Привет, Хаброжители! Обратите внимание на большую распродажу в честь Старого Нового года.
Когда виртуальная машина Java компилирует ваш исходный код Java в машинный, одна из задач, которые она должна при этом выполнить – решить, где хранить локальные переменные Java и другие подобные временные значения. В вашей машине отсутствует концепция локальных переменных, поэтому на этапе компиляции необходимо определиться, какое место в памяти стека (какой машинный регистр) будет использоваться для хранения каждой переменной. Эта операция называется «выделение регистров». Может показаться, что выделение регистров – сложная абстрактная теоретическая тема, но в этом коротком посте я покажу, как сначала соотнести исходный код Java с теорией, потом понять, как его видит компилятор, а потом – показать результирующий машинный код. В данном случае моя цель – продемонстрировать, что все эти концепции очень легко опробовать на практике с реальным компилятором.
Я покажу вывод динамического компилятора Graal, но концептуально все точно так же устроено и в других инструментах для динамической и опережающей компиляции Java, а также в компиляторах для многих других языков.
Чтобы инициировать компиляцию, этот код Java циклически выполняет метод test. Есть метод read для выдачи значений, метод write для их потребления, а также метод barrier, упрощающий некоторые вещи – об этом я расскажу в заключении поста.
class Test { public static void main(String[] args) { while (true) { test(); } } private static void test() { int v0 = read(); barrier(); int v1 = read(); barrier(); write(v0); barrier(); int v2 = read(); barrier(); int v3 = read(); barrier(); write(v1); barrier(); write(v2); barrier(); write(v3); } private static int read() { return 14; } private static void write(int value) { } private static void barrier() { } }
Рассмотрим выделение регистров в методе test. Для простоты я удалил вызовы метода barrier, стоявшие после каждой из строк.
int v0 = read(); int v1 = read(); write(v0); int v2 = read(); int v3 = read(); write(v1); write(v2); write(v3);
Можно составить впечатление о выделении регистров для этой программы, просто взглянув на код Java. Нужно подумать о том, как долго должна храниться каждая переменная. Этот феномен называется «пределами жизни» или «интервалом жизни» (live range). Эту задачу можно выразить в виде таблицы, где каждая строка кода войдет в строку с планкой, демонстрирующей, как долго нужно хранить переменную до тех пор, пока о ней можно будет забыть.

Здесь важнее всего отметить, что у нас четыре переменных, которые необходимо держать «в живых», но представляется, что мы сможем вместить их всего в три участка памяти. Посмотрите: планки v0 и v2 никогда не пересекаются. v0 можно отбросить еще до того, как будет создана v2, поэтому позже мы сможем использовать для v2 то место, которое осталось от v0. В качестве альтернативы мы могли бы совместно использовать хранилище для v0 и v3, но давайте придерживаться подхода первого подходящего и переиспользовать в качестве хранилища первый же освободившийся участок.

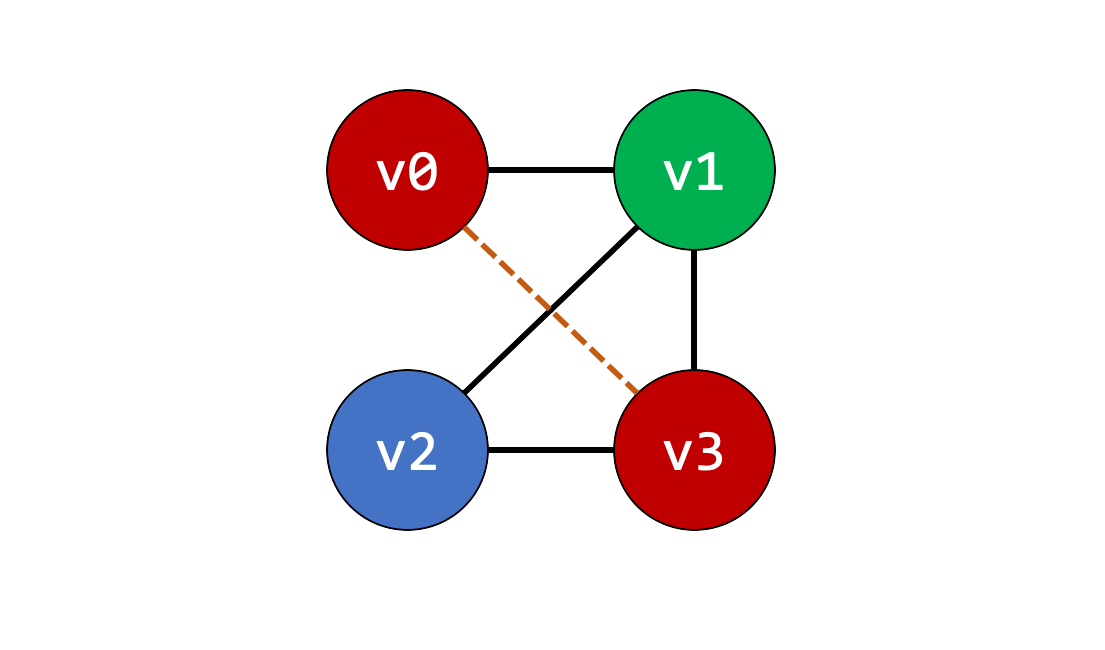
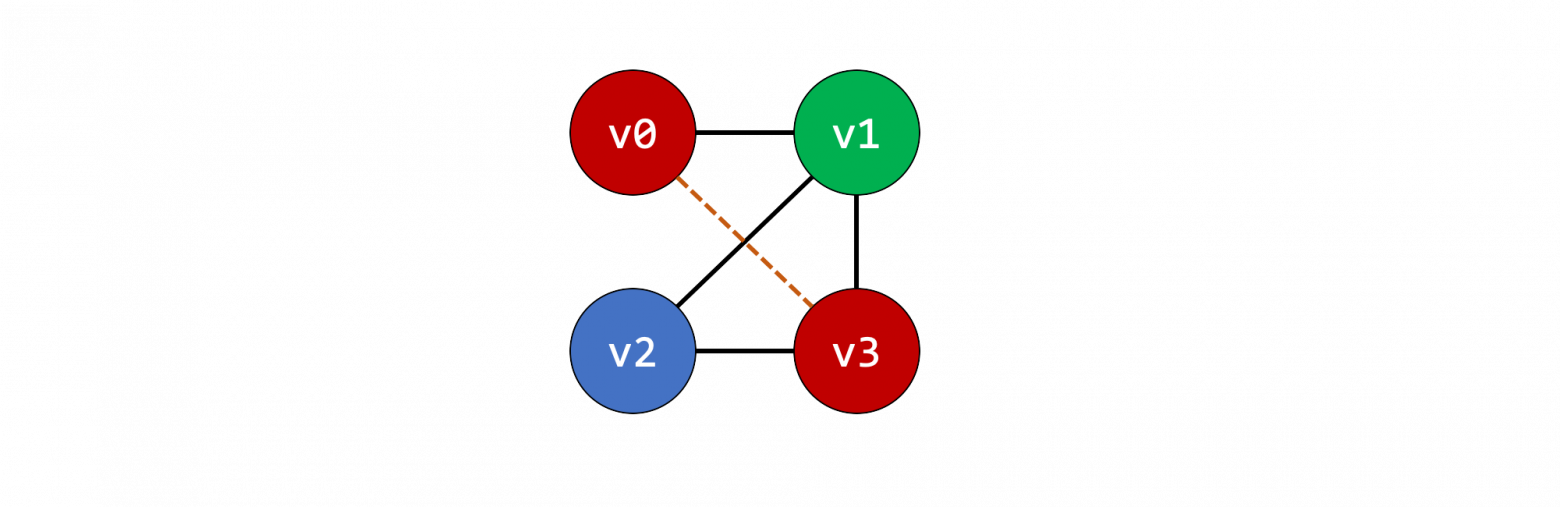
Более формальный подход к выделению регистров – построить граф, где каждая переменная соответствует узлу, и между узлами существуют ребра, если совпадает время жизни обозначаемых ими переменных. Это граф несовместимости (interference graph).
Затем решаем задачу раскраски каждого узла, так, чтобы никакие смежные узлы не были одного цвета. Это раскраска графа. Мы могли бы решить задачу, присвоив каждому из узлов свой уникальный цвет, но уже известно, что это напрасная трата ресурсов.
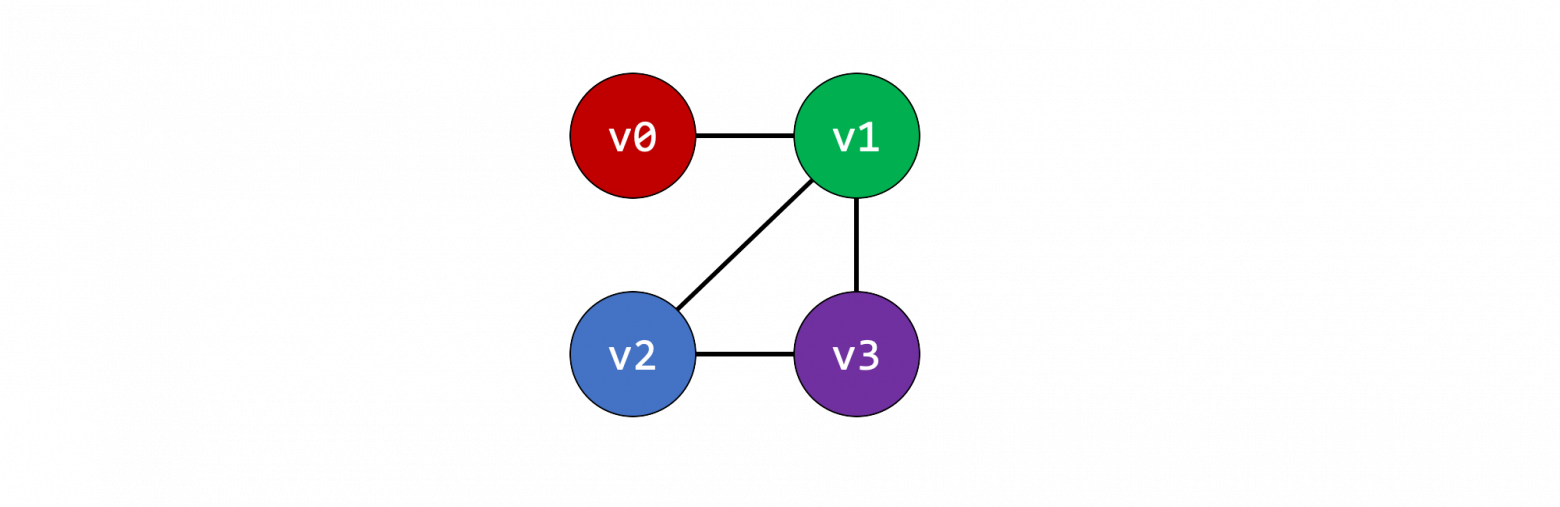
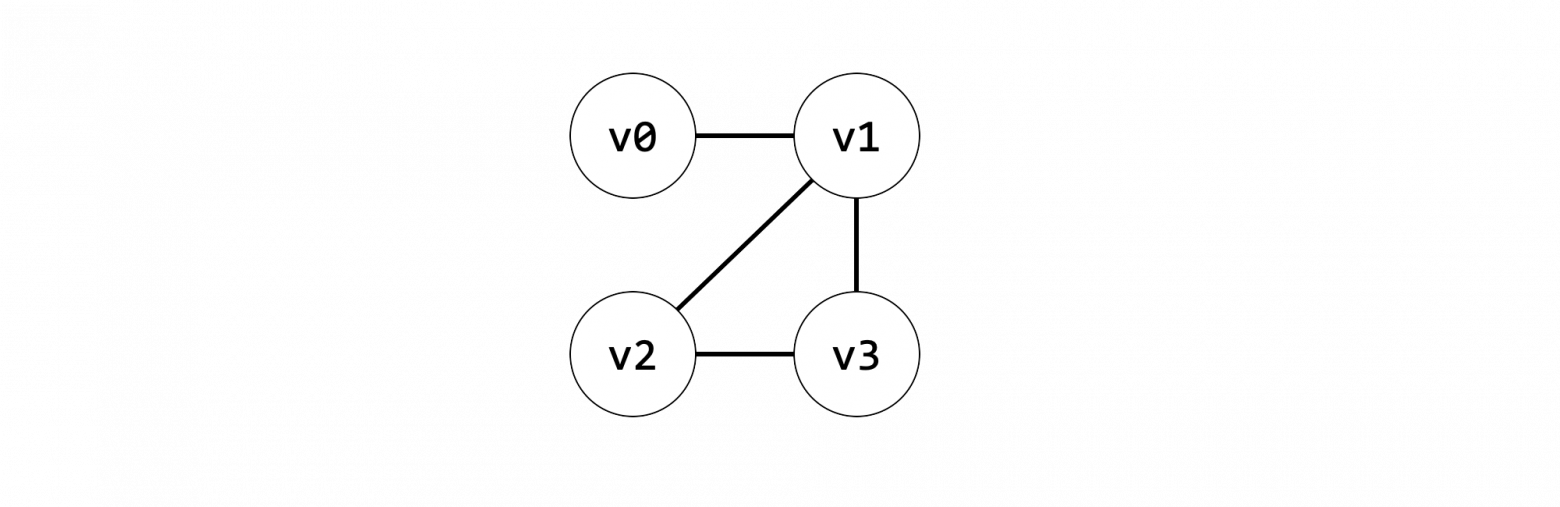
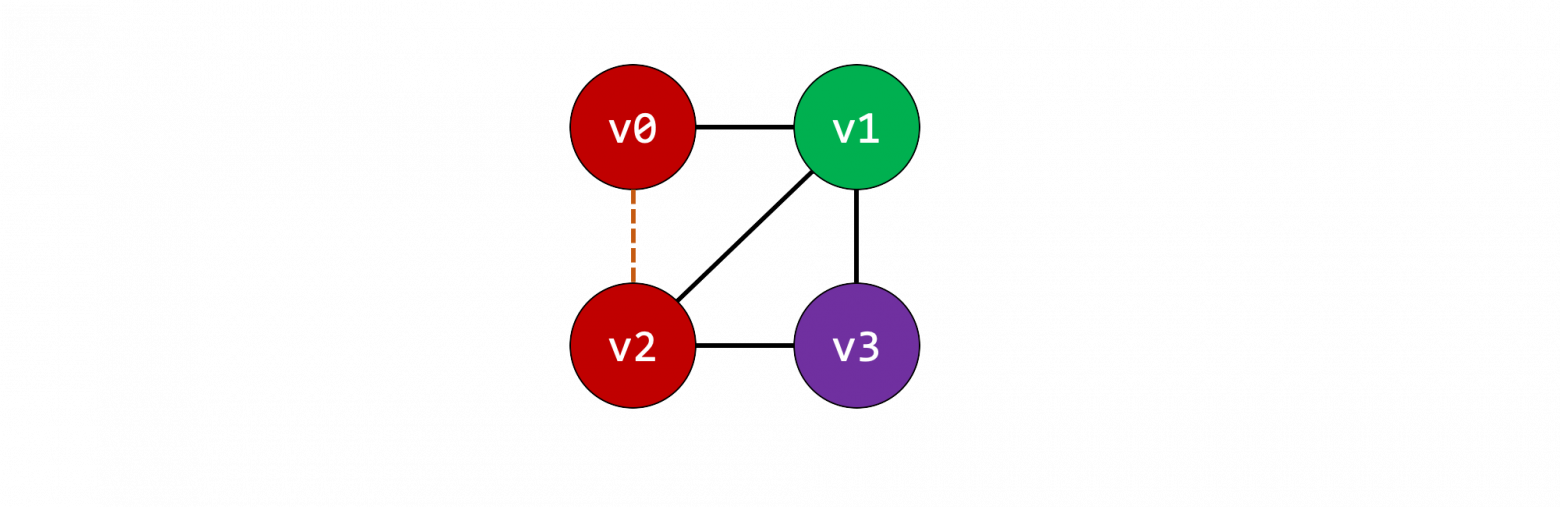
Давайте рассмотрим два уже имеющихся решения.
Чтобы рассмотреть на практике, как в Java выделяется память, можно воспользоваться GraalVM CE 20.1 Java 8, чтобы скомпилировать код Java в обычном порядке.
% ./graalvm-ce-java8-20.1.0/Contents/Home/bin/javac Test.java
Затем можно выполнить этот код, установив несколько флагов, чтобы посмотреть, что с кодом при этом происходит. Мы применим -XX:CompileOnly=Test::test, так, чтобы вызовы read, write и barrier не встраивались в строку. Если бы это, напротив, происходило, это позволило бы компилятору существенно переструктурировать программу, и интересующие нас вещи стали бы менее заметными. Применим -Dgraal.Dump=:3, чтобы записать, как компилятор понимает программу – запишем это в файл, который сможем изучить позже. Мы воспользуемся -XX:+UnlockDiagnosticVMOptions -XX:+PrintAssembly, чтобы вывести результирующий машинный код на ассемблере. Чтобы выполнить это, нам потребуется hsdis в текущем каталоге.
% ./graalvm-ce-java8-20.1.0/Contents/Home/bin/java -XX:CompileOnly=Test::test -Dgraal.Dump=:3 -XX:+UnlockDiagnosticVMOptions -XX:+PrintAssembly Test
Теперь воспользуемся инструментом, который называется c1visualizer. Этот инструмент показывает, как компилятор понимает вашу программу на бекенде, когда генерирует код и выделяет в памяти участки для хранения переменных.
% jdkhome=./graalvm-ce-java8-20.1.0/Contents/Home ./c1visualizer/bin/c1visualizer
Слева показано, как программа проходит различные этапы компиляции на бекенде.

В Before stack slot allocation (До выделения ячейки в стеке) могут стоять значения от v0 до v3. В таком представлении переменные – это ряды, и теперь каждый столбец содержит инструкцию байт-кода в методе Java, то есть, представление повернуто на 90 градусов. То же самое прослеживается и в интервалах, которые были у нас в исходном коде.

Если посмотреть «After stack slot allocation» (После выделения ячейки в стеке), то видны участки, выделенные в машинном стеке для этих переменных. Числа означают сдвиг от начала кадра в стеке. Они не увеличиваются на четыре на каждом шаге, поскольку это байтовые адреса, а мы сохраняем int Java, в котором четыре байта. Также они не начинаются с нуля, так как Java хранит в стеке наряду с переменными еще некоторую информацию. Также видим, что в схеме отражено то, что мы уже получили на кончике пера: переменные v0 и v2 хранятся в одном и том же участке стека, а именно stack:28.

Наконец, можно рассмотреть дизассемблированный машинный код, сгенерированный компилятором. Для ясности я немного упростил его; по-прежнему обходимся без вызовов к barrier. Всякий раз при вызове read код возвращает значение в регистре %eax, так что, например, инструкция mov %eax,0x14(%rsp) сохраняет возвращаемое значение в 0x14(%rsp), что иначе записывается как %rsp + 0x14. %rsp – это указатель стека, поэтому местоположения в стеке адресуются относительно нижнего края актуального стека (нижнего – поскольку он растет вниз).
sub $0x28,%rsp mov %rbp,0x20(%rsp) callq read mov %eax,0x14(%rsp) callq read mov %eax,0x10(%rsp) mov 0x14(%rsp),%esi callq write callq read mov %eax,0x14(%rsp) callq read mov %eax,0xc(%rsp) mov 0x10(%rsp),%esi callq write mov 0x14(%rsp),%esi callq write mov 0xc(%rsp),%esi callq write mov 0x20(%rsp),%rbp add $0x28,%rsp
Опять же, видим, что у первого и третьего вызова к read – то есть, у v0 и v2 - значение сохраняется в одном и том же месте - 0x14(%rsp). v1 идет в 0x10(%rsp), а v3 в 0xc(%rsp). Для этого машинного кода можем нарисовать такую же таблицу, как и сделали для кода Java.

Суть вышесказанного в том, что на практике все эти схемы соответствуют друг другу! Наши теоретические рассуждения о коде Java вместе с таблицами и графами несовместимости не сложнее экзаменационных задач, и они соответствуют тому, как именно понимается компилятором, производится и выполняется машинный код. Мы непосредственно видим, как наша теория подтверждается на практике.
Замечания
Мы поговорили о переменных, выделяемых в те или иные хранилища. В данном случае под переменной понимается любая информация, которую компилятору «вздумается» сохранить – такие переменные могут и не соответствовать каким-либо реальным локальным переменным, причем, не каждая локальная переменная обязательно будет сохранена.
Сначала мы стали говорить о выделении регистров, но потом обобщили тему до нахождения участков для хранения, а в конце статьи компилятор работал только со стеком, но не с регистрами. Причина в том, что на интервал жизни переменной приходится несколько вызовов, а внутренние соглашения по поводу вызовов, действующие в HotSpot, не предусматривают никаких регистров, сохраняемых на стороне вызываемого узла; вызывающий узел должен обеспечить, чтобы все значения были извлечены из регистров и сохранены в стеке.
Вызов barrier нужен потому, что без него интервалы жизни иногда немного сужаются, и поэтому не перекрываются друг с другом так, как мы хотели бы. Мы отключили встраивание в строку, чтобы вызов barrier срабатывал так, как нужно.
Для выделения регистров как такового Graal использует алгоритм линейного поиска.
Если вы заметили, что расположения в стеке, демонстрируемые визуализатором c1visualizer, не совпадают со сдвигами в машинном коде, то дело в том, что подсчет идет в разном направлении, а c1visualizer также учитывает возвращаемый адрес в стеке. Если вы заметили, что в кадре стека явно есть пустое место – это объясняется использованием дополнительных ячеек при деоптимизации, а также выравниванием.
Автор благодарит Тома Родригеса за консультации по поводу соглашений о вызовах в HotSpot и по поводу компоновки кадров.

