQL-системы мы обнаружили, что без прогнозирования использования ресурсов при выполнении SQL-запросов возникают необычные проблемы:
Планирование запросов требует оценки текущей рабочей нагрузки в системе SQL. Без должного планирования кластер может перегружаться: достаточно всего 10 секунд, чтобы ресурсоёмкие запросы легко заняли большую часть ресурсов кластера.
Клиенты систем обработки данных хотят знать оценку потребления ресурсов по их запросам. Если использование ресурсов, например процессорного времени, при выполнении запроса будет прогнозироваться, клиенты будут знать, сколько примерно ресурсов расходуют их запросы.
Для эластичного масштабирования требуется прогнозирование использования ресурсов при выполнении запросов. Из-за быстрого воздействия ресурсоёмких запросов система SQL должна масштабироваться до их обработки.
Чтобы прогнозировать использование ресурсов при выполнении запросов, в существующих подходах систем управления базами данных (СУБД) обычно используются планы запросов, генерируемые из движков SQL. Такие подходы ограничивали способность прогнозировать использование ресурсов для планирования запросов и приоритетного масштабирования, когда мы не использовали SQL-движки.
Теперь мы применяем методы машинного обучения для обучения двух моделей на данных логов прежних SQL-запросов, чтобы прогнозировать расход процессорного времени и пиковое использование памяти. В этой статье мы подробно расскажем о создании системы прогнозирования использования ресурсов при SQL-запросах в Twitter, основанной на ML.
Проектирование системы
В Twitter при каждом SQL-запросе, который обрабатывается системой объединения SQL, в логе запросов создаётся запись. Система прогнозирования стоимости запросов использует логи запросов в качестве исходного набора данных для обучения.
В каждом таком логе содержится связанная с запросом информация, в том числе уникальный идентификатор, имя пользователя, среда и инструкция запроса. Согласно нашим экспериментам, логи за последние три месяца (90 дней) — хороший показатель для прогнозирования стоимости онлайн-запросов. Типичный набор данных состоит примерно из 1,2 млн. записей и более 20 признаков.

Тренировочный кластер выполняет вычисления с применением машинного обучения. Чтобы прогнозировать расход процессорного времени и пиковое использование памяти, мы обучаем две модели ML — модель процессора и модель памяти — на данных логов прежних запросов. В учебном кластере выполняется:
Очистка данных и дискретизация в исходный набор, преобразование непрерывного процессорного времени и пиковой памяти в сегменты.
Применение методов векторизации для извлечения признаков из необработанных инструкций SQL.
Обучение моделей с помощью алгоритмов классификации.
В репозитории мы управляем обученными моделями, которые хранятся в центральном хранилище, например GCS. В обслуживающем кластере модели извлекаются из хранилища и помещаются в веб-сервис прогнозирования.
В этом процессе для внешних запросов предоставляются конечные точки RESTful API, которые используются, чтобы прогнозировать расход процессорного времени и пиковое использования памяти для онлайн-запросов SQL из инструментов Notebook/BI (так клиенты получают оценку расходования ресурсов при выполнении запросов) и маршрутизатора (для планирования запросов и приоритетного масштабирования).
Конвейер ML
В предыдущих статистических подходах для решения проблем СУБД применялись методы регрессии, такие как анализ временных рядов. Но распределение расходования ресурсов при выполнении SQL-запросов имеет экспоненциальный характер, поэтому традиционные регрессионные подходы сложно использовать из-за больших колебаний в хвосте распределения.
А ещё мы заметили, что быстрые оценки потребления ресурсов, планирования и масштабирования не требуют точного прогнозного значения для клиентов и маршрутизатора. Нужно лишь знать, какова ресурсоёмкость запроса: низкая, средняя или высокая. Для этого мы применяем дискретизацию в исходный набор данных, преобразуя непрерывные данные в дискретные.
Очистка и дискретизация данных
Как мы группируем эти запросы? Сначала выбираем пороговые значения для интенсивного использования процессора и памяти — 5 часов и 1 ТБ соответственно. Эти значения применялись в системе объединения SQL раньше, исходя из нашего опыта работы (в том числе DevOps) при выполнении аналитических запросов.
На основе опыта DevOps запросы, процессорное время которых менее 30 с, считаем легковесными. Это помогает охватить большую часть запросов в диапазоне [0, 30 с), т. е. более 70 % общего их числа. И лишь 1 % запросов попадает в диапазон [30 , 60 с].
Распределение пикового использования памяти более равномерное: как результат мы обычно распределяем по категориям запросы с пиковой памятью меньше 1 ТБ, а 1 МБ выбираем как границу запросов с низким и средним расходом памяти.
Ниже категории распределения:
процессорное время в трёх диапазонах: [0, 30 с), [30 с, 5 ч), [5 ч);
пиковое расходование памяти в трёх диапазонах: [0, 1 Мб), [1 Мб, 1 ТБ), [1 ТБ).
Преобразовав набор данных, разделяем его на данные для обучения (80% запросов) и тестовые данные (20% запросов).

")
Извлечение признаков
Чтобы создавать необходимые признаки для преобразованного набора данных с категориями пиковой памяти и процессорного времени, мы применяем методы векторизации из обработки естественного языка (NLP). Каждая SQL-инструкция сопоставляется с вектором чисел для последующей обработки с использованием векторизации. Это облегчает выполнение алгоритмов классификации текстовых данных.
Мы используем модели «мешка слов», в которых каждое слово представлено числом, так что последовательность чисел может представлять SQL-инструкцию. Типичное представление — частотность слов. Чтобы создавать признаки, мы также используем популярное представление значений частотности термина, обратной частоты документа (TF-IDF).
Модели «мешка слов» обладают большой гибкостью, могут быть обобщены на различные области текстовых данных и дают признаки без вычислений в SQL-движке и без взаимодействия с хранилищем метаданных. Мы не используем табличную статистику для разработки признаков: этот тип данных требует дополнительных затрат на анализ SQL-инструкций и извлечение метаданных таблиц.
Мы также заметили, что древовидные алгоритмы машинного обучения, например XGBoost, легко определяющие важность признаков, могут включать связанные с SQL признаки, такие как доступ к определённым таблицам и использование временных диапазонов. Эти признаки обычно используются в традиционных плановых моделях стоимости запросов. Иными словами, методы машинного обучения могут помочь разработчикам в изучении крупномасштабных систем SQL.
Обучение и оценка моделей
Подготовив извлеченные из TF-IDF признаки, используем древовидный алгоритм градиентного подъёма XGBoost, чтобы обучить классификаторы из обучающего набора данных. Чтобы найти оптимальные гиперпараметры, используется 3-проходная перекрёстная проверка. Затем тестируем обученные классификаторы на тестовом наборе данных. Модель процессора достигает точности 97,9 %, а модель памяти — 97,0 %.
Точность — один из популярных показателей оценки производительности модели, но не единственный. Учитывая несбалансированные классы в наборе данных для обучения, высокая общая точность не всегда указывает на высокую способность прогнозирования всех классов. За высокой точностью определения класса, содержащего большое количество образцов, может скрываться низкая точность прогнозирования классов с меньшим количеством образцов.
Чтобы решить возможную проблему, мы учитываем точность и отклик каждого класса, а особенно классов, представляющих запросы с интенсивным расходом ресурсов процессора или памяти. В приведённых ниже таблицах наши модели достигают высокой точности и отклика для всех классов, а также высокой общей точности. В частности, дают не менее 0,95 точности и отклика для ресурсоёмких запросов: [5 часов) и [1 ТБ).
")
")
Обслуживание моделей
Обучив и протестировав модели, помещаем их в веб-приложение для обслуживания трафика на продакшене в режиме реального времени. Сервис в обслуживающем кластере развёрнут в контейнерах Aurora на широко применяемом в Twitter инструменте Mesos.
Каждая единица развёртывания не имеет состояния, поэтому масштабируемость приложения может быть повышена за счёт увеличения числа реплик развёртывания. Чтобы прогнозировать расход процессорного времени и пиковое использование памяти при выполнении SQL-запроса, сервис предоставляет две конечные точки RESTful API. Время вывода составляет около 200 миллисекунд.
Заключение
Благодаря методам машинного обучения мы разработали систему прогнозирования стоимости SQL-запросов, позволяющую с точностью более 97 % прогнозировать расход процессорного времени и пиковое использование памяти при выполнении SQL-запросов.
В отличие от других система учится на простых SQL-инструкциях и создаёт модели машинного обучения на данных логов прежних SQL-запросов, не зависит ни от каких SQL-движков или планов запросов. Мы считаем, что описанный в статье подход может дать инновационное решение в смысле оптимизации производительности, связанной с традиционной инфраструктурой.
А научиться решать проблемы бизнеса с помощью ML вы сможете на наших курсах:

Узнайте подробности акции.
Другие профессии и курсы
Data Science и Machine Learning
Python, веб-разработка
Мобильная разработка
Java и C#
От основ — в глубину
А также

