Пришло время вернуться к теме, отложенной из-за большого количества работы.
Напомню, в первой части был рассказ о дешифровке древнейшей греческой письменности – Линейного письма В, исчезнувшего вскоре после Троянской войны, когда у дешифровщиков не было привычных «верных помощников» - параллельных текстов на других языках или хотя бы близкородственных письменностей (был разве что очень «дальний родственник»).
Во второй части речь пошла о более древних письменностях Крита, Линейном А и иероглифах, а также родственном кипро-минойском письме о. Кипр, на которых та же методика уже не сработала, поскольку их язык (или языки) имел(и) в принципе иную структуру. Все эти письменности (вместе с дешифрованными Линейным В и кипрским греческим) в настоящее время известны как «эгейские письменности» (по месту их происхождения в бассейне Эгейского моря).
Рассказав о весьма медленном прогрессе в их изучении, мы остановились на ряде «чисто человеческих» ошибок, совершённых дешифровщиками – например, в попытках определить язык надписей. Но там, где человеческий интеллект слаб – возможно, поможет компьютерная лингвистика, если правильно поставить задачу?
Анализ неизвестного языка
Чтобы статья не разрослась до неприлично большого размера, сосредоточимся для начала на одной письменности – Линейном письме А, непосредственном предке Линейного письма В. Хотя знаки его, с той или иной степенью вероятности, в большинстве читаются, язык его непонятен и родственные связи этого языка тоже неясны. Вероятность, что этот язык – реликт и у него нет надёжных живых родственников (как у баскского, или у мёртвых шумерского, эламского, этрусского), пока что довольно велика.
Что при таком раскладе можно «выжать» из надписей?
Тем более, что язык их заведомо непонятен, а любое сходство звучаний слов с известными языками – обманчиво и может завести не туда?
В этом случае в дело вступает формальный анализ текстов.
Ещё в 1970-е гг. Дэвид Вудли Паккард, наследник владельца компьютерной империи Hewlett-Packard, защитил и опубликовал в виде книги диссертацию с формальным анализом текстов Линейного А. Хотя текстов с тех пор прибавилось, основные выводы его до сих пор не потеряли актуальности.
Прежде всего, он провел статистический анализ встречаемости знаков (в целом в текстах, а также в начале, середине и конце слов), а также сочетаемости знаков друг с другом. Затем провел сопоставление с аналогичной статистикой для Линейного В, чтобы показать – речь идет о разных языках (что, в общем, и так было очевидно из дешифровки последнего, но нужно было проверить валидность метода для того, чтобы делать дальнейшие выводы из результатов его применения). Также Паккард протестировал гипотезу «ошибочности чтений», произвольно заменяя чтения одного из знаков в произвольно выбранных словах текстов, так, чтобы чтение полученного в результате замены «нового слова» совпадало с неким ранее известным словом из текстов Линейного В, и показывал на примере баланса «приобретений-потерь», что принятое до сих пор чтение было, скорее всего, правильным, так как при новом чтении возникало бы гораздо больше противоречий.
Затем Паккард провел анализ текстов на выявление возможных морфем (префиксов, суффиксов, общих корней) в словах Линейного А. Язык оказался весьма беден в плане этих морфем, однако выявленные морфемы не имели аналогов ни в греческом языке, ни в каких-либо других известных языках Средиземноморья того времени.
Что толку от этих морфем, спросит читатель, если мы даже не знаем, является ли слово существительным, глаголом, прилагательным?
Здесь тоже не все так безнадёжно. Поскольку контекст многих табличек Линейного А понятен благодаря идеограммам, для части из них можно сделать вывод: вот это – перечень городов, это – перечень имен, это – перечень товаров, поставленных в тот или иной дворец. Если сравнить с уже дешифрованным Линейным письмом В, то в последнем практически все документы составлены по тому же шаблону, это документы дворцовой бухгалтерии. При этом интересно отметить, что итоговая сумма, баланс документа, как бы помягче сказать, не всегда сходится (и подобное происходит неоднократно). Очевидно, у дворцовых писцов были веские причины не допускать массовой грамотности – письменность была достоянием дворцов и умерла вместе с их разрушением, когда вскоре после Троянской войны наступили «тёмные века».
Но в Линейном А, в отличие от Линейного В, был еще целый ряд относительно длинных (до десятка слов) надписей, не вписывающихся в шаблоны «дворцовой бюрократии». Предполагается, что как минимум часть этих надписей была связана с жертвоприношениями и посвящениями в храмах. Какой вывод можно сделать из этих надписей? Казалось бы, вот тут-то ключей меньше всего: ни цифр, ни идеограмм (почти во всех случаях).
На помощь опять же пришёл формальный анализ. Исследователи обратили внимание на повторяющееся во многих надписях подобного рода слово (или фразу?) ja-sa-sa-ra-me. У слова были варианты, например, ja-sa-sa-ra-ma-na или a-sa-sa-ra-me. Иногда слово встречалось в одиночку (на сосудах, очевидно, для возлияний), иногда в составе фразы.
Для начала лингвисты исследовали сочетаемость этого слова с другими словами, и таким образом, построили своего рода «формулу возлияний», где одним из элементов было пресловутое ja-sa-sa-ra-me, а другие отличались. Формула оказалась довольно однообразной, в разных контекстах слова формулы чаще всего повторялись, лишь некоторые элементы варьировались. В одном случае вместо ja-sa-sa-ra-me в надписи присутствовала идеограмма для оливок (а значит, слово, с большой вероятностью, представляло собой предмет приношений/посвящений, т.е. было существительным, что-то вроде «приношение» или «посвящение», а не именем бога и не глаголом вроде «посвящаю» или «приношу»).
В опубликованной два года назад статье британская лингвистка Роз Томас исследовала не только ja-sa-sa-ra-me, но и другие слова из «формулы приношений» в разных контекстах, и построила еще более широкую модель фразы с варьирующимися в ней словами. Анализ показал, что слова, занимавшие в модели одинаковые позиции, часто имели похожие суффиксы (а следовательно, представляли собой, с большой вероятностью, одни и те же части речи – существительное, глагол и т.п.). Исходя из этих суффиксов в разных контекстах, она нашла дополнительные свидетельства в пользу того, что ja-sa-sa-ra-me, скорее всего, было существительным (а предшествующее ему слово, по-видимому – глаголом). Более того, если предположить, что ja-sa-sa-ra-me и ja-sa-sa-ra-ma-na – это формы единственного и множественного числа, то можно заметить, что при этом меняются и окончания глаголов (примерно как в русском языке: «он сидИТ – онИ сидЯТ»). Отсюда уже можно было сделать предварительные выводы о структуре предложения в языке Линейного А, а также о структуре слов и предположительных значениях некоторых суффиксов.
Отмечу, что подобный анализ был проведен и для надписей иероглифами (здесь заметный вклад внесла греческая лингвистка Артемис Карнава). Несмотря на пугающую краткость большинства из них, на данный момент представляется бесспорным следующее:
- хотя иероглифы внешне выглядят как рисунки, по характеру это такое же слоговое письмо, как и Линейные письмена А и В
- между иероглифами и Линейным А наблюдаются не только заметные лексические совпадения, но совпадает также известная посвятительная формула (только в иероглифических надписях она пишется чуть иначе, ja-sa-sa-ra-ne). Совпадают также тенденции к употреблению определенных знаков в начале, середине или конце слова
- отсюда видно, что в иероглифах, с большой вероятностью, использовался тот же язык, что и в Линейном А (ну или, строго говоря, язык той же группы языков, так как более древний вариант языка мог несколько отличаться по грамматике и лексике, кроме того, он мог быть основан на другом диалекте).
Корпус и палеография
Придется добавить ложку дегтя в бочку меда. Несмотря на прогресс методов data science и natural language processing в современной лингвистике, пожалуй, работа Паккарда более чем 40-летней давности до сих пор остаётся наиболее масштабным достижением в компьютерном анализе надписей Линейного А и родственных ему письменностей. Отчасти это связано с тем, что изучение этих письменностей происходит в рамках программы классических исследований (антиковедения) в университетах разных стран, где математика и информатика отнюдь не являются ключевыми предметами; многое из того, что можно было бы исследовать с помощью хорошо написанных программ, в реальности делается «вручную».
С другой стороны, если тексты Линейного А кратки и фрагментарны, и из них удалось-таки выжать элементы грамматики, то вот для сравнения есть огромный манускрипт Войнича времён примерно эпохи Возрождения, где пока что, если я не ошибаюсь, разве что научились различать вариации окончаний слов, но до сих пор в плане изучения грамматики этого текста далеко не продвинулись; кто рискнет сказать, где в этом тексте существительные, глаголы, прилагательные?
Проблема, на мой взгляд, состоит не только в недостаточно активном применении компьютерных методов к Линейному письму А или иероглифам.
Как говорил современный российский лингвист В. Плунгян, современная лингвистика должна быть лингвистикой корпусов. Корпус – это база данных для конкретного языка, включающая в себя если не все известные тексты (для древнего языка это еще возможно, для современного – нереально), то по крайней мере наиболее репрезентативную их выборку, включая медиа-материалы (звуко- и видеозаписи). Корпус, в отличие от любого словаря, позволяет изучать язык в динамике, а слова – в контексте. Грамотно построенный корпус языка – хорошая база для множества сотен будущих научных работ. На корпусном подходе построены многие известные ныне онлайн-переводчики (Google Translate, DeepL и другие).
Корпуса существуют для большинства современных живых языков, а также для ряда хорошо задокументированных древних, вроде латыни или древнекитайского.
Корпус позволяет отслеживать исторические, региональные, стилистические и даже индивидуальные вариации (например, в связи с изменением орфографии, или индивидуальным словоупотреблением конкретного человека). Грамотно проведенное, со статистическим анализом, исследование на основе корпуса – куда более надежно, чем любая «работа гения» - хотя бы потому, что любой более-менее грамотный посторонний исследователь по той же теме сможет не только оценить правильность параметров или адекватность выводов, но и, слегка «подкрутив» или дополнив параметры, исследовать дальнейшие аспекты проблемы, которые предыдущий исследователь не успел охватить (были вне его интересов, или просто не хватило времени или финансирования). Причем, поскольку корпуса постоянно пополняются, возможно построение самообучающегося алгоритма (как в случае с технологиями машинного перевода – все еще несовершенными, но ушедшими далеко вперед за последние 2 десятка лет).
Как же обстоят дела с корпусами Линейного А, иероглифов, кипро-минойского письма?
Для первых двух – корпуса есть (известные под забавными аббревиатурами GORILA и CHIC); у GORILA, в свою очередь, есть адаптированная онлайн-версия SigLA. Для третьего он пока, мягко говоря, имеет неудобный для пользователя формат, но всё поправимо.
Но, скажем, если для современных языков составление корпуса в основном сводится к оцифровке текстов и их разметке, то для древних письменностей на первое место выходят задачи палеографического характера.
Палеография – дисциплина, занимающаяся изучением древних письменностей с точки зрения их «матчасти»: различные почерки, вариации написания знаков, развитие формы знаков во времени, и так далее. Задачи палеографии во многом напоминают те, с которыми работают OCR-алгоритмы, распознающие печатные и рукописные тексты на современных языках.
Разница в том, что если OCR-алгоритмам есть обучаться на чём-то уже готовом, то для письменностей вроде Линейного А необходима длительная подготовительная работа.
Одна из проблем состоит в том, что некоторые знаки (или по крайней мере отдельные их вариации в отдельных контекстах) могут по начертанию не отличаться друг от друга, будучи при этом разными знаками. Чтобы проиллюстрировать, что я имею в виду – я написал по-русски слово «шпинат» тремя своими разными почерками:

Как видно в первой строке, часть букв не только трудно отделить друг от друга, но я даже забыл написать одну черту; впрочем, мне-то в контексте слово понятно, ну а если текст читает человек без знания контекста?
Понятно, что палеографические задачи можно автоматизировать. Для этого нужно закодировать тексты, то есть составить перечень знаков Линейного А, каждому знаку присвоить цифровой индекс, а затем в тех местах в текстах, где знак неразборчив или возможны несколько вариантов – задать переменную и протестировать разные гипотезы о знаке. Если слово с сомнительным знаком встречается в нескольких текстах – вполне возможно, что в одном из текстов знак будет написан чётче, чем в остальных.

Но это в идеале. В реальности, конечно, пока получается много ручной работы.
Кроме того, помимо отличения знаков Линейного А собственно друг от друга, существует также проблема их сопоставления со знаками Линейного В (поскольку, как мы помним, мы можем читать знаки лишь постольку, поскольку уверены в их соответствии знакам уже дешифрованной письменности).
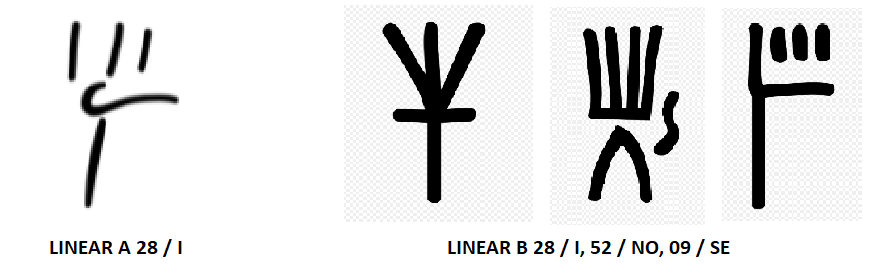
Вот только один пример: в Линейном В было три знака, не так уж и сильно похожих друг на друга: I, NO, SE (на рисунке ниже - справа), а в Линейном А часто встречался знак, похожий сразу на все три (на рисунке слева) - какому из них он соответствовал? Насколько я могу судить, проблема (в пользу первого чтения) была однозначно решена лишь примерно через пару десятилетий после дешифровки Вентриса, и совсем не при помощи компьютерного анализа, скорее путём долгого перебора возможных вариантов для того или иного случая. Гипотеза о значении I победила как наиболее вероятная, поскольку были обнаружены соответствия между некоторыми именами и названиями местностей в табличках Линейного А и В, где употреблялись эти знаки.
Тем не менее, помимо муторной работы, в палеографии есть и прорывы.
Перенесемся с Крита на Кипр, где существовало малоизученное кипро-минойское письмо, родственник Линейного А. Как я уже писал в предыдущей части, хотя родство этих двух письменностей заметно с первого взгляда, лишь около полутора десятков знаков можно сопоставить надёжно, для остальных же, как говорится, «возможны варианты». Лишь знаки архаичной формы кипро-минойского письма (от которого сохранилась одна табличка) были приближены к Линейному А; довольно скоро они претерпели радикальное упрощение для письма на глине. На рисунке ниже можно увидеть пример такого упрощения для знака, чья эволюция относительно легко реконструируется; для многих других такая реконструкция выглядит намного более сложной задачей. Таким образом, хотя дешифрованы ближайшие соседи кипро-минойского языка в эволюционной цепочке, представленной на рисунке, его дешифровка путем одного лишь графического анализа знаков представляется пока бессмысленной.
 - около 800 лет, нижняя (от возникновения кипро-минойского до исчезновения кипрского) - около 1200 лет.")
К этому добавилась ещё одна палеографическая проблема. Один из первых исследователей письма и составитель его корпуса, Жан-Пьер Оливье, выделил сразу три разновидности кипро-минойского письма (не считая архаического) и предположил, что за ними могли стоять три разных языка – как в случае Линейного А и Линейного В на Крите. Утверждение было принято на веру многими исследователями (в частности, эту точку зрения можно встретить в опубликованной на русском языке книге А. Бартонека "Златообильные Микены").
Лишь около 10 лет назад итало-британская исследовательница Сильвия Феррара, проведя структурный и палеографический анализ кипро-минойских надписей, сумела доказать, что гипотеза не имеет под собой оснований, поскольку:
Тексты всеми тремя разновидностями большей частью выполнены в одно и то же время
В текстах «разными видами» письма встречаются не только одни и те же слова (что вполне возможно при заимствовании слов из языка в язык), но и вариации слов (а это уже свидетельствует скорее об общей грамматике языка)
В статистике употребления знаков во всех трех разновидностях письма также соблюдаются одни и те же закономерности.
В отличие от корпуса Линейного письма А, где для каждого знака существуют десятки, если не сотни примеров употребления в разных текстах, палеография кипро-минойских текстов была куда более сложной задачей. Тем не менее, для ряда знаков, на основании их позиционного совпадения в схожих словах, Феррара убедительно доказала, что они являются вариациями одного и того же знака скорее, чем разными знаками.
На данный момент в палеографии эгейских письменностей существует глобальная задача - восстановить эволюционную цепочку если не для всех, то для большинства знаков. Пока что такое эволюционное древо, как для знаков с чтением "А" на рисунке выше, можно выстроить не более чем для 15-20 знаков в целом; для большинства же знаков связи надежно можно установить, в лучшем случае, для одной или двух соседних письменностей. Лучше всего изучена эволюция от Линейного А до Линейного В, хуже - от иероглифов до Линейного В и от кипро-минойского до кипрского; наконец, совсем плохо изучены соответствия между кипро-минойским письмом и Линейным письмом А и/или иероглифами (даже непонятно, от которого из двух кипро-минойское письмо произошло).
Окончание следует
В последней части речь пойдёт о возможной идентификации языков Крита и Кипра, а также о нескольких «аномальных» надписях, занимающих непонятное место в системе «эгейских письменностей» - Фестском диске, секире из Аркалохори и филистимских надписях.
Литература
Бартонек А. Златообильные Микены. Пер. О. П. Цыбенко. — М.: Наука, 1991.
Гордон С. Забытые письмена. — М: Евразия, 2002.
Зализняк А.А. О профессиональной и любительской лингвистике. «Наука и жизнь», 2009, № 1.
Молчанов А. А., Нерознак В. П., Шарыпкин С. Я. Памятники древнейшей греческой письменности. Введение в микенологию. — М.: Наука, 1988. — 190 с.
Плунгян В. Почему современная лингвистика должна быть лингвистикой корпусов. // «Полит.Ру», Лекции, 23 октября 2009 г.
Поуп М. Тайны исчезнувших языков. От египетских иероглифов до письма майя. М.: «А. Д. Варфоломеев», 2016. — 304 с.
Тайны древних письмён. Проблемы дешифровки. Сборник статей. — М.: Прогресс, 1976. — 592 с.
Фокс Маргалит. Тайна лабиринта. Как была прочитана забытая письменность. — М.: Corpus, 2016. — 352 с. — ISBN 978-5-17-090190-6.
Douros G. Linear A. An online database.
Ferrara S. Cypro-Minoan Inscriptions. Vol. 1: Analysis (2012); Vol. 2: The Corpus (2013). Oxford University Press. ISBN 0-19-960757-5 and ISBN 0-19-969382-X
Packard D.W. Minoan Linear A. University of California Press, 1974. — ISBN 0-520-02580-6.
Salgarella, E. The Aegean Linear Script(s): Rethinking the Relationship between Linear A and Linear B. Cambridge: Cambridge University Press, 2020. Pp. 436. — ISBN 9781108479387.
Younger A. Linear A Texts and Inscriptions in Phonetic Transcription.

