О чем статья
В этой статье речь пойдет о БАЗОВЫХ подходах и принципах к такому quality attribute (QA) как Availability. Никаких сложных случаев, ничего слишком сложного, только теория с двумя примерами, скипайте, если искали что-то эдакое.
Вся информация основана на парах книг, статей, и моем опыте. В конце статьи я покажу, какие именно. Также, эта статья - по суть перевод моей же статьи, только написанной на английском.
Что такое Availability?
Перед тем, как рассматривать паттерны и техники для обеспечения availability мы должны определить сам термин.
С книги “Designing Data-Intensive Applications”:
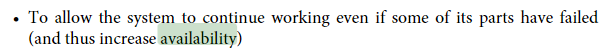
“Дать возможность системе продолжать работать, даже если некоторые части уже не работают”
C книги “Software Architecture in Practice”:

“Наше определение availability как аспект dependability таков: ‘availability означает способность системы маскировать и само восстанавливаться таким образом, чтобы периоды недоступности сервиса не превышали необходимого с течением какого-то времени’. …
Фундаментально, availability - это про минимизирование времени недоступности сервиса, предотвращая ошибки и фейлы”.
Если в простых словах, availability это про то, как сделать систему так, чтобы она отвечала, как корректно работающая, если время от времени что-то идет не так или если весь сервис уже неисправен (идеальный кейс).
Или немного более реалистичный кейс, availability это про какие-то гарантии клиентам, что сервис будет недоступен не более какого-то времени.
Stateful и Stateless
Теперь мы должны дать определения еще двум типам приложений: stateless и stateful.
Если приложение Stateful - то это значит, что оно сохраняет какие-то данные, пока работает (очень часто это информация о предыдущих запросах) как состояние внутри себя.
Это косвенно значит, что для таких же 2-х действий в приложении мы можем получить 2 разных результата. Примеры: клиентские приложения, хранилища (базы данных, кэши)
С другой стороны, stateless приложения работают таким образом, что мы получим два одинаковых результата для двух разных запросов (хотя тело запроса одинаковое, сами запросы отдельны друг от друга) и они не содержат данных из предыдущих запросов.
Почему это важно?
Дело в том, что паттерны для availability для stateless приложений намного проще в реализации, если сравнивать с stateful.
Availability паттерны и техники
Наиболее известная техника для availability это Избыточность. Причина проста: если у нас есть только одна копия приложения, и она перестала работать - мы уже ничего не можем сделать, здесь нет никакой магии.
Поэтому самый популярный паттерн - это создать много копий приложения, чтобы мы могли заменить нерабочие рабочими.
Основной цель статьи - это рассмотреть возобновление с неисправного состояния в исправное, но так же мы должны рассмотреть такие темы как распознавание неисправностей, и предотвращение неисправностей.

Наиболее популярные подходы для распознавания неисправностей связаны с разными подходами мониторинга: пинг, мониторинг ресурсов, процессора, потоков, инпут\аутпута, проверка корректности ответа от серверов и т.д.
Для предотвращения неисправностей мы пытаемся предвидеть все, что может пойти не так, и подготовить что-то, подготовить логику, которая будет обрабатывать такие ситуации: асерты (assertions), тесты (интеграционные, и2и, юнит), чистый код, хорошие практики, обработка ошибок и исключений, ретраи и т.д.
Реализация избыточности для stateless
На самом деле, для high availability лучше использовать что-то облачное, если есть бюджет (АВС, Ажур, Гугл), но для примера, я все продемонстрирую локально. Само собою, отдельные докер контейнеры можно считать контейнерами на отдельных серверах.
Давайте создадим stateless API для нашего примера. Вы можете писать на любом языке, но я, как дотнетчик, создам на дотнет коре.
Весь код решения и докер компоузы вы можете увидеть на моем гитхабе
Если URL невалидный, или не будет доступа - напишите мне в любой соц. Сети, вот например инстаграм
Создаем контроллер:
Редактируем appsettings.json, где задаем NodeId, чтобы можно было оверрайдить потом это значение в компоузе:
Дальше Dockerfile в руте проекта (где .sln расположен):
И докер компоуз в той же директории:
Как вы видите, я буду использовать Nginx как лоад балансер. Добавим еще конфигурационные файлы для Nginx в той же директории:
//app.conf
//nginx.conf
Сейчас наша архитектура выглядит как-то вот так:

Из-за того, что у нашего ендпоинта нет состояния, и он в каком-то смысле pure function, мы можем говорить, что две копии нашего приложение одинаковы, и это значит, что мы легко можем создавать новые и убирать существующие
Выполняем docker-compose up -d
Вот наш сетап:

Время от времени нам система отвечает first_app:

Время от времени, ответ second_app. Это зависит от внутренних правил Nginx’а, но мы точно можем сказать, что оба приложения живы.
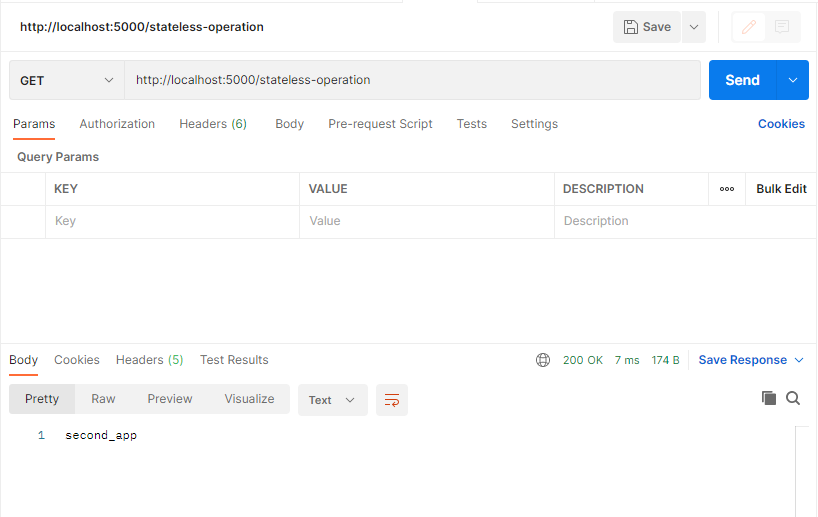
Давайте отключим одну API.

Теперь, сколько бы мы раз не слали запрос, мы увидим только ответ от stateless_api2.

Есть одна проблема с этим - Nginx должен выждать таймаут от ноды, чтобы понять, что она не жива, и послать запрос на другую. Но это уже детали реализации лоад балансера, это можно настроить, особенно на клаудах.
Вот, что говорит “Designing Data-Intensive Applications”:

Некоторые из читателей могут сказать, окей, у нас есть разные копии stateless приложения, но наш Nginx это наш single point of failure. То есть, если Nginx неисправен, система - мертва, она не сможет обслуживать запросы. Или наш сетап как-то гарантирует, что запросы будут обслужены?
Ответ - нет, не гарантирует. Это типичная проблема с лоадбалансерами.
Как возможное решение, мы можем создать копии лоадбалансеров, которые пробрасывают запросы на те же приложения, и дать каждому клиенту список лоадбалансером. Таким образом, если клиент видит ошибку от одного лоад балансера - он мог переключиться на другого.
Реализация для stateful
Для этого примера я использую репликацию с PostgreSQL.
Вы можете более детально ознакомиться с понятие репликации в книге “Designing Data-Intensive Applications''. Там описаны многие типы репликации: асинхронная, синхронная, лидер-фоловер, лидер-лидер, лидерлес.
Извините, я знаю, многие ожидают, что я сделаю репликацию с “голого” имейджа постгреса, сорян, я не хотел с этим запариваться, я нашел уже готовое решение: https://github.com/bitnami/bitnami-docker-postgresql. Репликация с нуля займет отдельную статью.
Копируем docker-compose.yml себе в директорию
Как я понял из документации этого сетапа, мы будем использовать асинхронную лидер-фолловер репликацию, которая считается наипростейшей в реализации.
Это значит, что мы можем читать/писать в лидер, но с фолловеров мы можем только читать. Да, это значит, если мастер - неисправен - мы не можем принимать записи в базу, но можем читать. Как возможное решение - мы можем использовать выбор нового лидера через quorum algorithm, или же использовать другие типы репликации. Но они сложнее в реализации и со своими проблемами.
Запускаем docker compose и смотрим, что запустилось.

В этом примере, наш лоадбалансер - это мастер нода вместо Nginx, она не просто переводит запросы на фолловеры, но и пишет данные в себе. Также наш мастер ответственен за репликацию
Давайте теперь присоединимся к лидеру и фолловеру через PgAdmin (это клиент для PostgreSQL), и создадим простую таблицу с одной колонкой.

Я назвал таблицу “entities”.

Мы можем видеть, что таблица пуста.

Теперь давайте добавим какие-то данные в таблицу

И потом достанем их из двух инстансов:

Теперь давайте отключим мастер, и посмотрим, что случится:


Как вы видите, мы не можем достать данные из мастер ноды, но все еще можем это сделать из фолловера
Это и есть смысл репликации, мы сохраняем при этом данные вместе с функциями системы. То есть, если даже диск с данными на мастере сгорит, у нас все еще есть эти данные на фолловере.
Литература и итоги
Я использовал
2 две крутые книги (очень советую):


Если влом читать статью - вот видео с лайв кодингом, снятое мною тоже:

