?Кратко о сути: парсинг исторических органических и цитируемых результатов 2017-2021 годов с Google Scholar используя пагинацию. Следом их сохранение в CSV и SQLite БД используя Python и библиотеку для веб-скрейпинга от SerpApi.
?Что понадобится: понимание циклов, структур данных, обработка исключений. А так же serpapi, urllib, pandas, sqlite3 библиотеки.
⏱️Сколько времени займет: ~20-60 минут на чтение и реализацию.
Что парсим
Из органических результатов:

?Примечание: На Google Scholar есть максимальный лимит в 100 страниц, поэтому когда вы видите About xxx.xxx results это не означает что все результаты отображаются и их можно спарсить. Так же как это происходит с Гугл поиском.
Из цитируемых результатов:
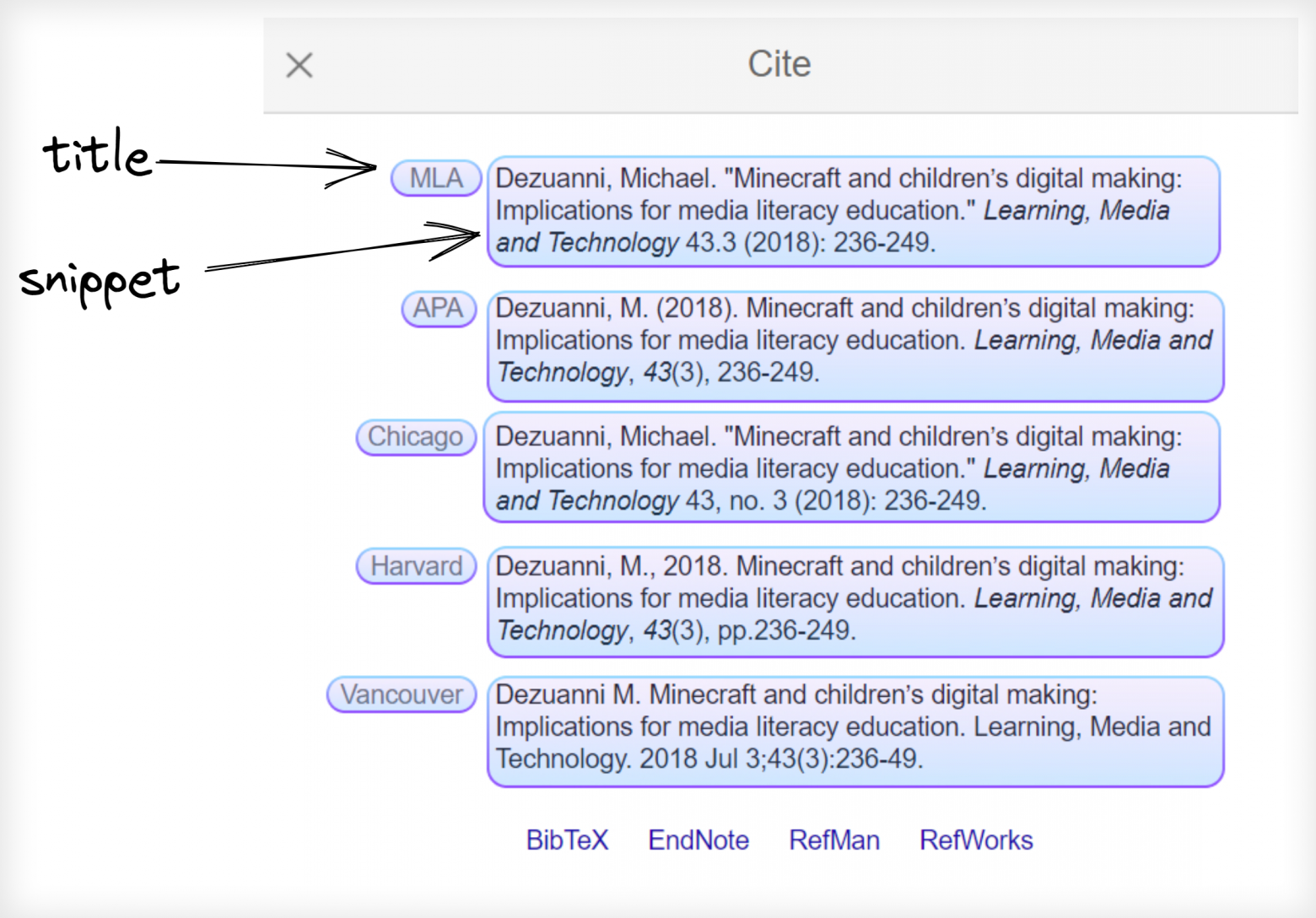
Что понадобится
Отдельное вирутуальное окружение
Если вы не работали с виртуальным окружением ранее, взгляните на посвященный этому блог пост на английском языке - Python virtual environments tutorial using Virtualenv and Poetry.
Вкратце, это штука, которая создает независимый набор установленных библиотек включая возможность установки разных версий Python которые могут сосуществовать друг с другом одновременно на одной системе, что в свою очередь предотвращает конфликты библиотек и разных версий Python.
?Примечание: использование виртуальной среды не является строгим требованием.
Установка библиотек:
pip install google-search-results pip install pandas
Процесс

Если объяснение не нужно:
забирайте код в секции весь код целиком,

Органические результаты
import os from serpapi import GoogleSearch from urllib.parse import urlsplit, parse_qsl def organic_results(): print("extracting organic results..") params = { "api_key": os.getenv("API_KEY"), # ключ для аутентификации в SerpApi "engine": "google_scholar", "q": "minecraft redstone system structure characteristics strength", # поисковый запрос "hl": "en", # язык "as_ylo": "2017", # с 2017 "as_yhi": "2021", # до 2021 "start": "0" # первая страница } search = GoogleSearch(params) organic_results_data = [] loop_is_true = True while loop_is_true: results = search.get_dict() print(f"Currently extracting page №{results['serpapi_pagination']['current']}..") for result in results["organic_results"]: position = result["position"] title = result["title"] publication_info_summary = result["publication_info"]["summary"] result_id = result["result_id"] link = result.get("link") result_type = result.get("type") snippet = result.get("snippet") try: file_title = result["resources"][0]["title"] except: file_title = None try: file_link = result["resources"][0]["link"] except: file_link = None try: file_format = result["resources"][0]["file_format"] except: file_format = None try: cited_by_count = int(result["inline_links"]["cited_by"]["total"]) except: cited_by_count = None cited_by_id = result.get("inline_links", {}).get("cited_by", {}).get("cites_id", {}) cited_by_link = result.get("inline_links", {}).get("cited_by", {}).get("link", {}) try: total_versions = int(result["inline_links"]["versions"]["total"]) except: total_versions = None all_versions_link = result.get("inline_links", {}).get("versions", {}).get("link", {}) all_versions_id = result.get("inline_links", {}).get("versions", {}).get("cluster_id", {}) organic_results_data.append({ "page_number": results["serpapi_pagination"]["current"], "position": position + 1, "result_type": result_type, "title": title, "link": link, "result_id": result_id, "publication_info_summary": publication_info_summary, "snippet": snippet, "cited_by_count": cited_by_count, "cited_by_link": cited_by_link, "cited_by_id": cited_by_id, "total_versions": total_versions, "all_versions_link": all_versions_link, "all_versions_id": all_versions_id, "file_format": file_format, "file_title": file_title, "file_link": file_link, }) if "next" in results["serpapi_pagination"]: search.params_dict.update(dict(parse_qsl(urlsplit(results["serpapi_pagination"]["next"]).query))) else: loop_is_true = False return organic_results_data
Объяснение парсинга органических результатов используя пагинацию
Импортируем os, serpapi, urllib библиотеки:
import os from serpapi import GoogleSearch from urllib.parse import urlsplit, parse_qsl
Создаем и передаем поисковые параметры в GoogleSearch() где происходит все извлечение данных на бэкенде SerpApi:
params = { "api_key": os.getenv("API_KEY"), # ключ для аутентификации в SerpApi "engine": "google_scholar", "q": "minecraft redstone system structure characteristics strength", # поисковый запрос "hl": "en", # язык "as_ylo": "2017", # с 2017 "as_yhi": "2021", # до 2021 "start": "0" # первая страница } search = GoogleSearch(params) # извлечение данных происходит тут
Создаём временный список list() для того чтобы сохранить данные которые будут дальше использоваться для сохранения в CSV или переданыcite_results() функции:
organic_results_data = []
Создаём while цикл для парсинга данных со всех доступных страниц:
loop_is_true = True while loop_is_true: results = search.get_dict() # парсинг данных происходит тутачки.. if "next" in results["serpapi_pagination"]: search.params_dict.update(dict(parse_qsl(urlsplit(results["serpapi_pagination"]["next"]).query))) else: loop_is_true = False
Если нет ссылки на следующую
"next"страницу -whileпрекратится установивloop_is_trueнаFalse.Если есть ссылка на следующую
"next"страницу,search.params_dict.updateразберет ссылку на части и передаст её кGoogleSearch(params)для результатов с новой страницы.
Парсим данные в for цикле:
for result in results["organic_results"]: position = result["position"] title = result["title"] publication_info_summary = result["publication_info"]["summary"] result_id = result["result_id"] link = result.get("link") result_type = result.get("type") snippet = result.get("snippet") try: file_title = result["resources"][0]["title"] except: file_title = None try: file_link = result["resources"][0]["link"] except: file_link = None try: file_format = result["resources"][0]["file_format"] except: file_format = None try: cited_by_count = int(result["inline_links"]["cited_by"]["total"]) except: cited_by_count = None cited_by_id = result.get("inline_links", {}).get("cited_by", {}).get("cites_id", {}) cited_by_link = result.get("inline_links", {}).get("cited_by", {}).get("link", {}) try: total_versions = int(result["inline_links"]["versions"]["total"]) except: total_versions = None all_versions_link = result.get("inline_links", {}).get("versions", {}).get("link", {}) all_versions_id = result.get("inline_links", {}).get("versions", {}).get("cluster_id", {})
try/exceptблоки были использованы для обработкиNoneзначений когда они отсутствуют из Google бэкенда.
Если объединить все в один try блок, извлеченные данные могут быть неаккуратны, иными словами если ссылка или описание на самом деле есть в выдаче, вместо этого оно вернёт None, поэтому здесь много try/except блоков.
Добавляем извлеченные данные во временный list() список:
organic_results_data = [] # тут парсинг и while цикл... organic_results_data.append({ "page_number": results["serpapi_pagination"]["current"], "position": position + 1, "result_type": result_type, "title": title, "link": link, "result_id": result_id, "publication_info_summary": publication_info_summary, "snippet": snippet, "cited_by_count": cited_by_count, "cited_by_link": cited_by_link, "cited_by_id": cited_by_id, "total_versions": total_versions, "all_versions_link": all_versions_link, "all_versions_id": all_versions_id, "file_format": file_format, "file_title": file_title, "file_link": file_link, })
Возвращаем временный list() список с данными которые будут использоваться позже при парсинге Цитируемых результатов:
return organic_results_data

Цитируемые результаты
В этой секции мы используем возвращенные данные из органической выдачи и передадим result_id в поисковый запрос для того чтобы спарсить цитируемые результаты.
Если у вас уже есть result_ids, вы можете пропустить парсинг Органических результатов:
# если у вас есть список result_ids result_ids = ["FDc6HiktlqEJ"..."FDc6Hikt21J"] for citation in result_ids: params = { "api_key": "API_KEY", # ключ для аутентификации в SerpApi "engine": "google_scholar_cite", # движок для парсинга цитируемых результатов "q": citation # FDc6HiktlqEJ ... FDc6Hikt21J } search = GoogleSearch(params) results = search.get_dict() # дальнейший код парсинга..
Ниже примера кода парсинга цитируемых результатов вы так же найдете пошаговое объяснение того что в нём происходит.
import os from serpapi import GoogleSearch from google_scholar_organic_results import organic_results def cite_results(): print("extracting cite results..") citation_results = [] for citation in organic_results(): params = { "api_key": os.getenv("API_KEY"), # ключ для аутентификации в SerpApi "engine": "google_scholar_cite", # # движок для парсинга цитируемых результатов "q": citation["result_id"] # # FDc6HiktlqEJ ... FDc6Hikt21J } search = GoogleSearch(params) results = search.get_dict() print(f"Currently extracting {citation['result_id']} citation ID.") for result in results["citations"]: cite_title = result["title"] cite_snippet = result["snippet"] citation_results.append({ "organic_result_title": citation["title"], "organic_result_link": citation["link"], "citation_title": cite_title, "citation_snippet": cite_snippet }) return citation_results
Объяснение парсинга цитируемых результатов
Создаём временный список list() для хранения извлеченных данных:
citation_results = []
Создаём for цикл для итерации по organic_results() результатам и передаем result_id в "q" поисковый запрос:
for citation in organic_results(): params = { "api_key": os.getenv("API_KEY"), # ключ для аутентификации в SerpApi "engine": "google_scholar_cite", # # движок для парсинга цитируемых результатов "q": citation["result_id"] # # FDc6HiktlqEJ ... FDc6Hikt21J } search = GoogleSearch(params) # парсинг на бэкенде SerpApi results = search.get_dict() # JSON конвертируется в словарь
Создаём второй for цикл и достукиваемся к данный таким же способом как и до словаря:
for result in results["citations"]: cite_title = result["title"] cite_snippet = result["snippet"]
Добавляем извелченные данные во временный список list() как словарь:
citation_results.append({ "organic_result_title": citation["title"], # чтобы понимать откуда берутся Цитируемые результаты "organic_result_link": citation["link"], # чтобы понимать откуда берутся Цитируемые результаты "citation_title": cite_title, "citation_snippet": cite_snippet })
Возвращаем временный список list():
return citation_results

Сохраняем в CSV
Нам только нужно передать возвращенные данные из органических и цитируемых результатов в DataFrame data аргумент и сохранить to_csv().
import pandas as pd from google_scholar_organic_results import organic_results from google_scholar_cite_results import cite_results print("waiting for organic results to save..") pd.DataFrame(data=organic_results()) .to_csv("google_scholar_organic_results.csv", encoding="utf-8", index=False) print("waiting for cite results to save..") pd.DataFrame(data=cite_results()) .to_csv("google_scholar_citation_results.csv", encoding="utf-8", index=False)
Объяснение процесса сохранения в CSV
Импортируем organic_results() и cite_results() откуда возвращаются данные, и библиотеку pandas:
import pandas as pd from google_scholar_organic_results import organic_results from google_scholar_cite_results import cite_results
Сохраняем органические результаты to_csv():
pd.DataFrame(data=organic_results()) \ .to_csv("google_scholar_organic_results.csv", encoding="utf-8", index=False)
Сохраняем цитируемые результаты to_csv():
pd.DataFrame(data=cite_results()) \ .to_csv("google_scholar_citation_results.csv", encoding="utf-8", index=False)
dataаргумент внутриDataFrameэто извлеченные данные.encoding='utf-8'аргумент просто для того чтобы все было корректно сохранено. Я использовал этот аргумент явно, несмотря на то что это его дефолтное значение.index=Falseаргумент чтобы убрать дефолтные номера строкpandas.

Сохраняем в SQLite
После этой секции вы узнаете о том как:
сохранять данные в SQLite используя
pandas,функционирует SQLite,
подключаться и разрывать соединение с SQLite,
создавать и удалять таблицы/колонки,
добавлять данные в
forцикле.
Пример того как функционирует SQLite:
1. открывается соединение 2. транзакция начинается 3. выполняется инструкция 4. транзакция завершается 5. закрывается соединение
Сохранение данные в SQLite используя pandas
# https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.to_sql.html import sqlite3 import pandas as pd from google_scholar_organic_results import organic_results from google_scholar_cite_results import cite_results conn = sqlite3.connect("google_scholar_results.db") # создавать таблицу ручными SQL запросами не нужно, # pandas это сделает автоматически. # сохраняет органические результаты в SQLite pd.DataFrame(organic_results()).to_sql(name="google_scholar_organic_results", con=conn, if_exists="append", index=False) # сохраняет цитируемые результаты в SQLite pd.DataFrame(cite_results()).to_sql(name="google_scholar_cite_results", con=conn, if_exists="append", index=False) conn.commit() conn.close()
nameэто название SQL таблицы.conэто соединение с базой данных.if_existsскажетpandasкак себя вести если таблица уже существует. По умолчанию оно не сработает"fail"и вызоветraiseошибкуValueError. В данном случаеpandasбудет добавлять данные.index=Falseчтобы убрать индекс столбцов отDataFrame.
Другой способ сохранения данных вручную используя запросы SQLite
import sqlite3 conn = sqlite3.connect("google_scholar_results.db") conn.execute("""CREATE TABLE google_scholar_organic_results ( page_number integer, position integer, result_type text, title text, link text, snippet text, result_id text, publication_info_summary text, cited_by_count integer, cited_by_link text, cited_by_id text, total_versions integer, all_versions_link text, all_versions_id text, file_format text, file_title text, file_link text)""") conn.commit() conn.execute("""CREATE TABLE google_scholar_cite_results ( organic_results_title text, organic_results_link text, citation_title text, citation_link text)""") conn.commit() # сохраняем органические результаты for item in organic_results(): conn.execute("""INSERT INTO google_scholar_organic_results VALUES (:page_number, :position, :result_type, :title, :link, :snippet, :result_id, :publication_info_summary, :cited_by_count, :cited_by_link, :cited_by_id, :total_versions, :all_versions_link, :all_versions_id, :file_format, :file_title, :file_link)""", {"page_number": item["page_number"], "position": item["position"], "result_type": item["type"], "title": item["title"], "link": item["link"], "snippet": item["snippet"], "result_id": item["result_id"], "publication_info_summary": item["publication_info_summary"], "cited_by_count": item["cited_by_count"], "cited_by_link": item["cited_by_link"], "cited_by_id": item["cited_by_id"], "total_versions": item["total_versions"], "all_versions_link": item["all_versions_link"], "all_versions_id": item["all_versions_id"], "file_format": item["file_format"], "file_title": item["file_title"], "file_link": item["file_link"]}) conn.commit() # сохраняем цитируемые результаты for cite_result in cite_results(): conn.execute("""INSERT INTO google_scholar_cite_results VALUES (:organic_result_title, :organic_result_link, :citation_title, :citation_snippet)""", {"organic_result_title": cite_result["organic_result_title"], "organic_result_link": cite_result["organic_result_link"], "citation_title": cite_result["citation_title"], "citation_snippet": cite_result["citation_snippet"]}) conn.commit() conn.close() # явно лучше, чем неявно
Объяснение сохранения извлеченных данных вручную прописывая запросы SQLite
Импортируем sqlite3 библиотеку:
import sqlite3
Соединяемся с существующей базе данных или даём новое имя и библиотека создаст базу данных:
conn = sqlite3.connect("google_scholar_results.db")
Создаём таблицу органические результаты, указываем тип данных и применяем изменения:
conn.execute("""CREATE TABLE google_scholar_organic_results ( page_number integer, position integer, result_type text, title text, link text, snippet text, result_id text, publication_info_summary text, cited_by_count integer, cited_by_link text, cited_by_id text, total_versions integer, all_versions_link text, all_versions_id text, file_format text, file_title text, file_link text)""") conn.commit()
Создаём таблицу цитируемые результаты, указываем тип данных и применяем изменения:
conn.execute("""CREATE TABLE google_scholar_cite_results ( organic_results_title text, organic_results_link text, citation_title text, citation_link text)""") conn.commit()
Добавляем извлеченные органические результаты в таблицу используя for цикл:
for item in organic_results(): conn.execute("""INSERT INTO google_scholar_organic_results VALUES (:page_number, :position, :result_type, :title, :link, :snippet, :result_id, :publication_info_summary, :cited_by_count, :cited_by_link, :cited_by_id, :total_versions, :all_versions_link, :all_versions_id, :file_format, :file_title, :file_link)""", {"page_number": item["page_number"], "position": item["position"], "result_type": item["type"], "title": item["title"], "link": item["link"], "snippet": item["snippet"], "result_id": item["result_id"], "publication_info_summary": item["publication_info_summary"], "cited_by_count": item["cited_by_count"], "cited_by_link": item["cited_by_link"], "cited_by_id": item["cited_by_id"], "total_versions": item["total_versions"], "all_versions_link": item["all_versions_link"], "all_versions_id": item["all_versions_id"], "file_format": item["file_format"], "file_title": item["file_title"], "file_link": item["file_link"]}) conn.commit()
Добавляем извлеченные цитируемые результаты в таблицу используя for цикл:
for cite_result in cite_results(): conn.execute("""INSERT INTO google_scholar_cite_results VALUES (:organic_result_title, :organic_result_link, :citation_title, :citation_snippet)""", {"organic_result_title": cite_result["organic_result_title"], "organic_result_link": cite_result["organic_result_link"], "citation_title": cite_result["citation_title"], "citation_snippet": cite_result["citation_snippet"]}) conn.commit()
Закрываем cоединение с базой данных:
conn.close()
Дополнительные полезные команды:
# удалить все данные из таблицы conn.execute("DELETE FROM google_scholar_organic_results") # удалить таблицу conn.execute("DROP TABLE google_scholar_organic_results") # удалить колонку conn.execute("ALTER TABLE google_scholar_organic_results DROP COLUMN authors") # добавить колнку conn.execute("ALTER TABLE google_scholar_organic_results ADD COLUMN snippet text")
Код целиком - парсинг
import os from serpapi import GoogleSearch from urllib.parse import urlsplit, parse_qsl def organic_results(): print("extracting organic results..") params = { "api_key": os.getenv("API_KEY"), "engine": "google_scholar", "q": "minecraft redstone system structure characteristics strength", # поисковый запрос "hl": "en", # язык "as_ylo": "2017", # от 2017 "as_yhi": "2021", # до 2021 "start": "0" } search = GoogleSearch(params) organic_results_data = [] loop_is_true = True while loop_is_true: results = search.get_dict() print(f"Currently extracting page №{results['serpapi_pagination']['current']}..") for result in results["organic_results"]: position = result["position"] title = result["title"] publication_info_summary = result["publication_info"]["summary"] result_id = result["result_id"] link = result.get("link") result_type = result.get("type") snippet = result.get("snippet") try: file_title = result["resources"][0]["title"] except: file_title = None try: file_link = result["resources"][0]["link"] except: file_link = None try: file_format = result["resources"][0]["file_format"] except: file_format = None try: cited_by_count = int(result["inline_links"]["cited_by"]["total"]) except: cited_by_count = None cited_by_id = result.get("inline_links", {}).get("cited_by", {}).get("cites_id", {}) cited_by_link = result.get("inline_links", {}).get("cited_by", {}).get("link", {}) try: total_versions = int(result["inline_links"]["versions"]["total"]) except: total_versions = None all_versions_link = result.get("inline_links", {}).get("versions", {}).get("link", {}) all_versions_id = result.get("inline_links", {}).get("versions", {}).get("cluster_id", {}) organic_results_data.append({ "page_number": results["serpapi_pagination"]["current"], "position": position + 1, "result_type": result_type, "title": title, "link": link, "result_id": result_id, "publication_info_summary": publication_info_summary, "snippet": snippet, "cited_by_count": cited_by_count, "cited_by_link": cited_by_link, "cited_by_id": cited_by_id, "total_versions": total_versions, "all_versions_link": all_versions_link, "all_versions_id": all_versions_id, "file_format": file_format, "file_title": file_title, "file_link": file_link, }) if "next" in results["serpapi_pagination"]: search.params_dict.update(dict(parse_qsl(urlsplit(results["serpapi_pagination"]["next"]).query))) else: loop_is_true = False return organic_results_data def cite_results(): print("extracting cite results..") citation_results = [] for citation in organic_results(): params = { "api_key": os.getenv("API_KEY"), "engine": "google_scholar_cite", "q": citation["result_id"] } search = GoogleSearch(params) results = search.get_dict() print(f"Currently extracting {citation['result_id']} citation ID.") for result in results["citations"]: cite_title = result["title"] cite_snippet = result["snippet"] citation_results.append({ "organic_result_title": citation["title"], "organic_result_link": citation["link"], "citation_title": cite_title, "citation_snippet": cite_snippet }) return citation_results # пример вывода при парсинге органических результатов и сохранение в SQL: ''' extracting organic results.. Currently extracting page №1.. Currently extracting page №2.. Currently extracting page №3.. Currently extracting page №4.. Currently extracting page №5.. Currently extracting page №6.. Done extracting organic results. Saved to SQL Lite database. '''
Код целиком - сохранение
import pandas as pd import sqlite3 from google_scholar_organic_results import organic_results from google_scholar_cite_results import cite_results # Один из способов сохранить данные в БД используя Pandas print("waiting for organic results to save..") organic_df = pd.DataFrame(data=organic_results()) organic_df.to_csv("google_scholar_organic_results.csv", encoding="utf-8", index=False) print("waiting for cite results to save..") cite_df = pd.DataFrame(data=cite_results()) cite_df.to_csv("google_scholar_citation_results.csv", encoding="utf-8", index=False) # ------------------------------ # Другой способ сохранить данные в БФ в ручную прописывая SQLite запросы conn = sqlite3.connect("google_scholar_results.db") conn.execute("""CREATE TABLE google_scholar_organic_results ( page_number integer, position integer, result_type text, title text, link text, snippet text, result_id text, publication_info_summary text, cited_by_count integer, cited_by_link text, cited_by_id text, total_versions integer, all_versions_link text, all_versions_id text, file_format text, file_title text, file_link text)""") conn.commit() conn.execute("""CREATE TABLE google_scholar_cite_results ( organic_results_title text, organic_results_link text, citation_title text, citation_link text)""") conn.commit() for item in organic_results(): conn.execute("""INSERT INTO google_scholar_organic_results VALUES (:page_number, :position, :result_type, :title, :link, :snippet, :result_id, :publication_info_summary, :cited_by_count, :cited_by_link, :cited_by_id, :total_versions, :all_versions_link, :all_versions_id, :file_format, :file_title, :file_link)""", {"page_number": item["page_number"], "position": item["position"], "result_type": item["type"], "title": item["title"], "link": item["link"], "snippet": item["snippet"], "result_id": item["result_id"], "publication_info_summary": item["publication_info_summary"], "cited_by_count": item["cited_by_count"], "cited_by_link": item["cited_by_link"], "cited_by_id": item["cited_by_id"], "total_versions": item["total_versions"], "all_versions_link": item["all_versions_link"], "all_versions_id": item["all_versions_id"], "file_format": item["file_format"], "file_title": item["file_title"], "file_link": item["file_link"]}) conn.commit() for cite_result in cite_results(): conn.execute("""INSERT INTO google_scholar_cite_results VALUES (:organic_result_title, :organic_result_link, :citation_title, :citation_snippet)""", {"organic_result_title": cite_result["organic_result_title"], "organic_result_link": cite_result["organic_result_link"], "citation_title": cite_result["citation_title"], "citation_snippet": cite_result["citation_snippet"]}) conn.commit() conn.close() print("Saved to SQL Lite database.") # пример вывода: ''' extracting organic results.. Currently extracting page №1.. ... Currently extracting page №4.. extracting cite results.. extracting organic results.. Currently extracting page №1.. ... Currently extracting page №4.. Currently extracting 60l4wsP6Ps0J citation ID. Currently extracting 9hkhIFu_BhAJ citation ID. ... Saved to SQL Lite database. '''
Ссылки
Что дальше
С этими данными должно быть возможно сделать какое-нибудь исследование, или визуализацию по определенной дисциплине. Классным дополнением к этому скрипту будет добавить возможность запускать его каждую неделю или месяц для парсинга дополнительных данных.
Следующий блог пост будет о парсинге Профилей с пагинацией, а так же Авторских результатов.
Если вы хотите парсить данные без необходимости писать парсер с нуля, разбираться как обойти блокировки от поисковых систем, как увеличить объем запросов, или, как парсить данные с JavaScript - попробуйте SerpApi или свяжитесь с SerpApi.

