В современных веб-приложениях большинство запросов к базе данных пишется не на сыром SQL, а с использованием объектно-реляционного отображения (ORM). Оно автоматически генерирует SQL-запросы по привычному объектно-ориентированному коду. Однако эти запросы не всегда оптимальны, и с ростом нагрузки на веб-приложение встает вопрос их оптимизации. Как раз в ходе такой оптимизации наша команда обнаружила, что документация Django с нами не совсем честна.
Меня зовут Альбина Альмухаметова, я python разработчица в Технократии. О вводящей в заблуждение документации Django я рассказывала на Pycon в этом году. Этот текст — адаптация моего выступления для тех, кто слишком занят, чтобы смотреть видео. В качестве бонуса я добавила пару примеров, которых нет видео-докладе, но которые любезно предложили наши зрители. Так что, если вы смотрели доклад, смело листайте к заголовку “Заметки с доклада” и изучайте новые сравнения индексов.
Но если вам интересно посмотреть, как я выступала на Pycon, то вот запись:
Также перед стартом хочу послать благодарность Павлу Гаркину, который первый из нашей команды обнаружил описанные ниже особенности и предложил способ их решения. Теперь поехали.
Содержание:
Проблема
Функция поиска на сайте — привычно и удобно, но лишь до тех пор, пока поиск быстрый. В нашем случае проблемы возникли в поисковой строке Django-админки. Если вы хоть раз пытались поменять запросы, которые делает Django для отображения страниц админки, вы знаете, что это очень больно.
Ситуацию получили следующую:
пользователи долго ждут загрузки страницы и не могут с нее уйти (ответ получить надо, а альтернатив нет)
разработчики не могут переписать запрос, чтобы его ускорить
Чтобы все спасти, решили вешать индексы на таблицы. И тут началось самое интересное.
Важное замечание: в докладе речь идет про Django 2.2 в связке с PostgreSQL. За время составления доклада и написания статьи вышла Django 3.2 со значительными улучшениями, которые играют роль в контексте данного доклада. В конце мы разберем, что же такого поменялось и как будет выглядеть код в обновленной версии.
Подсчет исходных данных
Note: Для упрощения кода и соблюдения NDA в качестве примера используем поиск по полю name, что в целом не меняет сущности проблемы.
Код модели:
class Person(models.Model): name = models.CharField(max_length=100) address = models.CharField(max_length=100) status = models.CharField(max_length=100)
В интересующих нас запросах участвовали следующие lookup’ы:
__exact
__iexact
__contains
__icontains
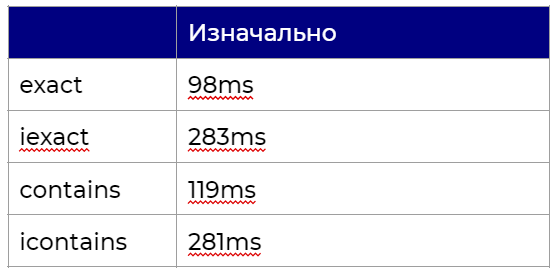
Первое, что мы сделали, — перевели запросы из ORM в сырой SQL и посмотрели, как и сколько они выполняются. Для статьи в качестве примера в таблицу добавили 1 000 000 записей и запустили запрос несколько раз.
__exact повел себя ожидаемым образом и дал результаты на картинке ниже:
>>> str(Person.objects.filter(name__exact='test').query) SELECT "names_person"."id", "names_person"."name", "names_person"."address", "names_person"."status" FROM "names_person" WHERE "names_person"."name" = test

А вот __iexact удивил. Дело в том, что в документации Django явно указано, что будет генерироваться следующий SQL запрос:
>>> qs.filter(first_name__iexact='олег') SELECT ... WHERE first_name ILIKE '%олег%';
Однако реальность в случае с PostgreSQL оказалась иной:
>>> str(Person.objects.filter(name__iexact='test').query) SELECT "names_person"."id", "names_person"."name", "names_person"."address", "names_person"."status" FROM "names_person" WHERE UPPER("names_person"."name"::text) = UPPER(test)

Аналогичная магия произошла с __contains и __icontains: __contains ведет себя нормально и выдает ожидаемые результаты:
>>> str(Person.objects.filter(name__contains='test').query) SELECT "names_person"."id", "names_person"."name", "names_person"."address", "names_person"."status" FROM "names_person" WHERE "names_person"."name"::text LIKE %test%

А __icontains тоже использует UPPER, вместо обещанного ILIKE
>>> str(Person.objects.filter(name__icontains='test').query) SELECT "names_person"."id", "names_person"."name", "names_person"."address", "names_person"."status" FROM "names_person" WHERE UPPER("names_person"."name"::text) LIKE UPPER(%test%)

Итого:
Попытка №1 - db_index=True
Можно было бы занять этим делом специально обученных людей DBA: попросить покопаться в производительности, построить индексы вручную под конкретные задачи, но:
придется помнить, что в базе есть индексы, которые не зафиксированы в коде
мы программисты, нам надо все автоматизировать
Поэтому решили вешать индексы через Django. В первую итерацию постаили db_index=True на нашу колонку.
Спойлер
class Person(models.Model): name = models.CharField(max_length=100, db_index=True) address = models.CharField(max_length=100) status = models.CharField(max_length=100)
После этого снова сделали замеры и получили следующее:

Из всех наших запросов индекс использовал только оператор __exact. Это становится очевидно, если заглянуть в код миграции, которую генерирует Django:
BEGIN; -- -- Alter field name on person -- CREATE INDEX "names_person_name_f55af680" ON "names_person" ("name"); CREATE INDEX "names_person_name_f55af680_like" ON "names_person" ("name" varchar_pattern_ops); COMMIT;
Здесь используется B-Tree индекс (т.к. по умолчанию в PostgreSQl берется именно он), а по документации этот индекс будет использоваться только в операторах сравнения
B-trees can handle equality and range queries on data that can be sorted into some ordering. In particular, the PostgreSQL query planner will consider using a B-tree index whenever an indexed column is involved in a comparison using one of these operators:
< , <= , = , >= , >
<...>
The optimizer can also use a B-tree index for queries involving the pattern matching operators LIKE and ~ if the pattern is a constant and is anchored to the beginning of the string — for example, col LIKE 'foo%' or col ~ '^foo', but not col LIKE '%bar'.
Здесь стоит также отдельно остановиться на ключевом слове “varchar_pattern_ops”, поскольку оно нам еще понадобится. Это так называемый op_class или operator class. Он определяет особые правила использования индекса. В данном случае, например, при использовании нестандартной С-локали и сравнении строк по паттерну (LIKE и ~) будет происходить посимвольное сравнение, а не принятое в локали. Подробнее можно почитать тут: https://www.postgresql.org/docs/9.5/indexes-opclass.html
Попытка №2 – свой индекс
Во второй итерации, осознав, что __iexact в целом тоже можно покрыть B-tree индексом, если повесить его на выражение UPPER(“name”), мы пошли искать, как это провернуть средствами Django. Ответ оказался прозаичным — никак. В документации есть описание класса Index, сокращенной версией которого является атрибут db_index, но все, что о нем известно, это описание 5 ключевых атрибутов.
Недолго подумав, мы полезли на github (спасибо открытым исходникам), нашли там класс Index и в нем метод create_sql, который судя по названию должен генерировать SQL-выражение самого индекса. Подробно о пути до конечной цели мы рассказываем в докладе, здесь оставим краткую выдержку:
Пишем наследника от Index, переопределяем в нем create_sql и ставим точку дебага в этом месте. Дальше запускаем выполнение миграции и смотрим, что получается.
class UpperIndex(Index): def create_sql(self, model, schema_editor, using='', **kwargs): statement = super().create_sql( model, schema_editor, using, **kwargs ) return statement class Person(models.Model): name = models.CharField(max_length=100, db_index=True) address = models.CharField(max_length=100) status = models.CharField(max_length=100) class Meta: indexes = [ UpperIndex(fields=['name'], name='name_upper_index') ]
В возвращаемом statement находим шаблон SQL-выражения и словарь parts, ключ columns которого подставится в этот шаблон как название колонки.

Находим исходники Columns на github и смотрим, как генерируется название колонки (метод __str__)
def __str__(self): def col_str(column, idx): try: return self.quote_name(column) + self.col_suffixes[idx] except IndexError: return self.quote_name(column) return ', '.join(col_str(column, idx) for idx, column in enumerate(self.columns))
Понимаем, что название оборачивается в метод self.quote_name и переопределяем его на свой — главное не напутать: метод quote_name — это метод column, соответственно, переопределять его надо у statement.parts[‘columns’]
class UpperIndex(Index): def create_sql(self, model, schema_editor, using='', **kwargs): statement = super().create_sql( model, schema_editor, using, **kwargs ) quote_name = statement.parts['columns'].quote_name def upper_quoted(column): return 'UPPER({0})'.format(quote_name(column)) statement.parts['columns'].quote_name = upper_quoted return statement
После этого запрос с __iexact начинает использовать индекс и показывать прирост по скорости


Попытка №3 — Trigram
Разобравшись с __exact и __iexact, остался вопрос, что делать с запросами на __contains и __icontains, потому что они используют LIKE, а с ним B-tree индекс не поможет. Покопавшись в документации PostgreSQL и возможных вариантов индекса, стало понятно, что ни один из индексов из коробки нам не поможет. Но многие индексы работают через те самые op_classes, о которых мы говорили выше, и нашлось расширение Trigram, которое предоставляет классы для GiST и Gin индексов специально под LIKE и ILIKE операторы.
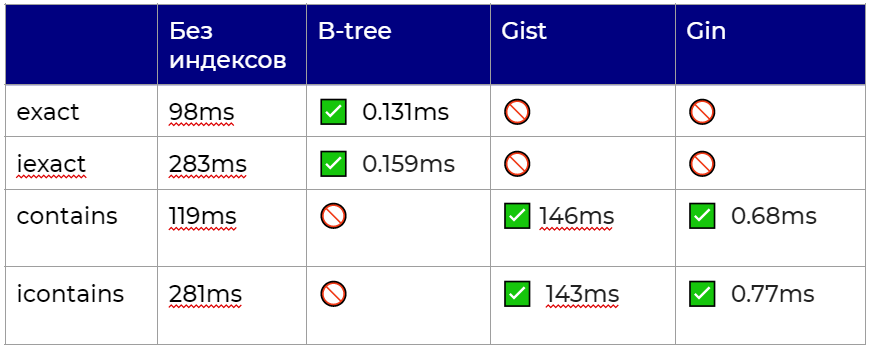
Мы попробовали оба индекса и получили следующее:
на проде GiST показал значительный прирост, а на синтетических данных (тот самый 1 000 000 из начала статьи) прироста в скорости нет
Gin показал прирост в производительности и на проде, и на синтетике, что в целом и понятно — он заточен под работу с текстом
Результаты замеров:
Gist __contains

Gist __icontains

Gin __contains

Gin __icontains

Итоговая таблица у нас получаются следующая (галочку мы ставим за использование индекса):
Как пользоваться?
Для __contains добавляем GinIndex к нашей модели и указываем gin_trgm_op
from django.contrib.postgres.indexes import GinIndex class Person(models.Model): name = models.CharField(max_length=100, db_index=True) address = models.CharField(max_length=100) status = models.CharField(max_length=100) class Meta: indexes = [ GinIndex(fields=['name'], name='name_gin_index', opclasses=['gin_trgm_ops']) ]
Для __icontains берем наш самописный класс, меняем родителя на GinIndex и подключаем, не забыв указать gin_trgm_op
class UpperGistIndex(GinIndex): def create_sql(self, model, schema_editor, using='', **kwargs): statement = super().create_sql( model, schema_editor, using, **kwargs ) quote_name = statement.parts['columns'].quote_name def upper_quoted(column): return 'UPPER({0})'.format(quote_name(column)) statement.parts['columns'].quote_name = upper_quoted return statement
Важно т.к. Trigram — это расширение для PostgreSQL, по умолчанию оно выключено и его надо включить. Для этого ДО того, как в миграциях появятся индексы c 'gin_trgm_ops' нужно вызвать класс TrigramExtension(). Например, это можно сделать в миграции, которая сгенерируется при добавлении индексов
from django.contrib.postgres.operations import TrigramExtension class Migration(migrations.Migration): dependencies = [ ('users', '0001__initial'), ] operations = [ TrigramExtension(), # тут добавление ваших индексов ]
Итоговая модель с индексами
class UpperIndex(Index): def create_sql(self, model, schema_editor, using='', **kwargs): statement = super().create_sql( model, schema_editor, using, **kwargs ) quote_name = statement.parts['columns'].quote_name def upper_quoted(column): return 'UPPER({0})'.format(quote_name(column)) statement.parts['columns'].quote_name = upper_quoted return statement class UpperGinIndex(GinIndex): def create_sql(self, model, schema_editor, using='', **kwargs): statement = super().create_sql( model, schema_editor, using, **kwargs ) quote_name = statement.parts['columns'].quote_name def upper_quoted(column): return 'UPPER({0})'.format(quote_name(column)) statement.parts['columns'].quote_name = upper_quoted return statement class Person(models.Model): name = models.CharField(max_length=100, db_index=True) address = models.CharField(max_length=100) status = models.CharField(max_length=100) class Meta: indexes = [ UpperIndex(fields=['name'], name='name_upper_index'), GinIndex(fields=['name'], name='name_gin_index', opclasses=['gin_trgm_ops']), UpperGinIndex(fields=['name'], name='name_gin_upper_index', opclasses=['gin_trgm_ops']), ]
Django 3.2
Если вы уже обновились, для вас приятные новости: в 3.2 ввели синтаксис expressions в индексах, и больше не нужно писать свои классы, модель будет выглядеть вот так:
class Person(models.Model): name = models.CharField(max_length=100, db_index=True) address = models.CharField(max_length=100) status = models.CharField(max_length=100) class Meta: indexes = [ Index(Upper('name'), name='name_upper_index'), GinIndex(fields=['name'], name='name_gin_index', opclasses=['gin_trgm_ops']), GinIndex(OpClass(Upper('name'), name='gin_trgm_ops'), name='name_upper_gin_index'), ]
Заметки после доклада
После доклада нам подкинули идею проверить еще Hash и Rum индексы.
Hash
Hash индекс будет работать только с “=”, поэтому повесим его в нашу колонку вместо B-Tree и посчитаем за сколько отработает запрос
Подсказка о том, как это подключить
Hash не входит в стандартную поставку Django индексов и как и Gist и Gin находится в пакете для postgres, поэтому код модели будет выглядеть как-то так
from django.contrib.postgres.indexes import HashIndex from django.db import models class Person(models.Model): name = models.CharField(max_length=100) address = models.CharField(max_length=100) status = models.CharField(max_length=100) class Meta: indexes = [ HashIndex(fields=['name'], name='name_hash_index'), UpperIndex(fields=['name'], name='name_upper_hash_index') ]
__exact

__iexact

Rum
А вот с Rum индексом все немного сложнее:
Rum поставляется только в PostgresPro Enterprise, а мы используем базовую версию.
Намеков на Rum в документации Django не найдено, а значит весь код по подключению extension и настройке индексов придется писать вручную. В принципе не проблема, но не очень приятно
И самое важное: Rum заточен под сложные поисковые запросы и, хоть он и предполагается как улучшение Gin, с оператором LIKE Rum-индекс не работает, а значит наши запросы придется переписывать.
Подведем итоги:

Также подписывайтесь на наш телеграм-канал «Голос Технократии». Каждое утро мы публикуем новостной дайджест из мира ИТ, а по вечерам делимся интересными и полезными мастридами.

